Phantom-Data:邁向通用的主體一致性視頻生成數據集
paper是字節發布在Arxiv2025的工作
paper title:Phantom-Data: Towards a General Subject-Consistent
Video Generation Dataset
Code:鏈接
Abstract
近年來,主體到視頻(subject-to-video, S2V)生成取得了顯著進展。然而,現有模型在忠實執行文本指令方面仍面臨重大挑戰。這一限制被廣泛稱為“復制-粘貼問題”(copy-paste problem),其根源在于當前普遍采用的 in-pair 訓練范式。該方法通過從與目標視頻相同場景中采樣參考圖像,使主體身份與背景和上下文屬性緊密耦合,從而影響模型的文本響應能力。為了解決上述問題,我們提出 Phantom-Data,這是首個通用的跨對(cross-pair)主體一致性視頻生成數據集,涵蓋多個類別,包含約一百萬組具有身份一致性的圖像-視頻樣本對。我們的數據集通過三階段流水線構建完成:
(1) 一個通用且輸入對齊的主體檢測模塊;
(2) 從超過 5300 萬個視頻和 30 億張圖像中進行大規模跨上下文主體檢索;
(3) 利用先驗引導的身份驗證機制,確保在上下文變化下的視覺一致性。
大量實驗表明,使用 Phantom-Data 進行訓練可以在保持主體一致性的同時,顯著提升模型對文本提示的響應能力和生成畫面的視覺質量,表現甚至可與 in-pair 基線持平。
1 Introduction

圖1 訓練樣本概覽。(a) 單參考設置:現有方法通常從目標視頻本身提取參考圖像。相比之下,我們的方法使用在不同環境中拍攝的參考圖像。(b) 我們的數據集還包含多參考樣本,展示了每個主體在不同上下文環境中的呈現。
近年來,以 Sora [4] 為代表的文本生成視頻(text-to-video)模型取得了顯著進展 [23, 35, 37, 39, 48]。然而,由于文本指令本身存在的控制能力有限,如何實現對視頻生成的細粒度控制仍是實際應用中的關鍵挑戰。在最近的研究中 [11, 16, 20, 22, 46, 49],越來越多的關注聚焦于在文本生成視頻中保持主體身份一致性的問題。主體一致性視頻生成任務(subject-consistent video generation, 簡稱 S2V)[6, 9, 10, 18, 27],旨在在遵循文本提示的同時,準確保留參考主體的身份特征,如人物、動物、商品或場景。這一能力在個性化廣告 [5] 和 AI 驅動的電影制作 [44] 等應用中具有巨大潛力。
盡管視覺一致性方面取得了可喜進展,現有 S2V 方法仍存在文本跟隨能力有限和視頻質量欠佳的問題,即所謂的“復制-粘貼問題”(copy-paste problem)。如圖 2 所示,模型生成的視頻直接復用了參考幀中的主體圖像,導致忽略了提示詞中提到的“拳擊擂臺”背景。這一問題的根源在于 in-pair 訓練范式,即參考圖像與目標視頻取自相同的場景(如圖1(a)所示)。結果是,模型不僅保留了主體身份,還會誤保背景等無關上下文信息 [15, 28]。但在真實世界中,這種耦合特征可能與文本中的動作或語義相矛盾,導致生成視頻偏離文本提示,甚至出現明顯的偽影。

圖2 復制-粘貼問題示意圖。所示結果由一個當前最先進的視頻生成模型(Kling [1])生成。
為了解決上述問題,以往的研究 [6, 18, 20, 21, 24] 嘗試引入多種數據歸一化和增強策略,如背景去除、顏色擾動和幾何變換。然而,這些方法因上下文變化有限,難以解決復雜視角或動作造成的耦合。最近的研究引入了“cross-pair”數據構建方式,即從不同來源中采樣具有身份一致性的參考圖像和目標幀。這一設定鼓勵模型關注主體身份的保持,減少對無關上下文的過擬合 [33, 50]。然而,現有 cross-pair 數據集主要集中于人臉領域,難以泛化到通用主體場景。此外,目前訓練數據集要么參考變化不足,要么缺乏領域多樣性,限制了模型緩解 copy-paste 問題的效果。
在本工作中,我們提出了 Phantom-Data,這是一個專為緩解“復制-粘貼”問題而構建的通用 S2V 數據集,具有以下三大設計原則:
- 通用且輸入對齊的主體:參考圖像需覆蓋真實應用中常見的主體類型,反映用戶輸入的自然分布;
- 不同上下文條件:參考主體應與視頻中的目標主體處于不同背景、視角或姿態下,以提升模型在分布偏移條件下的泛化能力,降低對無關相關性的依賴;
- 身份一致性:盡管上下文條件變化,參考主體在形狀、結構、紋理等方面需與目標主體保持視覺一致性。
為滿足以上原則,我們設計了一個三階段的數據構建流水線:
-
第一階段:S2V 檢測
利用視覺-語言模型進行開放集檢測,識別適當尺寸的候選主體。之后通過過濾步驟,保留語義相關且結構緊湊的主體。 -
第二階段:上下文多樣性檢索
構建包含 5300 萬視頻片段和 30 億圖像樣本的大規模主體數據庫,以提高在不同背景、姿態、視角下檢索到相同身份主體的可能性。 -
第三階段:先驗引導的身份驗證
對于生物體(如人類、動物),從長視頻中挖掘時間結構構建 cross-context 配對;對于靜態物體(如商品),執行類別特定檢索。最終通過基于視覺語言模型(VLM)的兩兩驗證,確保每對樣本在身份一致性與上下文多樣性上兼顧。
通過上述流水線,我們構建了一個大規模、高質量的 cross-pair 一致性數據集,包含約 100 萬組身份一致的配對樣本,涵蓋超過 3 萬個多主體場景,為通用 S2V 建模提供堅實基礎。代表性樣本如圖 1 所示。
為驗證數據集的有效性,我們在多個開源視頻生成模型上進行了系統性實驗。結果表明,相較于以往的數據構建方法,我們的 cross-pair 方案在提升文本對齊度和視覺質量的同時,仍能保持與 in-pair 基線相當的主體一致性。此外,通過消融實驗進一步表明,大規模、多樣化的數據對于生成性能提升至關重要。我們的數據構建流程在確保身份一致性的同時,也成功引入了足夠的上下文多樣性。
我們的主要貢獻總結如下:
- 我們提出了 Phantom-Data,這是首個通用的 cross-pair 視頻一致性數據集,包含約 100 萬組高質量、身份一致的樣本,覆蓋廣泛的主體類別和視覺上下文;
- 我們設計了面向 S2V 的結構化數據構建流程,融合了主體檢測、跨上下文檢索、先驗引導身份驗證,確保了嚴格的身份一致性與豐富的上下文多樣性;
- 我們進行了大量實驗,驗證了數據集在文本對齊、視覺質量和泛化能力方面相較 in-pair 基線的一致提升。

表1 Phantom-data 與以往工作中使用的數據集的比較。
2 Related Work
文本到視頻生成(Text-to-Video Generation)。早期基于擴散的 視頻生成器 [3, 12, 42] 僅能生成空間和時間分辨率受限的短視頻片段。然而,隨著大規模潛在擴散模型和基于 Transformer 的架構的引入,該領域迅速發展。值得注意的是,Sora [4] 已能夠生成時長達一分鐘的高保真視頻,而同期的系統如 Seaweed [37]、Hunyuan-Video [23]、CogVideo-X [48]、MAGI [35] 以及其他方法 [39],在幀率、分辨率、場景復雜度、真實感和運動平滑性方面都有進一步提升。盡管這些通用的文本條件生成模型在視覺質量上表現出色,但它們提供的控制仍較為粗糙:僅依靠文本提示,無法完全指定場景布局、主體外觀或視角,這促使研究人員探索更細粒度的控制信號。
主體一致性視頻生成(Subject-Consistent Video Generation)。主體一致性視頻生成(S2V)[6, 9, 10, 18, 27] 的任務是生成不僅與給定文本提示一致,還能保留參考主體(如人物、動物、產品或場景)視覺身份的視頻。從建模的角度看,一種常見策略 [6, 17, 18, 33] 是基于交叉注意力的融合方法,即將從預訓練編碼器 [31, 34, 45] 或多模態語言模型(VLM)中提取的視覺特征,通過專用注意力層注入到生成骨干網絡中。另一種替代方法是噪聲空間條件化(noise-space conditioning),即將從 VAE 編碼器獲得的身份特征直接與擴散模型的噪聲輸入拼接,而無需修改底層架構。這種輕量化設計使得身份信息幾乎無損地注入成為可能,如 Phantom [27] 和 VACE [20] 等 DIT 風格模型所示。近期的系統如 SkyReels-A2 [10] 探索了將兩種策略結合,在統一框架內引入交叉注意力引導和噪聲級別條件化。
主體到視頻生成中的訓練數據(Training Data in Subject-to-Video Generation)。訓練數據在主體一致性視頻生成中起著至關重要的作用,因為它直接影響模型生成真實且可控結果的能力。現有大多數方法依賴于配對(in-pair)監督,即參考幀和目標幀來自同一視頻片段。雖然這種設置能保證身份一致性,但往往會導致不期望的“復制-粘貼”效應——模型不僅復制了主體,還復制了參考幀的背景和姿態,從而限制了其對輸入提示的跟隨能力。為緩解這一問題,一些工作 [6, 18, 20, 21, 24] 采用了數據歸一化和增強策略,例如背景移除、顏色抖動和幾何變換。然而,這些技術與配對訓練固有的有限多樣性相結合,往往不足以應對運動、視角和場景布局等復雜上下文變化。近期的研究轉向跨配對(cross-pair)訓練,即從不同視頻中采樣身份一致的參考幀和目標幀。這種設置鼓勵模型專注于主體身份,同時減少對特定視覺上下文的過擬合 [33, 50]。然而,當前的跨配對數據集大多局限于狹窄的領域,如人臉,這限制了它們對更廣泛主體類別(如動物、產品或風格化角色)的泛化能力。總之,雖然跨配對監督為解決“復制-粘貼”問題提供了有前景的方向,但在通用領域中缺乏高質量、多樣化且身份一致的訓練數據,仍然是推進 S2V 模型發展的重要瓶頸。為彌補這一缺口,我們提出了 Phantom-data,這是一個大規模跨配對數據集,旨在支持覆蓋廣泛真實世界類別的主體一致性視頻生成。
3 Phantom Data
我們對 Phantom-Data 進行了詳細分析,重點關注其統計特性,并將其與現有的主體一致性視頻生成數據集進行了比較。
3.1 Statistical Analysis
我們從視頻層面和主體層面對數據集進行了分析。
視頻層面特性 如圖 3(a–c) 所示,我們的數據集涵蓋了廣泛的視頻時長、分辨率和運動模式。大約 50% 的視頻時長為 5–10 秒,大多數為 720p 分辨率。運動程度差異顯著,既包括相對靜態的場景,也包括高度動態的場景。
主體組成 圖 3(d) 展示了主體類型及其組合的分布。大多數樣本(約 72 萬個)僅包含一個主體,例如人類、產品或動物;此外,還有相當一部分(約 28 萬個)包含兩個或以上同時出現的實體,為多主體一致性建模提供了支持。
參考多樣性 如圖 3(e) 所示,數據集涵蓋了廣泛的主體類別語義空間。常見的參考實體包括人類(如女人、男人、女孩)、動物(如狗、鳥)以及人造物體(如智能手機、汽車、筆記本電腦),這凸顯了該數據集在跨不同領域的一般化主體到視頻建模任務中的適用性。
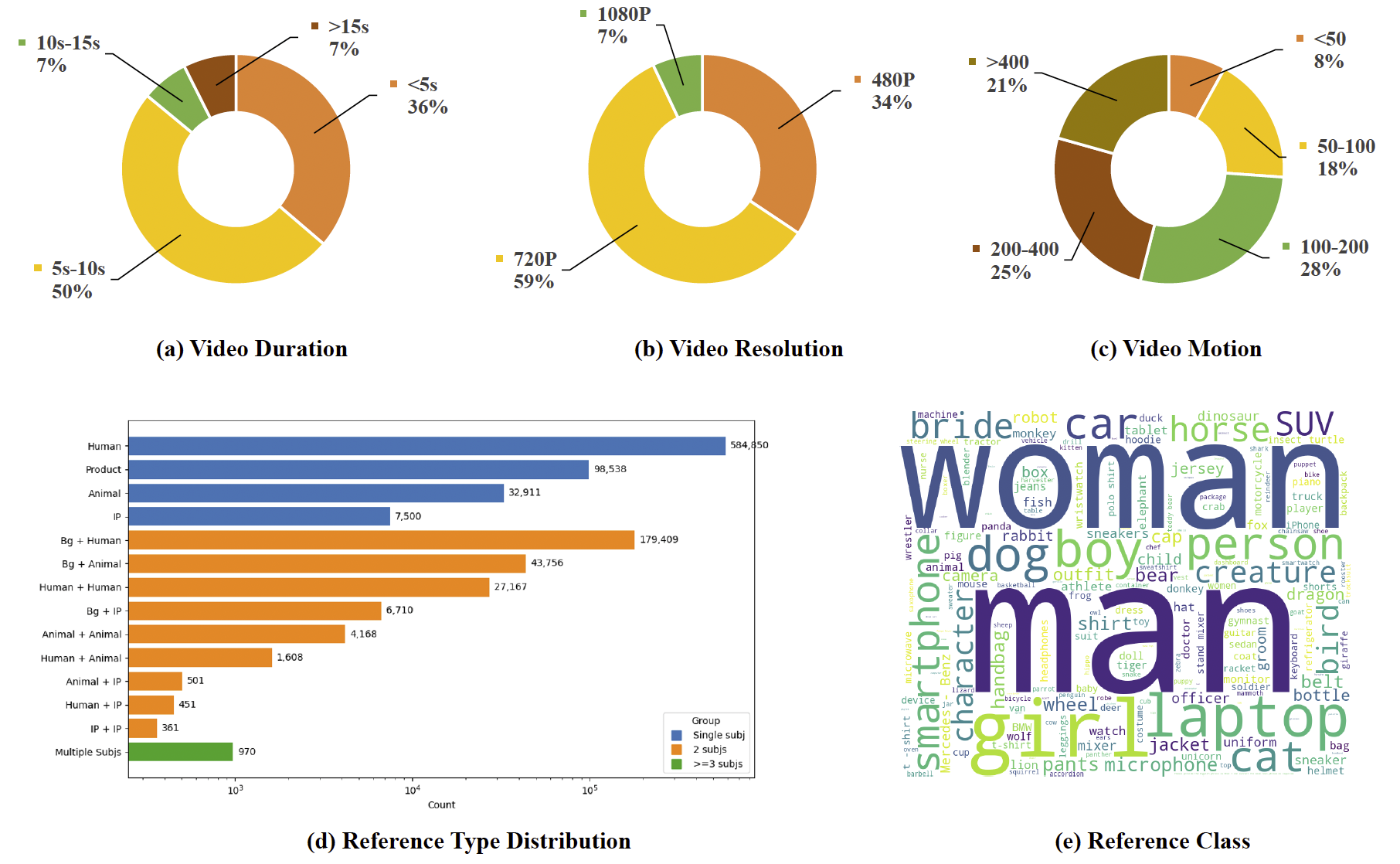
圖 3 Phantom-Data 的統計分析。
3.2 Comparison with Prior Datasets
如表 1 所示,現有的主體一致性視頻生成數據集要么缺乏通用物體的覆蓋,要么嚴重依賴來自同一視頻的輸入對齊參考幀,要么在上下文多樣性方面受限。相比之下,Phantom-Data 提供了更全面的設置:它支持超越人臉的通用物體類別,通過從不同場景中采樣主體-參考對來促進跨上下文建模,并且對研究公開可用。這使其成為第一個在通用、跨對設置下同時支持身份一致性和上下文多樣性的開放獲取數據集。
4 Data Pipeline
4.1 Video Data Source
Phantom-Data 視頻數據集由來自 Koala-36M [41] 等公共資源以及專有的內部資源庫的片段組成。每個視頻都經過嚴格的質量控制流程,包括黑邊檢測、運動分析和其他篩選步驟。隨后,長視頻會通過場景分割在秒級別切分成短片段。每個生成的片段都會被標注上相應的視頻字幕。視頻總數約為 5300 萬個。
4.2 Data Pipeline
給定一個輸入視頻及其對應的字幕,我們專注于構建一個高質量的跨配對數據集,其中同一主體在不同視覺環境中出現,同時保持身份一致性。為此,我們設計了一個由三個關鍵階段組成的結構化數據管道。如圖 4 所示,首先,我們執行 S2V 檢測(S2V Detection),以從視頻中識別高質量的主體實例。然后,我們提出一個情境多樣化檢索(Contextually Diverse Retrieval)模塊,用于召回在不同場景中可能與檢測到的主體對應的候選圖像。最后,我們應用基于先驗的身份驗證(Prior-based Identity Verification)來篩選檢索到的候選項,確保只保留那些在不同環境下共享相同身份的樣本。
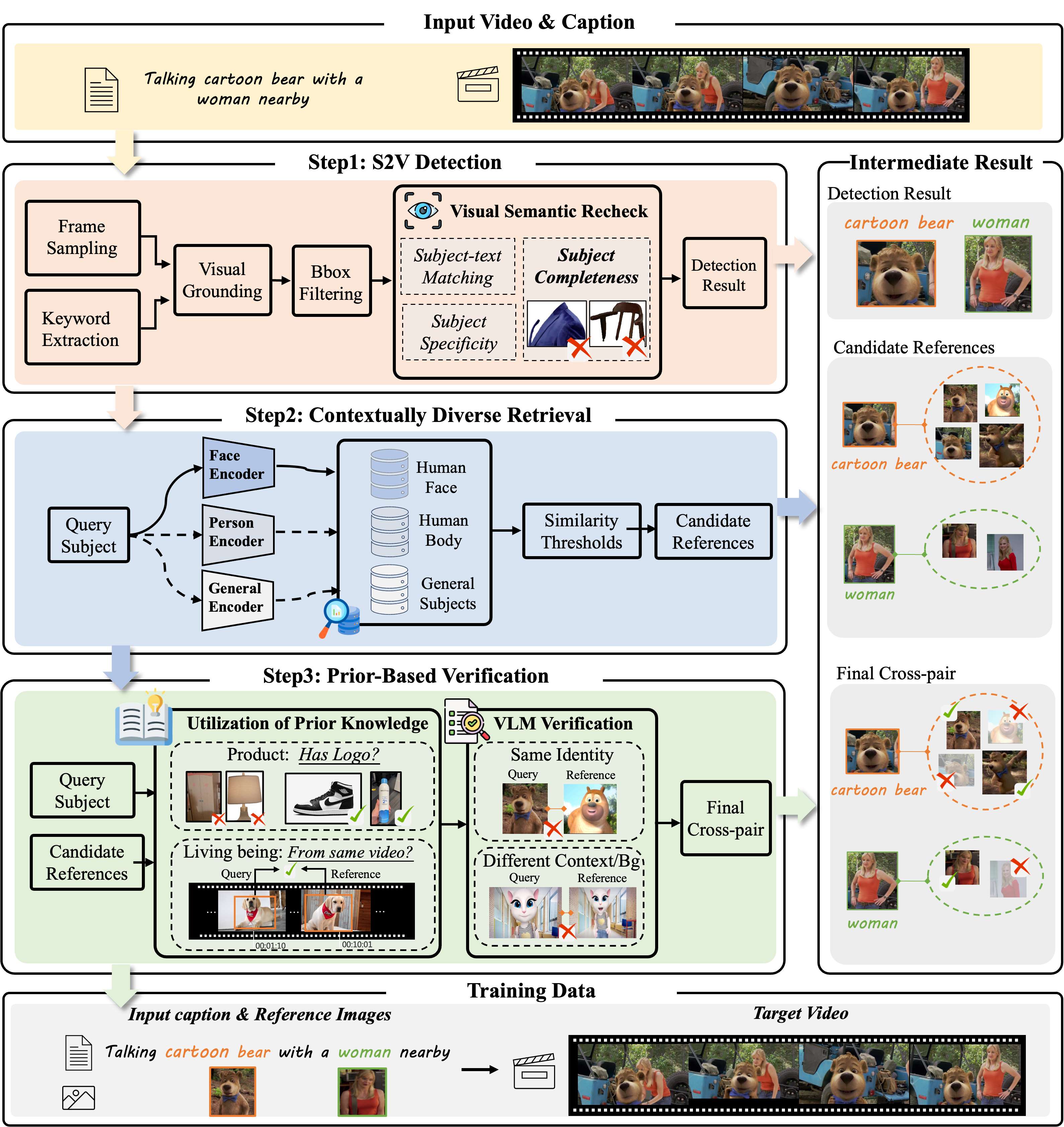
圖 4 構建跨配對訓練樣本的數據管道概覽。
4.2.1 S2V Detection
該階段旨在從每個視頻片段中識別多樣且合格的主體,作為跨場景配對的候選對象。它包括五個主要步驟:
- 幀采樣。為降低計算量,我們在每個片段的 t = 0.05、0.5 和 0.95 處采樣三幀,遵循 [6],以確保時間多樣性,同時避免對所有幀進行處理。
- 關鍵詞提取。我們使用 Qwen2.5 [47] 從字幕中提取關鍵名詞短語(如人、動物、產品),作為定位主體的候選項。
- 視覺定位。Qwen2.5-VL [2] 將每個短語與采樣幀中的區域進行對齊。對于映射到多個區域的模糊匹配,會被移除以減少噪聲。
- 邊界框過濾。我們保留覆蓋圖像 4% 至 90% 且大小至少為 128 × 128 的框。重疊框(IoU > 0.8)會被抑制以保證清晰性。
- 視覺-語義復查。為進一步確保定位主體的質量,我們使用另一種視覺語言模型 InternVL2.5 7B [7] 對每個檢測進行以下標準的驗證:
- 完整性:我們觀察到,視覺定位常會生成圍繞部分或裁剪對象的邊界框,這是底層檢測模型窮盡標注策略的結果。然而,在 S2V 任務中,用戶通常會提供完整的參考主體,因此這種不完整的檢測是不合適的。因此,我們會過濾掉未能覆蓋物體完整范圍的區域。
- 特異性:主體必須在視覺上清晰可辨。模糊或通用的物體(如樹木、巖石或背景雜物)會被排除。
- 主體-文本匹配:定位區域必須與相關短語在語義上一致。為提升對齊精度,我們使用另一實例的 InternVL2.5 重新評估文本描述與檢測到的主體之間的一致性。
通過該流程,我們獲得了一組高質量的主體實例,每個實例都配有相應的描述短語。由于一個主體可能會出現在視頻的多個幀中,我們僅選擇一個代表性實例用于 Fig. 4 的 Intermediate Result 部分的可視化。
4.2.2 Contextually Diverse Retrieval
在前一階段檢測到主體實例后,我們旨在尋找在不同視覺上下文中出現的相同主體的候選參考圖像。為此,我們構建了一個大規模檢索庫,并使用檢測到的主體進行身份感知的查詢。
大型檢索庫構建。檢索庫包含兩個核心組成部分:多樣化的主體圖像來源以增加上下文的多樣性,以及為保持身份一致性而設計的特征表示。
主體來源。我們首先將訓練視頻中檢測到的每個主體實例登記到檢索庫中。為了進一步擴大候選多樣性,我們在原始視頻語料之外,增加了來自 LAION 數據集[36] 的額外 30 億張圖像。這些外部圖像在場景、姿態和外觀上引入了更大的變化,從而在檢索過程中提供了更廣泛的上下文覆蓋,對于具有顯著實例內變化的產品類場景尤為有價值。
主體表示。為了支持可靠的跨上下文身份匹配,我們使用專家設計的編碼器提取保持身份一致性且與上下文無關的特征嵌入,這些嵌入針對不同主體類別進行了優化。這些嵌入既用于索引檢索庫,也用于查詢。
對于人臉表示,我們采用廣泛使用的 ArcFace 編碼器[8] 來提取穩健且具有判別力的身份嵌入:
Vface=Earcface(Iface).(1)V_{face} = E_{arcface}(I_{face}). \tag{1}Vface?=Earcface?(Iface?).(1)
對于通用物體,受 ObjectMate[43] 啟發,我們使用在一致性導向的圖像數據集[38] 上微調的 CLIP 模型來提取身份保持的嵌入:
Vsubj=EIR(I).(2)V_{subj} = E_{IR}(I). \tag{2}Vsubj?=EIR?(I).(2)
對于人類主體(在許多下游應用中占據核心地位),我們結合人臉和服裝特征。每個個體由通用外觀嵌入與相應的人臉嵌入拼接表示:
Vperson=[EIR(I),Earcface(Iface)].(3)V_{person} = [E_{IR}(I), E_{arcface}(I_{face})]. \tag{3}Vperson?=[EIR?(I),Earcface?(Iface?)].(3)
基于查詢的檢索。為了確保檢索到的候選與查詢圖像在視覺上有區別但保持相同身份,我們對相似度設置上下界。具體來說,我們通過設定上限相似度閾值來剔除過于相似的結果(潛在重復項),并通過設置下限閾值來排除無關身份。
4.2.3 Prior-Based Identity Verification
然而,由于檢索語料庫規模龐大,即使在看似合理的相似度范圍內,也經常出現誤檢。為了解決這一問題,我們采用了基于先驗知識和 VLM 驗證的兩階段過濾策略。
先驗知識的利用。我們針對不同類別設計了特定的過濾策略,以提升跨配對的可靠性:
1)非生物主體(如產品):這類主體通常具有較高的類內差異性,使得身份驗證更具挑戰性。為提高精度,我們僅保留那些具有完整且可識別品牌標志(如 Nike、Audi)并且在不同場景中依然可見的產品實例。
2)生物主體(如人類、動物):對于這些主體,我們將檢索到的候選限制在同一長視頻的不同片段中。該約束確保了場景和姿態的自然變化,同時保持身份一致性。
基于 VLM 的一致性驗證。為了進一步確保身份一致性和上下文多樣性,我們應用基于 VLM 的驗證過程:
1)身份一致性:對于非生物對象,我們在允許背景變化的同時,嚴格要求視覺細節(如顏色、包裝、文字元素)的一致性;對于生物主體,尤其是人類,我們驗證人臉身份的一致性,并在全身樣本的情況下,還需確保服飾的一致性。
2)上下文多樣性:我們僅保留那些在背景和場景上下文中具有顯著差異的跨配對樣本,從而在模型訓練過程中減少復制粘貼偽影。
5 Experiments
5.1 Implementation
模型架構。我們使用Phantom-wan [27]模型驗證所提數據的有效性。Phantom-wan構建于Wan2.1 [40]基礎之上,是一個領先的開源主體一致性視頻生成框架。
訓練與推理。我們使用Rectified Flow (RF) [25, 28]作為訓練目標,訓練了一個13億參數的Phantom-wan模型。訓練在64塊A100 GPU上進行,共迭代30k步,使用480p分辨率數據,能夠得到穩定的性能。在推理階段,我們采用Euler采樣(50步),并使用無分類器引導 [14] 來解耦圖像與文本條件。所有實驗均遵循相同的訓練和推理設置,以確保公平比較。
評估。我們構建了一個包含100個案例的測試集,覆蓋多種場景,包括人物、動物、產品、環境和服裝。這些案例包括單主體和多主體設置,并配有人工編寫的文本提示,模擬真實用戶輸入。我們從三個維度評估模型性能:視頻質量、文本-視頻一致性以及主體-視頻一致性。
主體-視頻一致性使用CLIP [13]、DINO [30]和GPT-4o得分進行評估,遵循受[32]啟發的最新評估協議。文本-視頻一致性通過Reward-TA [26]進行測量,二者均評估生成視頻內容與文本提示的語義對齊程度。視頻質量使用VBench [19]進行評估,提供多個方面的細粒度評價,包括Temporal(時間閃爍與穩定性)、Motion(主體運動的平滑度)、IQ(整體成像質量)、BG(跨幀背景一致性)以及Subj(生成主體的時間一致性)。


)


)
--(C/C++))
力扣.二叉樹的最大路徑和牛客.主持人調度(二))
:標準IO高級操作與文件流定位實戰》)




)
)


——numpy庫)

