與C、c++,Java等高級語言相比,匯編開發的效率偏低和維護成本偏高。大型的項目已經很少用匯編語言了,但并不是說匯編語言就完全沒有用處了,在某些特定的領域,匯編語言還是很有用處的,比如配置硬件驅動器,芯片接口開發等。并且可以與C和c++混合使用。本章講解高級語言接口,匯編語言與高級語言的混合編程,庫調用。
13.1 引言
大多數程序員不會用匯編語言編寫大型程序,因為這將花費相當多的時間。反之,高級語言則隱藏了會減緩項目開發進度的細節。但是匯編語言仍然廣泛用于配置硬件驅動器,以及優化程序速度和代碼量。
本章將重點關注匯編語言和高級編程語言之間的接口或連接。第二節將展示如何在C++中編寫內聯匯編代碼。第三節將把 32 位匯編語言模塊鏈接到 C++程序。最后,將說明如何在匯編程序中調用C庫函數。
13.1.1 通用規范
從高級語言中調用匯編過程時,需要解決一些常見的問題。
首先,一種語言使用的命名規范(namingconvention)是指與變量和過程命名相關的規則和特性。比如,一個需要回答的重要問題是:匯編器或編譯器會修改目標文件中的標識符名稱嗎?如果是,如何修改?
其次,段名稱必須與高級語言使用的名稱兼容。
第三,程序使用的內存模式(微模式、小描述、緊湊模式、中模式、大模式、巨模式,或平坦模式)決定了段大小(16或32位),以及調用或引用是近(同一段內)還是遠(不同段之間)。
調用規范 調用規范(calling convention)是指調用過程的底層細節。下面列出了需要考慮的細節信息:
●調用過程需要保存哪些寄存器。
●傳遞參數的方法:用寄存器、用堆棧、共享內存,或者其他方法。
●主調程序調用過程時,參數傳遞的順序
●參數傳遞方法是傳值還是傳引用。
●過程調用后,如何恢復堆棧指針
●函數如何向主調程序返回結果
命名規范與外部標識符 當從其他語言程序中調用匯編過程時,外部標識符必須與命名規范(命名規則)兼容。外部標識符(external identifier)是放在模塊目標文件中的名稱,鏈接器使得這些名稱能夠被其他程序模塊使用。鏈接器解析對外部標識符的引用,但是僅適用于命名規范一致的情況。
例如,假設C程序Main.c 調用外部過程ArraySum。如下圖所示,C 編譯器自動保留大小寫,并為外部名稱添加前導下劃線,將其修改為_ArraySum:

Array.asm 模塊用匯編語言編寫,由于其.MODEL 偽指令使用的選項為 Pascal 語言,因此輸出 ArraySum 過程的名稱就是ARRAYSUM。由于兩個輸出的名稱不同,因此鏈接器無法生成可執行程序。
早期編程語言,如 COBOL 和PASCAL,其編譯器一般將標識符全部轉換為大寫字母。近期的語言,如 C、C++ 和 Java 則保留了標識符的大小寫。此外,支持函數重載的語言(如C++)還使用名稱修飾(name decoration)的技術為函數名添加更多字符。比如,若函數名為MySub(int n,double b),則其輸出可能為MySub#int#double。
在匯編語言模塊中,通過MODEL偽指令選擇語言說明符來控制大小寫。
段名稱 匯編語言過程與高級語言程序鏈接時,段名稱必須是兼容的。本章使用Microsoft 簡化段偽指令.CODE、.STACK 和.DATA,它們與Microsoft C++編譯器生成的段名稱兼容。
內存模式 主調程序與被調過程使用的內存模式必須相同。比如,實地址模式下可選擇小模式、中模式、緊湊模式、大模式和巨模式。保護模式下必須使用平坦模式。本章將會給出兩種模式的例子。
13.1.2 MODEL偽指令
16 位和 32 位模式中,MASM 使用.MODEL 偽指令確定若干重要的程序特性:內存模式類型、過程命名模式以及參數傳遞規則。若匯編代碼被其他編程語言程序調用,那么后兩者就尤其重要。.MODEL 偽指令的語法如下:
.MODEL memorymodel [,modeloptions]
MemoryModel 表13-1列出了memorymodel字段可選擇的模式。除了平坦模式之外其他所有模式都可以用于16位實地址編程。
表13-1內存模式 | |
模式 | 說明 |
微模式 | 一個既包含代碼又包含數據的段。文件擴展名為.com的程序使用該模式 |
小模式 | 一個代碼段和一個數據段。默認情況下,所有代碼和數據都為近屬性 |
中模式 | 多個代碼段,一個數據段 |
緊湊模式 | 一個代碼段,多個數據段 |
大模式 | 多個代碼段和數據段 |
巨模式 | 與大模式相同,但是各個數據項可以大于單個段 |
平坦模式 | 保護模式。代碼與數據使用32位偏移量。所有的數據和代碼(包括系統資源)都在一個32位段內 |
32位程序使用平坦內存模式,其偏移量為32位,代碼和數據最大可達4GB。比如Iryine32.inc 文件包含了如下.MODEL偽指令:
.model flat, stdcall
ModelOptions .MODEL偽指令中的ModelOptions字段可以包含一個語言說明符和一個棧距離。語言說明符指定過程與公共符號的調用和命名規范。棧距離可以是NEARSTACK(默認值)或者FARSTACK。
1.語言說明符
偽指令.MODEL 有幾種不同的可選語言說明符,其中的一些很少使用(比如BASICFORTRAN 和 PASCAL)。反之,C 和 STDCALL 則十分常見。結合平坦內存模式,示例如下:
.model flat, C
.model flat, STDCALL
語言說明符 STDCALL 用于 Windows 系統函數調用。本章在鏈接匯編代碼和 C 與 C++程序時,使用C語言說明符。
2.STDCALL
STDCALL 語言說明符將子程序參數按逆序(從后往前)壓入堆棧。為了便于說明,首先用高級語言編寫如下函數調用:
AddTwo( 5:6);
STDCALL被選為語言說明符,則等效的匯編語言代碼如下:
push 6
push 5
call AddTwo另一個重要的考慮是,過程調用后如何從堆棧中移除參數。STDCALL 要求在 RET 指令中帶一個常量操作數。返回地址從堆棧中彈出后,該常數為 RET 執行與 ESP 相加的數值:
AddTwo PROCpush ebpmov ebp, espmov eax,[ebp+12] ;第二個參數add eax,[ebp+8] ;第一個參數pop ebpret 8 ;清除堆棧
AddTwo ENDP堆棧指針加上8后,就指回了主調程序參數人棧之前指針的位置。最后,STDCALL通過將輸出(公共)過程名保存為如下格式來修改這些名稱:
_name@nn
前導下劃線添加到過程名,@符號后面的整數指定了過程參數的字節數(向上舍人到4的倍數)。例如,假設過程 AddTwo 帶有兩個雙字參數,那么匯編器傳遞給鏈接器的名稱就為_AddTwo@8。
Microsoft鏈接器是區分大小寫的,因此MYSUB@8和MySub@8是兩個不同的名稱。要查看OBJ文件中所有的過程名,使用VisuaStudio中的DUMPBIN工具,選項為/SYMBOLS。
3.C說明符
和 STDCALL 一樣,C語言說明符也要求將過程參數按從后往前的順序壓人堆。對于過程調用后從堆棧中移除參數的問題,C語言說明符將這個責任留給了主調方。在主調程序中,ESP與一個常數相加,將其再次設置為參數入棧之前的位置:
push 6 ;第二個參數
push 5 ;第一個參數
call AddTwo
add esp, 8 ;清除堆棧C語言說明符在外部過程名的前面添加前導下劃線。示例如下:
_AddTwo
13.1.3 檢查編譯器生成的代碼
長久以來,C和C++編譯器都會生成匯編語言源代碼,但是程序員通常看不到。這是因為,匯編語言代碼只是產生可執行文件過程的一個中間步驟。幸運的是,大多數編譯器都可以應要求生成匯編語言源代碼文件。例如,表13-2列出了Visual Studio 控制匯編源代碼輸出的命令行選項。
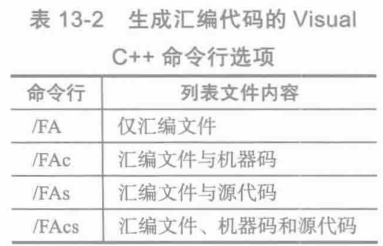
檢查編譯器生成的代碼文件有助于理解底層信息,比如堆棧幀結構、循環和邏輯編碼,并且還有可能找到低級編程錯誤。另一個好處是更加便于發現不同編譯器生成代碼的差異。
現在來看看C++編譯器生成優化代碼的一種方法。由于是第一個例子,因此先編寫一個簡單的C方法 ArraySum,并在 Visual Studio 2012 中進行編譯,其設置如下:
●Optimization=Disabled(使用調試器時需要)
●Favor Size or Speed=Favor fast code
●Assembler Output=Assembly With Source Code
下面是用ANSIC編寫的arraysum源代碼:
int arraySum(int array[], int count)
{int i;int sum = 0;for(i = 0; i < count; i++)sum += array[i];return sum;
}現在來查看由編譯器生成的arraysum的匯編代碼,如圖13-1所示。

圖13-1Visual Studio生成的 ArraySum 匯編代碼

1~4行定義了兩個局部變量(sum和i)的負數偏移量,以及輸人參數array和count的正數偏移量:
1: _sum$ = -8 ;size = 4
2: _i$ = -4 ;size = 4
3: _array$ = 8 ;size = 4
4: _count$ = 12 ;size = 4
9~10行設置 ESP為幀指針:
9: push ebp
10: mov ebp, esp
之后,11~14行從ESP中減去72,為局部變量預留棧空間。同時,把將會被函數修改的三個寄存器保存到堆棧。
11: sub esp, 72
12: push ebx
13: push esi
14: push edi
19行把局部變量sum定位到堆棧幀,并將其初始化為0。由于符號_sum$定義為數值-8,因此它就位于當前EBP下面8個字節的位置:
19: mov DWORD PTR_sum$[ebp], 0
24 和 25 行將變量 i初始化為 0,再轉移到 30 行,跳過后面循環計數器遞增的語句:
24: mov DWORD PTR_i$[ebp],0
25: imp SHORT $LN3@arraySum
26~29行標記循環開端以及循環計數器遞增的位置。從C源代碼來看,遞增操作(i++)是在循環末尾執行,但是編譯器卻將這部分代碼移到了循環頂部:
26: $LN2@arraySum:
27: mov eax,DWORD PTR _i$[ebp]
28: add eax,1
29: mov DWORD PTR _i$[ebp],eax
30~33行比較變量i和count,如果i大于或等于count,則跳出循環:
30:$LN3@arraySum:
31: mov eax, DWORD PTR _i$[ebp]
32: cmp eax, DWORD PTR _count$[ebp]
33: jge SHORT $LN1@arraySum
37~41行計算表達式sum+=array[]。Array[1]復制到 ECX,sum 復制到 EDX,執行加法運算后,EDX 的內容再復制回sum:
37: mov eax, DWORD PTR _i$[ebp]
38: mov ecx, DWORD PTR _array$[ebp]
39: mov edx, DWORD PTR _sum$[ebp]
40: add edx, DWORD PTR[ecx+eax*4]
41: mov DWORD PTR _sum$[ebp], edx
42 行將控制轉回循環頂部:
42: jmp SHORT SLN2@arraySum
43 行的標號正好位于循環之外,該位置便于作為循環結束時進行跳轉的目標地址:
43: $LN1@arraySum:
48 行將變量sum 送人 EAX,準備返回主調程序。
52~56 行恢復之前被保存的寄存器,其中,ESP 必須指向主調程序在堆棧中的返回地址。
48: mov eax, DWORD PTR _sum$[ebp]
49:
50: ; 12: }
51:
52: pop edi
53: pop esi
54: pop ebx
55: mov esp, ebp
56: pop ebp
57: ret 0
58: _arraySum ENDP
可以寫出比上例更快的代碼,這種想法不無道理。上例中的代碼是為了進行交互式調試,因此為了可讀性而犧牲了速度。如果針對確定目標編譯同樣的程序,并選擇完全優化,那么結果代碼的執行速度將會非常快,但同時,程序對人類而言基本上是無法閱讀和理解的。
調試器設置 用Visual Studio調試C 和 C++程序時,若想查看匯編語言源代碼,就在Tools 菜單中選擇 Options 以顯示如圖 13-2 的對話框窗口,再選擇箭頭所指的選項。上述設置要在啟動調試器之前完成。接著,在調試會話開始后,右鍵點擊源代碼窗口,從彈出菜單中選擇 Go to Disassembly。
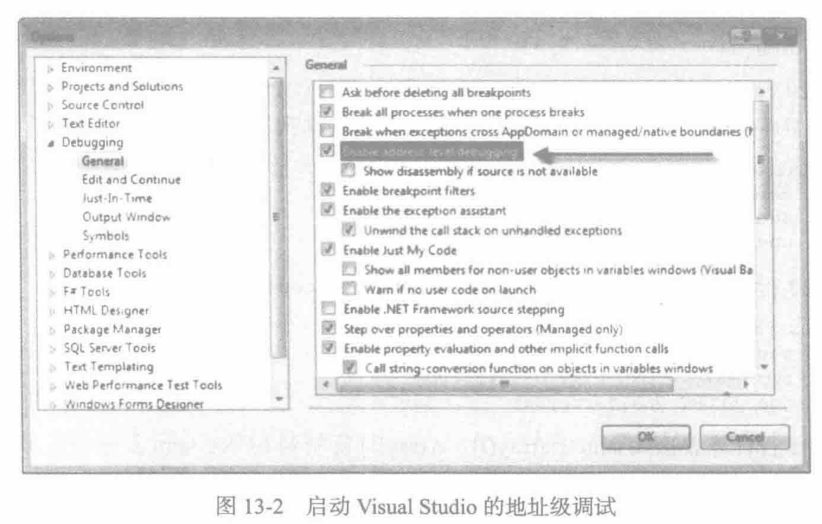
圖13-2啟動VisualStudio的地址級調試
本章目標是熟悉由C和C++編譯器產生的最直接和簡單的代碼生成例子。此外,認識到編譯器有多種方法生成代碼也是很重要的。比如,它們可以將代碼優化為盡可能少的機器代碼字節。或者,可以嘗試生成盡可能快的代碼,即使要用大量機器代碼字節來輸出結果(常見的情況)。最后,編譯器還可以在代碼量和速度的優化間進行折中。為速度進行優化的代碼可能包含更多指令,其原因是,為了追求更快的執行速度會展開循環。機器代碼還可以拆分為兩部分以便利用雙核處理器,這些處理器能同時執行兩條并行代碼。
13.1.4 本節回顧
1.什么是編程語言使用的命名規范?
答:語言的命名規范是指變量或過程命名的相關規則和特性。
2.實地址模式可以選擇哪些內存模式?
答:微模式、小模式、緊湊模式、中模式、大模式、巨模式
3.使用STDCALL語言說明符的匯編語言過程可以與C++程序鏈接嗎?
答:不可以,因為鏈接器無法找到過程名。
13.2 內嵌匯編代碼
13.2.1 Visual C++中的_asm偽指令
內嵌匯編代碼(inline assembly code)是指直接插入高級語言程序中的匯編源代碼。大多數C和C++編譯器都支持這一功能。
本節將展示如何在運行于32位保護模式,并采用平坦內存模式的MicrosoftVisual C++中編寫內嵌匯編代碼。其他高級語言編譯器也支持內嵌匯編代碼,但其語法會發生變化。
內嵌匯編代碼是把匯編代碼編寫為外部模塊的一種直接替換方式。編寫內嵌代碼最突出的優點就是簡單性,因為不用考慮外部鏈接,命名以及參數傳遞協議等問題。
但使用內嵌匯編代碼最大的缺點是缺少兼容性。高級語言程序針對不同目的平臺進行編譯時,這就成了一個問題。比如,在IntelPentium處理器上運行的內嵌匯編代碼就不能在RISC處理器上運行。一定程度上,在程序源代碼中插入條件定義可以解決這個問題,插入的定義針對不同目標系統可以啟用函數的不同版本。不過,容易看出,維護仍然是個問題另一方面,外部匯編過程的鏈接庫容易被為不同目標機器設計的相似鏈接庫所代替。
__asm偽指令 在VisualC++中,偽指令__asm可以放在一條語句之前,也可以放在一個匯編語句塊(稱為asm塊)之前。語法如下:
__asm statement
__asm {statement-1statement-2....statement-n
}(在“asm”的前面有兩個下劃線。)
注釋 注釋可以放在 asm塊內任何語句的后面,使用匯編語法或C/C++語法。VisualC++手冊建議不要使用匯編風格的注釋,以防與C宏混淆,因為C宏會在單個邏輯行上進行擴展。下面是可用注釋的例子:
mov esi,buf :initialize index register
mov esi,buf /* initialize index register*/
mov esi,buf //initialize index register特點 編寫內嵌匯編代碼時允許:
●使用 x86 指令集內的大多數指令。
●使用寄存器名作為操作數。
●通過名字引用函數參數。
●引用在asm 塊之外定義的代碼標號和變量。(這點很重要,因為局部函數變量必須在asm塊的外面定義。)
●使用包含在匯編風格或C風格基數表示法中的數字常數。比如,0A26h 和 0xA26 是等價的,且都能使用。
●在語句中使用PTR 運算符,比如 inc BYTE PTR[esi]。
●使用 EVEN 和ALIGN偽指令。
限制 編寫內嵌匯編代碼時不允許:
●使用數據定義偽指令,如DB(BYTE)和DW(WORD)。
●使用匯編運算符(除了PTR之外)。
●使用 STRUCT、RECORD、WIDTH 和MASK。
●使用宏偽指令,包括MACRO、REPTIRCIRP和ENDM,以及宏運算符(!&、%和.TYPE)。
●通過名字引用段。(但是,可以用段寄存器名作為操作數。)
寄存器值 不能在一個asm塊開始的時候對寄存器值進行任何假設。寄存器有可能被asm 塊前面的執行代碼修改。Microsoft Visual C++的關鍵字_fastcall 會使編譯器用寄存器來傳遞參數,為了避免寄存器沖突,不要同時使用_fastcall和_asm。
一般情況下,可以在內嵌代碼中修改 EAX、EBX、ECX和EDX,因為編譯器并不期望在語句之間保留這些寄存器值。但是,如果修改的寄存器太多,那么編譯器就無法對同一過程中的 C++代碼進行完全優化,因為優化要用到寄存器。
雖然不能使用OFFSET運算符,但是用LEA指令也可以得到變量的偏移地址。比如,下面的指令將buffer 的偏移地址送人 ESI
lea esi,buffer
長度、類型和大小 內嵌匯編代碼還可以使用LENGTHSIZE和TYPE運算符。LENGTH 運算符返回數組內元素的個數。按照不同的對象,TYPE 運算符返回值如下:
●對C或C++類型以及標量變量,返回其字節數。
●對結構,返回其字節數。
●對數組,返回其單個元素的大小。
SIZE運算符返回LENGTH*TYPE的值。下面的程序片段演示了內嵌匯編程序對各種C++類型的返回值。
Microsoft Visual C++內嵌匯編程序不支持 SIZEOF 和LENGHTOF 運算符。
使用 LENGTH、TYPE和 SIZE 運算符
下面程序包含的內嵌匯編代碼使用LENGTH、TYPE 和SIZE 運算符對 C++變量求值。每個表達式的返回值都在同一行的注釋中給出:
struct Package {long originZip //4long destinationZip //4float shippingPrice; //4
};
char myChar;
bool myBool;
short myShort;
int myInt;
long myLong;
float myFloat;
double myDouble;
Package myPackage;
long double myLongDouble;
long myLongArray[10];
__asm {mov eax, myPackage.destinationZipmov eax, LENGTH myInt; //1mov eax, LeNGTH myLongArray; //10mov eax, TYPE myChar; //1mov eax, TYPE myBool; //1mov eax, TYPE myShort; //2mov eax, TYPE myInt; //4mov eax, TYPE myLong; //4mov eax, TYPE myFloat; //4mov eax, TYPE myDouble; //8mov eax, TYPE myPackage; //12mov eax, TYPE myLongDouble; //8mov eax, TYPE myLongArray; //4mov eax, SIZE myLong; //4mov eax, SIZE myPackage; //12mov eax, SIZE myLongArray; //40
}13.2.2 文件加密示例
現在查看的簡短程序實現如下操作:讀取一個文件,對其進行加密,再將其輸出到另一個文件。函數TranslateBuffer 用一個__asm 塊定義語句,在一個字符數組內進行循環,并把每個字符與預定義值進行XOR 運算。內嵌語言可以使用函數形參、局部變量和代碼標號。由于本例是由Microsoft Visual C++編譯的 Win32控制臺應用,因此其無符號整數類型為32 位;
void TranslateBuffer(char *buf, unsigned count, unsigned char eChar)
{__asm {mov esi, bufmov ecx, countmov al, eCharL1:xor [esi], alinc esiloop L1} //asm
}C++模塊 C++啟動程序從命令行讀取輸入和輸出文件名。在循環內調用 TranslateBuffer從文件讀取數據塊,加密,再將轉換后的緩沖區寫入新文件:
頭文件:
#pragma once // 防止頭文件被重復包含, 非標準(但廣泛支持)
//translat.h
void TranslateBuffer(char* buf, unsigned count,unsigned char eChar);調用源文件
//13.2.2 文件加密示例
//現在查看的簡短程序實現如下操作:讀取一個文件,對其進行加密,再將其輸出到另一個文件。
#include <iostream>
#include <fstream>
#include "translat.h"
using namespace std;int main(int argcount, char *args[])
{//從命令行讀取輸入和輸出文件if (argcount < 3) {cout << "Usage: encode infile outfile" << endl;return -1;}const int BUFSIZE = 2000;char buffer[BUFSIZE];unsigned int count; //字符計數unsigned char encryptCode;cout << "Encryption code [0-255]?";cin >> encryptCode;ifstream infile(args[1], ios::binary);ofstream outfile(args[2], ios::binary);cout << "Reading " << args[1] << " and creating "<< args[2] << endl;while(!infile.eof()) {infile.read(buffer, BUFSIZE);count = infile.gcount();TranslateBuffer(buffer, count, encryptCode);outfile.write(buffer, count);}return 0;
}用命令提示符運行該程序,并傳遞輸入和輸出文件名是最容易的。比如,下面的命令行讀取infile.txt,生成encoded.txt:
encode infile.txt encoded.txt
在VS2019中設置命令行參數
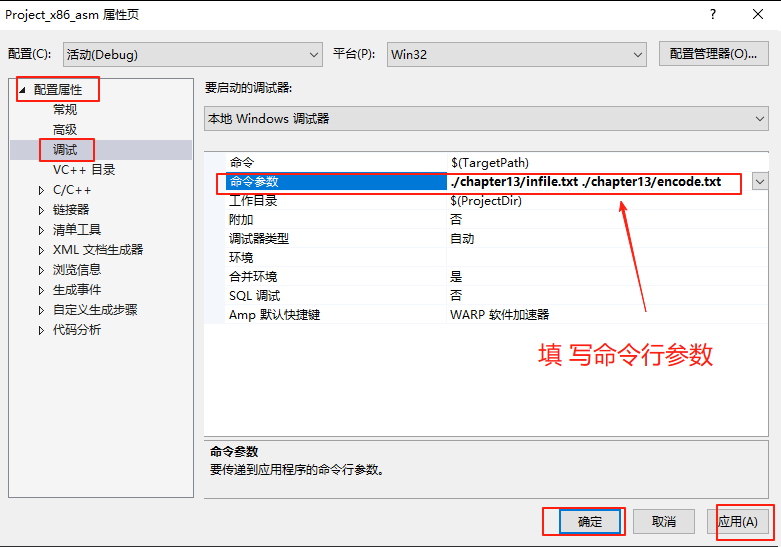
運行調試:

查看加密文件:

頭文件 頭文件translat.h包含了TanslateBuffer 的一個函數原型;
void TranslateBuffer(char* buf, unsigned count,unsigned char echar);
此程序位于本書\Examples\ch13\VisualCPP\Encode文件夾。
過程調用的開銷
如果在調試器調試程序時查看Disassembly窗口,那么,看到函數調用和返回究竟有多少開銷是很有趣的。下面的語句將三個實參送人堆棧,并調用 TranslateBuffer。在VisualC++的Disassembly 窗口,激活 Show Source Code和 Show Symbol Names 選項:
;TranslateBuffer(buffer, count, encryptCode)
movzx eax, byte ptr[encryptCode]
push eax
mov ecx, dword ptr [count]
push ecx
lea edx, [buffer]
push edx
call TranslateBuffer(0411834h)
add esp,0Ch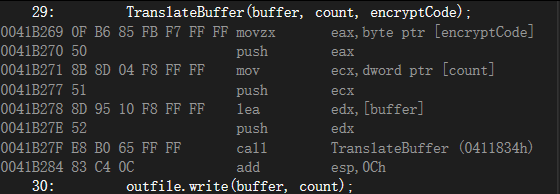
下面的代碼對TranslateBuffer進行反匯編。編譯器自動插人了一些語句用于設置EBP,以及保存標準寄存器集合,集合內的寄存器不論是否真的會被過程修改,總是被保存。
push ebp
mov ebp,esp
sub esp,0C0h
push ebx
push esi
push edi
mov edi,ebp
xor ecx,ecx
mov eax,0CCCCCCCCh
rep stos dword ptr es:[edi]
//代碼內嵌從這里開始
mov esi,dword ptr [buf]
mov ecx,dword ptr [count]
mov al,byte ptr [eChar]
xor byte ptr [esi],al
L1:
xor [esi], al;
inc esi
loop L1 (041B460h)
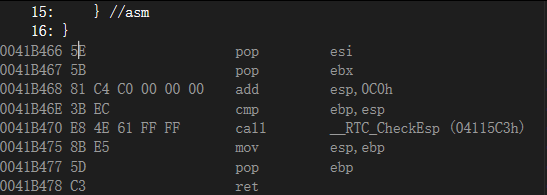
pop edi
//代碼內嵌結束
pop esi
pop ebx
add esp,0C0h
cmp ebp,esp
call __RTC_CheckEsp (04115C3h)
mov esp,ebp
pop ebp
ret 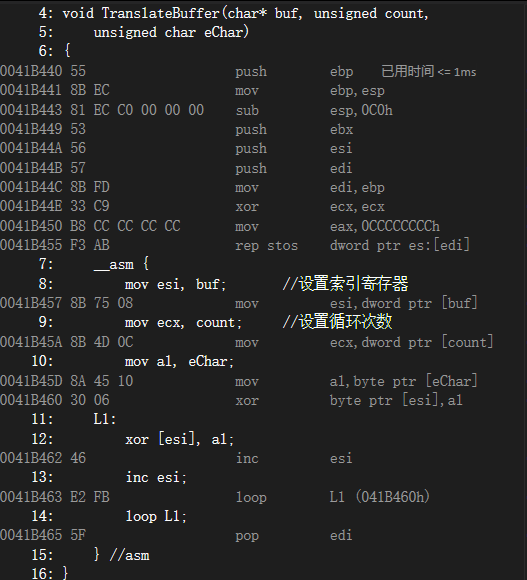
若關閉了調試器Disassembly窗口的Display Symbol Names 選項,則將參數送人寄存器的三條語句如下:
mov esi, dword ptr[ebp+8]
mov ecx, dword ptr [ebp+0ch]
mov al, byte ptr[ebp+10h]編譯器按要求生成Debug目標代碼,這是非優化代碼,適合于交互式調試。如果選擇Release 目標代碼,那么編譯器生成的代碼就會更加有效(但易讀性更差)。
忽略過程調用本小節開始時給出的TranslateBuffer中有6條內嵌指令,其執行總共需要8條指令。如果函數被調用幾千次,那么其執行時間就比較可觀了。為了消除這種開銷,把內嵌代碼插入調用TranslateBuffer的循環,得到更為有效的程序:
while(!infile.eof())
{infile.read(buffer, BUFFSIZE);count = infile.gcount();__asm {lea esi, buffer;mov ecx, count;mov al, encryptCode;L1:xor [esi],al;inc esi;loop L1;}//asmoutfile.write(buffer, count);}程序位于本書\Examples\ch13\VisualCPP\Encode Inline 文件夾。
13.2.3 本節回顧
1.內嵌匯編代碼與內嵌C++過程有什么不同之處?
答:內嵌匯編代碼是將匯編語言源代碼直接插入高級語言程序。反之,c++中的內嵌限定符則要求c++編譯器直接把函數體插入程序的編譯代碼,以便消除函數調用和返回所耗費的額外執行時間。(注意:回答這個問題需要用到本書并未涉及的一些c++語言知識。)
2.與使用外部匯編過程相比,內嵌匯編代碼有什么優勢?
答:編寫內嵌代碼的最大優點就是簡單,因為它沒有外部鏈接問題,命名哽,也不用考慮參數傳遞協議。其次,內嵌代碼執行速度更快,因為它避免了匯編語言過程和返回通常所需要的額外執行時間。
3.給出至少兩種在內嵌匯編代碼中添加注釋的方法。
答:注釋示例:
mov esi, buf ;initialize index register
mov esi, buf //initialize index register
mov esi, buf /*initialize index register*/
4.(是/否):內嵌語言是否可以引用_asm塊之外的代碼標號?
答:是




)







)






