自然語言處理與BERT模型:從基礎到實踐入門
自然語言處理(NLP)的核心目標之一是讓計算機理解人類語言的語義和上下文。本文將從基礎的字詞表示出發,逐步解析傳統模型的局限性、Self-attention的突破性思想,以及BERT如何通過預訓練成為強大的特征編碼器。
一、字的表示:從離散符號到語義向量
傳統NLP中,字或詞的表示主要依賴離散符號(如One-Hot編碼),但這種方式無法捕捉語義相似性(如“貓”和“狗”均為動物,但One-Hot向量正交)。深度學習中,通過Embedding技術將字映射為低維稠密向量(如300維),使得語義相近的字在向量空間中距離更近。例如:
- 詞袋模型(Bag of Words)
- Word2Vec、GloVe等預訓練詞向量
這一過程讓模型能夠從數學上理解“字”的語義特征。
二、上下文建模:RNN與LSTM的探索
為了捕捉序列中字與字之間的上下文關系,早期模型引入了循環神經網絡(RNN)。RNN通過隱狀態(Hidden State)/ 記憶單元傳遞歷史信息,但其存在兩大問題:
- 長距離依賴丟失:隨著序列變長,早期信息逐漸衰減(如段落開頭的主題詞影響結尾)。
- 梯度消失/爆炸:反向傳播時梯度難以穩定更新參數。
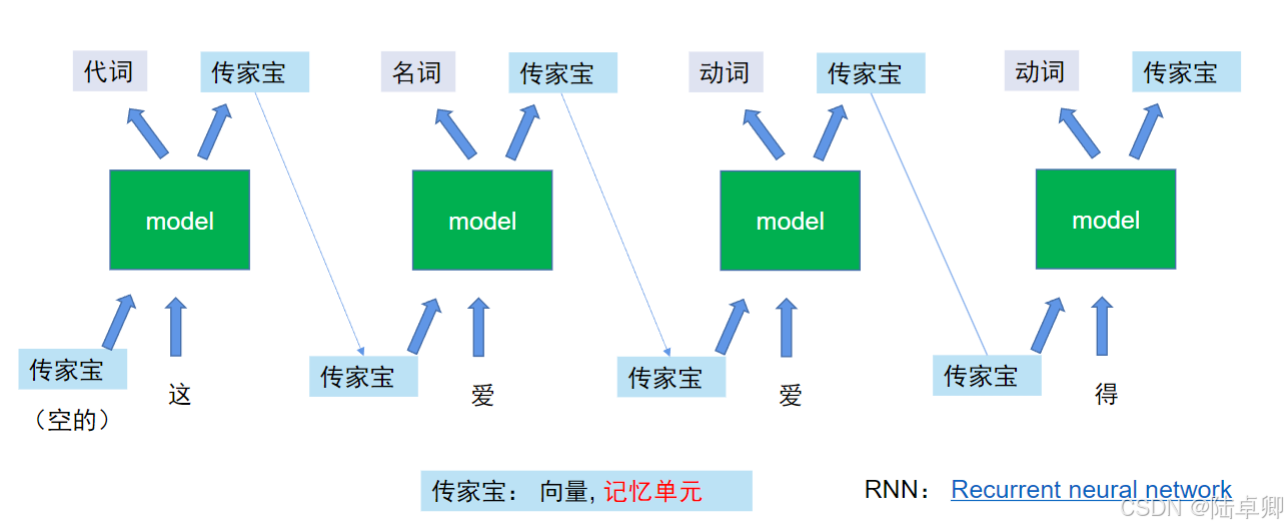
**LSTM(長短期記憶網絡)**通過門控機制(輸入門、遺忘門、輸出門)緩解了這些問題,但仍存在局限性:
- 無法并行計算:必須按順序處理序列,訓練速度慢。
- 單向上下文:傳統RNN/LSTM僅能捕捉從左到右的依賴,雙向模型(Bi-LSTM)雖融合雙向信息,但復雜度更高。
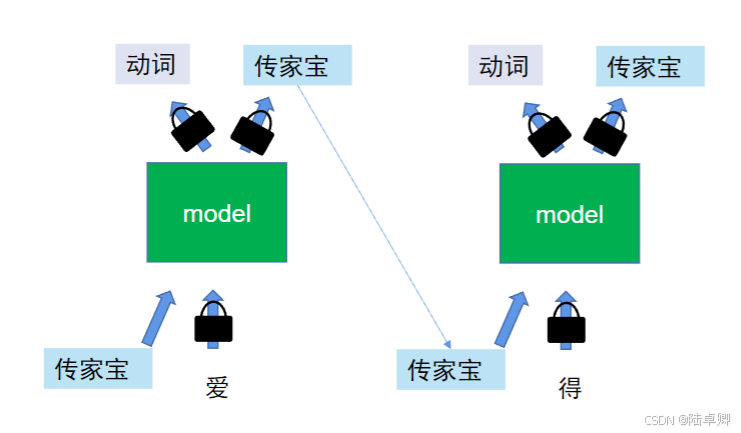
三、Self-attention的突破:并行化與全局上下文
為解決RNN系列模型的缺陷,Self-attention機制應運而生。其核心優勢在于:
- 并行計算:所有字的同時處理,大幅提升訓練速度。
- 全局感知:每個字直接與序列中所有字交互,捕捉長距離依賴。
- 雙向建模:天然支持雙向上下文(如同時考慮左右字的影響)。
這一機制成為Transformer架構的核心,徹底改變了NLP模型的設計范式。
四、Self-attention的實現細節
1. 輸入表示:Embedding與位置編碼
每個字的輸入由兩部分相加構成:
- 字Embedding:表示字本身的語義(如“貓”對應的向量)。
- 位置Embedding:表示字在序列中的位置(如第1個字、第2個字),通過正弦函數或可學習參數生成。
二者相加后得到最終的Token表示,既包含語義又包含位置信息。
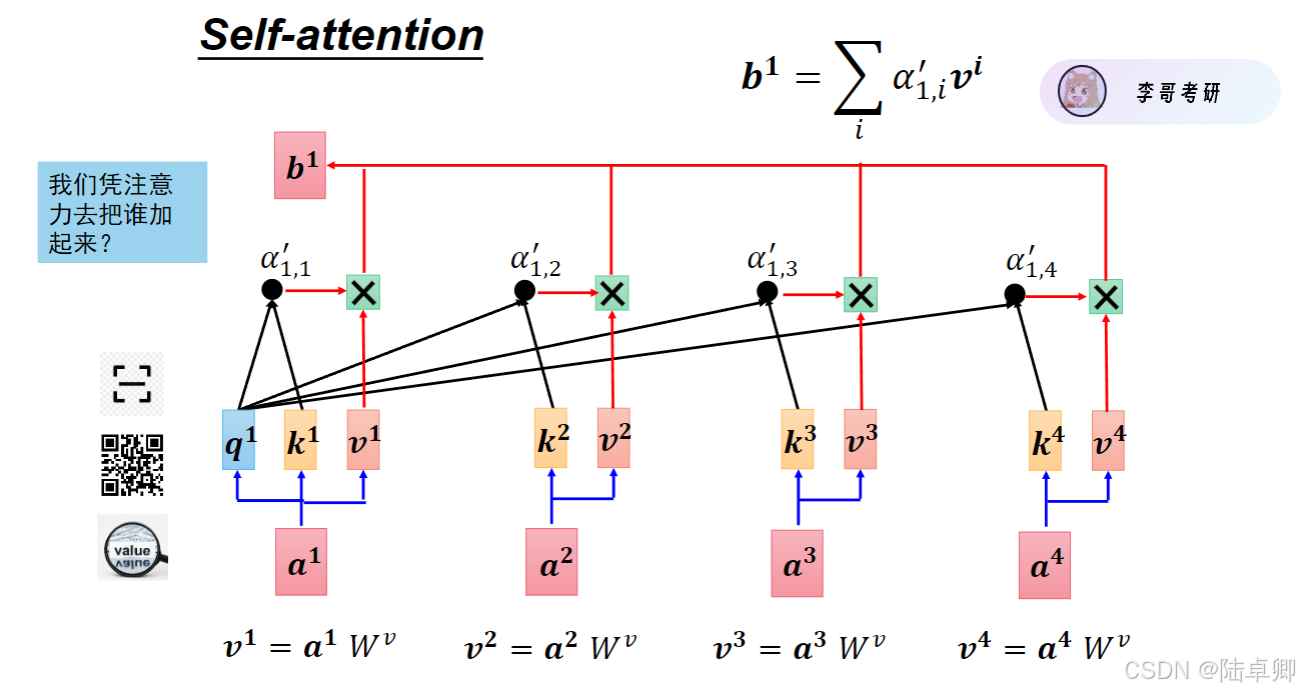
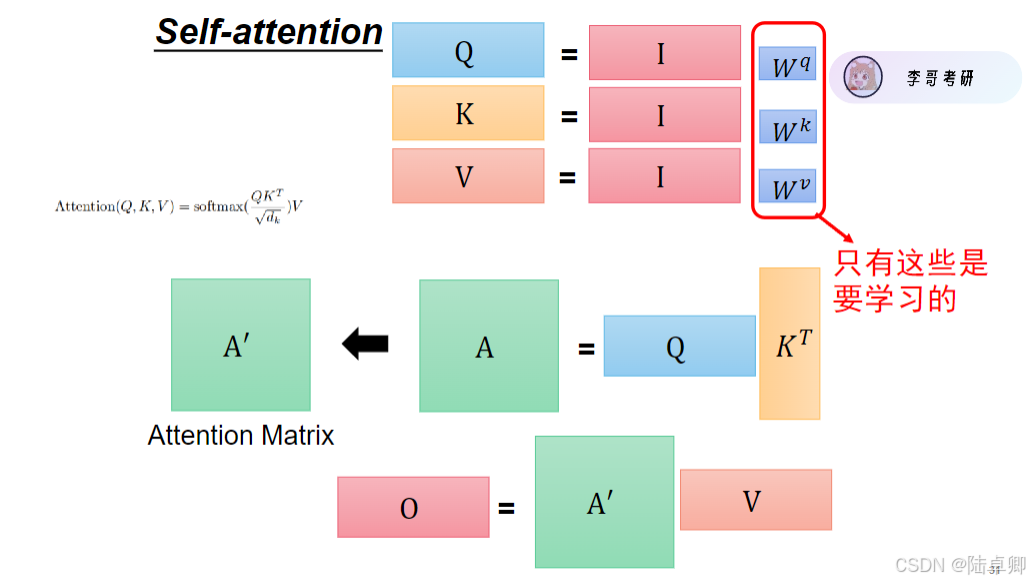
2. QKV交互與注意力計算
Self-attention通過三個矩陣(Query, Key, Value)實現字與字之間的交互:
- Query(Q):當前字需要查詢的信息。
- Key(K):其他字提供的索引信息。
- Value(V):其他字的具體內容信息。
計算步驟如下:
- 通過Q和K的點積計算注意力分數,反映字與字的相關性。
- 對分數歸一化(Softmax)得到注意力權重。
- 根據權重對V加權求和,得到當前字的上下文感知表示。
公式表達:
\ [
\ text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
]
五、BERT:基于Self-attention的特征編碼器
BERT(Bidirectional Encoder Representations from Transformers)是一個多層Transformer編碼器堆疊的模型,其核心目標是將輸入文本編碼為上下文相關的特征向量。
由Google AI在2018年提出的預訓練語言模型,它是基于Transformer架構的一個具體應用實例。與原始Transformer不同的是,BERT僅使用了Transformer的編碼器部分,并在此基礎上進行了創新,采用了雙向訓練的方式——即同時考慮一個詞左邊和右邊的所有上下文信息,這與傳統單向語言模型形成了鮮明對比。
1. 自監督預訓練
BERT通過以下任務預訓練,無需人工標注數據:
- Masked Language Model (MLM):隨機遮蓋15%的字,模型預測被遮蓋的字(如“貓坐在[MASK]上” → “墊子”)。
- Next Sentence Prediction (NSP):判斷兩句話是否連續(如“今天下雨” + “我帶了一把傘” → 正樣本)。
2. 特征提取與下游任務
預訓練后的BERT可直接作為特征提取器: 
- 提取任意字的Embedding或整句的
[CLS]向量。 - 將特征輸入簡單分類層,即可適配文本分類、問答等任務。
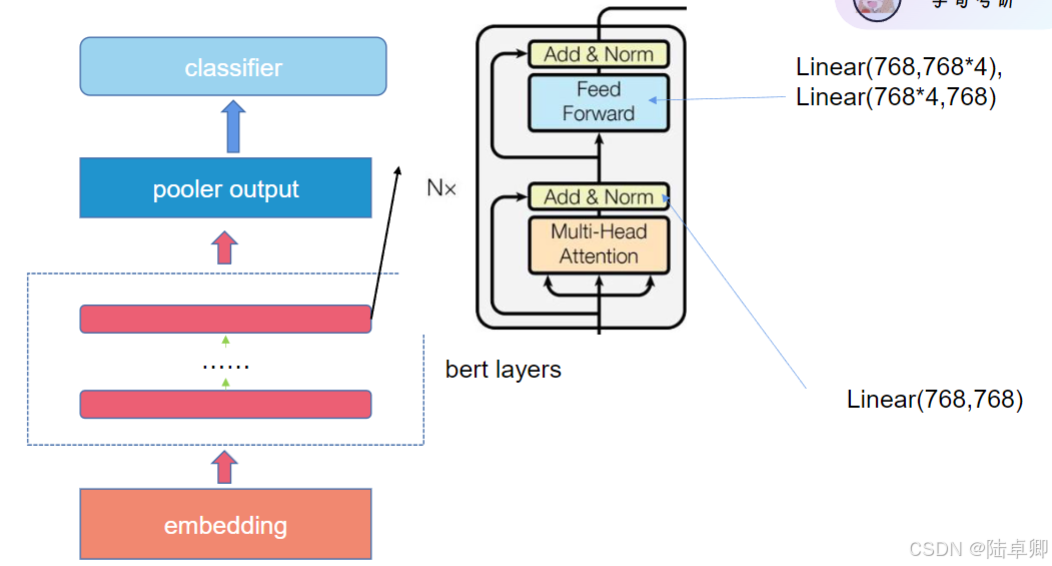
六、BERT的三大核心結構
1. Embedding Layer (嵌入層)
在BERT中,輸入文本首先需要被轉換為計算機能夠理解的形式——向量。這個過程稱為“嵌入”,即把詞語映射到一個連續的向量空間中。BERT使用了三種類型的嵌入:
-
Token Embeddings: 這是將每個單詞或子詞(如WordPiece分詞后的結果)轉換成向量表示的過程。例如,“hello”可能會被轉換成一個
768維的向量。 -
Segment Embeddings: BERT支持處理句子對的任務(比如問答),因此需要一種方法來區分這些句子。這通過給來自不同句子的tokens分配不同的段落標識(通常是0或1)來實現。
-
Position Embeddings: Transformer模型沒有內置的方式來識別序列中元素的順序。所以,位置嵌入用來告訴模型每個token在其序列中的相對位置。
2. BERT Layers (BERT層)
BERT由多層Transformer編碼器組成。每層都包含以下兩個主要組件:
-
Multi-Head Attention (多頭注意力機制): 這個組件允許模型同時關注輸入序列的不同部分,從而捕捉到詞語之間的依賴關系。通過多個“頭”并行運行,它可以專注于不同類型的信息。
-
Feed Forward Neural Network (前饋神經網絡): 在注意力機制之后,有一個簡單的兩層全連接網絡,用于進一步處理信息。每層之間都有殘差連接和歸一化步驟,有助于穩定訓練過程。
3. Pooler Output (池化輸出)
在BERT的最后一層編碼器之后,通常會有一個池化層,它會取第一個token([CLS]標記)對應的隱藏狀態作為整個句子的表示。這是因為,在預訓練過程中,[CLS]標記的最終隱藏狀態被用作句子分類任務的特征表示。
4. Classifier (分類器)
對于特定的下游任務,比如情感分析、命名實體識別等,會在BERT的頂部添加一個額外的分類層。這個分類層通常是一個簡單的全連接層,可能后面跟著一個softmax函數,用于生成最終的預測結果。
5. Linear Layers (線性層)
在BERT的結構中,線性層主要用于調整向量的維度大小。例如,在前饋神經網絡中,會有兩次線性變換:第一次擴展向量維度,第二次則壓縮回原始維度。這樣做的目的是為了引入非線性,使模型能夠學習更復雜的模式。
七.總結
從字的表示到BERT的完整架構,NLP模型的演進始終圍繞“如何更好地理解上下文”展開。BERT的成功得益于Self-attention的并行化能力和自監督預訓練策略。理解這些核心思想后,讀者可進一步探索BERT的變體(如RoBERTa、ALBERT)及在多語言、多模態任務中的應用。
- BERT實戰中的數據不平衡問題
- 在文本分類等任務中,數據不平衡是一個常見的挑戰。例如,在情感分析任務中,“正面”評論往往比“負面”評論多得多。為了解決這個問題,可以使用Focal Loss函數來調整損失函數級別,無需修改數據集本身。這種方法特別關注那些難以正確分類的樣本,從而有助于提高模型的整體性能。
代碼示例(使用Hugging Face庫):
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
inputs = tokenizer("自然語言處理很有趣!", return_tensors="pt")
outputs = model(**inputs)
# 獲取整句特征([CLS]向量)
sentence_embedding = outputs.last_hidden_state[:, 0, :]
八.問題
以下是基于你提供的知識庫內容和常見復試場景設計的BERT項目相關問題及參考答案,涵蓋技術原理、實現細節、優化策略和應用實踐:
1. 問題:BERT的輸入處理步驟中,為什么要使用[CLS]和[SEP]標記?它們在模型中的作用是什么?
答案:
- [CLS] 標記:
- 位于輸入序列的最開始,其對應的隱層輸出(最后一層的[CLS]向量)被用作整個序列的分類表示。
- 在分類任務中(如情感分析),模型通過全連接層對[CLS]向量進行預測。
- [SEP] 標記:
- 用于分隔兩個句子(如在NSP任務中),幫助模型區分句子邊界。
- 在單句分類任務中,僅需一個[SEP]標記結束句子。
- 作用:
- 通過[CLS]向量聚合全局語義信息,避免依賴固定位置的平均或池化操作。
- [SEP]標記明確句子結構,防止兩個句子的上下文混淆。
2. 問題:在BERT的預訓練任務中,Masked Language Model (MLM) 如何解決自回歸模型的單向性問題?
答案:
- MLM的核心思想:
- 隨機遮蔽15%的詞,模型需根據雙向上下文(左、右兩側的詞)預測被遮蔽的詞。
- 例如,遮蔽“貓”時,模型需同時利用“黑”和“在睡覺”等信息,實現雙向語義建模。
- 與自回歸模型(如GPT)的對比:
- GPT僅利用左向上下文預測下一個詞,無法捕捉右向信息;
- BERT通過MLM強制模型學習雙向依賴,提升對復雜語義的理解能力。
- 數學實現:
- 遮蔽詞的位置由均勻分布隨機選擇,80%遮蔽為[Mask],10%保留原詞,10%替換為隨機詞(防止模型依賴[Mask]標記)。
3. 問題:BERT的位置編碼(Position Embedding)與Transformer的原始實現有何不同?
答案:
- BERT的位置編碼:
- 采用可訓練的絕對位置嵌入(learned absolute positional embeddings),與Token Embedding和Segment Embedding相加。
- 通過反向傳播學習位置信息,適應不同任務的上下文依賴。
- Transformer的原始實現:
- 使用固定的位置編碼(sinusoidal函數生成的相對位置編碼),不依賴訓練數據。
- 差異與影響:
- BERT的絕對位置編碼更適合需要明確序列順序的任務(如文本分類);
- 固定編碼在長序列(超過512)時可能失效,而BERT因位置嵌入長度固定(最大512),無法處理超長文本(需截斷或分塊)。
4. 問題:為什么BERT的NSP(Next Sentence Prediction)任務在某些下游任務中被認為效果有限?
答案:
- NSP任務的初衷:
- 預測兩個句子是否連續,幫助模型學習句子間的
語義關系(如問答任務中的上下文理解)。
- 預測兩個句子是否連續,幫助模型學習句子間的
- 局限性:
- 任務簡單性:NSP的二分類任務容易被模型過擬合,且實際任務中句子對齊問題(如文檔分類)與NSP關聯性弱。
- 數據偏差:隨機組合的負樣本(非連續句子對)可能包含語義相關但非連續的句子,導致噪聲。
- 改進方案:
- ALBERT:用**句子順序預測(OSP)**替代NSP,判斷兩個句子的順序是否合理;
- RoBERTa:完全移除NSP任務,僅保留MLM。
5. 問題:在BERT的微調階段,如何避免過擬合?請結合代碼說明。
答案:
- 常見策略:
- 學習率調度:
- 使用分階段衰減(如
Cosine Annealing)或Warmup + Linear Decay(BERT論文推薦)。 - 代碼示例(PyTorch):
from transformers import get_linear_schedule_with_warmup total_steps = len(train_dataloader) * num_epochs scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=total_steps)
- 使用分階段衰減(如
- 正則化:
- 添加Dropout層(BERT默認在Transformer層后已配置);
- 使用AdamW優化器(解耦權重衰減,知識庫[1]提到)。
- 早停法(Early Stopping):
- 監控驗證集損失,當性能不再提升時終止訓練。
- 學習率調度:
6. 問題:BERT的多頭注意力(Multi-Head Attention)為什么需要對每個頭進行降維?
答案:
- 數學原理:
- 多頭注意力的計算復雜度為 (O(T^2D)),其中 (T) 是序列長度,(D) 是嵌入維度。
- 通過將每個頭的維度從 (D) 降為 (D/h)((h) 為頭數),總復雜度變為 (O(T^2D/h * h) = O(T^2D)),復雜度不變,但降低了單個頭的計算量。
- 作用:
- 允許模型在多個低維子空間中并行學習不同特征(如語法、語義),提升表達能力;
- 例如,BERT-base使用12頭,每個頭維度為64(總維度768)。
7. 問題:如何處理輸入文本超過BERT最大長度(512)的問題?
答案:
- 解決方案:
- 截斷與分塊:
- 截斷過長文本(如保留前512個token),但可能丟失關鍵信息;
- 分塊處理(如將長文本分成多個片段,合并結果)。
- 模型擴展:
- 使用長序列模型(如Longformer,通過稀疏注意力機制處理長文本)。
- 任務適配:
- 在文本分類中,僅保留關鍵段落(如摘要);在問答任務中,結合滑動窗口策略。
- 截斷與分塊:
8. 問題:BERT與GPT在訓練目標和應用場景上的根本區別是什么?
答案:
| 維度 | BERT | GPT |
|---|---|---|
| 訓練目標 | MLM(雙向上下文) + NSP | 自回歸語言模型(單向左到右) |
| 架構 | Transformer Encoder(無Mask) | Transformer Decoder(帶Mask) |
| 優勢場景 | 需要全局語義理解的任務(分類、問答) | 需要生成連續文本的任務(文本生成、對話) |
| 計算效率 | 并行計算速度快 | 逐詞生成,推理速度慢 |
| 上下文利用 | 雙向上下文(通過MLM) | 單向上下文(僅左向) |
9. 問題:在BERT的預訓練中,為什么需要對注意力權重進行縮放(除以√d_k)?
答案:
- 數學原因:
- 注意力分數 (QK^T) 的值可能很大(維度 (d_k) 趨大時),導致softmax后的權重梯度消失(指數爆炸)。
- 縮放因子 (\sqrt{d_k}) 使分數的尺度更小,梯度更穩定。
- 實驗效果:
- 未縮放時,注意力權重可能集中在少數位置,模型無法有效學習全局關聯(知識庫[3]提到的QK矩陣測試)。
10. 問題:如何將BERT與知識圖譜結合提升模型效果?請舉例說明。
答案:
- 結合方法:
- 靜態知識注入:
- 在預訓練階段,將知識圖譜中的實體關系編碼到BERT的詞嵌入中(如通過圖神經網絡)。
- 動態推理:
- 在微調階段,引入知識圖譜的先驗知識作為約束(如約束問答任務的答案必須來自知識圖譜的實體)。
- 聯合訓練:
- 將知識圖譜的三元組(頭、關系、尾)作為額外訓練數據,擴展MLM任務(如預測被遮蔽的實體關系)。
- 靜態知識注入:
- 應用場景:
- 在醫療問答中,BERT結合疾病知識圖譜,確保答案符合醫學知識體系。
11. 問題:BERT的LayerNorm為什么選擇在Transformer層的內部使用,而不是BatchNorm?
答案:
- LayerNorm的優勢:
- 數據依賴性低:LayerNorm按樣本維度歸一化,不受batch大小影響,適合小batch訓練;
- 穩定性:Transformer的殘差連接需要穩定的激活值分布,LayerNorm能有效緩解梯度消失。
- BatchNorm的局限性:
- 在NLP任務中,序列長度變化較大,BatchNorm的統計量(均值、方差)依賴batch數據,可能引入噪聲。
12. 問題:在BERT的微調階段,如何選擇凍結哪些層?
答案:
- 策略:
- 漸進式解凍:
- 初始凍結所有層,僅訓練分類頭;逐步解凍頂層Transformer層,再解凍底層。
- 基于任務相似性:
- 若下游任務與預訓練語料相似(如新聞分類),可僅凍結底層;若差異大(如醫學文本),需解凍更多層。
- 實驗驗證:
- 通過驗證集性能調整凍結策略,避免過擬合或欠擬合。
- 漸進式解凍:



)





:端口無權限)
線性方程組解的結構)

 這樣的 Controller 方法)






