目錄
- 索引是什么
- 優點和缺點
- B樹和B+樹
- 紅黑樹和哈希表存儲數據的局限
- B樹
- B+樹
- MySQL中的頁
- 頁是什么
- 為什么要使用頁
- 頁的結構
- 三層樹高的B+樹可以存放多少條記錄
- 索引的分類
- 主鍵索引
- 普通索引
- 唯?索引
- 全?索引
- 聚集索引和非聚集索引(重要)
- 索引覆蓋
- 創建索引
- 自動創建
- 手動創建
- 創建復合索引
- 查看索引
- 索引的一些注意事項
索引是什么
- MySQL中的索引是一種數據結構, 他可以幫助我們在數據庫追上快速的查詢到對應的記錄. 一般我們查詢表里面的記錄是一條一條遍歷來查詢的, 而有了索引我們就不用遍歷整個數據表來查詢. 對查詢速度提升了許多.
- 就好比我們書籍的目錄, 如果我們想看關于挖寶藏的內容, 我們就可以看看書籍目錄里面比如"xx寶藏遺址" 之類的標題, 我們就可以看到對應的頁數, 直接翻到對應的頁數.
優點和缺點
優點:
- 加快了查找記錄的速度
缺點:
- 索引需要占 磁盤空間 ,除了數據表占數據空間之外,每一個索引還要占一定的物理空間, 存儲在磁盤上,如果有大量的索引,索引文件就可能比數據文件更快達到最大文件尺寸。
- 雖然索引大大提高了査詢速度,同時卻會 降低更新表的速度 。當對表中的數據進行增加、刪除和修改的時候,索引也要動態地維護,這樣就降低了數據的維護速度。
B樹和B+樹
前面說了, 索引是MySQL中的一個數據結構, 那他使用的是那個數據結構呢? 好像查詢速度比較快的就只有哈希表(o(1)查詢速度)和紅黑樹(logn)這兩個數據結構查詢的速度快吧. 很可惜不是他們兩個.
紅黑樹和哈希表存儲數據的局限
- 哈希表之所以不適合作為索引的數據結構, 其主要原因就是不支持范圍查詢. 假設有幾本書定價為10, 20, 40 , 60, 80, 100元, 他們通過哈希函數定址到同一個0號書架或者分散到不同的書架. 那么現在我們要去尋找50 - 100元之間的書, 你不知道這些書到底在那個書架. 他們有可能在同一個書架也可能在不同的書架, (哈希函數并不支持范圍映射, 這里你通過哈希函數找到0, 可能還存在30 % 10 = 0, 30也在0號書架), 所以哈希表不能支持范圍查詢, 而我們的索引通常會會有查詢某個范圍數據的需求.
- 紅黑樹雖然支持范圍查詢, (左小跟右大跟), 但是紅黑樹是一個二叉搜索樹, 他一個節點只有兩個分支, 也就是每層的節點最多是2^n - 1次方, 這就導致存在數據庫里面的大量數據會導致紅黑樹的高度非常高, 如果我們要進行查詢每個數據, 我們有可能就會訪問節點訪問很多次. 在檢索數據時,每次訪問某個節點的?節點時都會發??次磁盤IO,?在整個數據庫系統中,IO是性能的瓶頸,減少IO次數可以有效的提升性能. 所以紅黑樹也不適合當索引的數據結構.
B樹
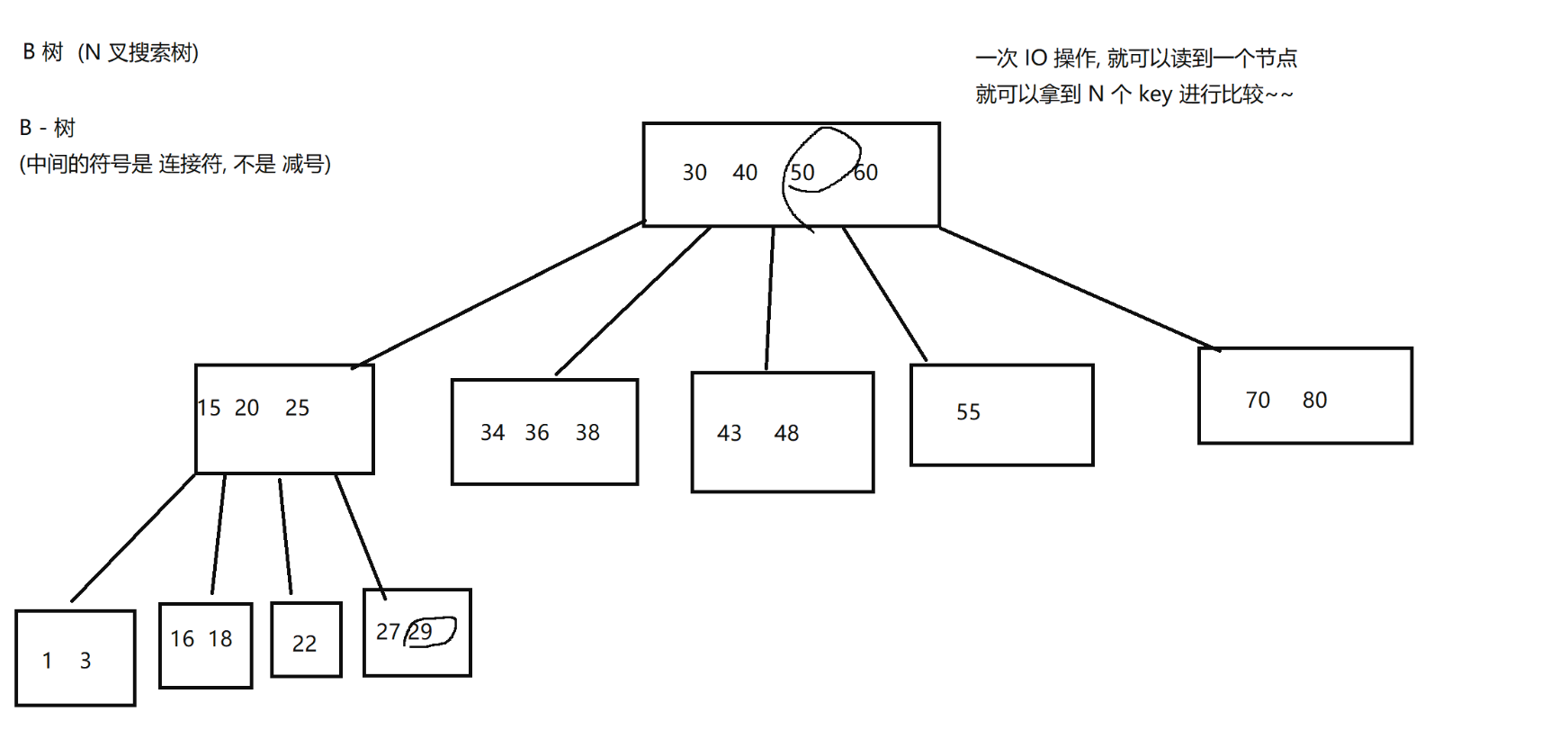
- B樹的分支樹是節點N個key值的N + 1條邊, 例如第一個節點有4個, 那么這個節點就有5條分支.
- B樹的非葉子節點也有可能存儲數據, 所以他的所有節點都有可能存儲數據.
這里我們要進行查找40 - 60之間的數據, 這時候我們找到40的右分支, 找到43, 48. 這個時候我們又要回溯到根節點看到50也滿足, 然后又去找到他的右分支.找到55這個滿足條件的數據. 結果又要回溯到根節點, 發現根節點60這值也滿足
- 可以看到我們進行范圍查找的時候, 由于B樹的數據都是分散存儲在各個節點. 我們進行范圍查找的時候需要警察進行回溯操作. 需要不斷 “回溯根節點→跳轉子節點→再回溯→再跳轉”,像走迷宮一樣,效率極低。這個效率和全部遍歷差不了多少, 所以B樹也不太適合作為索引的數據結構.
B+樹
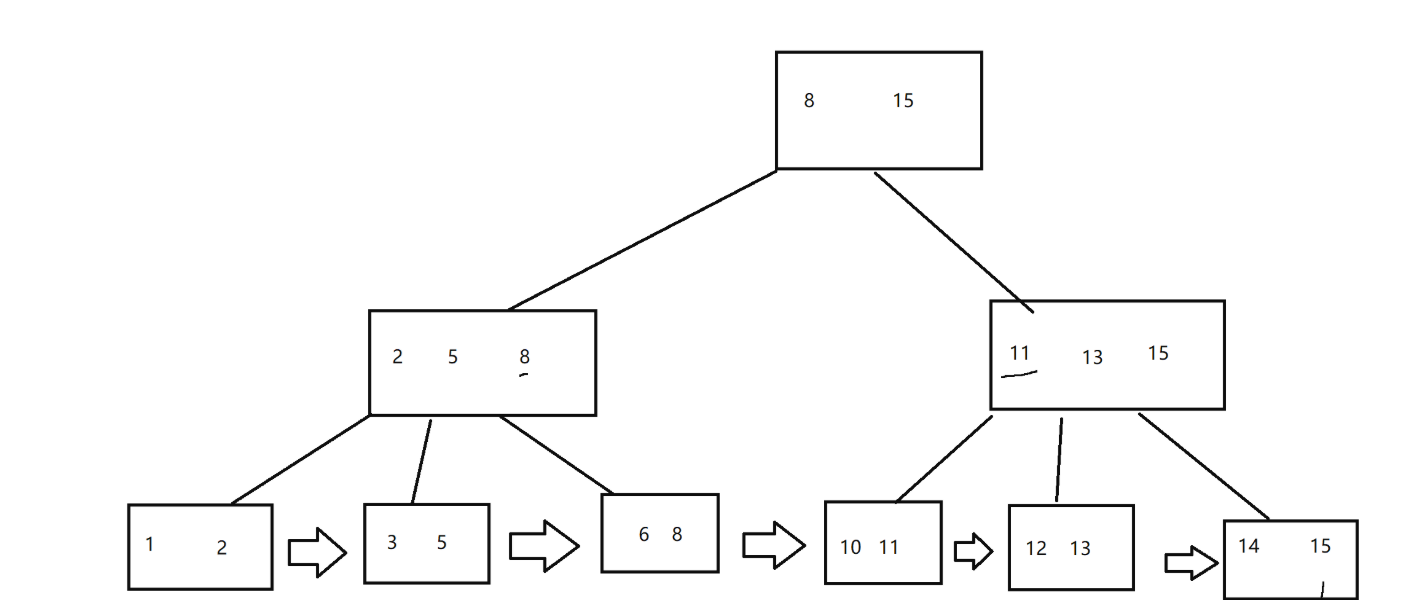
- B + 樹也是一個 N 叉搜索樹
- 每個節點上有 N 個值,劃分出 N 個區間 (不是 N + 1 個), 期中最后一個元素表示當前子樹的最大值 (也可以約定,第一個元素是最小值…)
- 每個子節點中,也可以包含 N 個值,同時會把父節點中對應最大值,放過來==> 最終效果,葉子節點,就是完整的數據集合
- 葉子節點通過雙向鏈表連接起來, 這樣我們就可以遍歷整個鏈表就能找到完整的數據集合, 非常適合范圍查找.
B + 樹相比于 B 樹的優勢:
- 葉子節點是數據全集,并且用鏈表連接,非常方便,進行范圍查詢了
- 所有的數據都是在葉子上,使得葉子節點才存儲完整的數據行,非葉子節點,只需要存儲 索引 key 值即可,此時意味著非葉子節點占用空間較小,更適合在內存中緩存
- 每次查詢,都是需要查詢到葉子,才能夠完成查詢的。中間經歷的過程是差不多開銷的~~(比較次數是相當的) ==> 查詢的開銷比較穩定, 比如我們查找1, 5范圍數據, 和12, 15范圍數據都是遍歷到葉子節點, 這個查詢效率是大差不差的.很穩定, 穩定其實是非常好的優
- 不需要像B樹那樣一直回溯, 因為數據全集就在葉子節點, 我們只需要遍歷葉子節點這個鏈表即可.
MySQL中的頁
頁是什么
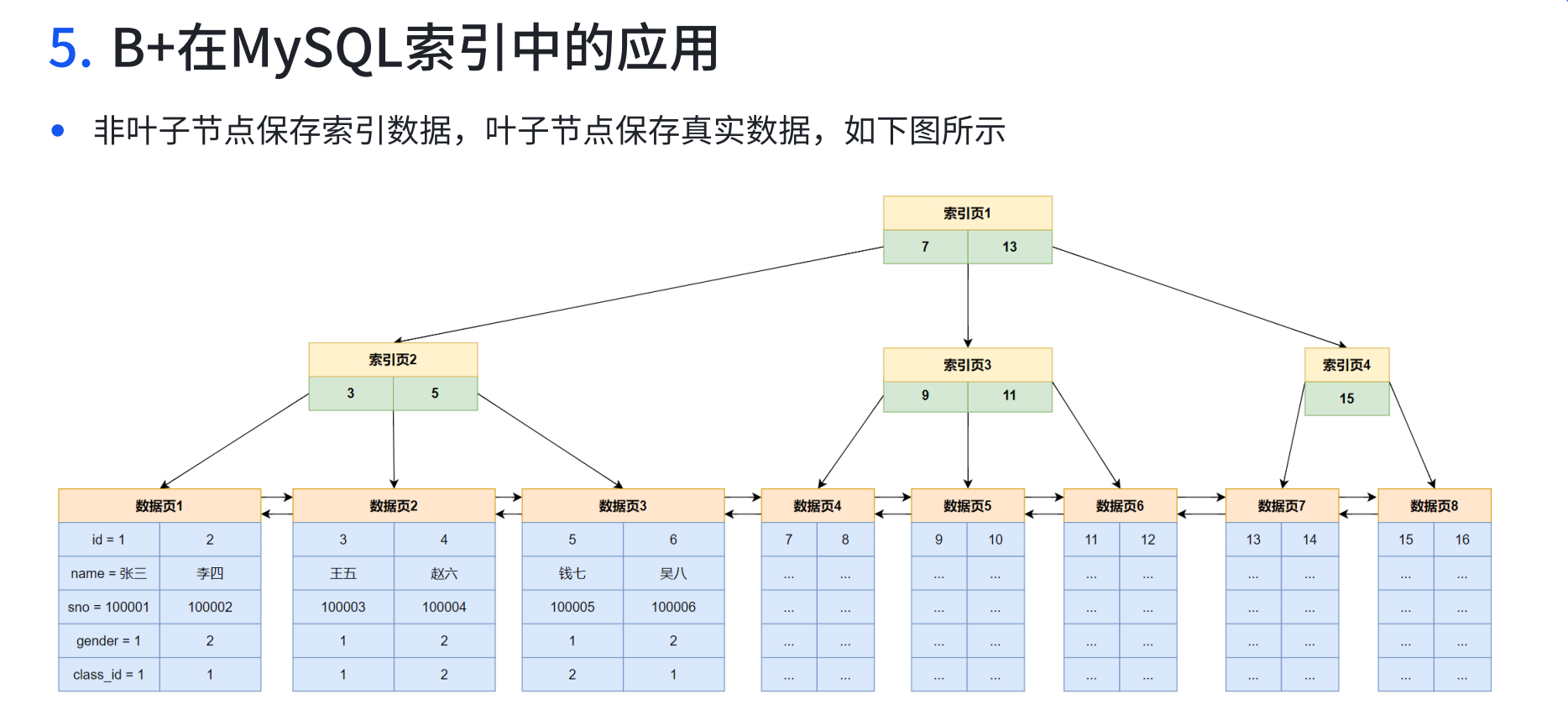
頁其實就是我們B+樹上的節點, 這里又分為數據頁和索引頁. 數據頁對應葉子節點, 存儲若干個數據行. 索引頁對應非葉子節點, 存儲key和子節點的位置(也是一個頁)
- 頁默認??為16KB,
為什么要使用頁
因為我們數據庫讀取硬盤中的數據至少要讀取一頁, 頁里面我們上面說了, 可能存儲若干個數據行. 這個又因為我們有一個叫局部性原理的東西: 根據經驗如果我們讀取了硬盤中的一部分數據, 那么他旁邊的數據我們也可能會讀取. 那么使用頁就會把旁邊的一部分數據也存在同一個頁中, 這個時候我們把這旁邊的數據也讀取出來了, 我們就不需要再去硬盤讀取那部分數據了. 減少了硬盤的IO次數.
頁的結構
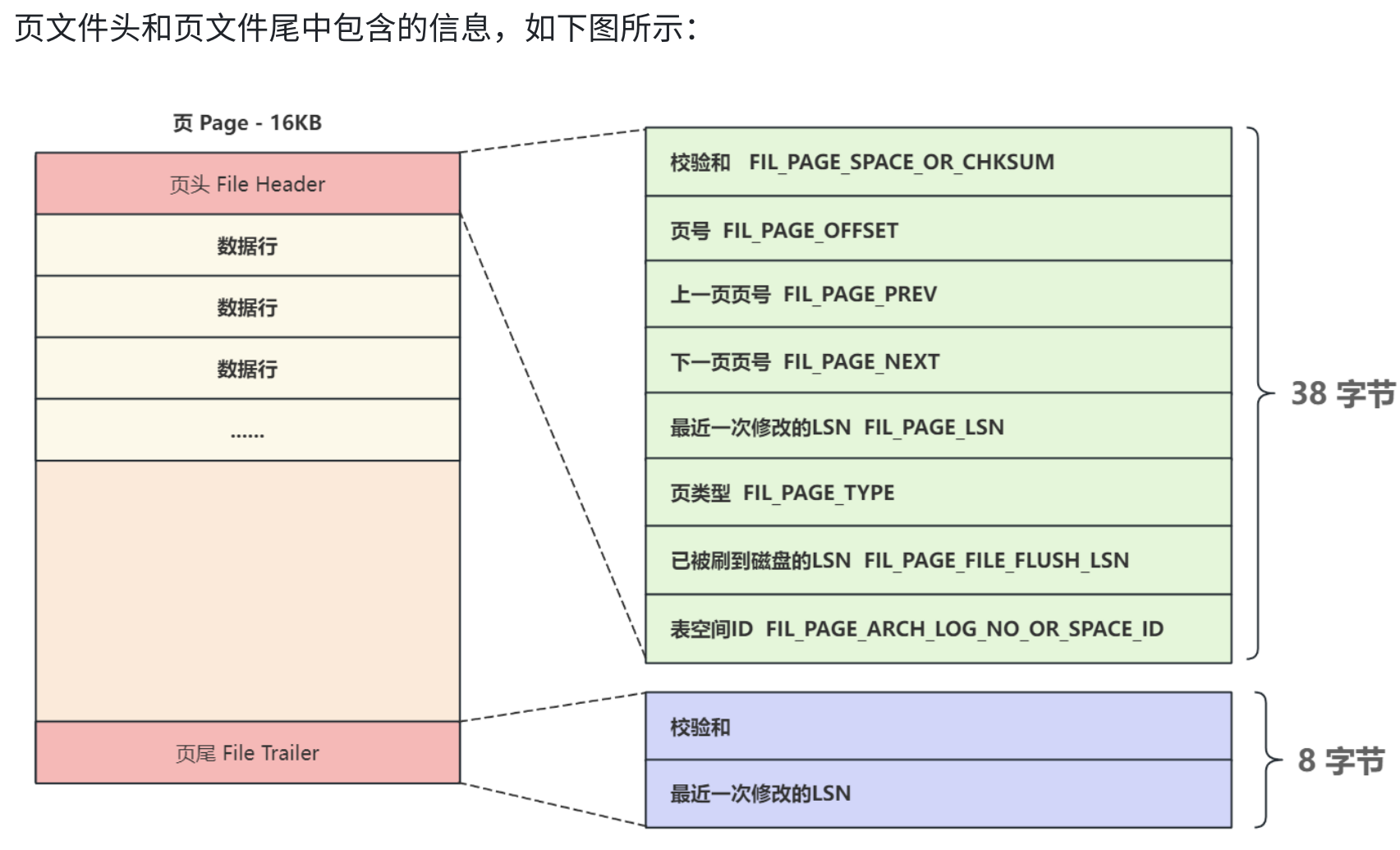
- 從這張圖我們可以看出來, 頁是由頁頭+數據行+頁尾構成的, 至于其他的具體內容, 我們在數據庫高階進行講解.
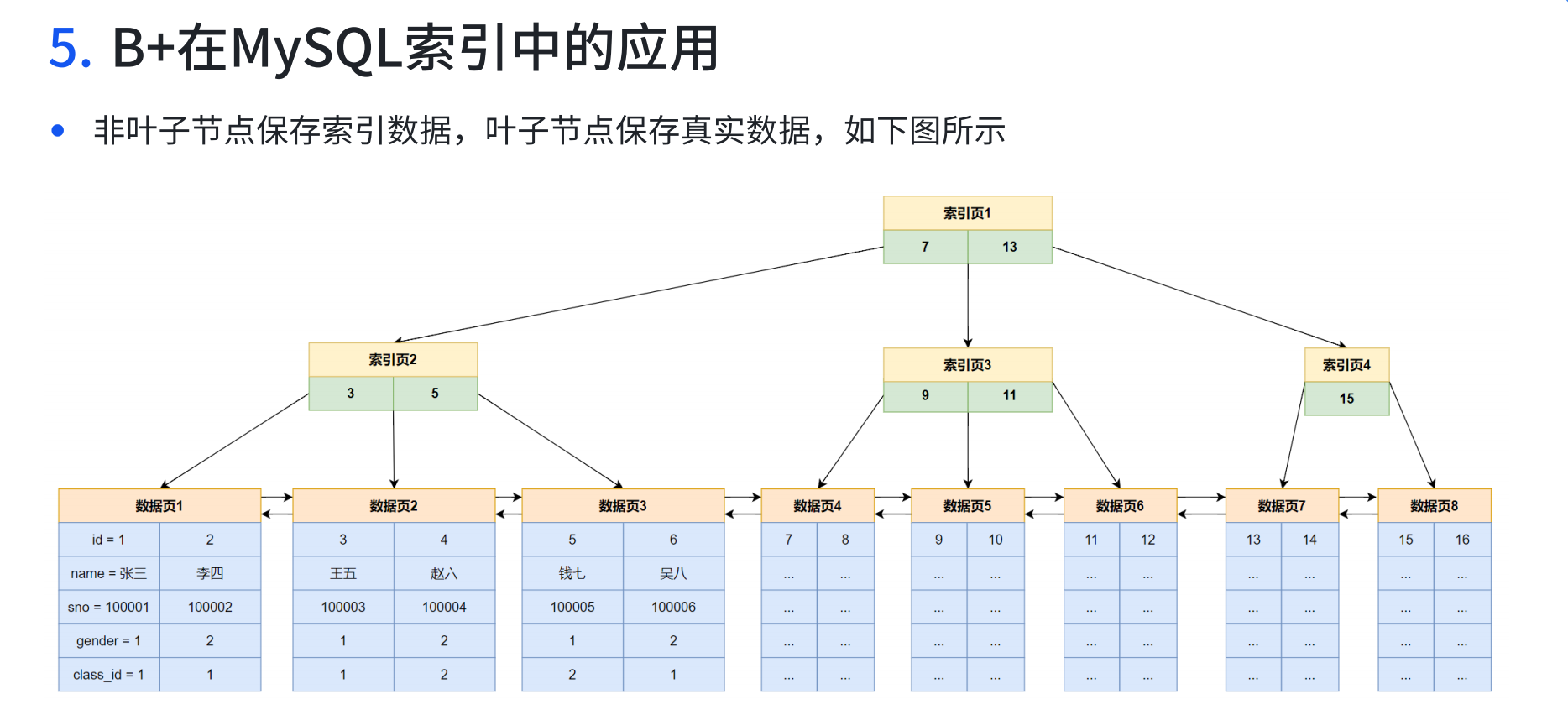
三層樹高的B+樹可以存放多少條記錄
- B+樹的每個節點是一個頁, 非葉子節點是索引頁, 葉子節點是數據頁
- 一頁默認大小是16kb
- 索引頁通常存儲key(索引值) 和下一個子節點的位置 , 這里我們設key值是bigint類型占8個字節, 下一個頁節點位置的指針占4個字節. 所以我們一個數據組是14個字節, 我們一頁16kb = 16384個字節, 可以存儲16484 / 14 = 1170條這樣的數據組.
- 那么我們根節點就有1170個這樣的數據組, 就有1170個頁節點, 第二層1170個節點每個節點也可以存儲1170個這樣的數據組. 所以單個節點就有1170個分支, 1170個頁節點就是1170 * 1170個 = 136w個頁節點
- 到了第3層數據頁, 就有了136w個節點, 數據頁存儲若干個數據行, 假設我們這里的數據行占1kb(實際是多少要看表結構), 我們一個數據頁節點默認大小是16kb, 那么我們1個數據頁節點就能存儲16條數據, 我們有136w個頁節點, 就能存儲136w * 16 = 2000w條數據(這里忽略了頁頭頁尾這些屬性, 他們占太少字節了)
- 綜上, 我們3層樹高的B+樹大概可以存放2000w條數據
其他要注意的是, 我們如果單個表的行數超過了2000w, 繼續增加數據就可能讓B+樹的高度增加, 查詢開銷就有可能增加了. 這個時候我們就要考慮是否對這么大的表進行拆分來提升查詢性能.
索引的分類
主鍵索引
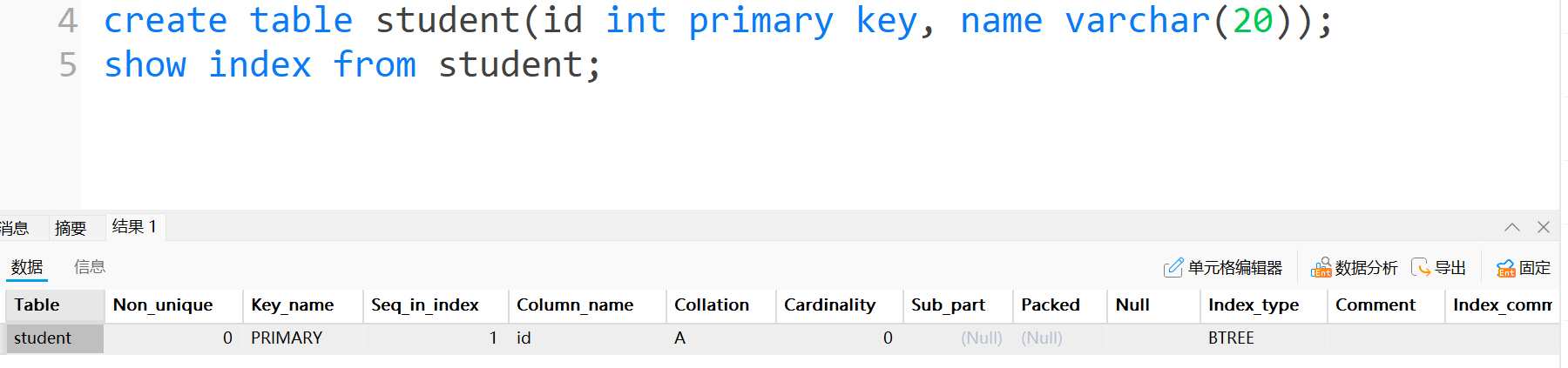
創建主鍵的時候, 數據庫自動創建的索引. 如果表中本身有主鍵, 自然就有主鍵索引. 如果表里面沒有主鍵, 其實數據庫會自動創建"隱藏列", 作為主鍵, 根據隱藏列設定索引.
普通索引
- 最基本的索引類型,沒有唯?性的限制。
- 可能為多列創建組合索引,稱為復合索引或組全索引
唯?索引
- 當在?個表上定義?個唯?鍵 UNQUE 時,?動創建唯?索引。
- 與普通索引類似,但區別在于唯?索引的列不允許有重復值。
全?索引
- 基于?本列(CHAR、VARCHAR或TEXT列)上創建,以加快對這些列中包含的數據查詢和DML操作
- ?于全?搜索,僅MyISAM和InnoDB引擎?持。
聚集索引和非聚集索引(重要)
- 聚集索引也叫做聚簇索引.
- 前面的主鍵索引就是一個聚簇索引, 他對的葉子結點是保存了所有的數據行. 整個數據表就是通過聚簇索引來表示的
- 非聚集索引也叫做非聚簇索引, 假設我們有一個數據表student(id, name, sex, age), id是一個聚簇索引如上圖表示. 現在用name列創建一個非聚簇索引.
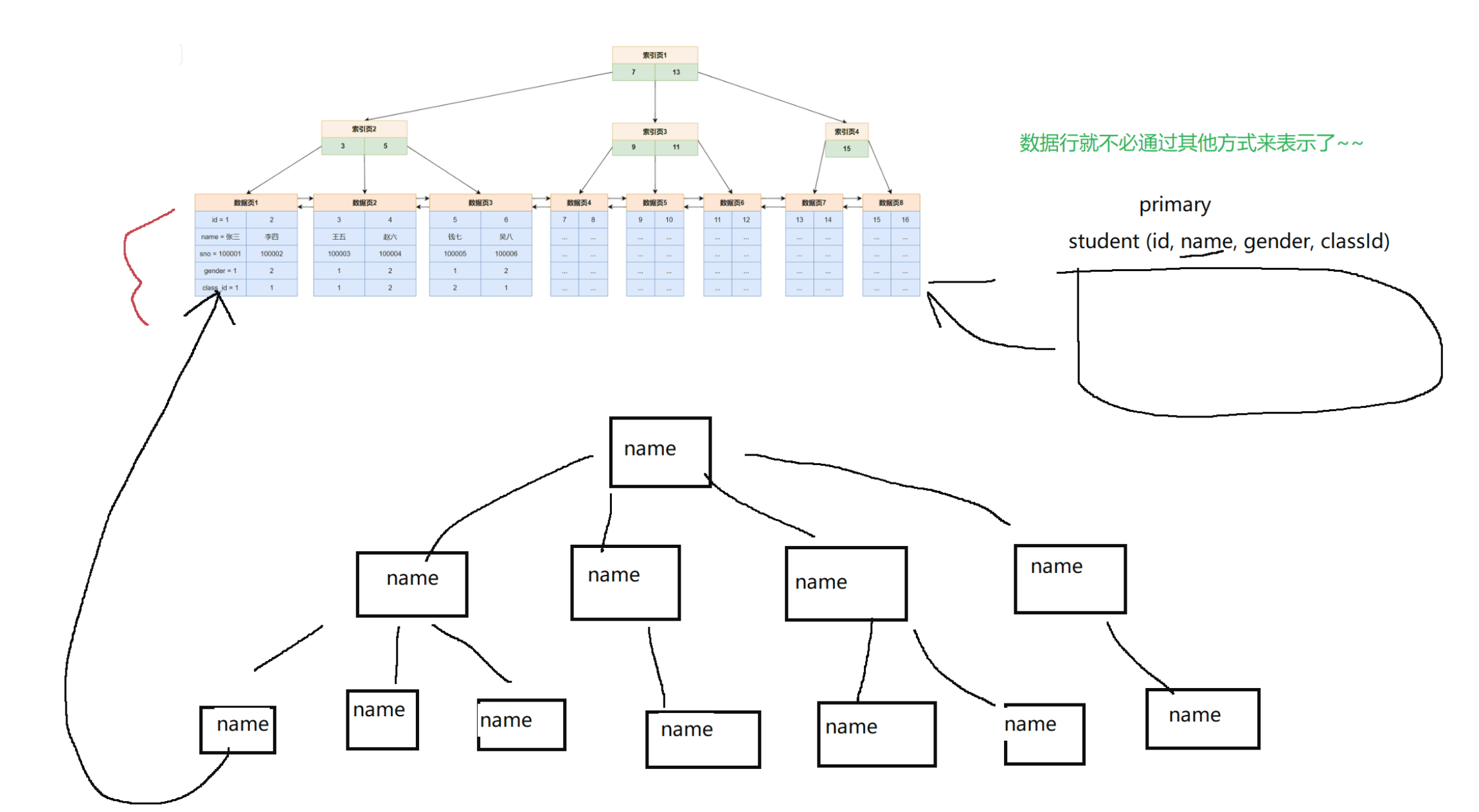
- 為了節省空間, 我們不可能每個列的索引(B+樹)都把數據行存儲在葉子節點, 這里我們非聚簇索引(B+樹)的葉子節點存儲的就不是全部數據行行了, 而是保存對應數據行的主鍵id(主鍵索引存儲的數據行)
- 那么針對name進行查詢的時候, 我們不是直接查詢到數據行, 而是查詢到數據行對應的主鍵id, 然后再去主鍵索引中, 查一遍, 得到最終對的數據行(這個再查一遍的操作也叫做回表操作)
注意: 不管是聚簇索引和是非聚簇索引, 我們都有一個前提條件就是要使用MySQL中的innoDB這樣的存儲引擎, 如果其他的存儲引擎有可能主鍵索引也是非聚簇索引.
- 那么存儲引擎是什么呢? 存儲引擎就是負責維護硬盤上數據存儲的結構的模塊. 對于MySQL來說, 最常用的存儲引擎就是InnoDB
索引覆蓋
- 當?個select語句使?了普通索引且查詢列表中的列剛好是創建普通索引時的所有或部分列,這時
就可以直接返回數據,?不?回表查詢,這樣的現象稱為索引覆蓋 - 就比如說我們select name from student, 那么我們不是查詢整個數據行, 我們就可以在普通索引(B+樹)的葉子節點就可以找到, 就不需要去主鍵索引(聚簇索引)哪里去找, 即不進行回表操作. 這個就叫做索引覆蓋.
創建索引
自動創建
- 當我們為?張表加主鍵約束(Primary key),外鍵約束(Foreign Key),唯?約束(Unique)時,
MySQL會為對應的的列?動創建?個索引 - 如果表不指定任何約束時,MySQL會?動為每?列?成?個索引并? ROW_ID 進?標識(前面說了不創建主鍵也有一個隱藏列作為主鍵索引)
- 這里創建主鍵, 自動創建
- 創建外鍵約束和唯一約束自動創建的索引
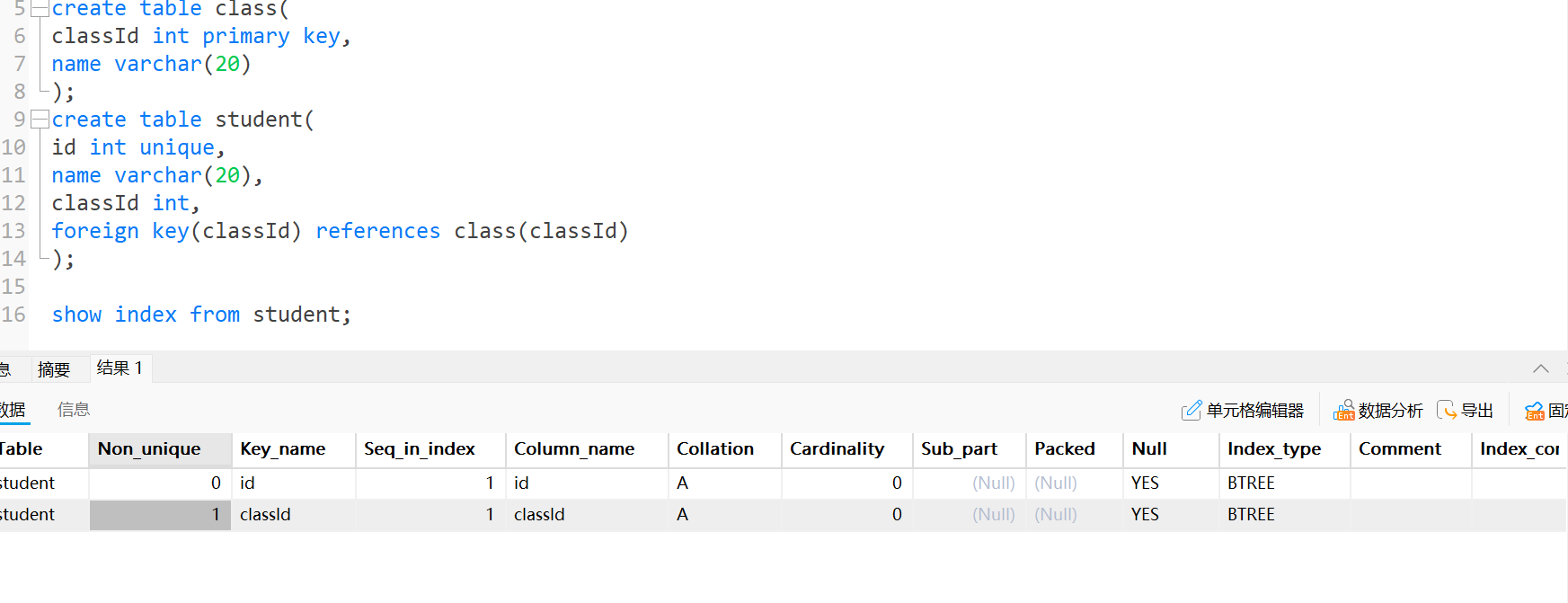
- 這里classID這個列的索引的意義就是為了針對父表class進行修改/刪除操作的時候, 需要根據classID在子表student進行查詢, 看他存不存在如果存在則不能進行修改/刪除操作, 即子表約束了父表.
- 唯一索引也就是創建唯一約束自動創建的.
手動創建
- create index 索引名 on 表名(列名)
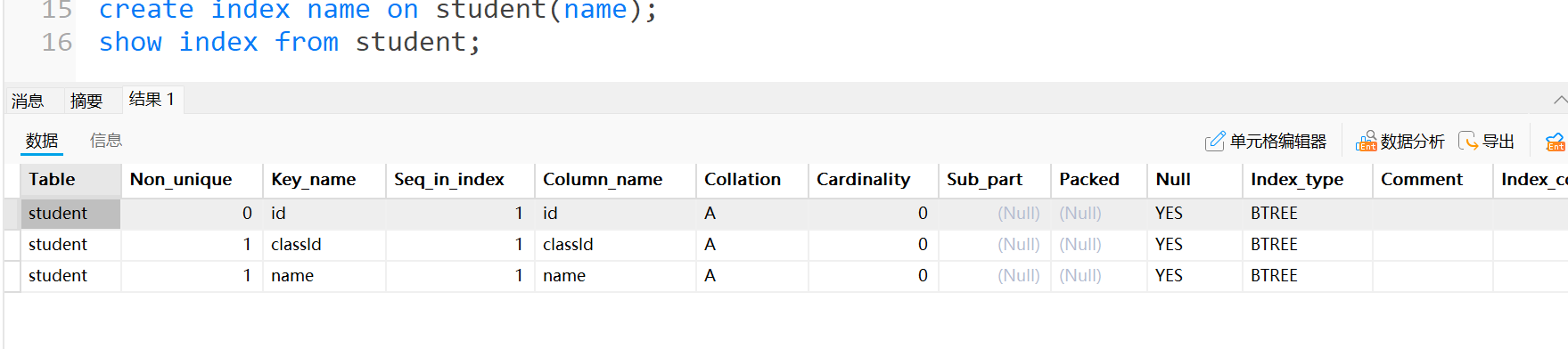
- 這樣我們的student表又增加了一個索引
創建復合索引

- 復合索引就是先按第一列查, 如果第一列相同了, 再去按照第二列來查找
查看索引
索引的一些注意事項
- 索引應該創建在?頻查詢的列上
- 索引需要占?額外的存儲空間
- 創建過多或不合理的索引會導致性能下降,需要謹慎選擇和規劃索引(索引會去創建B+樹, 如果數據多了, 是會影響性能的)
- 對表進?插?、更新和刪除操作時,同時也會修索引,可能會影響性能




)



架構中,SoC(系統級芯片)與FPGA(現場可編程門陣列)之間的數據交互)
DFS)









