課堂筆記:吳恩達的AI課(AI FOR EVERYONE)-W2 AI項目工作流程
一、如何開始一個AI項目?
1、建設項目工作流程
2、選擇合適的AI項目
3、為這個項目收集數據和組織團隊

二、AI項目的工作流程
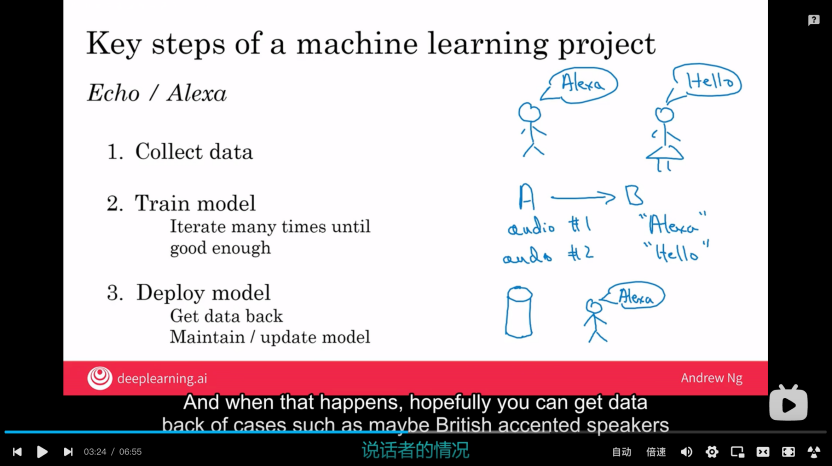
(1)機器學習項目的關鍵步驟:示例1:以亞馬遜的語音助手 Echo/Alexa為例
①收集數據
②訓練模型:迭代這個模型,直到達到足夠好的效果
③部署模型:獲取反饋,持續優化模型
(2)機器學習的關鍵步驟:示例2:以自動駕駛為例
①收集數據:圖片,例如圖片中其他車的位置
②訓練模型:不停地迭代,直到獲取到足夠好的效果
③部署模型:獲取反饋數據,持續優化模型

(3)數據科學項目的關鍵步驟:示例1:優化銷售模式
①收集數據:例如用戶ID,國家,時間和網址等
②分析數據:不停地迭代職高獲得更好的效果
③輸出建議或者行動:實施這些變化,重新分析新的數據

(4)數據科學項目的關鍵步驟:示例2:以工廠手工線體為例
以做咖啡杯為例,不同供應商提供的黏土哪個更好?
①收集數據:例如,加班時間,需要的溫度,灼燒的時間等
②分析數據:不停地迭代直到獲得更好的洞察
③輸出建議或者行動:實施這些變化,重新分析新的數據

三、各職能部門對于數據應用能力的建設
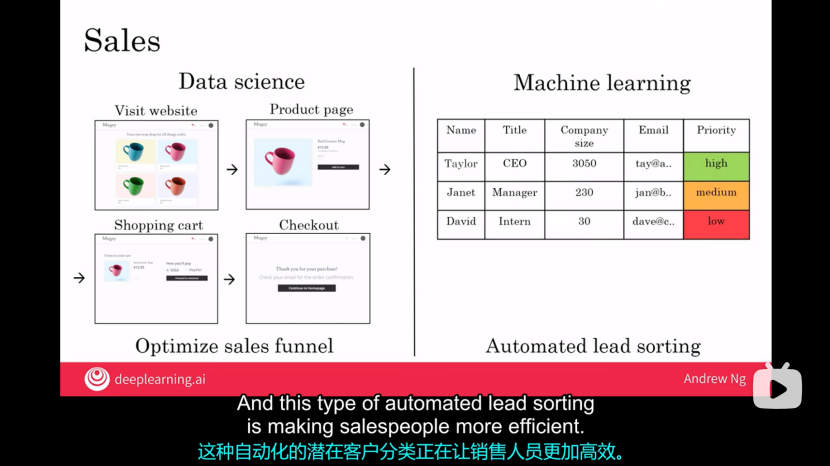
(1)對于銷售來說:
①數據科學:優化銷售數據漏斗;
②機器學習:自動排序客戶優先級;
(2)手工線體管理:
①數據科學:優化線體效率
②機器學習:自動識別優劣品

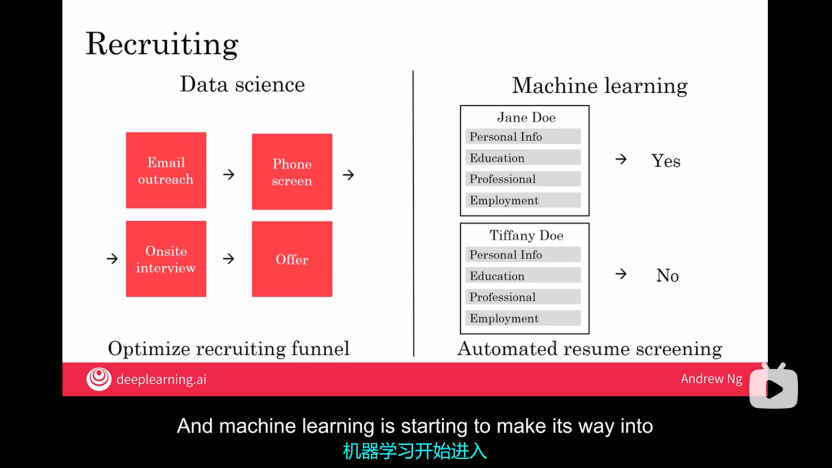
(3)招聘:
①數據科學:優化招聘漏斗;
②機器學習:自動化建立篩選;
(4)市場:
①數據科學:A、B測試;
②機器學習:定制化產品推薦;

(5)農業:
①數據科學:種子分析;
②機器學習:精準除草;

四、如何選擇人工智能項目
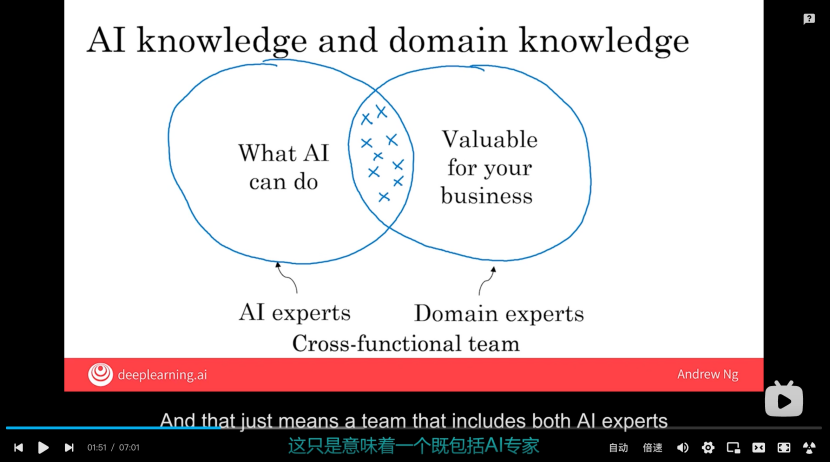
(1)AI知識和領域知識
①AI專家負責知道AI可以做什么;
②領域專家 知道 這個事情的商業價值;
③所以AI項目團隊是跨領域的項目團隊,既要有AI專家,又要有領域專家;
(2)頭腦風暴的框架:
①思考要任務化,而非崗位化,例如呼叫中心的具體任務,或者放射科的具體任務;
②驅動這件事情的最主要的業務價值是什么?
③做這個事情的最大的痛點是什么?

(3)你可以做一些事情,即使沒有大量的數據
①有非常多的數據,這件事沒有害處;
②數據能讓某些業務(比如網頁搜索)具備競爭壁壘。
③但即便只有小數據集,你仍能取得進展。

五、如何選擇人工智能項目2
(1)項目的一些工作側重點
①技術工作側重點:
a.人工智能系統能否達到預期性能;
b.需要多少數據;
c.工程時間安排;
②業務工作側重點:
a.更低的成本
b.增長的收益
c.啟動新的產品或者業務
其中,a和b針對的是現有的業務,c是針對新業務;

(2)自研 還是 外包?
①機器學習項目可以自研或者外包;
②數據科學項目大多數是自研的;
③一些事情已經有了行業標準,那么我們要避免自研這些事情;
一句通俗的話,我們不要在火車前面奔跑;
行業發展十分迅速,我們不應該去對抗,或者一心求著去快速趕超或者制造行業標準,獲取我們擁抱行業標準,才會更快更好的實現價值;

六、人工智能團隊協作機制
(1)明確你的驗收標準:
①目標:以 95% 的準確率檢測缺陷;
②向人工智能團隊提供一個數據集,用于衡量其性能;

(2)AI團隊應該如何看待數據?
①訓練集:用于訓練模型;
②測試集:用于測試模型;

(3)陷阱:期望達到 100% 準確率
① 測試集;
② 機器學習的局限性;
③ 數據不足;
④ 數據標注錯誤;
⑤ 標簽模糊;

七、人工智能團隊技術工具
(1)一些開源框架:
①機器學習框架:
a.PyTorch
b.TensorFlow(張量流 )
c.Hugging Face(擁抱臉,知名機器學習模型庫 )
d.PaddlePaddle(飛槳 )
e.Scikit - learn(科學工具包 - 學習 )
f.R(編程語言 )
②研究出版物平臺:
Arxiv(預印本平臺 ,常用于分享學術研究成果 )
③開源代碼庫:
GitHub

(2)CPU 和 GPU
①CPU:計算機處理器(中央處理單元)
②GPU:圖像處理器
(3)云、本地部署和邊緣部署
①云部署:線上部署代碼,現在的趨勢;
②本地部署:在本地服務器上部署代碼;
③邊緣部署:在各個終端部署代碼,可以更加便捷的獲取終端數據;


















)
)
