path模塊
path模塊主要用于操作路徑。要使用path,首先需要引入path模塊。require('path')
path.resolve
用于拼接規范的絕對路徑。
如果想拼接一個路徑,有時候是使用字符串手動拼接的,但由于系統的規范不同,路徑中的\和/無法統一,有時候手動拼接的字符串路徑并不標準,path.resolve可以提供一種標準的絕對路徑。
path.resolve的參數是要拼接的路徑。path.resolve中,相對路徑可以省略./,但不能以/開頭,以/開頭的路徑會被識別為絕對路徑,作為根路徑與其他路徑參數進行拼接。
const path = require('path');let myPath = path.resolve(__dirname,'./demo.txt');path.sep
獲取操作系統的路徑分隔符
windows的分隔符是\?
linux的分隔符是/
const tmp = path.sep;path.parse
解析路徑并返回對象
__filename:和__dirname一樣是全局變量,里面保存的是文件所在文件夾的絕對路徑。
const path = require('path');const tmp = path.parse(__filename);
console.log(tmp);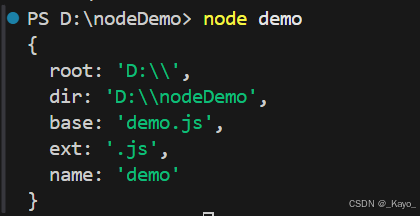
root:文件盤符;dir:文件所在文件夾的路徑;base:文件名;ext:擴展名;name:文件名。
path.basename
獲取文件名,對應parse里的base。
path.dirname
獲取文件所在文件夾的路徑,即parse里的dir。
path.extname
獲取擴展名,即parse里的ext。
HTTP協議
HTTP:Hypertext Transfer Protocol超文本傳輸協議。
HTTP是互聯網應用最廣泛的協議之一。
協議:雙方必須遵守的一組約定。
HTTP協議:對瀏覽器和服務器之間的通信進行了約束。
請求:瀏覽器向服務器發起的通信。
響應:服務器給瀏覽器返回的結果。
請求報文:瀏覽器給服務器發送的數據。
響應報文:服務器給瀏覽器返回的數據。
請求報文和響應報文都是HTTP報文。
當在瀏覽器中敲入URL,按回車時,瀏覽器就給對應的服務器發送了請求。
HTTP報文:
想要查看HTTP報文,可以借助工具,一個可以查看HTTP報文的工具是fiddler。fiddler的原理是,在安裝了fiddler之后,瀏覽器會把請求發給fiddler,fidder把請求轉發給服務器。服務器響應時,也把響應傳給fiddler,fiddler轉發給瀏覽器。
fiddler的下載:Download Fiddler Web Debugging Tool for Free by Telerik
官網填一下信息就能下載了。下載一路Next和agree就可以。
打開軟件后,點擊導航欄Tools下的options,勾選Decrypt HTTPS traffic按鈕,并在彈窗的時候選擇yes。然后重啟fiddler。
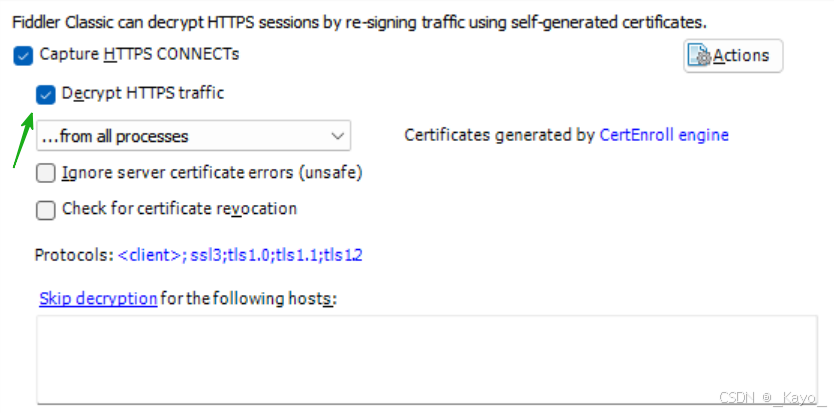
重新進入后,可以選擇只看瀏覽器請求,在左下角點擊All Processes,選擇Web Browsers。

如果想清空列表,可以點擊上面導航欄里的X,選擇Remove all。
![]()
想查看一個報文時,雙擊列表里的報文,就能在右側看到報文信息:
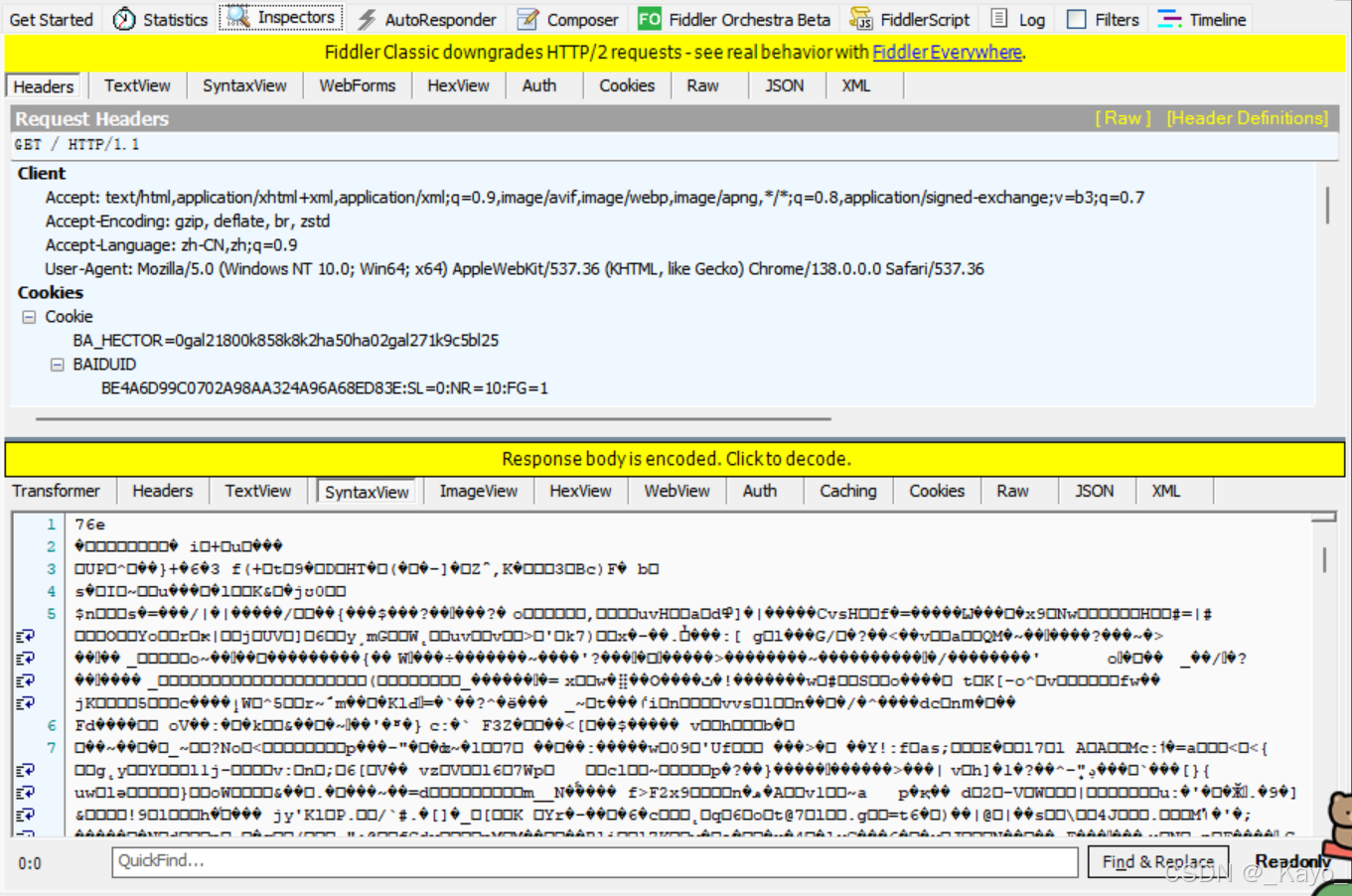
信息上面是請求報文Request,下面是響應報文Response。
原始請求/響應報文,可以點擊Raw查看。
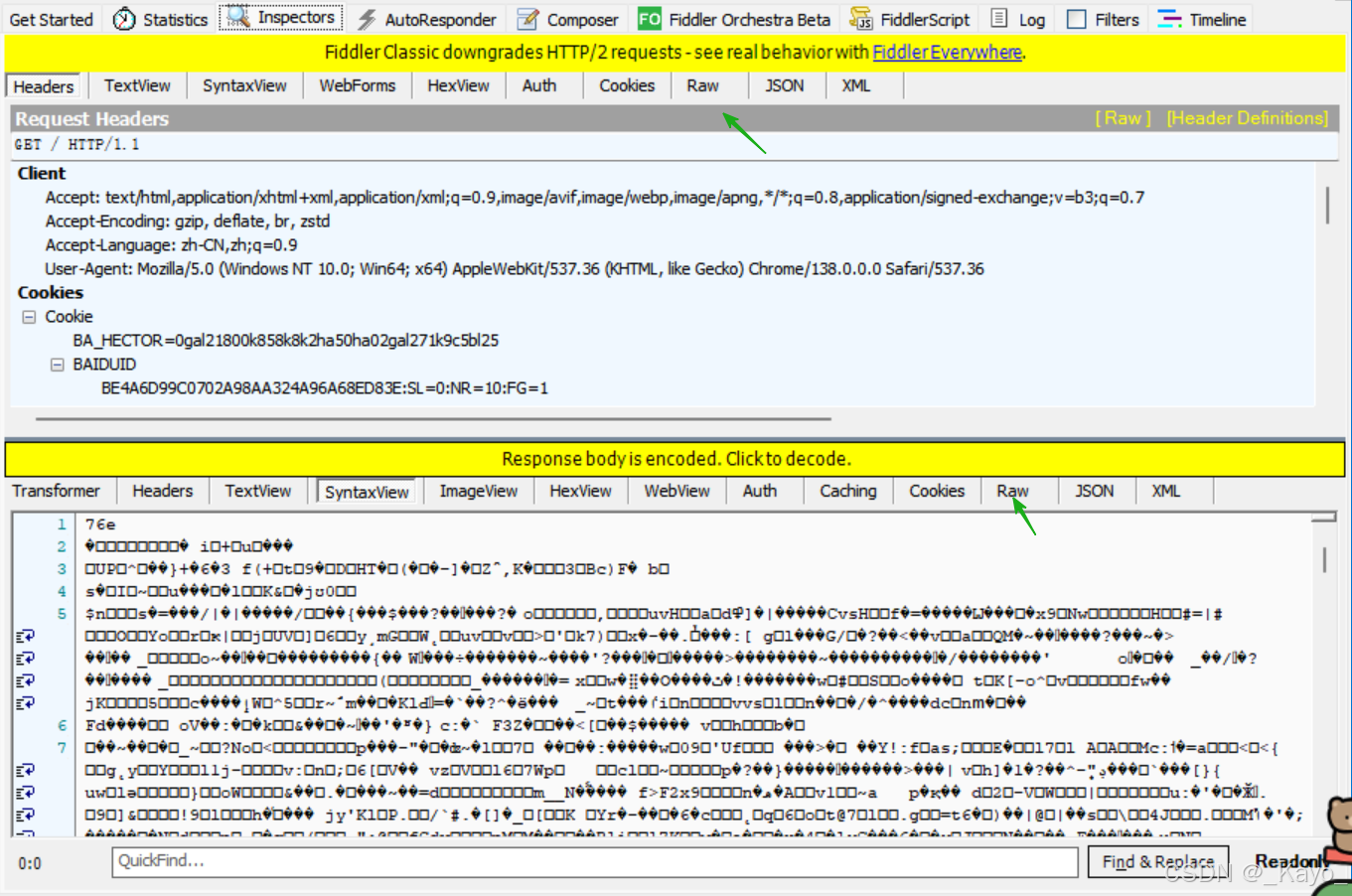
按照提示點擊Response body is encoded.Click to decode,可以自動解碼,讓響應報文的信息不再是亂碼。
HTTP請求報文的結構:
以請求百度為例,點擊請求報文的raw,獲取如下信息:
GET https://www.baidu.com/ HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
sec-ch-ua: "Not)A;Brand";v="8", "Chromium";v="138", "Google Chrome";v="138"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36
Sec-Purpose: prefetch;prerender
Purpose: prefetch
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9
Cookie: BDUSS_BFESS=tJWE0tSExLdERyYzd-WnJYY29TY3E4NjBHbWkzUG9PWDY3TXNWbHNZeUVQS3htRVFBQUFBJCQAAAAAAAAAAAEAAAB5dRPqza~E6sPmsPx0b3BhegAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAISvhGaEr4RmeG; PSTM=1733825412; BIDUPSID=04F444AAF0FB821D9DB875112E6F48D0; BD_UPN=12314753; MAWEBCUID=web_SEdQpQMWNWJYnmjuCByJwhagZSZOaTHKPCtmgSwfuNPUFTOFxs; BAIDUID=BE4A6D99C0702A98AA324A96A68ED83E:SL=0:NR=10:FG=1; H_WISE_SIDS_BFESS=62325_62969_63144_63195_63210_63243_63253_63357_63378_63383_63186_63394_63393_63390_63404; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; BD_CK_SAM=1; PSINO=2; BAIDUID_BFESS=BE4A6D99C0702A98AA324A96A68ED83E:SL=0:NR=10:FG=1; channel=baidusearch; baikeVisitId=f15c073a-0ffd-49e0-b898-40144ff8ef9c; BA_HECTOR=0gal21800k858k8k2ha50ha02gal271k9c5bl25; ZFY=L5NO43JVWWU3MBZjCkIsDKlDxVFGdwgXI2KmQMmDaeI:C; H_PS_PSSID=62325_63144_63947_64011_64127_64173_64248_64245_64258_64260_64269_64308_64318_64326_64366_64362_64363_64403_64413_64427; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_WISE_SIDS=62325_63144_63947_64011_64127_64173_64248_64245_64258_64260_64269_64308_64318_64326_64366_64362_64363_64403_64413_64427; sug=3; sugstore=0; ORIGIN=0; bdime=0; H_PS_645EC=49earUefVsN%2ByYhzjL%2FWcXOSkQUH045XqWgq7TUmq1bdcgOP3TfA%2Bf%2FF7XUPvfcklN8e; Hm_lvt_aec699bb6442ba076c8981c6dc490771=1754359961,1754490996,1754610718,1754750394; Hm_lpvt_aec699bb6442ba076c8981c6dc490771=1754750394; HMACCOUNT=4DF589D7A7F85E98; BDSVRTM=0; COOKIE_SESSION=34_0_6_8_10_8_0_0_6_7_0_1_42_0_42_0_1754750434_0_1754750392%7C9%232283914_3_1754268230%7C2HTTP報文由三部分組成:請求行,對應上面的Get https://www.baidu.com/ HTTP/1.1。請求行是報文的第一行內容。
第二行開始到空行處是請求頭,對應上面Host行到Cookie行。
剩下的內容是請求體,本次請求目前請求體是空的,所以空行后沒有內容。
請求頭和請求體之間有一行空行。
請求行:
GET https://www.baidu.com/ HTTP/1.1請求行由三部分組成:請求方法(GET)、URL(https://www.baidu.com/)、HTTP版本號(HTTP/1.1)。
請求方法:
HTTP請求常見的請求方法有:GET(獲取數據)、POST(新增數據)、PUT/PATCH(更新數據)、DELETE(刪除數據)。
還有一些平常比較少用的方法:HEAD、OPTIONS、CONNECT、TRACE。
GET的應用場景:在地址欄中直接輸入URL訪問、點擊a鏈接、link標簽引入css、script標簽引入js、video與audio引入多媒體;img標簽引入圖片;form標簽中method為get、ajax的get請求。
POST的應用場景:form標簽中method為post;ajax的POST請求。
GET和POST的區別:
1.作用不同,GET主要用來獲取數據,POST主要用來提交數據(但這不是絕對的,也可以通過POST獲取數據,通過GET提交數據)。
2.參數的位置不同,GET的參數是將參數放在URL中,而POST請求的參數是在請求體中(但這也不是絕對的,GET請求也可以設置請求體,POST請求也可以在URL中傳參,只是一般不會這么用)。
3.安全性不同:POST相對GET來說安全一些,因為GET請求時,參數會暴露在地址欄中。
4.GET請求的大小有限制,一般為2K,而POST請求的大小沒有限制。
URL:
Uniform Resource Locator 統一資源定位符
URL是一個字符串,用于定位服務器中的資源。服務器中有很多資源,URL用于定位其中的某一個資源,服務器找到URL對應的資源后返回結果。
URL的組成:
以下面的路徑為例:
https://mp.csdn.net:80/mp_blog/creation/editor?spm=1001.2014.3001.4503https://mp.csdn.net:80/mp_blog/creation/editor?spm=1001.2014.3001.4503
協議名:https
主機名:mp.csdn.net
端口號:80
路徑:/mp_blog/creation/editor
查詢字符串:?spm=1001.2014.3001.4503
URL中,端口號之后,?之前的部分是路徑,路徑用于定位服務器中的某一個資源。
查詢字符串是?及后面的部分,格式是key1=value1&key2=value2&key3=value3……,查詢字符串用于向服務器傳遞參數,是對請求資源額外的一種描述。
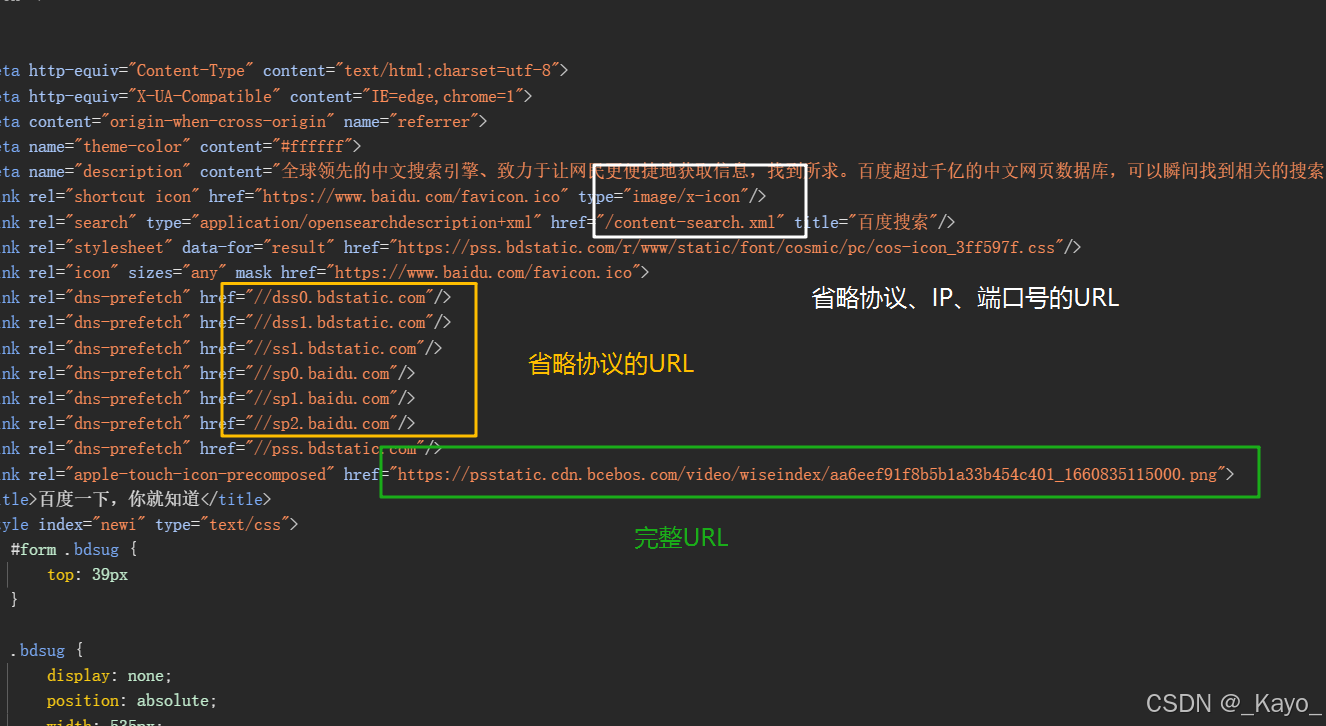
URL有絕對路徑和相對路徑兩種形式。
絕對路徑:絕對路徑有三種形式,一種是整個完整的路徑;一種是省略協議的URL(省略協議時,會把當前頁面的協議和URL拼接形成完整的URL);一種是省略URL、IP地址、端口號的URL,以\開頭(省略URL、IP地址、端口號時,會把當前頁面的URL、IP地址、端口號和以\開頭的URL進行拼接,形成完整的URL)。
在使用省略URL、IP、端口號的絕對路徑時,可以避免當前請求服務器主機名改變時,需要修改URL的問題。
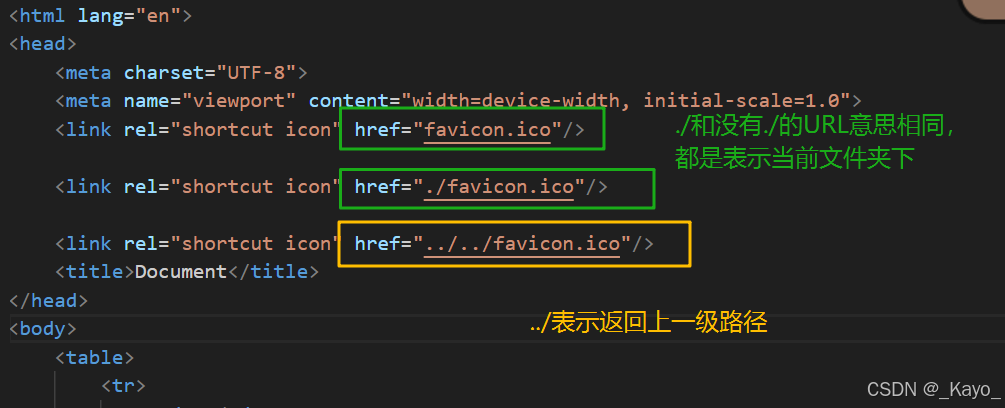
相對路徑:
相對路徑也有多種形式,以./開頭的路徑;直接就是文件路徑沒有./;../開頭的路徑。
使用相對路徑時,需要與當前URL頁面路徑進行計算,得到完整的URL之后,再發送請求。
比如當前的目錄是http://www.text.com/login/myLogin,如果請求的URL是../img/login.png,最終的請求路徑是http://www.text.com/login/img/login.png。
如果請求URL是text.css,或./text.css最終的請求路徑是http://www.text.com/login/myLogin/text.css。
相對路徑是不可靠的,在實際開發中,很少使用相對路徑。
URL使用場景:a href、link href、script src、img src、video src、audio src、form action、ajax url等,在這些地方,URL可以是相對路徑,也可以是絕對路徑。
HTTP版本號:
HTTP版本:1.0(1996年發布)、1.1(1999年發布)、2(2015年發布)、3(2018年發布)
請求頭:
請求頭是以一系列的key(鍵名):value(鍵值)對組成。
請求頭中可以記錄瀏覽器相關的一些信息:
User-Agent:記錄了瀏覽器的平臺、版本號等。
Accept:記錄了瀏覽器能夠處理的數據類型。
Accept-Encoding:記錄了瀏覽器支持的壓縮方式。
Accept-Language:記錄瀏覽器支持的語言。
Cookie:用于會話控制。
除了瀏覽器信息,請求頭中還有交互的行為信息:
Connection: Keep-alive。設置保持連接通道。
Upgrade-Insecure-Requests:1。設置升級HTTP請求為HTTPS,提高通信的安全性。
請求頭中還可以記錄和請求體相關的信息。
請求體:
請求體的內容格式非常靈活,可以設置任意內容。
請求體使用比較多的格式,是一個數組或者對象,且請求體是json格式。
HTTP響應報文:
HTTP/1.1 200 OK
Connection: keep-alive
Content-Security-Policy: frame-ancestors 'self' https://chat.baidu.com http://mirror-chat.baidu.com https://fj-chat.baidu.com https://hba-chat.baidu.com https://hbe-chat.baidu.com https://njjs-chat.baidu.com https://nj-chat.baidu.com https://hna-chat.baidu.com https://hnb-chat.baidu.com http://debug.baidu-int.com https://sai.baidu.com https://mcpstore.baidu.com https://mcpserver.baidu.com https://www.mcpworld.com https://platform-openai.now.baidu.com;
Content-Type: text/html; charset=utf-8
Date: Sat, 09 Aug 2025 14:50:32 GMT
Server: BWS/1.1
Set-Cookie: H_PS_PSSID=62325_63144_63947_64011_64127_64173_64248_64245_64258_64260_64269_64308_64318_64326_64366_64362_64363_64403_64413_64427; path=/; expires=Sun, 09-Aug-26 14:50:32 GMT; domain=.baidu.com
Traceid: 1754751032349825665010009797973434738610
X-Ua-Compatible: IE=Edge,chrome=1
X-Xss-Protection: 1;mode=block
Content-Length: 654507<!DOCTYPE html><!--STATUS OK--><html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="origin-when-cross-origin" name="referrer"><meta name="theme-color" content="#ffffff"><meta name="description" content="全球領先的中文搜索引擎、致力于讓網民更便捷地獲取信息,找到所求。百度超過千億的中文網頁數據庫,可以瞬間找到相關的搜索結果。"><link rel="shortcut icon" href="https://www.baidu.com/favicon.ico" type="image/x-icon" /><link rel="search" type="application/opensearchdescription+xml" href="/content-search.xml" title="百度搜索" /><link rel="stylesheet" data-for="result" href="https://pss.bdstatic.com/r/www/static/font/cosmic/pc/cos-icon_3ff597f.css"/><link rel="icon" sizes="any" mask href="https://www.baidu.com/favicon.ico"><link rel="dns-prefetch" href="//dss0.bdstatic.com"/><link rel="dns-prefetch" href="//dss1.bdstatic.com"/><link rel="dns-prefetch" href="//ss1.bdstatic.com"/><link rel="dns-prefetch" href="//sp0.baidu.com"/><link rel="dns-prefetch" href="//sp1.baidu.com"/><link rel="dns-prefetch" href="//sp2.baidu.com"/><link rel="dns-prefetch" href="//pss.bdstatic.com"/><link rel="apple-touch-icon-precomposed" href="https://psstatic.cdn.bcebos.com/video/wiseindex/aa6eef91f8b5b1a33b454c401_1660835115000.png"><title>百度一下,你就知道</title><style index="newi" type="text/css">#form .bdsug{top:39px}.bdsug{display:none;position:absolute;width:535px;background:#fff;border:1px solid #ccc!important;_overflow:hidden;box-shadow:1px 1px 3px #ededed;-webkit-box-shadow:1px 1px 3px #ededed;-moz-box-shadow:1px 1px 3px #ededed;-o-box-shadow:1px 1px 3px #ededed}.bdsug li{width:519px;color:#000;font:14px arial;line-height:25px;padding:0 8px;position:relative;cursor:default}.bdsug li.bdsug-s{background:#f0f0f0}.bdsug-store span,.bdsug-store b{color:#7A77C8}.bdsug-store-del{font-size:12px;color:#666;text-decoration:underline;position:absolute;right:8px;top:0;cursor:pointer;display:none}.bdsug-s .bdsug-store-del{display:inline-block}.bdsug-ala{display:inline-block;border-bottom:1px solid #e6e6e6}.bdsug-ala h3{line-height:14px;background:url(//www.baidu.com/img/sug_bd.png?v=09816787.png) no-repeat left center;margin:6px 0 4px;font-size:12px;font-weight:400;color:#7B7B7B;padding-left:20px}.
.......
*** FIDDLER: RawDisplay truncated at 262144 characters. Right-click to disable truncation. ***HTTP響應報文也由三部分組成:響應行、響應頭、響應體。
在響應頭和響應體之間有空行。
響應行:
HTTP/1.1 200 OK由三部分組成:HTTP版本號(HTTP/1.1)、響應狀態碼(200)、響應狀態的描述(OK)
響應狀態碼:
是三位的數字,用來標識響應的結果狀態。
常見響應狀態碼:200(請求成功)、403(禁止請求)、404(找不到資源)、500(服務器內部錯誤)。
響應狀態碼的分類:1xx(信息響應)、2xx(成功響應)、3xx(重定向消息)、4xx(客戶端錯誤響應)、5xx(服務端錯誤響應)。
通過狀態碼,可以得知請求的結果。
響應狀態的描述:
響應狀態的描述是一個字符串,他與響應狀態碼是保持一一對應的。
200(OK)、403(Forbidden)、404(Not Found)、500(Internal Server Error)。
響應狀態碼的具體含義可以到MDN文檔上查詢。
響應頭:
記錄了與服務器相關的信息:
Server:記錄了服務器使用的技術。
Data:記錄了響應的時間。
記錄了與響應體相關的信息:
Content-Type:聲明響應體應用的格式與字符集。
Content-Length:記錄響應體的長度,單位是字節。
響應頭同樣可以到MDN上查詢。如果某個響應頭在MDN上無法搜到,這個響應頭是服務器自定義的,用于傳輸個性化數據。
響應體:
響應體與請求體類似,格式十分靈活,可以傳遞各種信息。
常見的響應體有:HTML、CSS、JavaScript、圖片、視頻、JSON等。
IP
IP類似于快遞的收件地址,在網絡世界中,IP地址用于尋找網絡設備。
IP也叫IP地址,是一個數字標識。
IP是32位的二進制數字,IP的表示方式,是把每8位(一字節)分為一組,再把8位二進制轉換為十進制數字,各組之間用點分隔。
IP地址的作用:標識網絡中的設備,實現設備間的通信。
每一個接入網絡的設備,手表、音響、電視、主機等,都有自己的IP地址。有了IP地址,通信雙方就可以通過IP找到對方。設備和設備之間才能通信。
IP共享技術:
32位二進制數據最多能表示2的32次方的IP地址,即42(億)94967296個。
但這個數字遠遠小于世界人口,如果人手一個設備,IP地址是不夠的,尤其是現在社會下,很多人往往擁有多個設備。
在32位IP不夠用的情況下,提出了一些共享IP的技術。
區域共享:在一個區域下的設備,所有設備共享一些IP。
家庭共享:家庭里的設備,所有設備共用一個IP。
比如在家庭里,所有的設備(手機、電腦、打印機、顯示器)都連接(通過WIFI或者物理線路)到路由器,路由器給每個設備都分配一個IP地址,而路由器本身也有一個IP地址,就形成了一個局域網。路由器分配的IP地址叫局域網IP,也叫私網IP。在局域網中,設備之間可以互相通信。如果想和其他網絡通信,路由器就需要接入互聯網。通過到通信公司(連通、移動)等辦理業務,可以接入互聯網。會從外部拉一根線到路由器上,接到這根線之后,路由器會有另一個IP,這個IP被稱為廣域網IP(或叫公網IP),有了公網IP,就可以和外部的網絡通信。
每一個家庭都可以按照同樣的方式分配IP,每個家庭內部都可以按同樣的IP分配IP地址,進行IP的復用(實現局域網復用)。再通過不同的公網IP,就可以實現相互的通信。
本地回環IP地址:
這個IP一直指向當前的設備本身。
IP分類:
本機回環IP地址:127.0.0.1~127.255.255.254
局域網IP(私網IP):192.168.0.0~192.168.255.255、172.16.0.0~172.31.255.255、10.0.0.0~10.255.255.255
廣域網IP(公網IP):除本機回環IP地址和局域網IP的IP
以上分類只是一個籠統的分類,如果想了解IP的分類細節,需要去學習IP標準分類。
端口
端口是應用程序的數字標識。
一臺計算機有65536個端口,端口號的范圍是0~65535。
一個應用程序可以使用一個或多個端口。
端口的作用:實現不同主機應用程序之間的通信。也就是說,當需要與一臺計算機通信時,通過IP可以找到這臺計算機,但是數據具體應該傳輸給哪個程序,是通過端口確定的。
HTTP模塊
通過node.js創建一個HTTP服務:有了HTTP服務,就可以處理瀏覽器發送過來的HTTP請求,并且給瀏覽器發送響應。
HTTP服務創建步驟:
1.導入HTTP模塊
const http = require('http')
2.創建服務對象
http.createServer() 用于創建服務對象,返回結果是一個對象。
http.createServer接收一個參數,該參數是一個函數,函數的參數是request(請求)、response(響應)。request是一個對象,是瀏覽器發來的請求報文的封裝對象。借助于這個對象,可以獲取請求報文的信息。response是對響應報文的封裝對象,可以用response給瀏覽器設置響應信息。該函數當服務器端接收到HTTP請求時執行。
const server = http.createServer((request,response)=>{
? ? ? ? response.end('Hello world')
})
response.end()用于設置響應體,并結束響應。
3.監聽端口,啟動服務
server.listen()。
參數是(端口號,回調函數),端口號是給當前服務器端設置的端口,回調函數在服務器端啟動成功時調用。
server.listen(5005,()=>{
? ? ? ? console.log('server start');
})
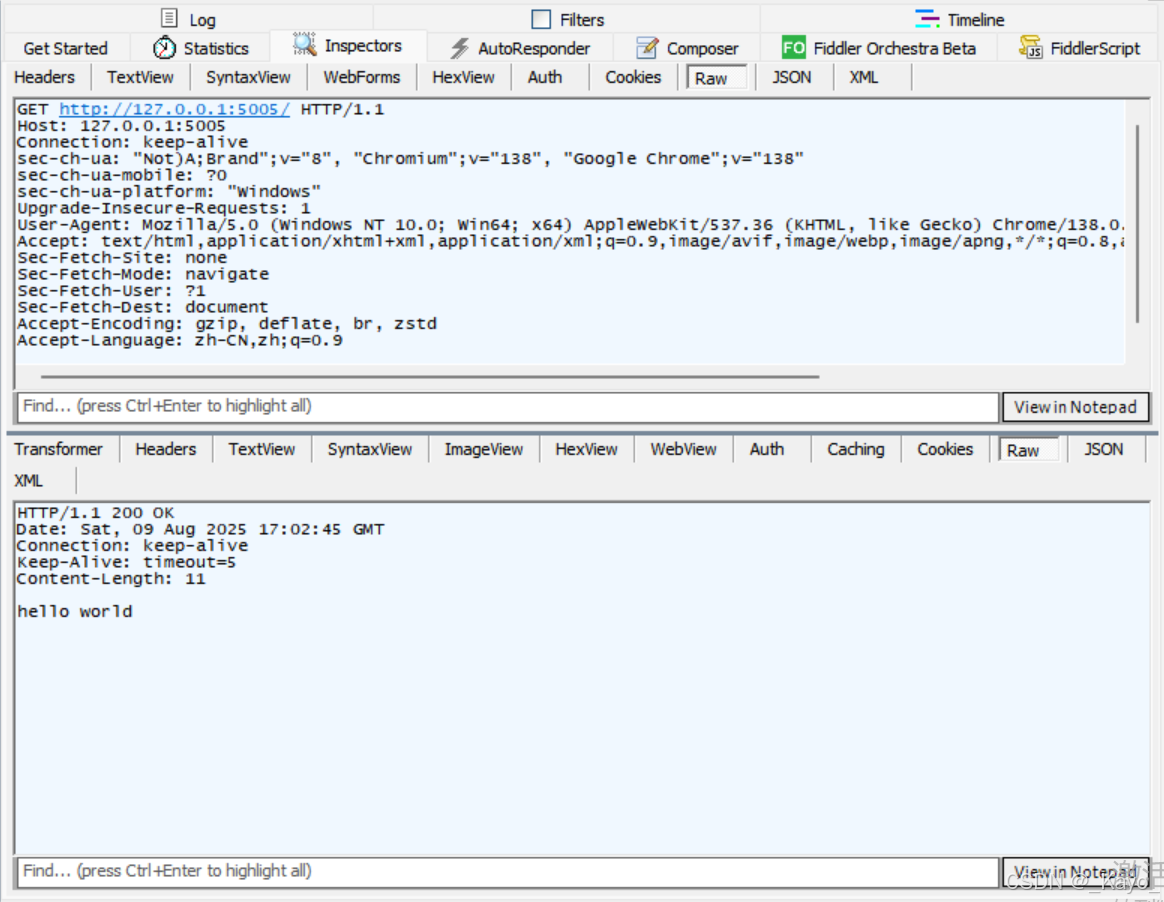
const http = require('http');const server = http.createServer((request,response)=>{response.end('hello world');}
)server.listen(5005, ()=>{console.log('server start!');
} )當有人往服務器IP:5005發送請求時,這個請求會被交給當前開啟的服務器處理。在http.createServer中配置的參數函數(回調函數)會被執行。
用fiddler查看這個請求:
啟動服務之后如何停止服務:在命令行敲Ctrl+c
當服務器端的代碼有更新,需要保存代碼,重新啟動服務器之后,才能生效。
響應體中如果有中文,會出現亂碼:
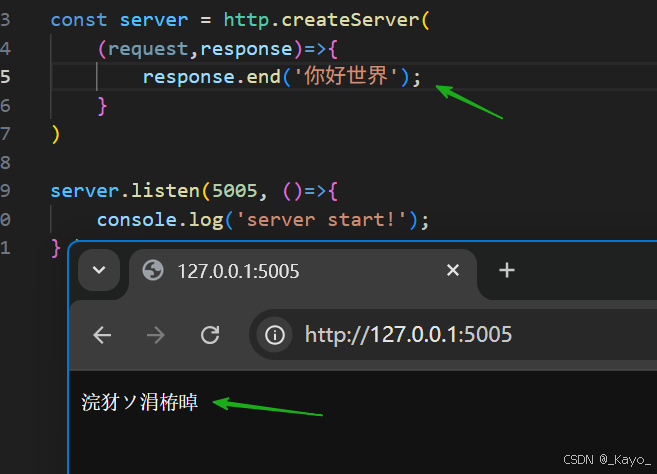
這是由于字符集設置有問題,可以通過response.setHeader設置響應頭,這個方法接收兩個參數,第一個參數是響應頭的名字,第二個參數是該key的value值。
在這里需要設置content-type為text/html;charset=utf-8。這個響應頭content-type可以告知瀏覽器響應體內容是text/html,字符集是utf-8。
const http = require('http');const server = http.createServer((request,response)=>{response.setHeader('content-type','text/html;charset=utf-8');response.end('你好世界');}
)server.listen(5005, ()=>{console.log('server start!');
} )如果當前服務器設置的端口號已經被其他程序使用了,服務器無法正常啟動,啟動會報錯。可以把占用端口的程序停掉,空出這個端口解決問題。也可以更換當前服務器的端口為一個沒有程序使用的端口。
借助資源監視器,可以找到占用端口的程序。在開始里面搜索資源監視器并打開:
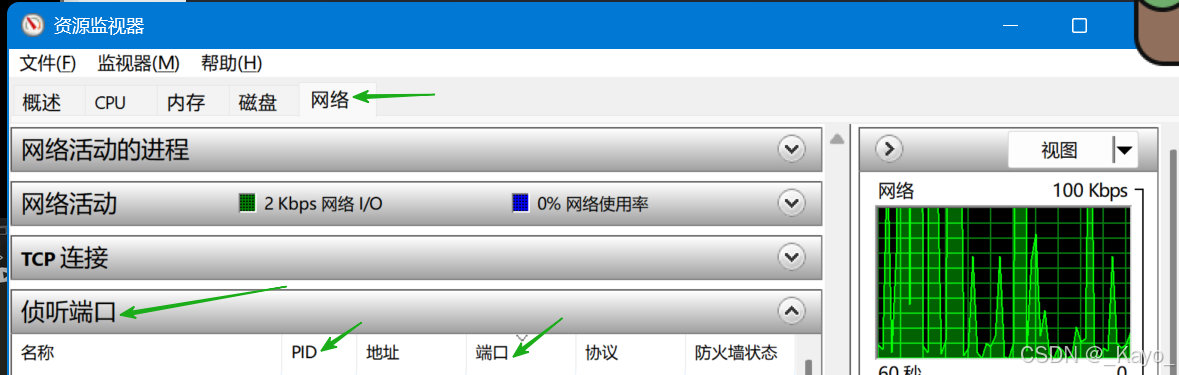
點擊網絡,在偵聽端口界面根據找到對應的程序,記住對應程序的PID:
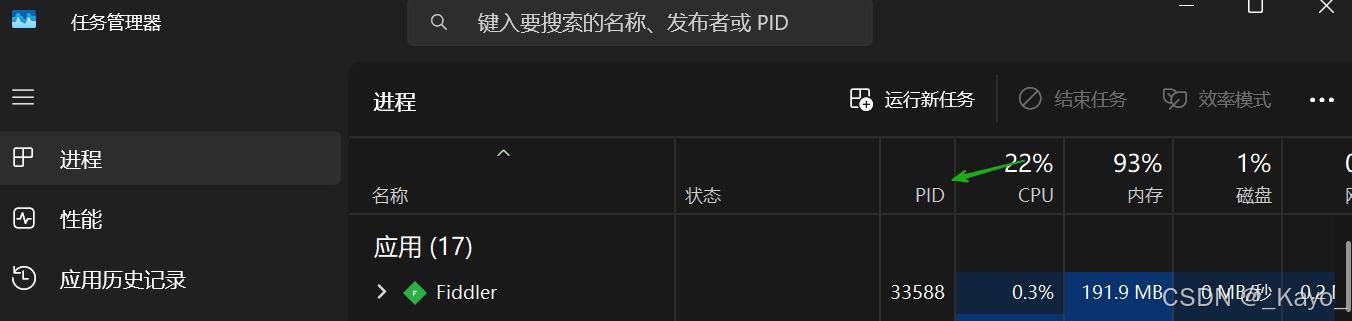
打開任務管理器,找到對應的PID,把程序停掉:
HTTP協議的默認端口是80。在給服務器發送請求時,如果不添加端口號,則端口號是默認端口80。
HTTPS協議默認端口是443。
HTTP開發常用的端口:3000、8080、8090、9000等。
瀏覽器查看HTTP報文:
在瀏覽器中點擊F12,打開開發者窗口。點擊網絡(NetWork),可以查看網站使用過程中的所有報文信息。
favicon.ico:該請求是谷歌瀏覽器的默認行為,每次打開網頁時,都會發送這個請求去獲取網頁圖標。網頁圖標:網頁頁簽上的圖標。
點擊想查看的請求,右邊會出現請求報文和響應報文信息:
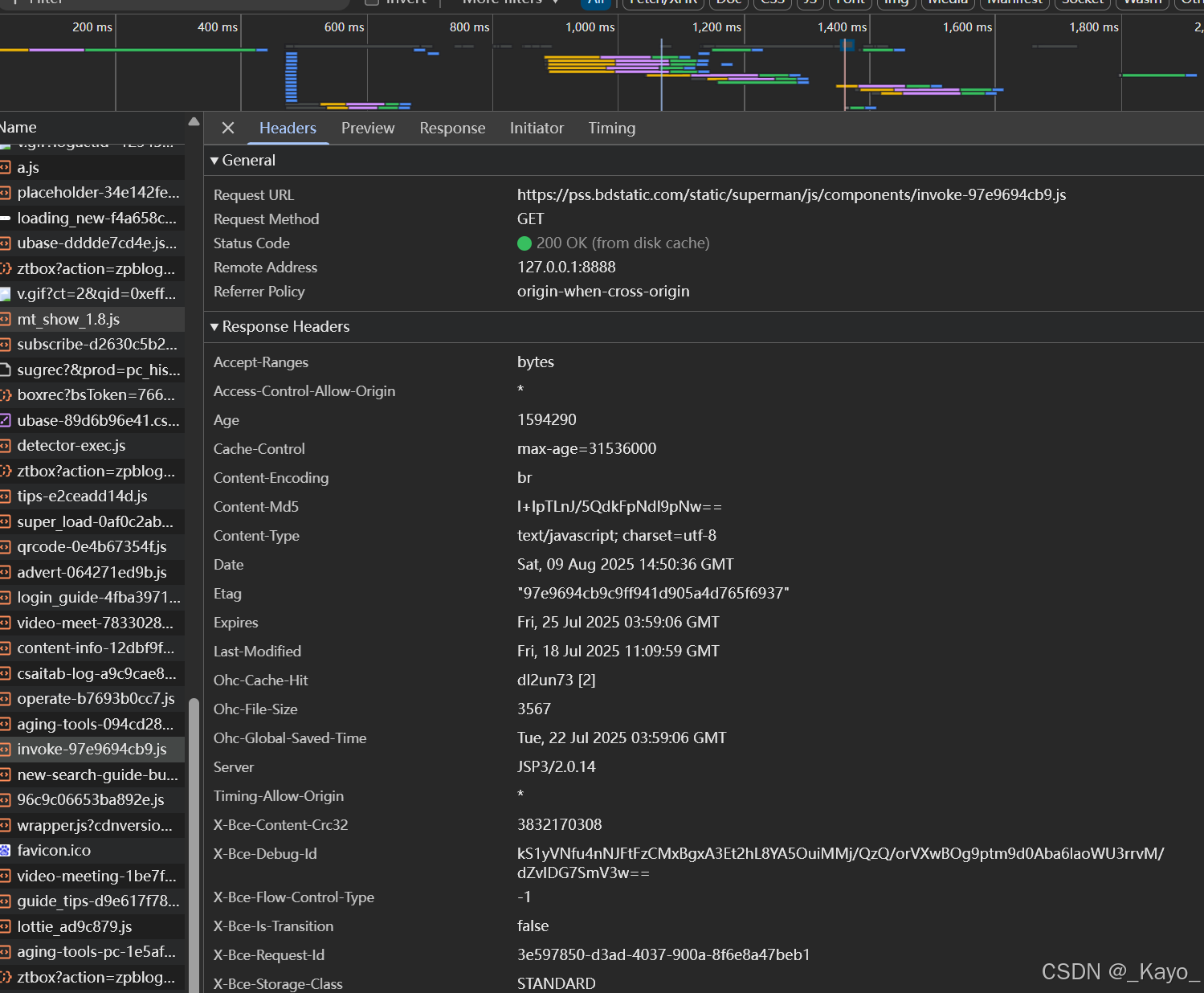
請求體內容可以在載荷(payload)中查看。GET請求沒有payload。
URL中的查詢字符串(?key1=value1&key2-value2&……)也可以在載荷里查看。
響應體在響應(Response)里查看。
在實際開發中,一般都是通過瀏覽器查看報文,不需要使用額外的工具。
提取HTTP請求報文:
本小節介紹如何在node.js服務器中提取報文信息。在瀏覽器把請求發送給后端時,后端服務器為了給瀏覽器返回正確的結果,就需要根據請求報文獲取相關信息。
在http.createServer回調函數的參數request中,獲取請求報文的相關信息。
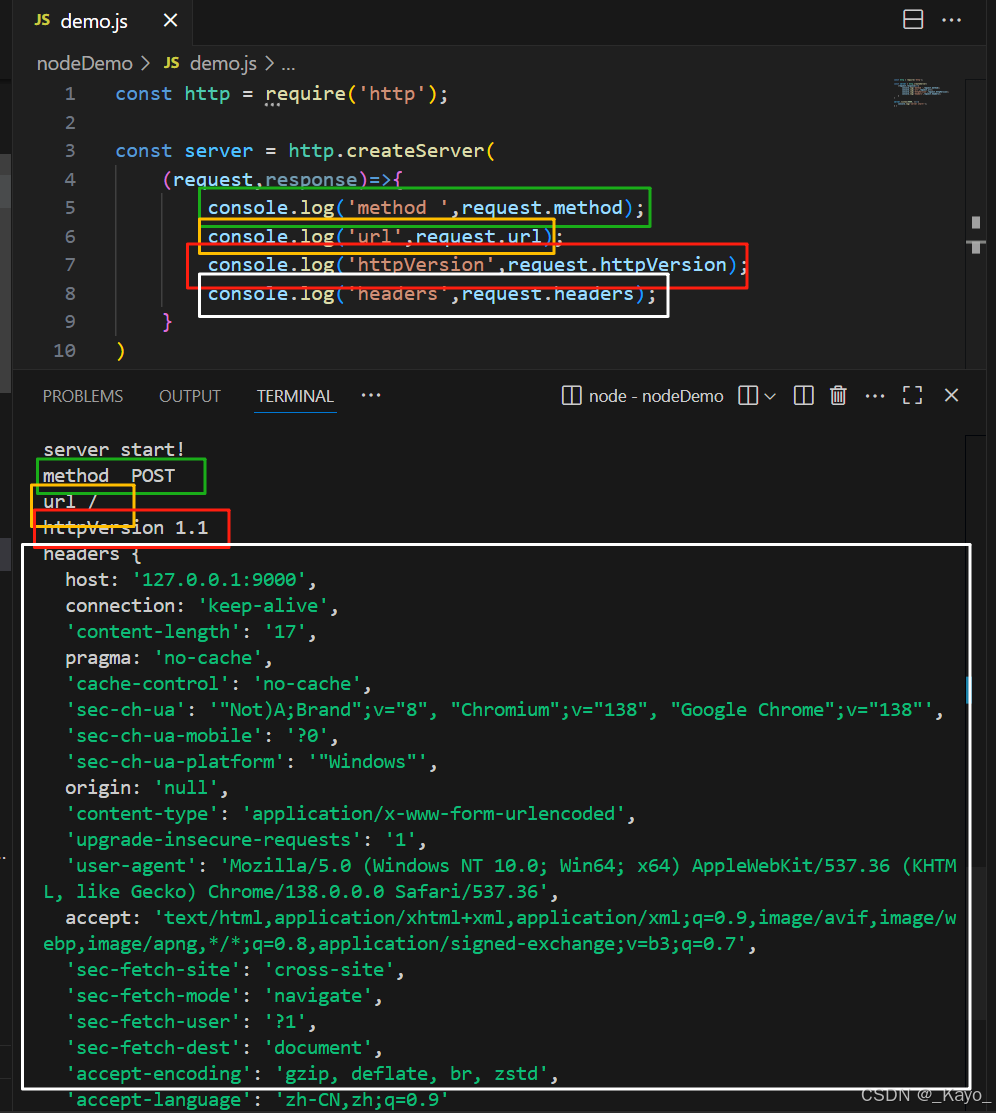
request.method
可以獲取請求報文中,請求行的請求方法,也就是GET、POST等。
request.httpVersion
可以獲取請求報文中,請求行的HTTP協議版本號。
request.headers
可以獲取請求報文的請求頭。
返回的結果是一個對象,對象中包含請求頭中的所有內容。
對象中,key的字母都是小寫字母。
如果只想獲取某個具體的請求頭,可以通過request.headers.key獲取。
提取URL:
request.url
可以獲取請求報文中,請求行的URL。
URL中只包含URL路徑和查詢字符串。
如果想獲取請求中的URL信息,雖然也可以使用request的url屬性獲取,但這種方式獲取的路徑有時候并不能滿足開發需求,可以使用Url模塊,更好地解析URL路徑。
url模塊
1.導入Url模塊
const url = require('url');
2.使用url模塊
url.parse(request.url); 用于提取request.url中的URL信息。
url.parse接收兩個參數,第一個參數是需要解析的URL,第二個參數是設置URL中的query屬性如何解析,如果是true,query屬性是一個對象。
const http = require('http');
const url = require('url');
const server = http.createServer((request,response)=>{console.log(url.parse(request.url));}
)server.listen(9000, ()=>{console.log('server start!');
} )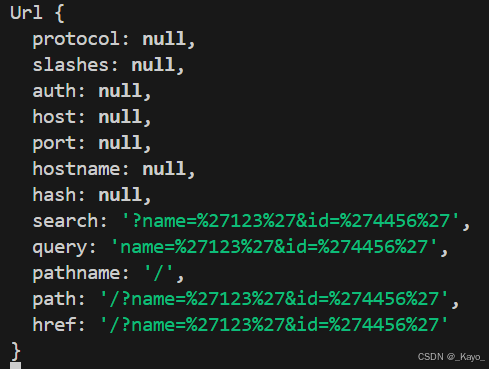
pathname:URL路徑。
query:查詢字符串。如果調用url.parse時,第二個參數不傳,或者為false,則返回的是字符串。如果是true,則返回對象。
設置url.parse第二個參數為true:
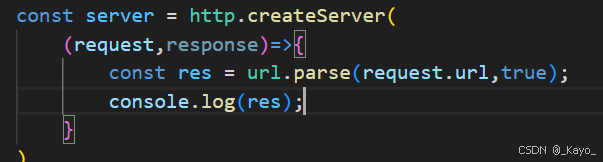
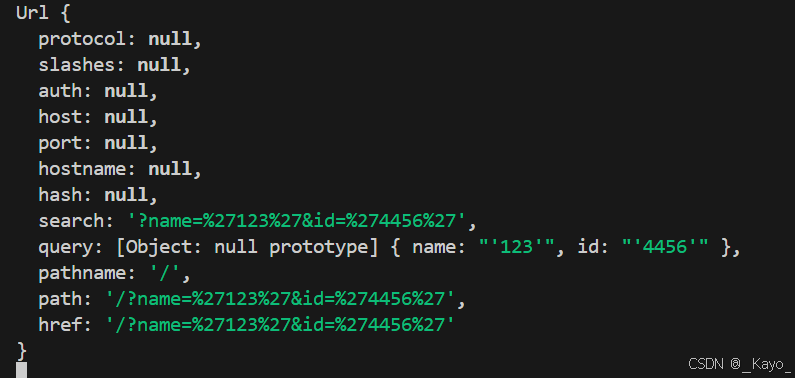
[Object:null prototype]只是一個提示,表示這個對象的原型指向null。
通過res.query.key,可以獲取query的value。
除了通過url模塊獲取URL,還可通過實例化URL對象獲取URL數據:
實例化URL對象
let url = new URL(URL地址)
URL地址可以有兩種形式:1.一個完整的URL地址;2.分成兩個參數,第一個參數是路徑和查詢字符串,第二個參數是協議、IP和端口號。
const http = require('http');const server = http.createServer((request,response)=>{const url = new URL('http://127.0.0.1:9000'+request.url);const url2 = new URL(request.url,'http://127.0.0.1:9000');console.log(url);console.log(url2);}
)server.listen(9000, ()=>{console.log('server start!');
} )![]()
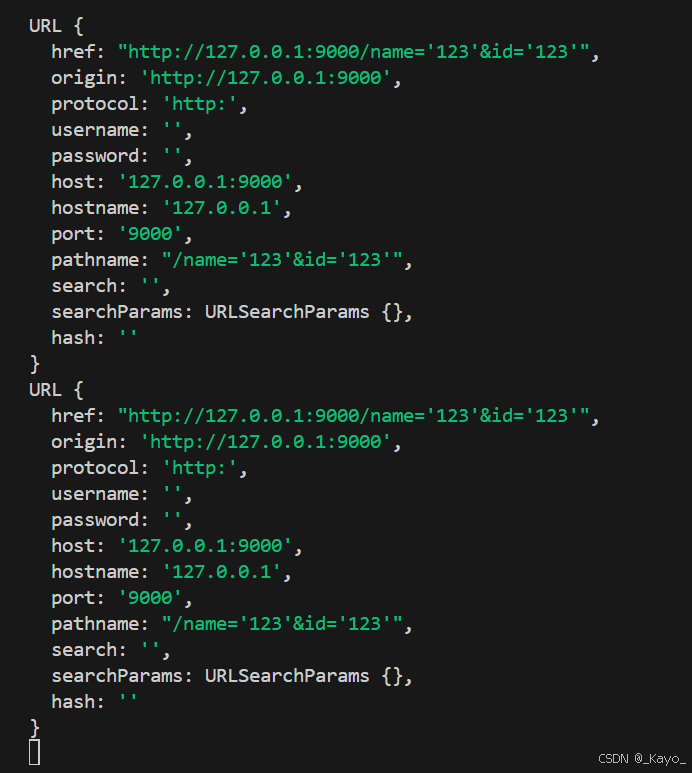
在URL中,serch和serchParams存儲著查詢字符串,search是字符串的形式,而searchParams是一種類對象的形式,如果想通過searchParams獲取key對應的value,語法是url.searchParams.get(key)。
獲取請求體
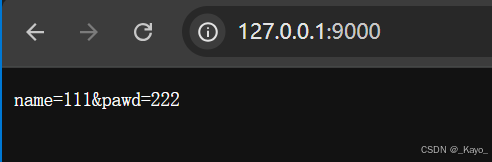
寫一個簡單的HTML,給服務器發送POST請求:
<body><form action="http://127.0.0.1:9000" method="post"><input type="text" name="name"><input type="password" name="pawd"><input type="submit" value="提交"></form>
</body>1.給request綁定事件:
request.on('data',回調函數)
request請求體對象是一個可讀流對象,可以通過可讀流把request中的數據讀取。
let bodyData = '';
request.on('data',(chunk)=>{
? ? ? ? bodyData += chunk;
});
chunk本身是一個Buffer,但是當使用+操作時,chunk會自動轉換為字符串。
2.綁定end事件
end事件在可讀流讀完后會進行回調。可以在函數中設置響應等。
request.on('end',()=>{
? ? ? response.end('....');??
})
const http = require('http');const server = http.createServer((request,response)=>{let bodyData = '';request.on('data',(chunk)=>{bodyData += chunk;})request.on('end',()=>{response.end(bodyData);})}
)server.listen(9000, ()=>{console.log('server start!');
} )
根據URL路徑不同返回不同的結果:
在以上的例子中,不管請求路徑是什么,都默認返回http.createServer的回調函數。但在實際開發中,需要根據不同的請求路徑,返回不同的數據。
實際上,如果需要返回不同的內容,也可以都寫在createServer函數中。
如果需要通過method方法,以及請求地址判斷返回的內容,先通過request.method獲取方法,再通過request.url獲取請求路徑。然后再進行判斷,就能實現根據不同的路徑返回不同的結果。
由于網站會自動請求favicon.ico,所以最好在服務器端配置一下對favicon.ico的處理,否則瀏覽器發給服務器端請求,服務器端沒有處理的邏輯,請求也不會返回,會一直和服務器端建立聯系,占用資源。
完整代碼:
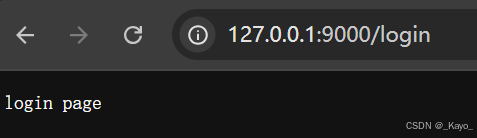
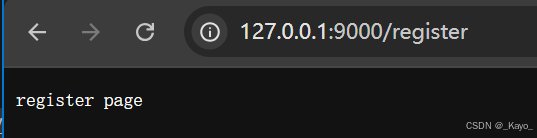
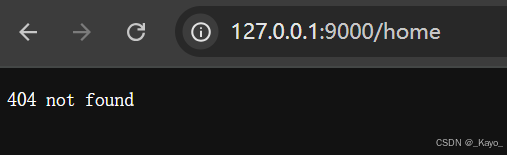
const http = require('http');const server = http.createServer((request,response)=>{let url = request.url;let method = request.method;console.log(method);console.log(url);if(method=='GET' && url=='/login'){response.end('login page');}else if(method=='GET' && url=='/register'){response.end('register page');}else{response.end('404 not found');}}
)server.listen(9000, ()=>{console.log('server start!');
} )
設置HTTP響應報文
本小節主要介紹response的屬性及方法。
通過response來設置響應結果。
response.statusCode
設置響應狀態碼,比如response.statusCode = 203;
statusCode默認是200。
response.statusMessage
設置響應狀態的描述,比如response.statusMessage = 'Not Found';
不過,一般情況下,響應狀態的描述和響應狀態碼都是一一對應的,不需要手動設置。
response.setHeader()
設置響應頭,第一個參數是響應頭的key,第二個參數是value。
response.setHeader('Server','Node.js');
key是大小寫都可以。
除了設置標準的響應頭,也可以設置自定義響應頭。
response.setHeader('demo','123');
setHeader也可以設置同名響應頭response.setHeader('demo',[1,2,3]);在這種情況下,會返回三個key都是demo的響應頭,value分別為1,2,3。
response.write()
設置響應體。
里面的參數就是響應體本身。在返回時,會把response.end和response.write的內容拼接在一起返回。
response.write可以多次調用。返回的響應體是多個write的拼接。
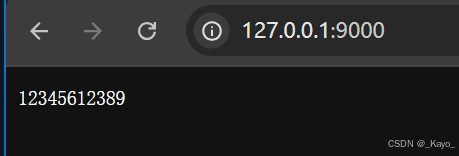
const http = require('http');const server = http.createServer((request,response)=>{response.write('123');response.write('456');response.write('123');response.end('89');}
)server.listen(9000, ()=>{console.log('server start!');
} )
response.end()
可以用于設置響應體。
在回調函數中,一次返回只能設置一個response.end。
在響應內容中,可以設置響應HTML代碼。
可以把以下HTML代碼放在end中返回:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head>
<body><table><tr><td>1</td><td>2</td><td>3</td></tr><tr><td>4</td><td>5</td><td>6</td></tr><tr><td>7</td><td>8</td><td>9</td></tr></table><style>table,td,th{border: 1px solid black;}table,td{border-collapse: collapse;}td{padding: 10px 20px;}table tr:nth-child(odd){background-color: burlywood;}table tr:nth-child(even){background-color: blueviolet;}</style><script>let tds = document.querySelectorAll('td');tds.forEach(item=>{item.onclick = function(){this.style.background = 'blue';}})</script>
</body>
</html>const http = require('http');const server = http.createServer((request, response) => {response.end(`<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title></head><body><table><tr><td>1</td>...}})</script></body></html>`);}
)server.listen(9000, () => {console.log('server start!');
})但通過這種方法返回HTML數據時,返回的HTML沒有代碼高亮和語法提示,在開發時十分不便,可以把HTML代碼寫在HTML文件中,然后在response.end()中,返回HTML文件。
思路是通過fs模塊讀取HTML文件,然后作為end的內容返回。
const http = require('http');
const fs = require('fs');const server = http.createServer((request, response) => {let html = fs.readFileSync(__dirname + '/demo.html');response.end(html);}
)server.listen(9000, () => {console.log('server start!');
})通過這種方式返回HTML數據,一個是可以更好地編寫返回的HTML數據,一個是當修改HTML中的內容時,不需要重啟服務器也可以返回新的頁面,因為每次請求讀取的是HTML文件中的數據,而HTML文件中的數據已經更新了。
通過fs.readFileSync讀取的數據格式是Buffer,response.end也可以處理Buffer數據,因此不需要手動做類型轉換。
錯誤類型設置:
當請求發生錯誤時,如何返回準確的錯誤類型:
可以根據讀取文件回調函數的err判斷:
fs.readFile(filePath,(err,data)=>{
? ? ? ? if(err){
? ? ? ? ? ? ? ? response.setHeader('content-type','text/html;charset=utf-8');
? ? ? ? ? ? ? ? switch(err.code){
? ? ? ? ? ? ? ? ? ? ? ? case 'ENOENT':
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? response.statusCode = 404;
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? response.end(404錯誤頁面對應的HTML文件);
? ? ? ? ? ? ? ? ? ? ? ? case 'EPERM':
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? response.statusCode = 403;
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? response.end(403禁止訪問頁面對應的HTML文件);
? ? ? ? ? ? ? ? ? ? ? ? ...
? ? ? ? ? ? ? ? ? ? ? ? default:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? reponse.statusCode = 500;
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? response.end(500對應頁面的HTML);
????????????????}
????????}
})
網頁資源加載的過程:
當通過瀏覽器訪問一個網頁時,網頁會向服務器端發送多次請求。
在輸入完URL之后,敲擊回車,首先瀏覽器會向服務器發送一個請求當前URL頁面的請求:
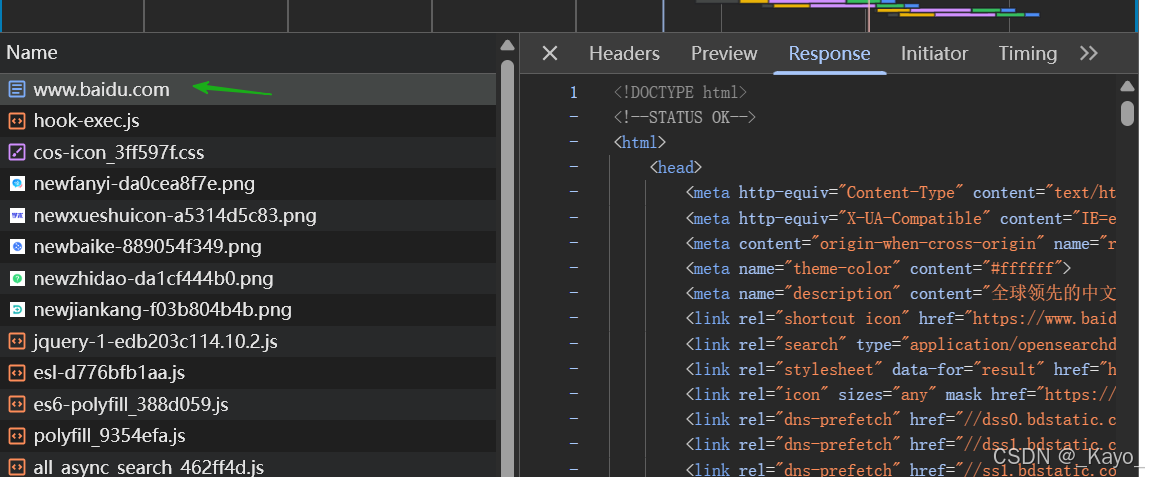
返回后,瀏覽器會對返回的HTML進行解析,當解析到外部的資源時,比如css資源等,瀏覽器會向服務器再次發送請求,請求CSS資源等。
當CSS的數據返回后,瀏覽器會對CSS進行解析,讓CSS中設置的樣式控制瀏覽器頁面的樣式。

當碰到圖片資源請求時,瀏覽器也會向服務器請求圖片資源,當服務器端返回圖片之后,瀏覽器會渲染并呈現圖片。
當碰到外部JS資源時,瀏覽器會向服務器端發起請求,請求JS資源。
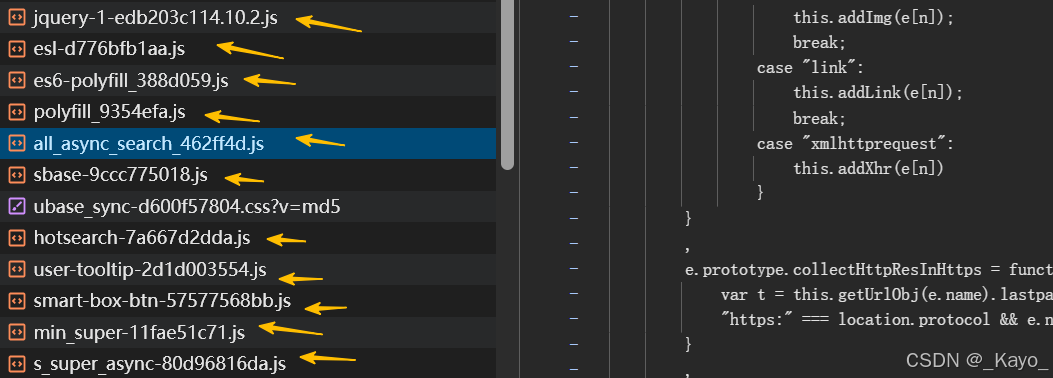
也就是說,當瀏覽器請求數據時,并不是一次性就把數據全部請求到,而是在解析內容時,發現有資源需要向服務器請求時,多次發送請求。且多個請求之間并不是串行的,是并行的,也就是請求某個資源時,并不是一定要等前面的資源請求完畢才可以,如果資源之間沒有關聯,可以并行請求多個資源。
當一個HTML頁面中引用了外部CSS和JS,如何通過response.end返回:
如果一個HTML中通過link ref等方法引入了外部CSS,通過javascript src引入了外部JS,在response.end中,就不能直接返回HTML文件了。因為在這種情況下,即使是瀏覽器向服務器請求css或Js數據,服務器也會返回HTML文件。
如果想正確返回數據,應該調整createServer的邏輯:
當頁面請求css時,請求路徑會是一個css文件;請求js時,請求路徑會是一個js文件。通過請求URL,可以對響應數據進行判斷。
const http = require('http');
const fs = require('fs');const server = http.createServer((request, response) => {let html = fs.readFileSync(__dirname + '/demo.html');let { pathname } = request.url;if(pathname == '/'){response.end(html);}else if(pathname == './index.css'){response.end(__dirname + '/index.css');}else if(pathname == './index.js'){response.end(__dirname + '/index.js');}else{response.end('404 not found');}}
)server.listen(9000, () => {console.log('server start!');
})但通過這種方法返回請求資源,需要編寫多個if else,這種寫法比較復雜。
靜態資源
靜態資源是指內容長時間不會改變的資源,圖片、視頻、CSS、JS、HTML、字體等一般都是靜態資源。
動態資源
動態資源是指內容經常發生更新的資源,比如搜索列表頁、首頁等,每次訪問返回的數據可能各不相同。
搭建靜態資源服務
靜態資源服務:用于給瀏覽器返回靜態資源。
在上面的例子中,通過if else判斷返回何種資源,是十分復雜和冗余的。
如果想完成下列響應:
GET /index.html 響應pages/index.html
GET /css/demo.css 響應pages/css/demo.css
GET /image/demo.jpg?響應pages/image/demo.jpg
一般URL的請求路徑,和文件路徑之間是有關聯的,所以可以通過通用關聯拼接文件路徑,而不需要每次都通過if else判斷。
拼接完路徑之后,通過fs讀取文件,再返回就可以了。
const http = require('http');
const fs = require('fs');const server = http.createServer((request, response) => {let { pathname } = request.url;let filePath = __dirname + '/page' + pathname;fs.readFile(filePath, (err,data)=>{if(err){response.statusCode = 500;response.end('fail');return ;}response.end(data);})
)server.listen(9000, () => {console.log('server start!');
})靜態資源目錄:是指靜態資源存放的文件夾的目錄。靜態資源目錄,也叫網站根目錄。
在配置靜態資源服務時,就是拼接靜態資源目錄,再拼接靜態資源目錄和請求路徑,去這個路徑讀取文件。
...
let root = __dirname + '/page';
let filePath = root + pathname;
...MIME類型
Multipurpose Internet Mail Extensions ,MIME。稱為媒體類型,或資源類型。
是一種標準,用來表示文檔、文檔、字節流的性質和格式。
MIME類型的結構:主類型/子類型。
text/html、text/css、image/jpeg、application/json。
在響應頭中,可以通過Content-Type來表明響應的MIME類型。瀏覽器會根據Content-Type類型來決定如何處理響應體資源。
常見的MIME類型對應:
html文件:text/html、css文件:text/css、JS文件:text/javascript、png圖片:image/png、jpg圖片:image/jpg、gif圖片:image/gif、MP3文件:audio/mpeg、MP4文件:video/mp4、json文件:application/json。
在服務端返回資源時,可以通過文件的后綴名決定返回的Content-Type類型:
1.通過path.extname(filePath).slice(1)獲取當前文件路徑的后綴。
2.聲明MIME類型對象mimes。
3.根據類型返回Context-Type值:response.setHeader('content-type',mimes[ext]);
對于未知的資源類型,可以設置Context-Type為application/octet-stream,瀏覽器碰到這種響應設置時,會對響應體的內容進行獨立存儲,也就是下載的效果。
當前,Content-Type的設置其實也可以不手動進行,因為瀏覽器有MIME嗅探功能,瀏覽器會根據響應體自動分析MIME類型,但是返回準確的MIME類型,是一種比較規范的開發模式。
為了防止中文亂碼問題,在設置Content-Type值時,一般需要再拼接一下';charset=uft-8'。
除了設置Content-Type,如果資源類型是HTML,在HTML中,通過<meta charset='UTF-8'>也可以給資源設置charset,也不會產生亂碼。
meta charset和Content-Type的優先級:Content-Type的優先級高于meta charset。
對于CSS、JS、圖片等資源,一般不需要給資源單獨設置字符集,他們的字符集一般是根據資源所在的網頁的字符集處理的。
所以一般判斷ext(文件后綴)是否是HTML,是HTML再設置charset。






爬蟲進階(Python爬蟲教程)(CSS選擇器))




)





:端口無權限)
線性方程組解的結構)
