FedViT:邊緣視覺轉換器的聯邦持續學習
FedViT: Federated continual learning of vision transformer at edge
(北京理工大學-2023年發表于《Future Generation Computer Systems》中科院二區)
highlight:
?提出一種輕量級的客戶端聯合持續學習方法。
?通過將簽名任務的知識整合到客戶端上,防止災難性遺忘。
?減少負面知識轉移,無需頻繁與服務器通信。
?理論上保證了我們方法更快的訓練收斂。
?適用于多任務、多客戶端、多ViT的場景。
一.Introduction
background:隨著客戶端環境的不斷變化,需要DNN模型重新訓練并適應這些變化。例如圖中ViT,需要隨著時間的推移處理一系列任務。通常,一個任務由多個類別/對象和每個類別的不同特征組成。
聯邦持續學習(FCL)它從由不同任務組成的非平穩數據中增量學習深度模型。FCL在從其他客戶端的(間接)經驗中學習的直覺的驅動下,將持續學習結合在聯邦學習框架中,使客戶端中的模型可以不斷地從其本地數據和其他客戶端的任務知識中學習。
主要問題是災難性遺忘:當其模型隨著時間的推移學習新任務時,它可能會忘記以前學習的任務信息,并且這些任務中的模型準確性會降低。(例:一旦客戶端1中的模型完成其初始任務(即任務(1))的訓練,其參數收斂到任務損失區域的最優點,產生86%的準確率。然而,當隨后適應第二個任務(即使用相同模型的任務(2))時,由于兩個任務之間的相關性有限,參數逐漸偏離任務1的最優點,并逐漸接近任務2的最佳狀態。因此,盡管在任務 2 上達到了 83% 的準確率,但模型對任務 1 的分類準確率卻大幅下降至 54%,這體現了對前一個任務的災難性遺忘現象。)
當客戶端的模型與聯邦學習中來自其他客戶端的模型聚合時,這種差異帶來了重大挑戰。其他客戶端模型中的不同知識可能會降低模型在其專用本地數據上的性能。這種從全局模型中轉移不相關知識的有害轉移被稱為負向知識轉移
ViT對數據分布漂移表現出很強的魯棒性,這是持續學習和聯邦學習面臨的關鍵問題。此外,ViT高度依賴訓練數據,例如數據量和數據多樣性。在FCL中,隨著任務數量的增加,它自然會向ViT提供這些數據資源。
ViT在邊緣持續聯邦學習中的挑戰:
邊緣計算是為了降低與云服務器的通信成本,并通過設備上的數據處理增強數據隱私;模型訓練中的計算和通信成本隨著任務和客戶端的數量而增加,并且在資源受限的邊緣設備上進行這種昂貴的訓練會帶來兩個技術挑戰。
1.有限的計算資源導致顯著的精度損失。因此,第一個挑戰是設計一種輕量級的學習方法,可以直接在資源受限的邊緣設備上保留大量的歷史知識并縮短模型訓練時間。
2.防止負面知識轉移會導致高通信成本和隱私泄露。第二個挑戰是如何開發一種分布式方法,可以防止負面的知識轉移,而不增加客戶之間的額外通信。
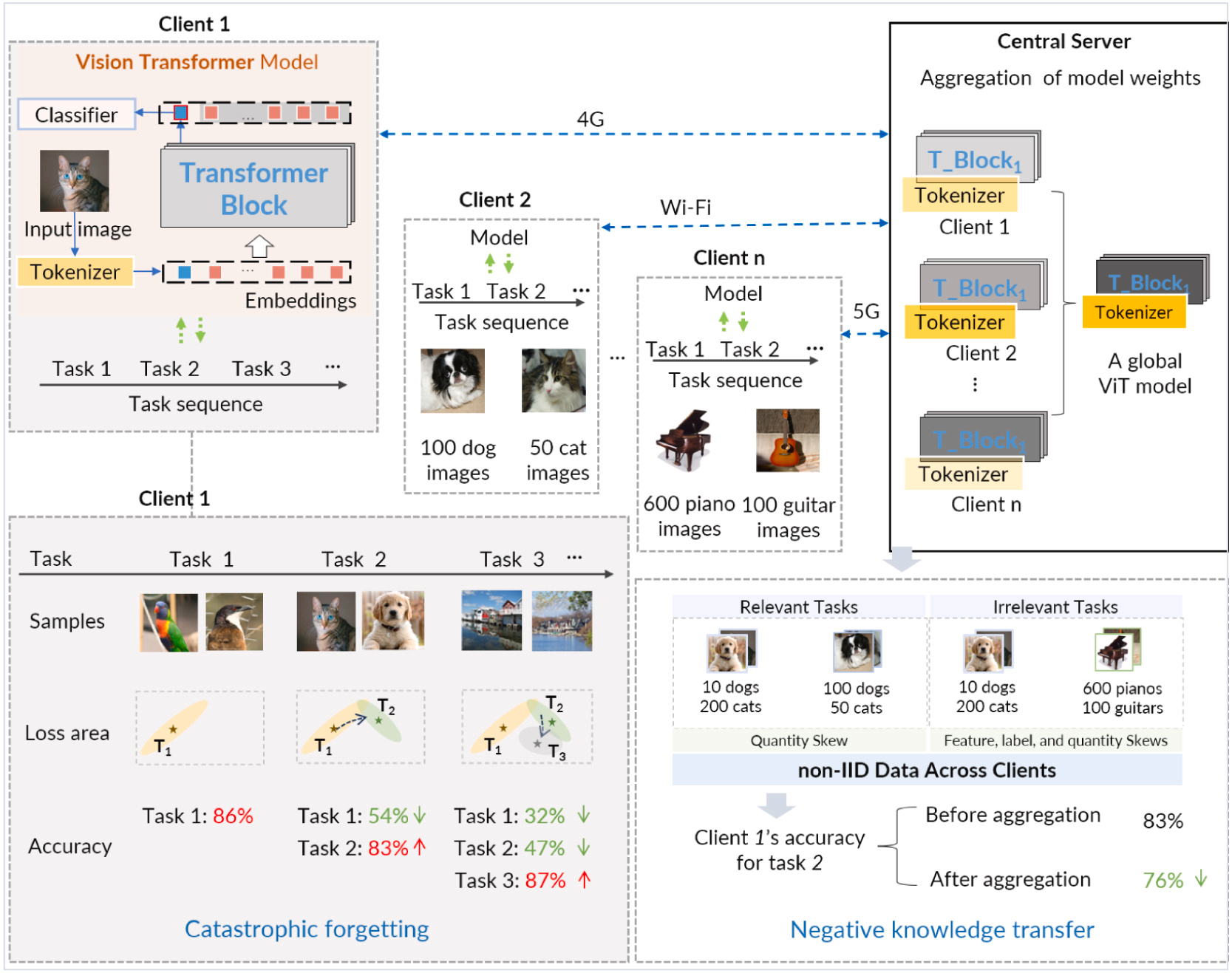
圖. 聯邦持續學習的示例場景 n 客戶
二、方法
總結:FedViT是一種輕量級的客戶端解決方案,它集成了包含相關過去和對等任務的簽名任務的知識。FedViT 在每個客戶端中發揮作用,并提取緊湊且可轉移的知識——重要的數據樣本。在學習一項新任務時,FedViT 將其與其簽名任務的知識相結合,這些任務是從本地過去的任務中識別出新任務中最不同的任務,以防止災難性遺忘,以及代表其他客戶端當前任務的更新全局模型,以防止負面知識轉移。通過完成具有多項式時間復雜度的知識集成,FedViT 通過提供高模型精度和邊緣低通信開銷來解決現有技術的局限性。
1.通過對簽名任務的了解提供可擴展的客戶端解決方案。
2.通過梯度積分進行高精度模型訓練。

主要分為三個部分:知識提取器、梯度恢復器、梯度積分器
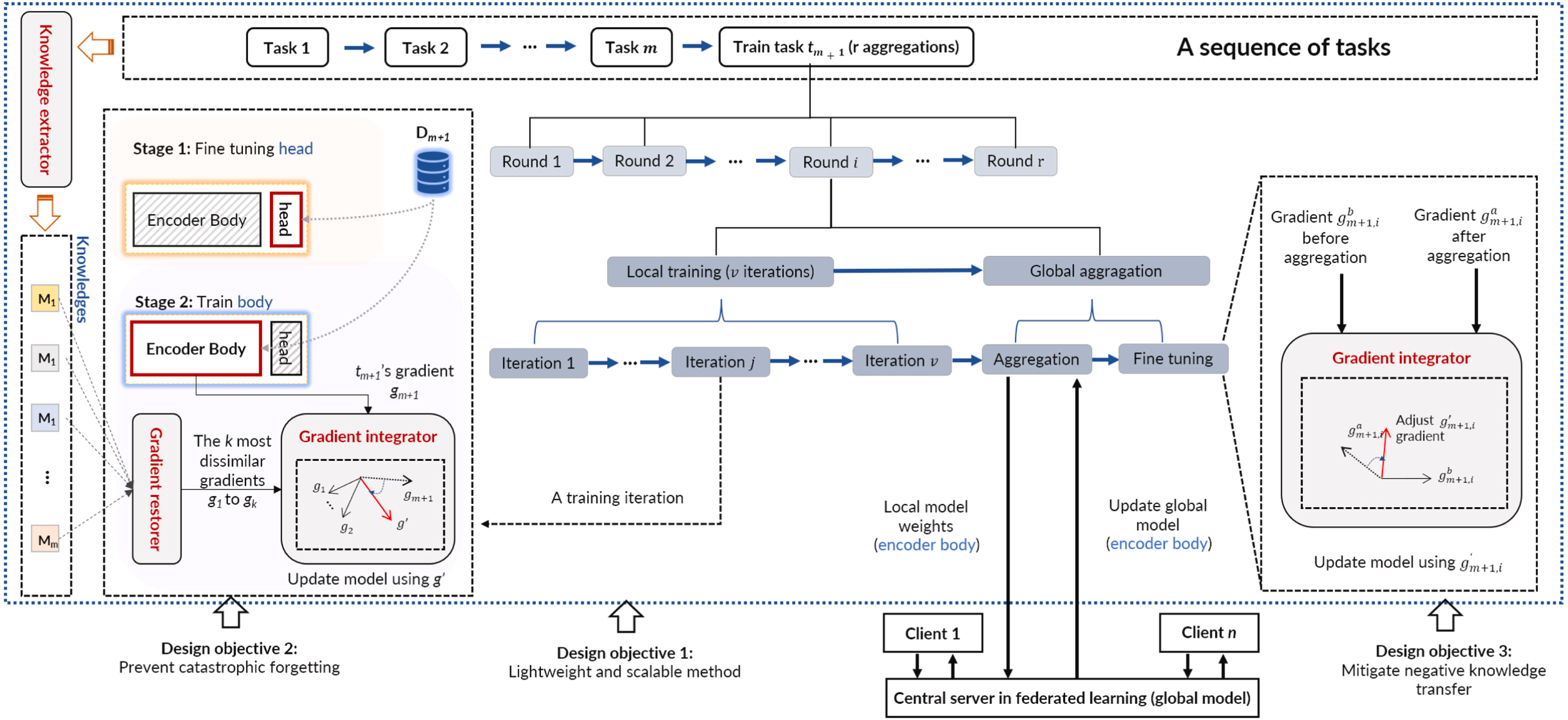
圖 FedViT的流程和設計目的

三、實驗:
測試平臺:Jetson TX2 8 GB; Jetson Nano 4 GB; Jetson Xavier NX 16 GB; Jetson AGX 32 GB
數據集:CIFAR100、FC100、COR50、MiniImageNet、TiniImageNet;分為多個任務,每個任務有多個類別;并隨機分配為Non-IID,數據間差異較大
對比基線模型:
- 持續學習方法:gradient episodic memory (GEM)、Balanced Continual Learning (BCN)、Balanced Continual Learning (BCN)、Memory aware synapses(MAS)、Dytox、LVT
- 聯邦學習方法:FedAvg、APFL、FedRep
- 聯邦持續學習方法:FedWEIT、FedKNOW
評價指標:平均準確率 (Average Accuracy)、遺忘率 (Forgetting Rate)、通信成本 (Communication Cost)、計算成本 (Computation Cost)、存儲開銷 (Memory Storage)
對比試驗:
不同FCL下精度評估:在不同數據集上,測試了不同類型模型的準確度(災難性遺忘和負面知識轉移);此外還評估了異構邊緣設備上FedViT的準確率
通信成本評估:
將FedViT和FedWEIT進行對比,在不同數據集上,FedViT在執行相同模型訓練任務時需要更少的通信成本;
在不同網絡帶寬下,FedViT的通信時間始終更少。
客戶端和任務數量討論:
任務數:將TinyImageNet(200類)構建為多任務數據集,50個任務,每個任務4類;為了保證每個任務的數據異構性,將數據集劃分為 10 個客戶端,每個客戶端最多包含 2 類數據樣本。 測試不同任務下,對比模型的精度。
客戶端數:50個和100個客戶端比較準確率和遺忘率。
綜上所述,FedViT 利用少量高質量樣本作為舊任務知識,使其即使在訓練樣本極其有限的場景下也能準確恢復舊任務知識。此外,基于梯度積分的知識恢復器有效解決了客戶端或任務數量不斷增加導致的嚴重負向知識轉移問題,使其成為實際聯邦學習應用的潛在候選者。
不同ViT模型的適用性:
測試了5種共8個ViT模型,隨任務數增加精度的變化,結果表明在8種模型下,FedViT框架都取得了最好的精度。還對比了不同客戶端采樣率下的比較;不同知識存儲速率下的比較;以及圖像分辨率的影響
超參數的影響:
知識存儲率的影響 ;所選漸變數量的影響
結論:
FedViT是一個專為分布式邊緣設備上基于Transformer的計算機視覺模型而設計的框架。FedViT 在三個方面進行創新,以應對邊緣聯合持續學習的關鍵挑戰。首先,基于樣本的輕量級知識提取減少了設備開銷,同時保留了關鍵的過去任務信息,提高了約束下的持續學習精度。其次,梯度積分消除了負遷移,有利于新舊知識的同化,提高了模型泛化性。最后,簽名任務知識的本地化集成可以隨著任務和客戶的增長實現可擴展性,而無需額外的通信成本。大量實驗表明,FedViT 在確保準確性的同時顯著降低了通信開銷,并表現出很強的可擴展性。
研究利用PBFT中的動態視圖變換機制,實現區塊鏈系統高效運轉)
—— 分組、子查詢與窗口函數全攻略)








)






:一個用于兩性關系動力學建模的隨機耦合系統框架)

 一個二叉樹)