1 聚類算法
-
聚類算法:
- 是一種無監督學習算法,它不需要預先知道數據的類別信息,而是根據樣本之間的相似性,將樣本劃分到不同的類別中;
- 不同的相似度計算方法,會得到不同的聚類結果,常用的相似度計算方法有歐式距離法;
- 其目的是在沒有先驗知識的情況下,自動發現數據集中的內在結構和模式;
-
使用不同的聚類準則,產生的聚類結果不同;
-
聚類算法在現實生活中的應用十分廣泛,涵蓋多個領域:
-
商業領域:可用于用戶畫像和廣告推薦,通過分析用戶的行為、偏好等數據,將用戶進行聚類,從而為不同類別的用戶推送更精準的廣告;還能進行基于位置信息的商業推送,根據用戶的地理位置等信息進行分類推送;
-
信息處理領域:可實現新聞聚類和篩選排序,將相似的新聞歸為一類,方便用戶閱讀和篩選;在搜索引擎方面,可用于流量推薦和惡意流量識別,提高搜索結果的質量和安全性;
-
圖像和生物領域:在圖像方面,可進行圖像分割、降維和識別;在生物方面,可用于離群點檢測(如信用卡異常消費檢測)以及發掘相同功能的基因片段等;
-
-
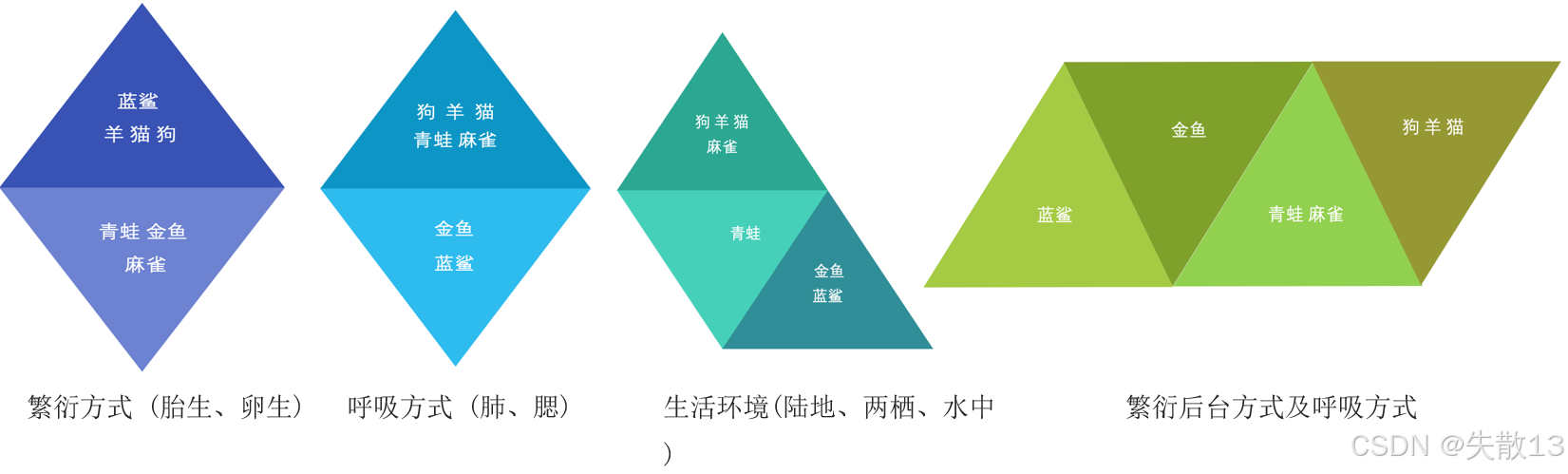
聚類算法主要有以下兩種分類方式:
-
根據聚類顆粒度分類:
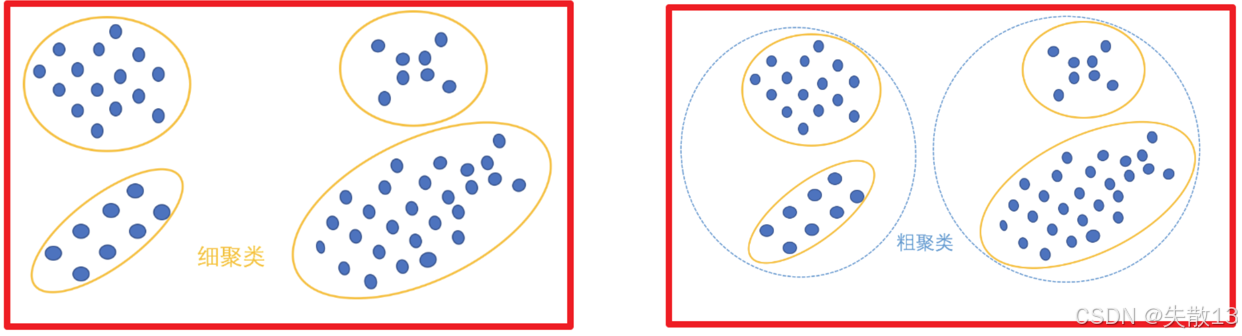
- 細聚類:將數據劃分成更細致的類別,每個類別包含的數據點相對較少且更具針對性
- 粗聚類:將數據劃分成較粗的類別,每個類別包含的數據點相對較多,概括性更強
-
根據實現方法分類:
- K-means:按照質心分類,是一種通用且普遍使用的聚類算法
- 層次聚類:對數據進行逐層劃分,直到達到聚類的類別個數
- DBSCAN聚類:是一種基于密度的聚類算法,能夠發現任意形狀的聚類
- 譜聚類:是一種基于圖論的聚類算法,通過構建樣本的相似性矩陣,將聚類問題轉化為圖的劃分問題
-
2 API&Kmeans算法
-
API:
sklearn.cluster.KMeans(n_clusters=8)- 參數:
n_clusters,整型,缺省值為 8,用于指定開始的聚類中心數量,即最終生成的聚類數,也就是產生的質心(centroids)數; - 方法:
estimator.fit(x):用于對數據x進行訓練,計算聚類中心;estimator.predict(x):用于預測數據x中每個樣本所屬的類別;estimator.fit_predict(x):該方法的作用是計算聚類中心并預測每個樣本屬于哪個類別,相當于先調用fit(x),然后再調用predict(x);
- 參數:
-
例:隨機創建不同二維數據集作為訓練集,并結合k-means算法將其聚類,嘗試分別聚類不同數量的簇,并觀察聚類效果
-
導包:
# 0.導包 from sklearn.datasets import make_blobs import matplotlib.pyplot as plt from sklearn.cluster import KMeans # 導入KMeans聚類算法 from sklearn.metrics import silhouette_score # 導入輪廓系數評估指標 -
構建數據集:
# 1.構建數據集 # 使用make_blobs生成4個聚類中心的二維數據 x,y=make_blobs(n_samples=1000, # 生成1000個樣本點n_features=2, # 每個樣本有2個特征(便于可視化)centers=[[-1,-1],[4,4],[8,8],[2,2,]], # 指定4個聚類中心的坐標cluster_std=[0.4,0.2,0.3,0.2] # 指定每個聚類的標準差(數據離散程度)) plt.figure() # 繪制散點圖,x[:,0]為第一特征,x[:,1]為第二特征 plt.scatter(x[:,0],x[:,1]) plt.show()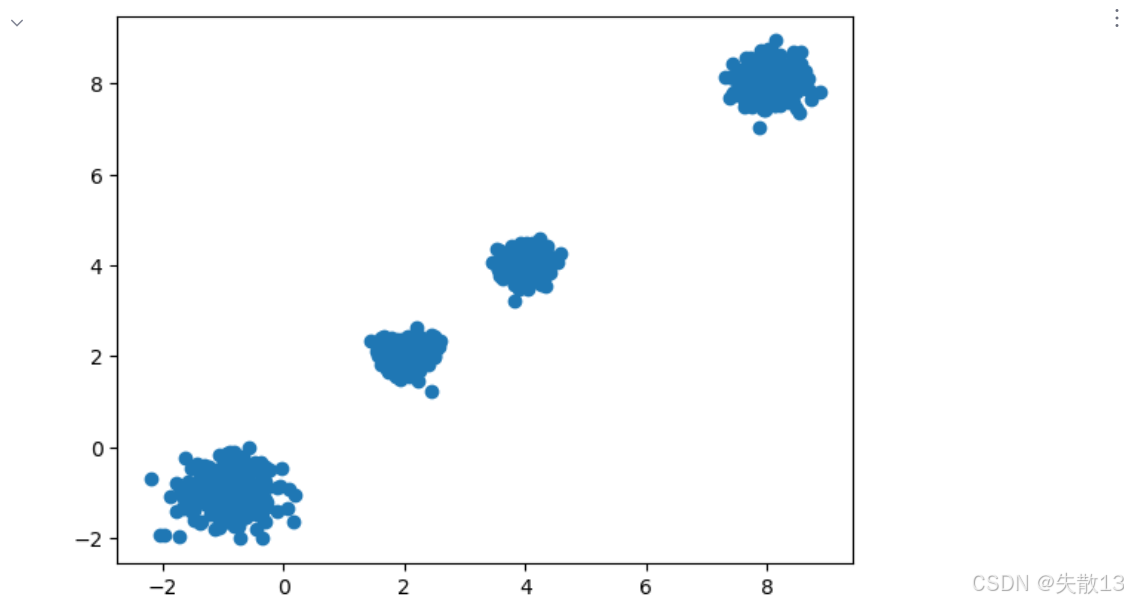
-
模型訓練預測:
# 2.模型訓練預測 # 創建KMeans模型實例,指定聚類數量為4(與我們生成數據時的中心數一致) model=KMeans(n_clusters=4) # 訓練模型并對數據進行預測,返回每個樣本的聚類標簽 # fit_predict()等價于先調用fit()訓練模型,再調用predict()預測標簽 y_prd=model.fit_predict(x)plt.figure() # 按預測的聚類標簽著色繪制散點圖,不同聚類會顯示不同顏色 plt.scatter(x[:,0],x[:,1],c=y_prd) plt.show()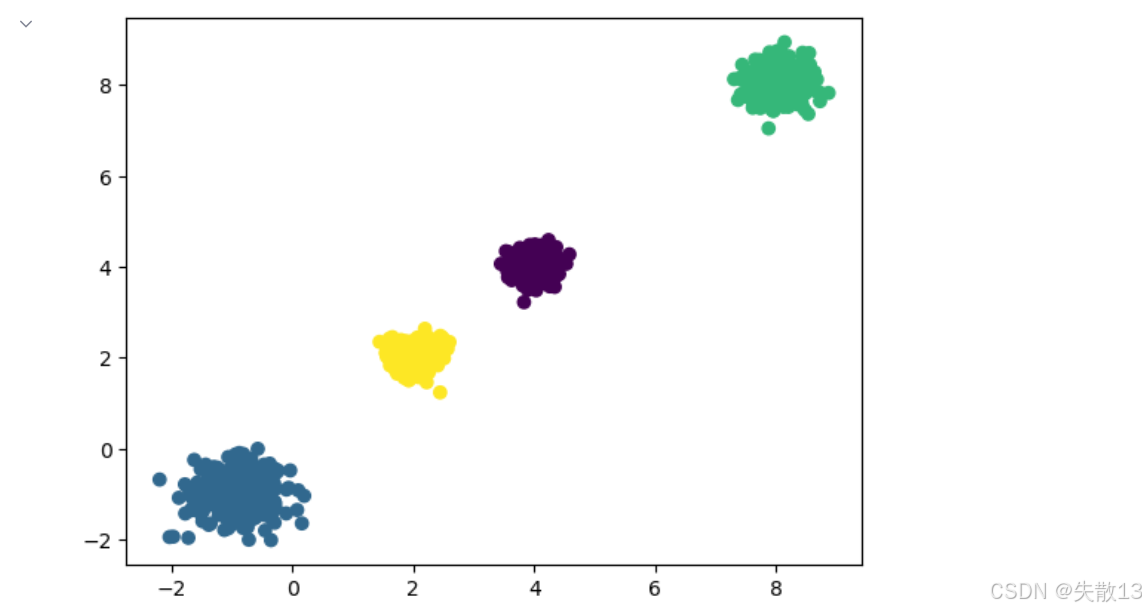
-
模型評估:
# 3.評估 # 使用輪廓系數(silhouette_score)評估聚類效果 # 輪廓系數取值范圍為[-1,1],越接近1表示聚類效果越好 # 輸入參數為原始數據x和預測的聚類標簽y_prd print(silhouette_score(x,y_prd))
-
3 Kmeans實現流程
3.1 概述
-
KMeans算法的實現主要分為以下幾個步驟:
- 確定聚類數K:首先需要事先確定常數K,K表示最終想要得到的聚類類別數;
- 選擇初始聚類中心:隨機從數據集中選擇K個樣本點,將它們作為初始的聚類中心;
- 分配樣本到最近聚類:計算每個樣本到這K個聚類中心的距離,然后將每個樣本分配到距離最近的那個聚類中心所對應的類別中;
- 更新聚類中心并迭代:根據每個類別中的所有樣本點,重新計算該類別的新聚類中心點(通常是該類別所有樣本點的均值)。如果新計算出的聚類中心點與原來的聚類中心點相同,那么聚類過程停止;否則,重新進行步驟2和步驟3,直到聚類中心不再發生變化為止;
-
下面通過圖形化的方式展示KMeans算法的迭代過程:
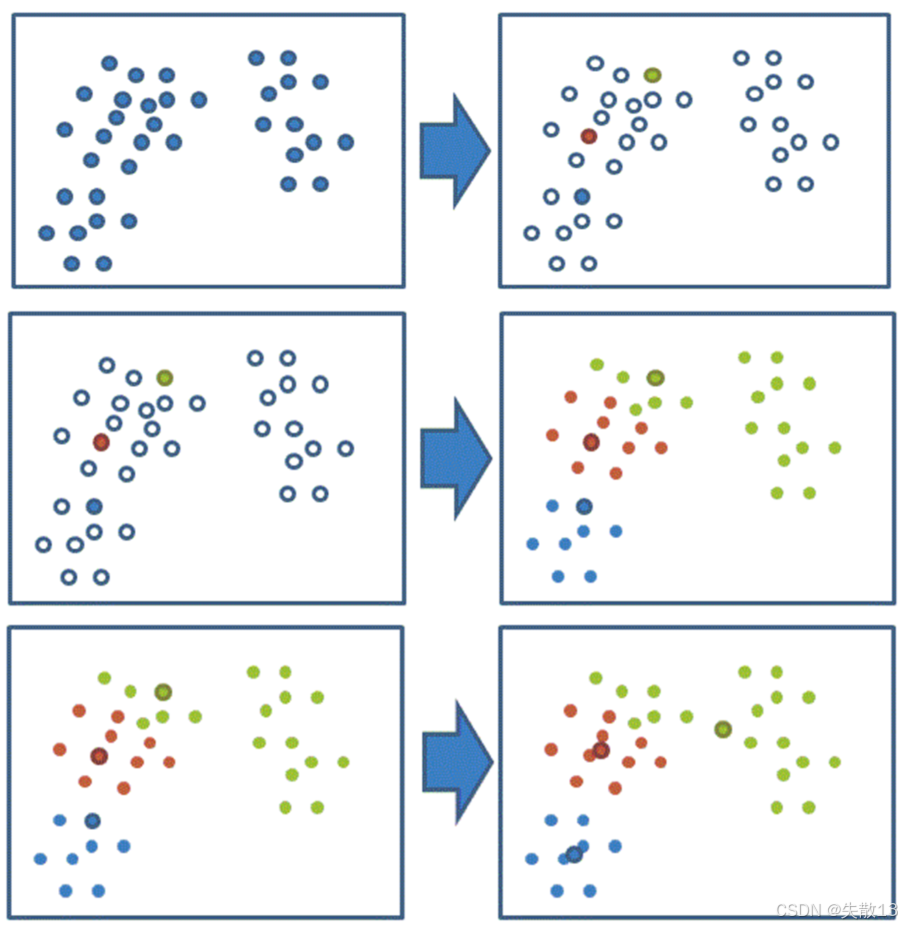
-
初始狀態:首先隨機選擇了兩個初始聚類中心(圖中可能用不同顏色或標記表示)
-
第一次迭代:根據初始聚類中心,將數據點分配到最近的聚類中心,形成兩個初始的聚類
-
后續迭代:重新計算每個聚類的中心點,然后再次將數據點分配到新的聚類中心,不斷重復這個過程
-
收斂狀態:經過多次迭代后,聚類中心不再發生明顯變化,算法收斂,得到最終的聚類結果
-
3.2 例
-
數據準備:已知數據集如下,包含 15 個數據點(P1 - P15),每個數據點有兩個特征(X 值和 Y 值)。這些數據點將作為輸入,用于后續的 KMeans 聚類過程;
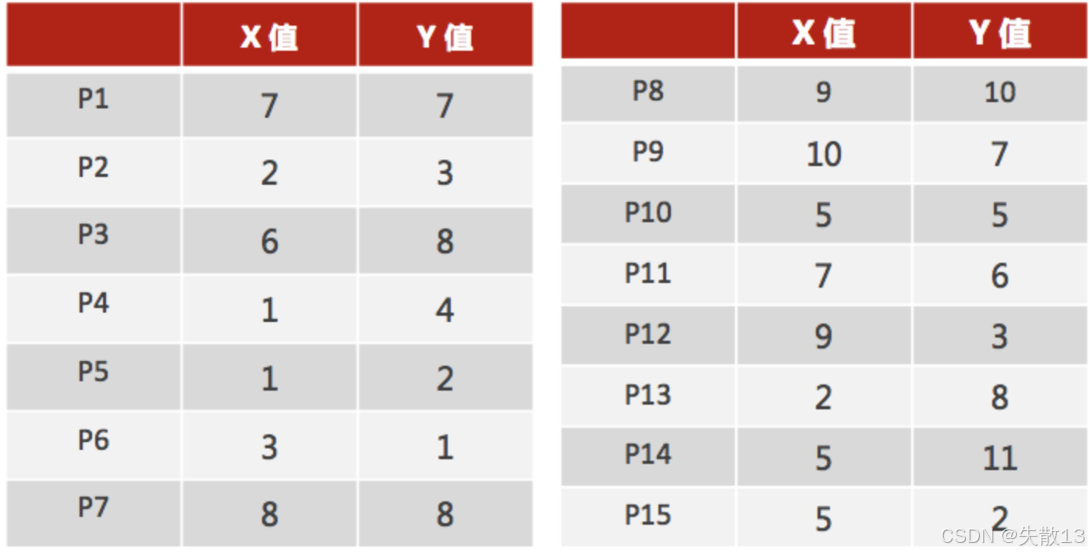
-
選擇初始聚類中心
-
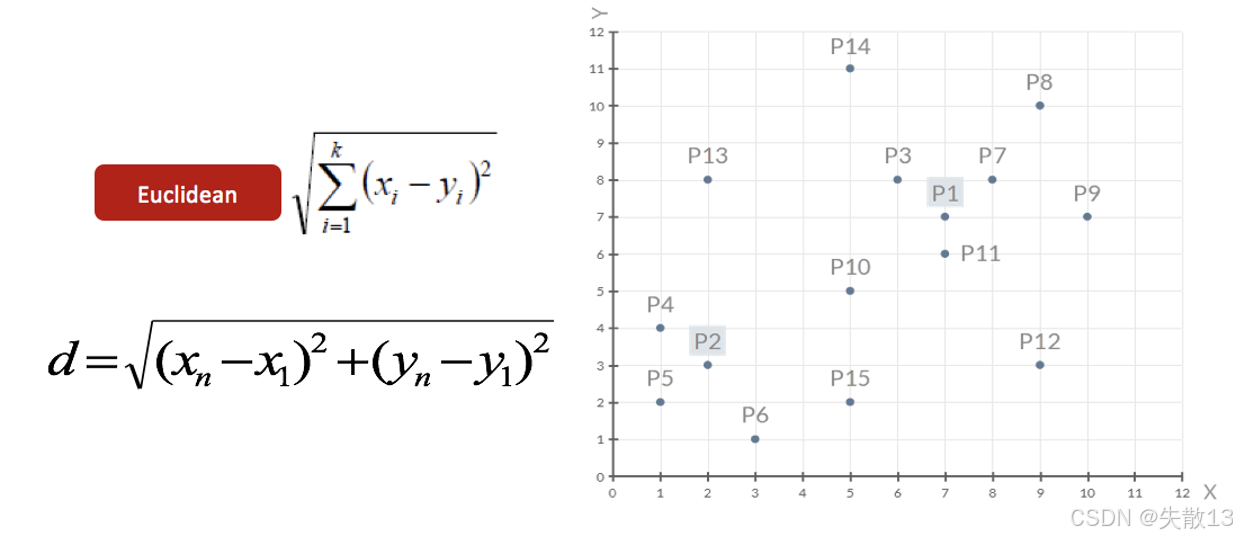
選擇初始聚類中心:在這個例子中,隨機選擇了兩個數據點 P1(7, 7)和 P2(2, 3)作為初始的聚類中心;
-
距離計算公式:使用歐幾里得距離(Euclidean distance)來計算數據點之間的距離。公式為:
d=∑i=1k(xi?yi)2 d=\sqrt{\sum_{i = 1}^{k}(x_i - y_i)^2} d=i=1∑k?(xi??yi?)2? -
對于二維數據,公式可以簡化為:
d=(xn?x1)2+(yn?y1)2 d=\sqrt{(x_n - x_1)^2+(y_n - y_1)^2} d=(xn??x1?)2+(yn??y1?)2?- 其中,(xn,yn)(x_n, y_n)(xn?,yn?) 和 (x1,y1)(x_1, y_1)(x1?,y1?) 分別是兩個數據點的坐標;
-
數據點分布:下圖展示了所有數據點在二維平面上的分布情況,其中 P1 和 P2 被標記為初始聚類中心
-
-
分配樣本到最近聚類
-
計算距離并分配類別:對于每個數據點,計算其到兩個初始聚類中心(P1 和 P2)的距離,并將數據點分配到距離較近的聚類中心所在的類別。例如:
- P3 到 P1 的距離為 1.41,到 P2 的距離為 6.40,所以 P3 被分配到 P1 所在的類別;
- P4 到 P1 的距離為 6.71,到 P2 的距離為 1.41,所以 P4 被分配到 P2 所在的類別;
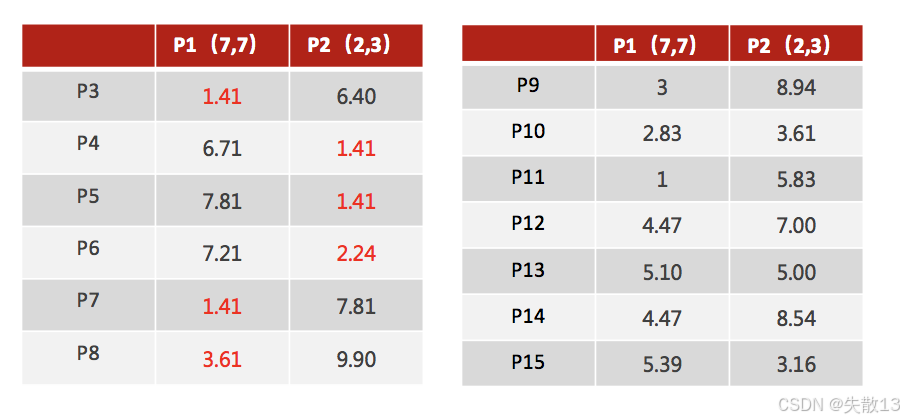
-
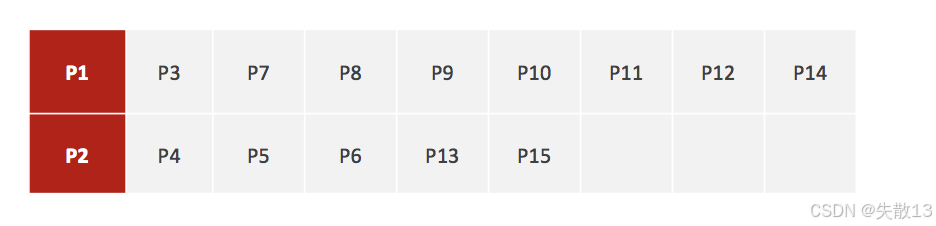
聚類結果:經過計算和分配,得到了兩個初始的聚類,分別以 P1 和 P2 為中心。其中:
- P1 所在的聚類包含 P3、P7、P8、P9、P10、P11、P12、P14;
- P2 所在的聚類包含 P4、P5、P6、P13、P15;
-
-
更新聚類中心
-
重新計算聚類中心:根據上一步得到的兩個聚類,重新計算每個聚類的新中心。新中心的計算方法是該聚類中所有數據點的 X 值和 Y 值的平均值;
- 對于 P1 所在的聚類,新中心 P1′P_1'P1′? 的 X 值為 (7+6+8+9+5+7+9+5)/8=7.3(7 + 6 + 8 + 9 + 5 + 7 + 9 + 5) / 8 = 7.3(7+6+8+9+5+7+9+5)/8=7.3,Y 值為 (7+8+8+10+5+6+3+11)/8=7.2(7 + 8 + 8 + 10 + 5 + 6 + 3 + 11) / 8 = 7.2(7+8+8+10+5+6+3+11)/8=7.2,即 P1′=(7.3,7.2)P_1' = (7.3, 7.2)P1′?=(7.3,7.2);
- 對于 P2 所在的聚類,新中心 P2′P_2'P2′? 的 X 值為 (2+1+1+3+2+5)/6=1.8(2 + 1 + 1 + 3 + 2 + 5) / 6 = 1.8(2+1+1+3+2+5)/6=1.8,Y 值為 (3+4+2+1+8+2)/6=4.6(3 + 4 + 2 + 1 + 8 + 2) / 6 = 4.6(3+4+2+1+8+2)/6=4.6,即 P2′=(1.8,4.6)P_2' = (1.8, 4.6)P2′?=(1.8,4.6);
-
數據點分布:圖中展示了更新后的聚類中心 P1′P_1'P1′? 和 P2′P_2'P2′? 在二維平面上的位置;
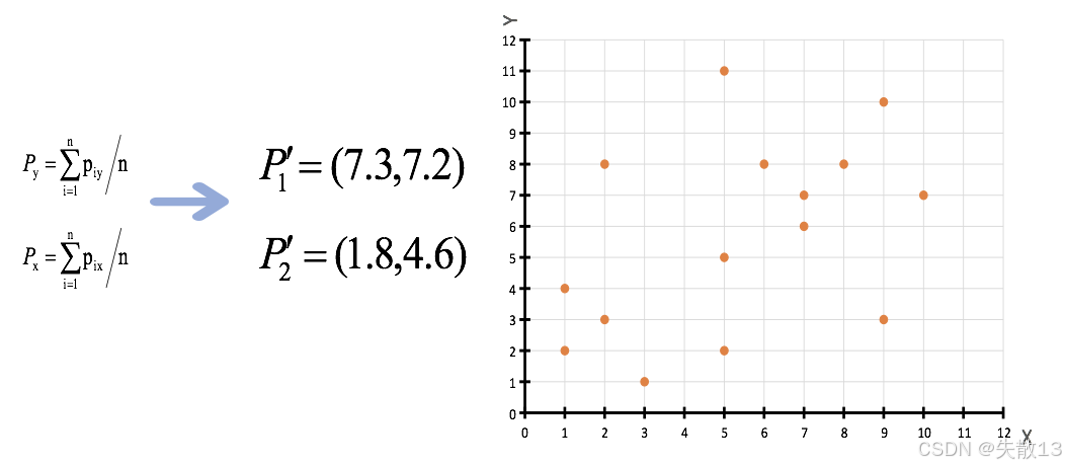
-
-
判斷是否收斂
-
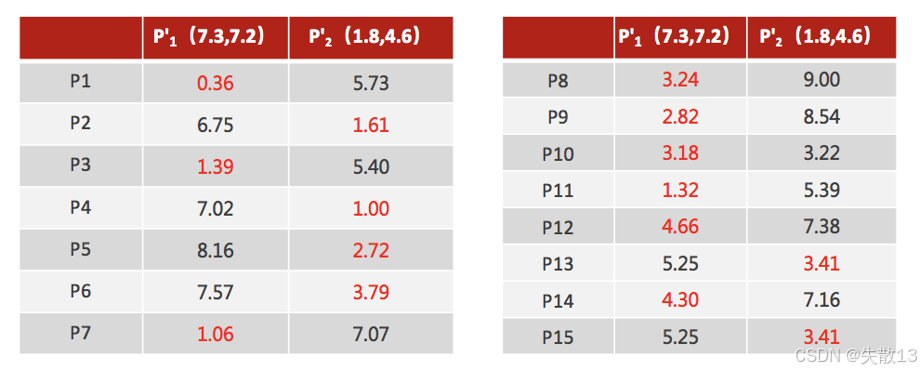
計算新距離并重新分配類別:使用更新后的聚類中心 P1′P_1'P1′? 和 P2′P_2'P2′?,再次計算每個數據點到這兩個中心的距離,并重新分配類別。例如:
- P1 到 P1′P_1'P1′? 的距離為 0.36,到 P2′P_2'P2′? 的距離為 5.73,所以 P1 被分配到 P1′P_1'P1′? 所在的類別;
- P2 到 P1′P_1'P1′? 的距離為 6.75,到 P2′P_2'P2′? 的距離為 1.61,所以 P2 被分配到 P2′P_2'P2′? 所在的類別;

-
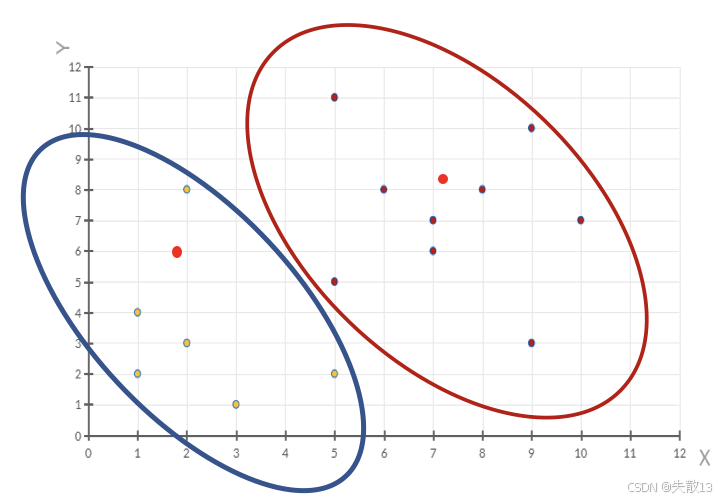
判斷是否收斂:
- 比較新的聚類中心與原來的聚類中心,如果新的聚類中心與原來的聚類中心相同(質心不再移動),則聚類過程結束;
- 否則,需要重新進行第二步和第三步,直到聚類中心不再發生變化為止;
- 在這個例子中,經過判斷,新的聚類中心與原來的聚類中心不同,所以需要重復上述步驟,開始新一輪迭代;
-
4 模型評估方法
4.1 SSE聚類評估指標
-
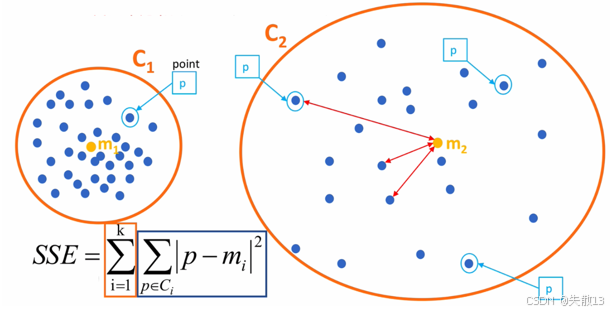
誤差平方和SSE(The sum of squares due to error)。SSE公式:
SSE=∑i=1k∑p∈Ci∣p?mi∣2 SSE = \sum_{i = 1}^{k}\sum_{p \in C_i} |p - m_i|^2 SSE=i=1∑k?p∈Ci?∑?∣p?mi?∣2- 其中:CiC_iCi? 表示簇、kkk 表示聚類中心的個數、ppp 表示某個簇內的樣本、mmm 表示質心點
-
含義:
- SSE 越小,表示數據點越接近它們的中心,聚類效果越好;
- 下圖通過兩個簇 C1C_1C1? 和 C2C_2C2? 的示例,展示了 SSE 的計算方式,即每個數據點到其所在簇質心的距離的平方和;
-
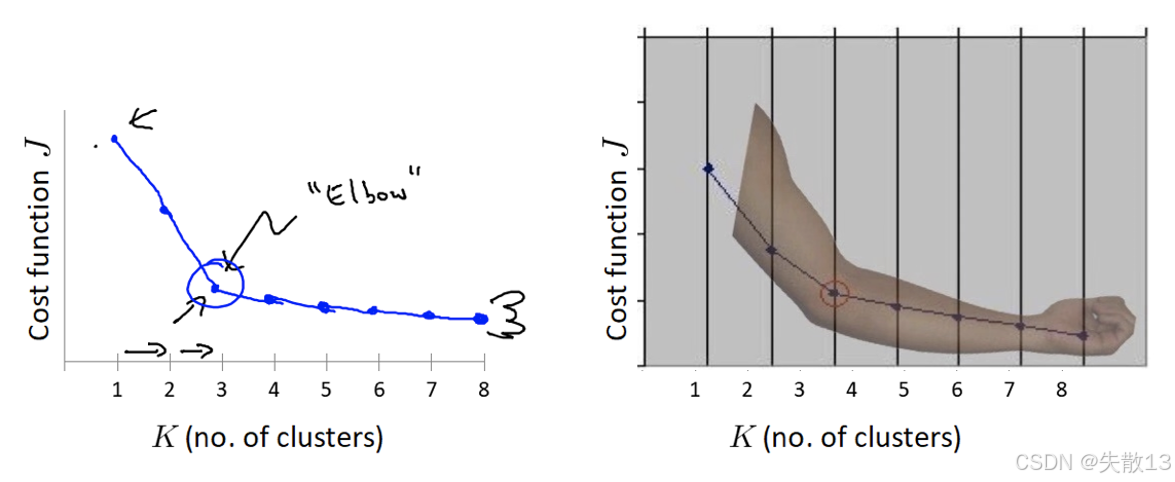
**“肘”方法(Elbow method)**通過 SSE 確定聚類數 n_clustersn\_clustersn_clusters 的值。步驟:
- 對于有 nnn 個點的數據集,迭代計算 kkk 從 1 到 nnn,每次聚類完成后計算 SSE
- SSE 會逐漸變小,因為每個點都是它所在簇中心本身
- SSE 變化過程中會出現一個拐點,當下降率突然變緩時,此時的 kkk 即為最佳的 n_clustersn\_clustersn_clusters 值
- 在決定什么時候停止訓練時,肘形判據同樣有效,數據通常有更多的噪音,在增加分類無法帶來更多回報時,停止增加類別
-
圖示:左側的圖展示了隨著 kkk 的增加,SSE 的變化曲線,其中的拐點(“Elbow”)即為最佳的 kkk 值;右側的圖通過手臂的形狀形象地展示了肘形判據的概念;
4.2 SC聚類評估指標
-
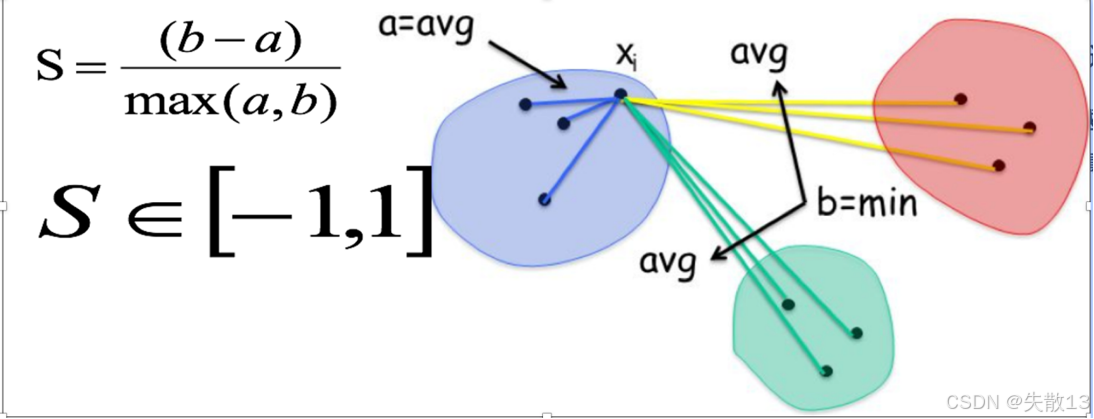
SC輪廓系數法(Silhouette Coefficient)的考慮因素:輪廓系數法考慮簇內的內聚程度(Cohesion)和簇外的分離程度(Separation);
-
計算過程:
- 計算每一個樣本 iii 到同簇內其他樣本的平均距離 aia_iai?,該值越小,說明簇內的相似程度越大;
- 計算每一個樣本 iii 到最近簇 jjj 內的所有樣本的平均距離 bijb_{ij}bij?,該值越大,說明該樣本越不屬于其他簇 jjj;
- 根據公式 S=b?amax(a,b)S = \frac{b - a}{max(a, b)}S=max(a,b)b?a? 計算該樣本的輪廓系數;
- 計算所有樣本的平均輪廓系數;
-
取值范圍:輪廓系數的范圍為 [?1,1][-1, 1][?1,1],SC 值越大聚類效果越好;
-
圖示:圖中展示了樣本 xix_ixi? 到同簇內其他樣本的平均距離 aaa 和到最近簇內所有樣本的平均距離 bbb,并通過公式計算輪廓系數;
4.3 CH聚類評估指標
-
考慮因素:CH 系數(Calinski-Harabasz Index)考慮簇內的內聚程度、簇外的離散程度以及質心的個數。
-
公式:
CH(k)=SSBSSW?m?kk?1 CH(k) = \frac{SSB}{SSW} \cdot \frac{m - k}{k - 1} CH(k)=SSWSSB??k?1m?k?- 其中:
-
SSW=∑i=1m∥xi?Cpi∥2SSW = \sum_{i = 1}^{m} \|x_i - C_{pi}\|^2SSW=∑i=1m?∥xi??Cpi?∥2,相當于 SSE,是簇內距離,表示簇內的內聚程度,越小越好。CpiC_{pi}Cpi? 表示質心,xix_ixi? 表示某個樣本;
-
SSB=∑j=1knj∥Cj?Xˉ∥2SSB = \sum_{j = 1}^{k} n_j \|C_j - \bar{X}\|^2SSB=∑j=1k?nj?∥Cj??Xˉ∥2,是簇間距離,表示簇與簇之間的分離程度,越大越好。CjC_jCj? 表示質心,Xˉ\bar{X}Xˉ 表示質心與質心之間的中心點,njn_jnj? 表示樣本的個數;
-
mmm 表示樣本數量,kkk 表示質心個數;
-
- 其中:
-
評估標準:類別內部數據的距離平方和越小越好,類別之間的距離平方和越大越好,聚類的種類數越少越好。
4.4 代碼
-
導包:
# 0.導包 import os # 設置OpenMP線程數為1,避免多線程沖突(某些環境下KMeans可能出現的警告) os.environ["OMP_NUM_THREADS"]="1" from sklearn.datasets import make_blobs # 用于生成模擬聚類數據 import matplotlib.pyplot as plt from sklearn.cluster import KMeans # 導入KMeans聚類算法 # 導入兩種聚類評估指標:Calinski-Harabasz指數和輪廓系數 from sklearn.metrics import calinski_harabasz_score,silhouette_score -
構建數據集:
# 1.構建數據集 # 生成1000個樣本的二維數據,包含4個真實聚類中心 # centers參數指定真實聚類中心坐標,cluster_std指定每個聚類的標準差(數據離散程度) x,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[4,4],[8,8],[2,2,]],cluster_std=[0.4,0.2,0.3,0.2]) -
使用肘部法確定最佳k值:
# 使用肘部法(Elbow Method)確定最佳k值 # 存儲不同k值對應的SSE(誤差平方和) temp_list = [] # 迭代測試k從1到99的情況 for k in range(1,100):# 創建KMeans模型,n_clusters=k表示聚類數為k,n_init='auto'自動選擇初始中心數量model = KMeans(n_clusters=k, n_init='auto')model.fit(x) # 訓練模型# 將當前k值對應的SSE(模型的inertia_屬性)添加到列表# SSE是所有樣本到其所屬聚類中心的距離平方和temp_list.append(model.inertia_)# 繪制肘部法圖像 plt.figure() # 創建圖形對象 plt.grid() # 添加網格線,便于觀察 # 繪制k值(2到99)與對應SSE的關系曲線,紅色圓點連線 plt.plot(range(2,100), temp_list[1:], 'or-') # temp_list[1:]跳過k=1的情況 plt.xlabel('k (Number of clusters)') # x軸標簽:聚類數量k plt.ylabel('SSE (Sum of Squared Errors)') # y軸標簽:誤差平方和 plt.title('Elbow Method for Optimal k') # 圖表標題 plt.show() # 顯示圖像 # 肘部法原理:尋找SSE下降速率明顯減緩的"拐點",該點對應的k即為較優值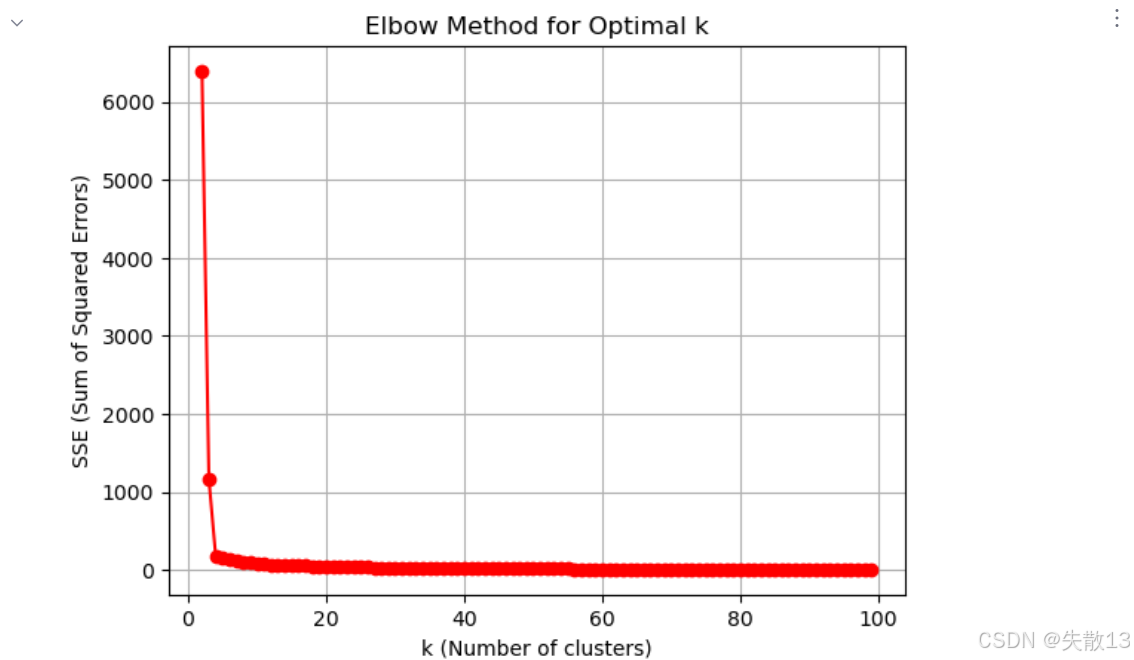
-
使用輪廓系數(Silhouette Coefficient)評估不同k值的聚類效果
# 使用輪廓系數(Silhouette Coefficient)評估不同k值的聚類效果 # 重置存儲列表 temp_list = [] # 迭代測試k從2到99的情況(輪廓系數不適用于k=1) for k in range(2,100):model = KMeans(n_clusters=k, n_init='auto') # 創建模型model.fit(x) # 訓練模型y_pred = model.predict(x) # 預測聚類標簽# 計算輪廓系數并添加到列表,值越接近1表示聚類效果越好temp_list.append(silhouette_score(x, y_pred))# 繪制輪廓系數圖像 plt.figure() plt.grid() # 繪制k值與對應輪廓系數的關系曲線 plt.plot(range(2,100), temp_list, 'or-') plt.xlabel('k (Number of clusters)') plt.ylabel('Silhouette Coefficient') # 輪廓系數 plt.title('Silhouette Method for Optimal k') plt.show()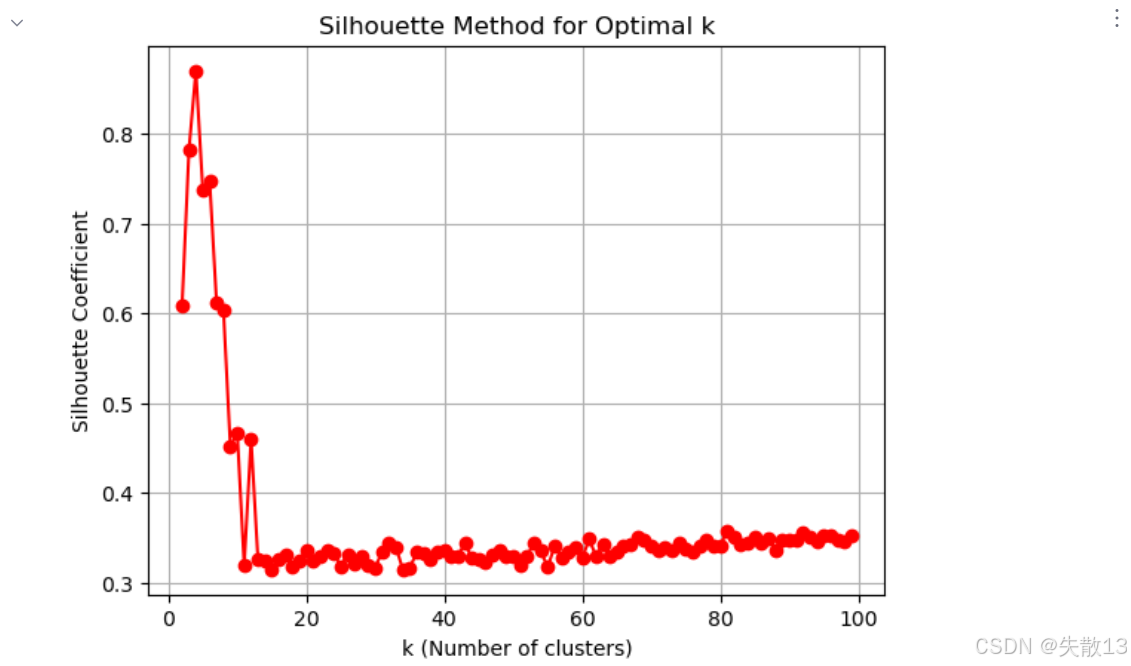
-
使用Calinski-Harabasz指數評估不同k值的聚類效果
# 使用Calinski-Harabasz指數評估不同k值的聚類效果 # 重置存儲列表 temp_list = [] # 迭代測試k從2到99的情況 for k in range(2,100):model = KMeans(n_clusters=k, n_init='auto')model.fit(x)y_pred = model.predict(x)# 計算CH指數并添加到列表,值越大表示聚類效果越好temp_list.append(calinski_harabasz_score(x, y_pred))# 繪制CH指數圖像 plt.figure() plt.grid() # 繪制k值與對應CH指數的關系曲線 plt.plot(range(2,100), temp_list, 'or-') plt.xlabel('k (Number of clusters)') plt.ylabel('Calinski-Harabasz Score') # CH指數 plt.title('Calinski-Harabasz Method for Optimal k') plt.show()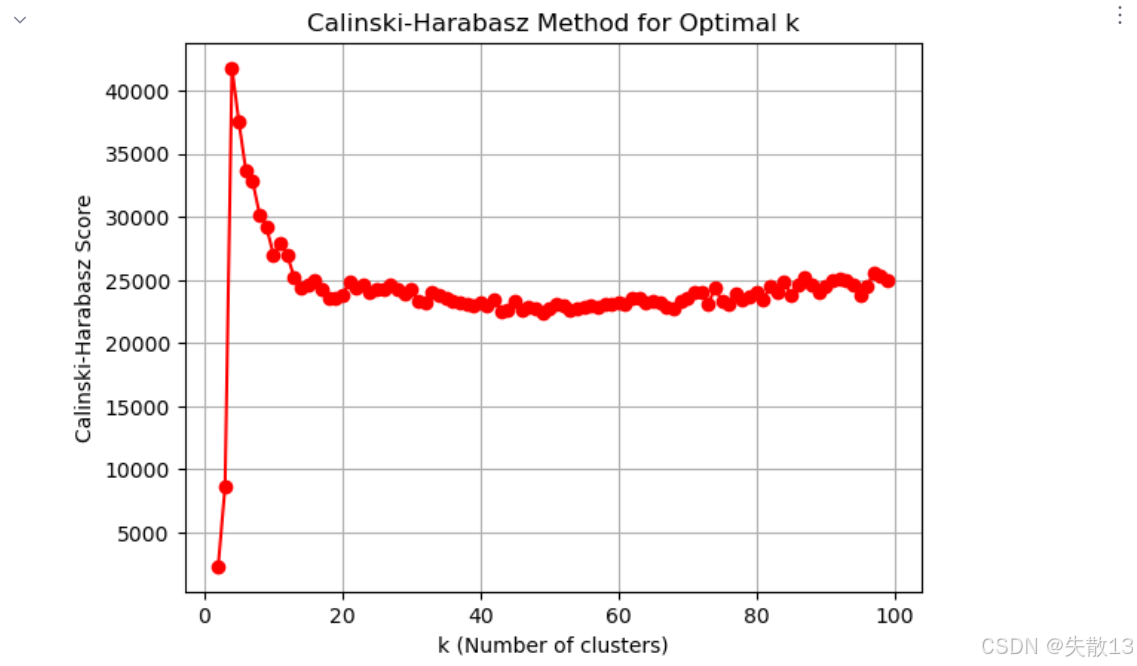
4.5 小結
- 誤差平方和SSE:
- 誤差平方和的值越小越好
- 主要考量:簇內聚程度
- 肘部法:下降率突然變緩時即認為是最佳的k值
- SC系數:
- 取值為[-1, 1],其值越大越好
- 主要考量:簇內聚程度、簇間分離程度
- CH系數:
- 分數s高則聚類效果越好
- CH達到的目的:用盡量少的類別聚類盡量多的樣本,同時獲得較好的聚類效果
- 主要考量:簇內聚程度、簇間分離程度、質心個數
5 案例:顧客數據聚類分析
-
已知:客戶性別、年齡、年收入、消費指數
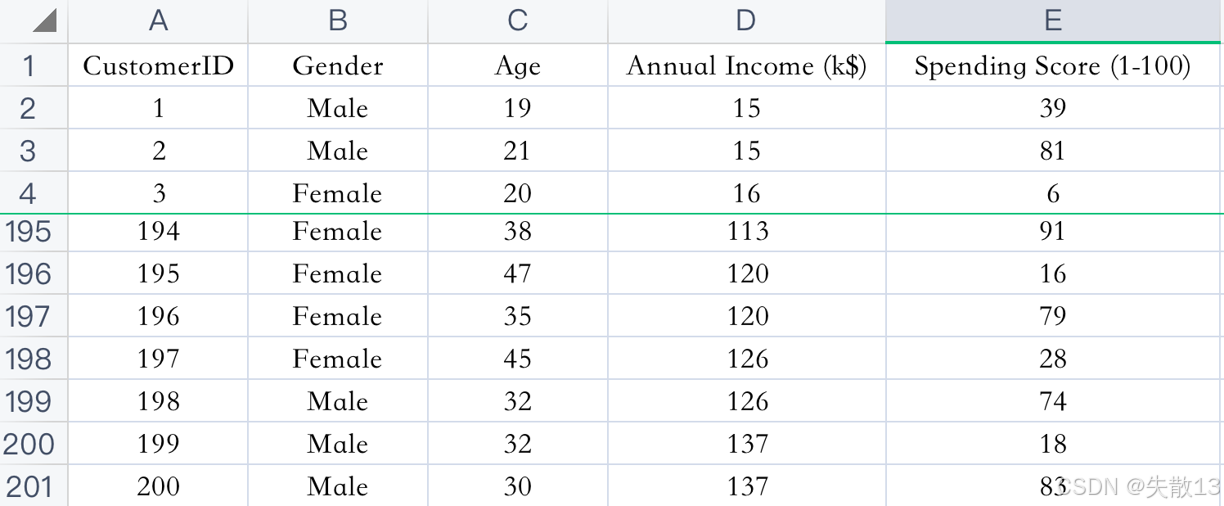
-
需求:對客戶進行分析,找到業務突破口,尋找黃金客戶
-
導包:
import pandas as pd from sklearn.cluster import KMeans import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常顯示漢字 plt.rcParams['axes.unicode_minus'] = False # 正常顯示負號 from sklearn.metrics import silhouette_score -
加載數據:
# 1.加載數據 data =pd.read_csv('data/customers.csv') print(data.head()) -
特征選擇:
# 2.特征選擇 # 選擇數據中的所有行,第4列和第5列作為聚類特征 x =data.iloc[:,[3,4]] print(x)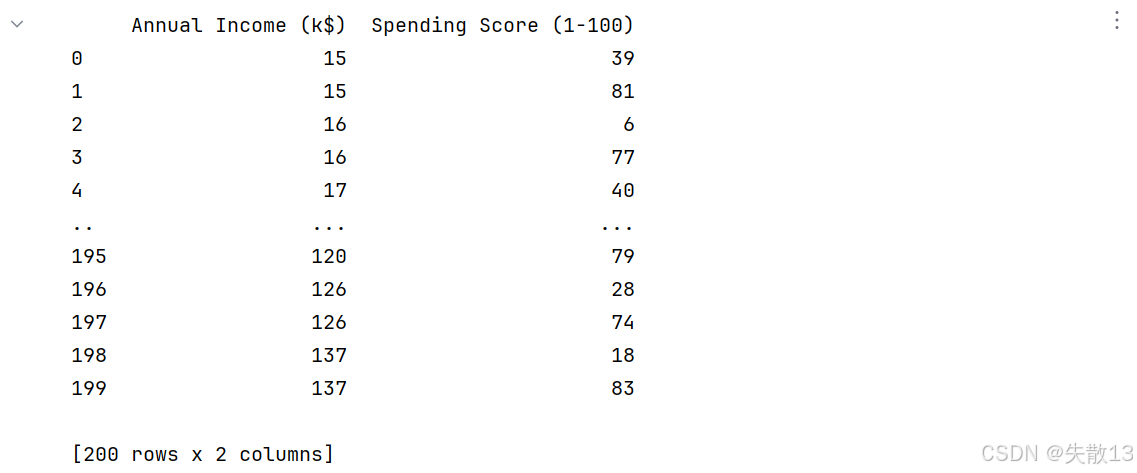
-
模型訓練與優化——K值的選擇(確定最佳聚類位置)
# 3. 模型訓練與優化 # 3.1 K值的選擇(確定最佳聚類數量) # 存儲不同K值對應的SSE(誤差平方和) sse_list = [] # 存儲不同K值對應的輪廓系數 sc_list = []# 測試K值從2到19的情況(聚類數通常不會太大,20以內較為常見) for i in range(2, 20):# 創建KMeans模型,設置聚類數為imodel = KMeans(n_clusters=i, n_init='auto') # 添加n_init='auto'避免警告# 使用選擇的特征數據訓練模型model.fit(x)# 獲取當前K值對應的SSE(模型的inertia_屬性)sse = model.inertia_sse_list.append(sse)# 預測每個樣本的聚類標簽y_pred = model.predict(x)# 計算當前K值對應的輪廓系數,評估聚類效果sc_list.append(silhouette_score(x, y_pred)) -
繪制SSE隨K值變化的曲線(肘部法)
# 繪制SSE隨K值變化的曲線(肘部法) plt.figure(figsize=(10, 6)) plt.grid(True, linestyle='--', alpha=0.7) plt.plot(range(2, 20), sse_list, 'or-', markersize=8, linewidth=2) plt.xlabel('K值(聚類數量)', fontsize=12) plt.ylabel('SSE(誤差平方和)', fontsize=12) plt.title('肘部法確定最佳K值', fontsize=14) plt.show()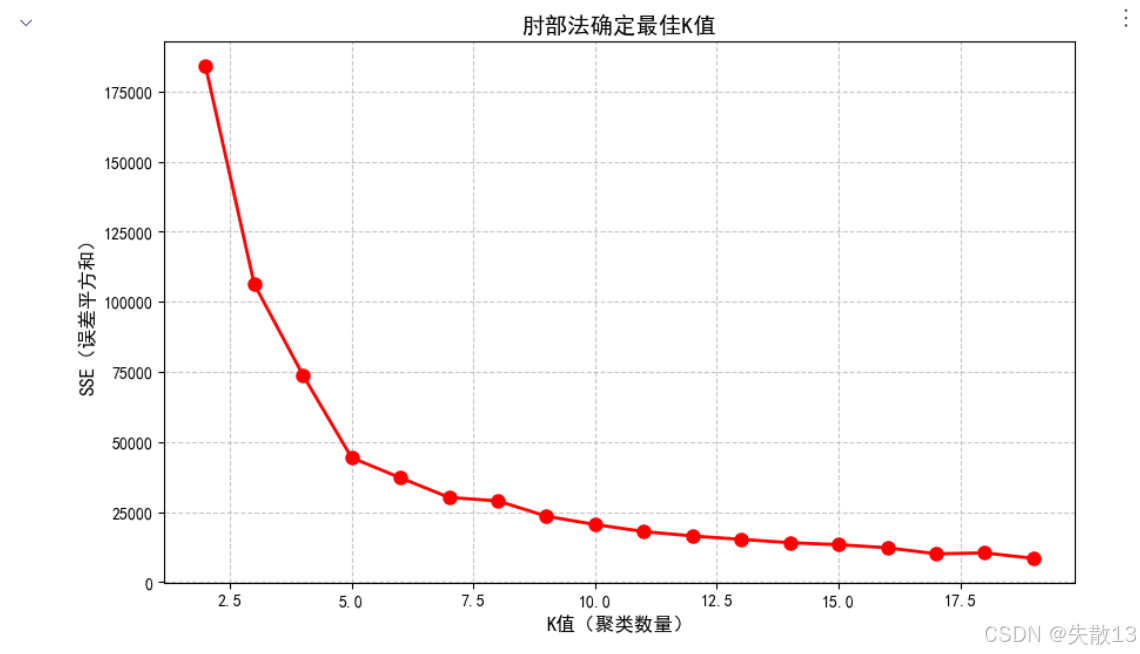
-
繪制輪廓系數隨K值變化的曲線
# 繪制輪廓系數隨K值變化的曲線 plt.figure(figsize=(10, 6)) plt.grid(True, linestyle='--', alpha=0.7) plt.plot(range(2, 20), sc_list, 'ob-', markersize=8, linewidth=2) plt.xlabel('K值(聚類數量)', fontsize=12) plt.ylabel('輪廓系數', fontsize=12) plt.title('輪廓系數法確定最佳K值', fontsize=14) plt.show()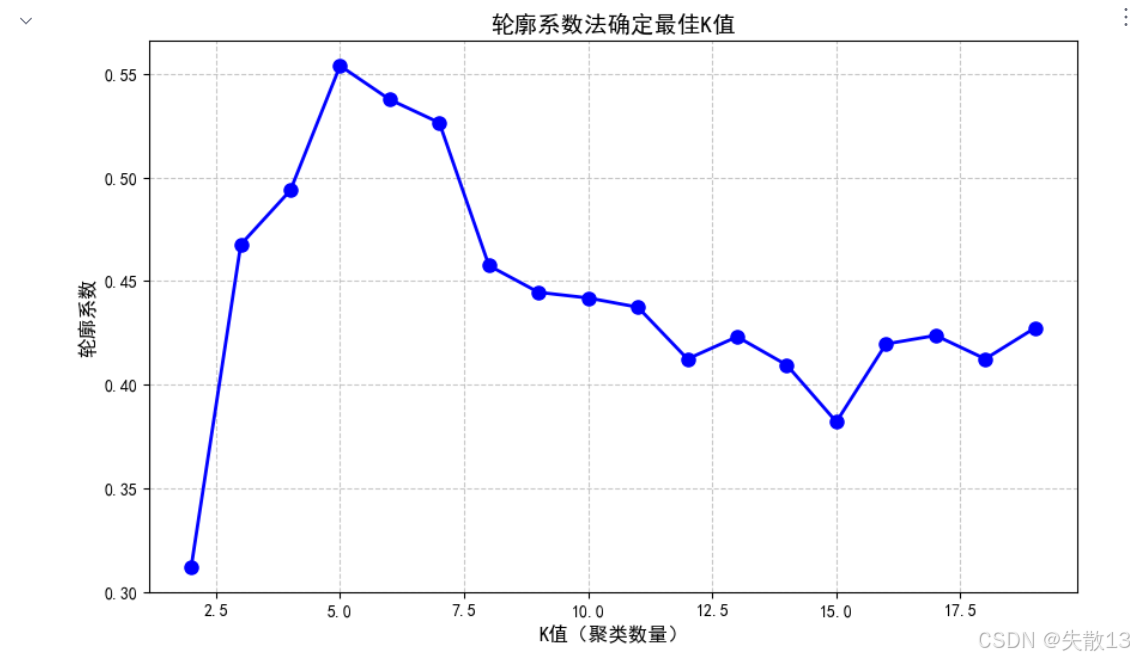
-
根據上述分析結果,選擇K=5進行最終聚類
# 3.2 根據上述分析結果,選擇K=5進行最終聚類 model = KMeans(n_clusters=5, n_init='auto') # 實例化模型,設置聚類數為5 model.fit(x) # 訓練模型 y_pred = model.predict(x) # 預測每個客戶的聚類標簽 print("聚類結果標簽:", y_pred) # 打印聚類標簽 print("各聚類中心坐標:\n", model.cluster_centers_) # 打印每個聚類的中心(質心)
-
聚類結果可視化
# 4. 聚類結果可視化 plt.figure(figsize=(10, 8))# 分別繪制每個聚類的散點,使用不同顏色區分 plt.scatter(x.values[y_pred == 0, 0], x.values[y_pred == 0, 1], c='r', label='客戶群1', alpha=0.7) plt.scatter(x.values[y_pred == 1, 0], x.values[y_pred == 1, 1], c='b', label='客戶群2', alpha=0.7) plt.scatter(x.values[y_pred == 2, 0], x.values[y_pred == 2, 1], c='y', label='客戶群3', alpha=0.7) plt.scatter(x.values[y_pred == 3, 0], x.values[y_pred == 3, 1], c='g', label='客戶群4', alpha=0.7) plt.scatter(x.values[y_pred == 4, 0], x.values[y_pred == 4, 1], c='gray', label='客戶群5', alpha=0.7)# 繪制各聚類的中心(用黑色星號標記) plt.scatter(model.cluster_centers_[:, 0], model.cluster_centers_[:, 1], c='black', s=200, marker='*', label='聚類中心')plt.xlabel('特征1(如:消費金額)', fontsize=12) plt.ylabel('特征2(如:消費頻率)', fontsize=12) plt.title('客戶分群結果可視化', fontsize=14) plt.legend() # 顯示圖例 plt.grid(True, linestyle='--', alpha=0.5) plt.show()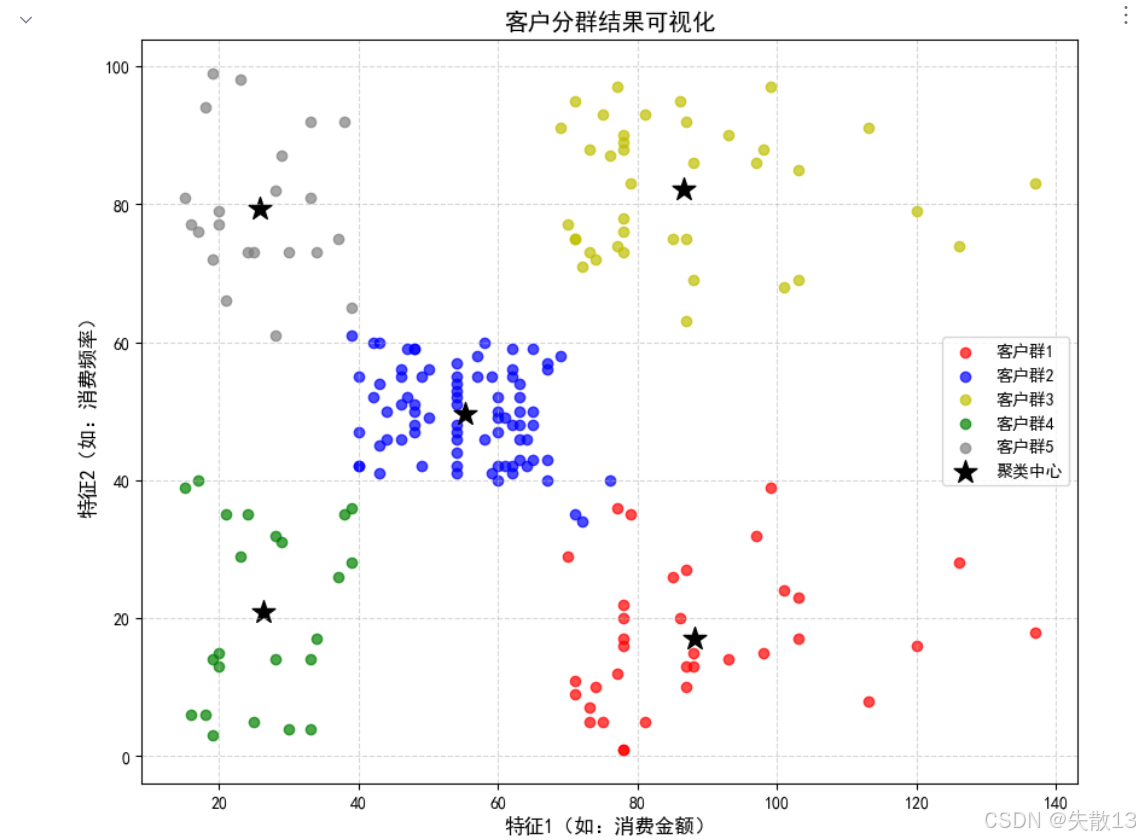



)
)


)



)

)

![[Robotics_py] 路徑規劃算法 | 啟發式函數 | A*算法](http://pic.xiahunao.cn/[Robotics_py] 路徑規劃算法 | 啟發式函數 | A*算法)

 226. 翻轉二叉樹 (深度優先搜索dfs ))
)
