講解代碼分為3個步驟:有什么用,為什么需要他,如何使用
保證大家耐心看完一定大有裨益!如果有懂的可以跳過,不過建議可以看完,查漏補缺嘛。
現在開始吧!
項目目標
我們的目標是根據泰坦尼克號乘客的個人信息(如年齡、性別、船艙等級等),預測他是否能在海難中幸存下來。這是一個典型的二元分類問題。現在我們開始吧,這是原版測試集和訓練集的下載地址:
鏈接: https://pan.baidu.com/s/1zc1dpc6Xm-BzHbeMrp4oSw?pwd=6688 提取碼: 6688?
由于原版訓練測試集有很多數據遺漏,所以我們要對其梳理一下。
第一步,導入必要庫與加載數據
import pandas as pd
import numpy as np# 加載數據
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')# 打印數據信息,快速了解數據
print("訓練數據信息:")
train_df.info()
print("\n測試數據信息:")
test_df.info()print("\n訓練數據前5行:")
print(train_df.head())1.pd.read_csv('train.csv'):
有什么用:
它的作用是讀取一個CSV(逗號分隔值)文件,并將其內容加載到一個 pandas DataFrame 對象中。在這里,代碼分別讀取了 train.csv 和 test.csv 兩個文件,并把它們存儲在名為 train_df 和 test_df 的變量里。df 是 DataFrame 的常用縮寫。
為什么要用它:
這是數據加載的核心步驟。沒有這一步,我們的程序就無法訪問和使用存儲在文件中的訓練數據和測試數據。在機器學習中,我們通常會將數據分成“訓練集”(用于訓練模型)和“測試集”(用于評估模型在未見過數據上的表現),所以這里會加載兩個文件。
使用語法:
pandas.read_csv(filepath_or_buffer)最主要的參數就是文件的路徑。這里
'train.csv'表示文件就在當前代碼運行的目錄下。這個函數還有很多可選參數,例如,如果你的數據不是用逗號分隔的,可以用
sep參數指定分隔符,如pd.read_csv('data.txt', sep='\t')用于讀取用Tab分隔的文件。
2.train_df.info():
有什么用:
這是一個非常方便的函數,用于快速獲取 DataFrame 的一個簡潔摘要。
為什么需要:
在真正開始處理數據前,我們需要對數據有一個宏觀的了解。.info() 方法能立刻告訴我們以下關鍵信息:
數據有多少行、多少列:了解數據規模。
每一列的名稱是什么。
每一列有多少個非空值:這是發現“缺失數據”最快的方法。如果“非空值”數量少于總行數,就說明這一列有數據缺失。
每一列的數據類型(
Dtype):比如是數字(int64,float64)、文本(object)還是其他類型。這對于后續的數據預處理至關重要。
使用語法
它是一個
DataFrame對象的方法,直接在變量名后調用即可,不需要參數。dataframe_variable.info()
3.train_df.head():
有什么用:
這個函數用于查看 DataFrame 的前幾行數據,默認是前5行。
為什么需要它?
.info() 給了我們數據的“骨架”信息,而 .head() 則讓我們能親眼看到數據的內容長什么樣。通過查看真實的數據樣本,我們可以直觀地了解每一列的數值范圍、文本格式等,對數據建立一個具象的認識。如果數據集有幾百萬行,你不可能把它全部打印出來看,所以看頭幾行和尾幾行(用.tail())是最高效的方式。
使用語法
dataframe_variable.head(n)n是你想查看的行數,是可選參數。如果省略,默認為5。例如,
train_df.head(10)就會顯示前10行數據。
運行結果:

Age, Cabin 有大量缺失值。Embarked 在訓練集中有少量缺失。
Sex, Embarked 是文本類別,需要轉換為數字。
PassengerId, Name, Ticket 對預測可能用處不大或者處理起來太復雜,我們初期可以先舍棄。Cabin 缺失太多,也先舍棄。
第二步,數據梳理準備
# 為了方便,我們將訓練集和測試集合并處理,最后再分開
# 保存測試集的PassengerId用于最后提交
test_passenger_ids = test_df['PassengerId']# 我們只挑選部分特征開始
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']# 合并數據
all_df = pd.concat([train_df[features], test_df[features]], axis=0).reset_index(drop=True)# 1. 處理缺失值
# Age: 使用中位數填充,因為它對異常值不敏感
all_df['Age'] = all_df['Age'].fillna(all_df['Age'].median())
# Fare: 同樣使用中位數填充
all_df['Fare'] = all_df['Fare'].fillna(all_df['Fare'].median())
# Embarked: 使用眾數(出現次數最多的值)填充
all_df['Embarked'] = all_df['Embarked'].fillna(all_df['Embarked'].mode()[0])
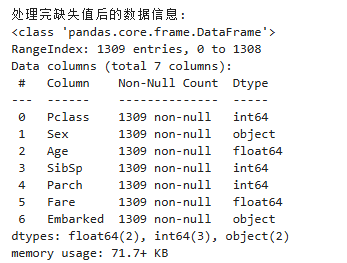
print("\n處理完缺失值后的數據信息:")
all_df.info()1. test_passenger_ids = test_df['PassengerId']
有什么用?
這行代碼從測試集
test_df中提取出'PassengerId'這一列,并將其保存到一個新的變量test_passenger_ids中。
為什么需要它?
在很多機器學習任務(尤其是像Kaggle競賽)中,
PassengerId這種ID列是用來唯一標識每一行數據的,但它本身不包含任何可供模型學習的“特征”信息(乘客的ID號與他能否生還無關)。因此,我們不應該把它作為特征喂給模型去訓練。但它又非常重要。當我們用模型對測試集
test_df做出預測后,我們需要將預測結果和每個乘客對應起來,才能生成最終的提交文件。所以,我們在這里提前把它單獨存起來,等所有處理和預測都完成后,再用它來和預測結果配對。
使用語法
dataframe['column_name']這是
pandas中選擇單個列的標準方法。test_df['PassengerId']會返回一個pandas Series對象,里面包含了所有測試集乘客的ID。
2. features = ['Pclass', 'Sex', 'Age', ...]
有什么用?
這行代碼創建了一個Python列表(
list),其中包含了我們初步決定要用來訓練模型的特征列的名稱。這個過程叫做特征選擇(Feature Selection)。
為什么需要它?
一個原始數據表里可能有很多列,但并非所有列都對我們的預測目標(比如,預測乘客是否生還)有用。
排除無關特征:像
PassengerId和Name(乘客姓名)通常被認為是無關特征。簡化模型:選擇一個特征子集可以使我們的代碼更清晰,模型更簡單,訓練速度更快。
方便管理:把所有要用的特征名放在一個列表里,后續可以很方便地從DataFrame中一次性把它們都選出來,也便于未來增刪特征做實驗。
使用語法
這是標準的Python列表定義語法:
list_name = [element1, element2, ...]。
3. all_df = pd.concat([...]).reset_index(drop=True)
這一行做了兩件大事:concat 和 reset_index。我們分開看。
pd.concat([train_df[features], test_df[features]], axis=0)
有什么用?
將訓練集和測試集中我們選定的特征列(
features列表中的那些列)合并成一個大的DataFrameall_df。
為什么需要它?
為了確保預處理的一致性。訓練集和測試集常常需要進行相同的預處理操作,比如:
填充缺失值:
Age列可能有缺失值。我們通常會用所有數據(訓練集+測試集)的年齡平均值或中位數來填充,這樣更準確。編碼分類變量:
Sex列是'male'/'female'這樣的文本,需要轉換成0/1這樣的數字。Embarked列也是同理。我們必須保證在訓練集和測試集中,相同的文本被轉換成相同的數字。
將它們合并后,我們只需要對
all_df這一個DataFrame進行預處理,就可以保證操作的統一性,避免了對訓練集和測試集重復寫同樣的代碼,減少了出錯的可能。處理完畢后,我們再將它們拆分回訓練集和測試集。
使用語法
pd.concat(objs, axis=0)objs: 一個列表,包含了要合并的DataFrame對象。這里是[train_df[features], test_df[features]]。注意train_df[features]表示從train_df中只選擇features列表里包含的那些列。axis=0: 這是關鍵參數。axis=0表示縱向合并(按行合并),也就是把第二個DataFrame接到第一個的下面,行數相加。這正是我們合并訓練/測試集時想要的。如果用axis=1,則是橫向合并(按列合并)。
4.reset_index(drop=True)
有什么用?
為合并后的新DataFrame
all_df創建一個全新的、連續的索引。
為什么需要它?
當你用
pd.concat合并兩個DataFrame時,默認會保留它們各自原來的索引。比如,訓練集索引是 0 到 890,測試集索引是 0 到 417。合并后,新的all_df的索引就會是0, 1, ..., 890, 0, 1, ..., 417,存在大量重復。這會給后續的數據篩選和處理帶來麻煩。reset_index()會生成一個從0開始的全新連續索引 (0, 1, 2, ... , 1307)。參數
drop=True的作用是丟棄原來的舊索引。如果不加這個參數,原來的舊索引會被當作一個新列(列名為'index')保留下來,但我們通常不需要它,所以直接丟棄。
5.all_df['Age'] = all_df['Age'].fillna(all_df['Age'].median())
有什么用?
這兩行代碼分別找到了
Age(年齡)列和Fare(票價)列中所有的缺失值,并用這兩列各自的中位數(median)來填充它們。
為什么需要它?(特別是,為什么用中位數?)
必要性:
Age和Fare是重要的數值特征,但它們存在缺失數據,必須填充。策略選擇:對于數值型數據,常見的填充策略有使用平均值(mean)、中位數(median)或眾數(mode)。
平均值:計算簡單,但容易被“異常值”(outliers)影響。例如,有幾個乘客買了天價船票,這會把平均票價拉得很高,用這個偏高的平均值去填充缺失票價可能就不太合理。
中位數:將所有數據排序后取中間的那個數。它最大的優點是對異常值不敏感(魯棒性強)。即使有天價船票,中位數也不會受其影響,因此它往往能更好地代表數據的“一般水平”。正如代碼注釋所說,這是一個更穩妥的選擇。
使用語法
代碼結構為:
df['列名'] = df['列名'].fillna(要填充的值)all_df['Age']: 選中Age這一列數據(這是一個Pandas Series)。.median(): 這是Pandas Series的一個方法,調用它會計算出該列的中位數,返回一個數字。.fillna(value): 找到該列中所有的NaN,并將它們替換為括號中提供的value。整個流程是:先計算出
Age列的中位數,然后用這個中位數去填充Age列中的所有NaN,最后將填充好的新列數據覆蓋掉原來的Age列。Fare列同理。
6.all_df['Embarked'] = all_df['Embarked'].fillna(all_df['Embarked'].mode()[0])
有什么用?
這行代碼找到了
Embarked(登船港口)列中的所有缺失值,并用該列的眾數(mode)來填充。眾數就是數據中出現次數最多的那個值。
為什么需要它?(特別是,為什么用眾數?)
Embarked列是分類特征,它的值是文本(如'S', 'C', 'Q'),而不是數字。對于這種數據,我們無法計算平均值或中位數。最合乎邏輯的填充方法,就是用出現頻率最高的值來填充。我們推斷,缺失的值有最大的可能性是那個最常見的值。
使用語法
語法結構和上面類似,但有一個關鍵點
[0]。.mode(): 這個方法計算列的眾數。為什么是
.mode()[0]? 因為一列數據的眾數可能不止一個(比如'S'和'C'的出現次數完全相同且都是最高)。所以.mode()方法總是返回一個Pandas Series,里面包含一個或多個眾數值。即便只有一個眾數,它也依然被包在一個Series里。我們需要通過索引[0]來把第一個(通常也是唯一一個)眾數值取出來,作為一個單獨的值去填充。
經過這步處理后,all_df中這三列的“窟窿”就被補上了,數據變得更加完整,可以用于下一步的轉換和建模。
最后的運行結果為:
# 2. 將分類特征轉換為數值特征
# Sex: Male -> 0, Female -> 1
all_df['Sex'] = all_df['Sex'].map({'male': 0, 'female': 1})
# Embarked: 使用獨熱編碼 (One-Hot Encoding)
all_df = pd.get_dummies(all_df, columns=['Embarked'], prefix='Embarked')print("\n轉換分類特征后的數據前5行:")
print(all_df.head())1.all_df['Sex'] = all_df['Sex'].map({'male': 0, 'female': 1})
有什么用?
這行代碼將
Sex列中的文本值 'male' 替換為數字0,'female' 替換為數字1。這是一種手動實現的標簽編碼(Label Encoding)。
為什么需要它?
Sex列是一個典型的二元分類特征(只有兩種可能的類別)。對于這種情況,最簡單直接的方法就是將兩個類別分別映射到一個數字。這樣,'male'和'female'這兩個字符串就被轉換成了模型可以處理的0和1。
使用語法
Series.map(字典)all_df['Sex']選中Sex這一列數據。.map()是Pandas Series的一個方法,它可以接受一個字典作為參數。{'male': 0, 'female': 1}就是這個映射字典。.map方法會遍歷Sex列中的每一個元素,如果在字典的“鍵”(key)中找到了該元素(比如'male'),就把它替換成字典里對應的“值”(value)(也就是0)。最后,將這個轉換后的新Series賦值回
all_df['Sex']列。
2.all_df = pd.get_dummies(all_df, columns=['Embarked'], prefix='Embarked')
有什么用?
這行代碼對
Embarked(登船港口)列進行了獨熱編碼(One-Hot Encoding)。它會做兩件事:
1.移除原來的Embarked列。
2.根據Embarked列中所有不重復的值(比如'S', 'C', 'Q'),創建出對應數量的新列(Embarked_S, Embarked_C, Embarked_Q)。
對于每一行數據,如果原來的Embarked值是'S',那么在新列Embarked_S中,該行的值就為1,而在Embarked_C和Embarked_Q中則為0。
為什么需要它?(特別是,為什么不用map方法映射成0, 1, 2?)
Embarked列是多元(無序)分類特征。它有三個類別'S', 'C', 'Q'。陷阱:如果我們像處理
Sex列一樣,簡單地把它們映射成S=0,C=1,Q=2,模型可能會錯誤地理解它們之間存在某種順序關系或大小關系(比如認為Q>C>S)。但實際上,這三個港口只是地點不同,沒有順序或大小之分。這種錯誤的假設會干擾模型的學習。獨熱編碼的優勢:它通過將一個特征拆分成多個“是/否”的二元特征來完美地解決了這個問題。每個新列代表“是否是這個港口?”。這樣,特征之間就變得相互獨立,模型不會再做出錯誤的順序假設。這是處理無序多元分類特征的標準做法。
使用語法
pd.get_dummies(data, columns, prefix)data: 需要進行獨熱編碼的整個DataFrame,這里是all_df。columns=['Embarked']: 一個列表,指定要對哪些列進行獨熱編碼。prefix='Embarked': 為新生成的列添加前綴。如果不指定,新列名可能就是'S', 'C', 'Q',可讀性較差。加上前綴后,新列名會變成Embarked_S,Embarked_C,Embarked_Q,非常清晰。這個函數會返回一個全新的、已經完成了編碼的DataFrame,我們再把它賦值給
all_df。
輸出結果:
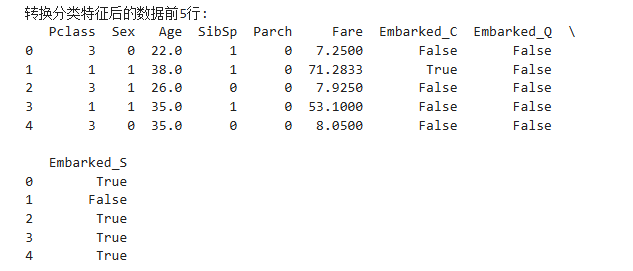
Sex列已經變成了0和1。原來的
Embarked列消失了。數據表的末尾多了幾個
Embarked_開頭的新列。
# 3. 特征縮放 (Feature Scaling)
# 神經網絡對特征的尺度很敏感,我們使用標準化(Standardization)
from sklearn.preprocessing import StandardScaler# 需要縮放的列
cols_to_scale = ['Age', 'Fare', 'Pclass', 'SibSp', 'Parch']
scaler = StandardScaler()
all_df[cols_to_scale] = scaler.fit_transform(all_df[cols_to_scale])print("\n特征縮放后的數據前5行:")
print(all_df.head())有什么用?
這段代碼的核心作用是對指定的數值特征列進行標準化(Standardization)。
標準化處理后,這些列的數據都會被轉換成平均值為0,標準差為1的新數據。
為什么需要它?(這可能是最重要的一步)
不同特征的“量綱”差異巨大:觀察我們的數據,
Age的范圍可能是0-80,Fare的范圍可能是0-500+,而Pclass(艙位等級)只有1, 2, 3。這些特征的數值尺度(量綱)相差懸殊。對神經網絡訓練的影響:神經網絡的權重更新依賴于梯度下降算法。如果特征尺度差異很大:
收斂速度變慢:尺度大的特征(如
Fare)在計算損失和梯度時會占據主導地位,導致損失函數的“等高線圖”變成一個又扁又長的橢圓形。模型優化的路徑會像在一個狹長的山谷中來回震蕩,而不是平穩地走向最低點,這會大大減慢模型的訓練收斂速度。權重學習不公平:模型可能會錯誤地認為,數值范圍更大的特征就更重要。通過縮放,我們將所有特征拉到了一個可比較的起跑線上,讓模型能夠根據特征真正的預測能力來學習其權重,而不是被它們的原始尺度所迷惑。
標準化 vs. 歸一化:
標準化 (Standardization) (我們用的這種): 將數據處理成均值為0,標準差為1。它不把數據限制在特定范圍內,對異常值的敏感度較低,是神經網絡中最常用的縮放方法之一。
歸一化 (Normalization / Min-Max Scaling): 將數據縮放到一個固定的區間,通常是[0, 1]。
使用語法
cols_to_scale = [...]: 定義一個列表,清晰地指明哪些列需要被縮放。這里包含了我們所有的數值型特征(包括Pclass這種有序分類特征,我們也可以當數值特征來處理和縮放)。scaler = StandardScaler(): 創建一個StandardScaler的實例(對象)。此時,這個scaler對象還是“空的”,它不了解我們的數據。scaler.fit_transform(...): 這是最核心的一步,它是一個復合操作:fit()(擬合):scaler首先會“學習”我們提供的數據(all_df[cols_to_scale])。具體來說,它會計算出Age,Fare等每一列的平均值和標準差,并把這些統計值保存在scaler對象內部。transform()(轉換):然后,scaler會使用剛剛學到的平均值和標準差,對每一列的每一個數據點應用標準化公式:新值 = (原值 - 平均值) / 標準差。fit_transform將這兩個步驟合并為一步,代碼更簡潔高效。它會返回一個包含所有轉換后數據的新數組。
all_df[cols_to_scale] = ...: 將fit_transform返回的包含新值的數組,賦值回all_df中對應的列,完成對原始數據的替換。
輸出結果:
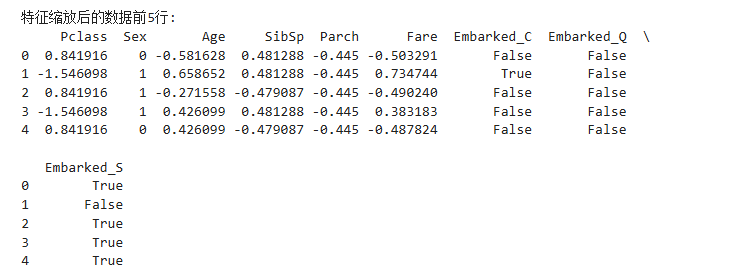
# 4. 分離回訓練集和測試集
train_processed_df = all_df[:len(train_df)]
test_processed_df = all_df[len(train_df):]
target = 'Survived'
y_train = train_df[target] # 訓練集的標簽有什么用?
這兩行代碼將我們之前合并并處理好的
all_df,重新精確地拆分回處理后的訓練集train_processed_df和處理后的測試集test_processed_df。
為什么需要它?
我們的策略是“合并處理,分離建模”。
合并是為了確保對訓練集和測試集應用完全一致的預處理規則(比如用同一個中位數填充,用同一個縮放器
scaler)。分離是機器學習的基本原則。我們必須用訓練集 (
train_processed_df和其對應的標簽y_train) 來訓練模型,然后用訓練好的模型去對測試集 (test_processed_df) 進行預測。測試集是模擬的“未來未知數據”,在訓練過程中絕對不能讓模型看到測試集的數據(除了在預處理階段為了更準確的統計而“借用”了一下),否則就是“作弊”,會導致模型評估結果過于樂觀且不真實。
使用語法
這里利用了Pandas DataFrame對Python切片(slicing)語法的支持,非常巧妙。
len(train_df): 我們獲取了原始訓練集train_df的行數。假設它有891行。all_df[:len(train_df)]: 這句代碼的意思是“從all_df的第0行開始,取到第891行(不包括第891行)”。因為我們當初是先把train_df放在前面進行合并的,所以這部分數據不多不少,正好就是屬于原來訓練集的那部分數據。all_df[len(train_df):]: 這句代碼的意思是“從all_df的第891行開始,一直取到最后一行”。這部分數據正好就是屬于原來測試集的那部分。
結果:
現在,我們擁有了:
train_processed_df(X_train): 處理好的訓練特征y_train(y_train): 訓練標簽test_processed_df(X_test): 處理好的測試特征
“萬事俱備,只欠東風”,下一步就是將它們轉換成PyTorch Tensor,搭建神經網絡這個“東風”,來完成最終的訓練和預測任務了!
我們先看看我們的訓練集:
import torch
from torch.utils.data import Dataset, DataLoader, TensorDatasetprint(train_processed_df.info())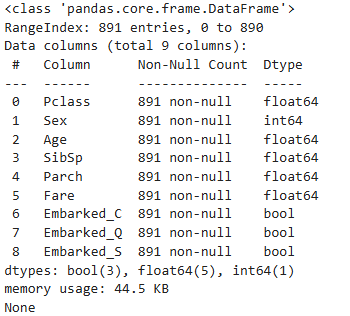
第三步,數據打包與搭建神經網絡
# 直接轉換為NumPy浮點數組 -> 再轉PyTorch張量
X_np = train_processed_df.to_numpy(dtype=np.float32) # 強制指定float32
X_train_tensor = torch.from_numpy(X_np) # NumPy->PyTorch自動類型匹配# 標簽處理(注意保持維度一致)
y_np = y_train.to_numpy(dtype=np.float32)
y_train_tensor = torch.from_numpy(y_np).view(-1, 1) # 相當于unsqueeze(1)1.train_processed_df.to_numpy(dtype=np.float32)
有什么用?
將我們處理好的
train_processed_df這個Pandas DataFrame,轉換成一個NumPy數組X_np。
為什么需要它?
PyTorch的親密伙伴:PyTorch與NumPy的集成是無縫的。將數據從Pandas轉換到PyTorch時,NumPy是最理想、最高效的中間橋梁。
強制指定
np.float32:這是一個非常關鍵的細節。默認情況下,NumPy可能會創建float64(雙精度)的數組。但在深度學習中,幾乎所有的計算都是在float32(單精度)下進行的。這能在保證足夠精度的情況下,將內存占用和計算量減半,尤其是在使用GPU時,性能提升非常明顯。所以我們在這里強制指定數據類型為np.float32。
使用語法
.to_numpy(): 這是Pandas DataFrame或Series對象的方法,用于將其轉換為NumPy數組。dtype=np.float32: 是一個可選參數,用來指定轉換后數組中元素的數據類型。
2.torch.from_numpy(X_np)
有什么用?
從NumPy數組
X_np創建一個PyTorch張量X_train_tensor。這正是我們的最終目的。
為什么需要它?
PyTorch框架中的所有運算,無論是模型的前向傳播還是反向傳播,都必須在
torch.Tensor對象上進行。沒有這一步,數據就無法進入PyTorch的生態系統。一個重要的特性:
torch.from_numpy()創建的張量和原始的NumPy數組共享內存。這意味著它們指向計算機內存中的同一塊數據。這樣做的好處是效率極高,因為它避免了復制數據的開銷。但也要注意,如果后續修改了NumPy數組,那么對應的PyTorch張量也會跟著改變,反之亦然。在這個場景下,這完全沒問題,因為我們只是做最后的轉換。
使用語法
torch.from_numpy(numpy_array): PyTorch的函數,輸入一個NumPy數組,輸出一個PyTorch張量。輸出張量的數據類型會自動與輸入的NumPy數組匹配(這也是我們上一步要指定float32的原因)。
3.torch.from_numpy(y_np).view(-1, 1):
有什么用?
將標簽NumPy數組
y_np轉換為PyTorch張量,并且調整其形狀(維度)。
為什么需要
.view(-1, 1)?原始形狀:
torch.from_numpy(y_np)執行后,得到的張量是一個一維向量,形狀是[891](假設有891個樣本)。模型輸出的形狀:我們的模型在進行二分類任務時,最后一層的輸出通常是一個形狀為
[批量大小, 1]的二維張量。對于整個訓練集,就是[891, 1]。維度匹配:在計算損失時,PyTorch需要模型輸出和標簽張量的形狀能夠匹配。如果一個是
[891, 1],另一個是[891],可能會導致廣播(broadcasting)錯誤或潛在的bug。解決方案:
.view(-1, 1)的作用就是將形狀從[891]強制“重塑”為[891, 1]。它把一個一維的“列表”變成了一個N行1列的“列向量”。這樣就確保了我們的標簽張量和模型輸出張量的維度是完全一致的,可以讓損失計算準確無誤地進行。
使用語法
tensor.view(shape): 是一個改變張量形狀的方法。view(-1, 1):這里的-1是一個占位符,意思是PyTorch根據總元素數量和另一個維度(這里是1)自動計算出這個維度的大小。所以view(-1, 1)就是告訴PyTorch:我們想要1列,行數你幫我算好。對于一維向量來說,
.view(-1, 1)和.unsqueeze(1)的效果是完全一樣的,都是在最后增加一個維度。
現在,我們已經成功地將數據從最開始的CSV文件,一路過關斬將,變成了PyTorch可以直接使用的、格式干凈、維度正確的張量:
X_train_tensor: 訓練特征張量,形狀為[樣本數, 特征數]y_train_tensor: 訓練標簽張量,形狀為[樣本數, 1]
這兩份張量已經準備好,可以打包成Dataset和DataLoader
# 2. 創建TensorDataset
# TensorDataset可以把特征和標簽打包在一起
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)# 3. 創建DataLoader
# DataLoader可以幫我們打亂數據、劃分批次
BATCH_SIZE = 64
train_loader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True)1.TensorDataset:將特征和標簽打包
有什么用?
TensorDataset是一個PyTorch提供的工具類,它的作用就像一個拉鏈,將我們的特征張量X_train_tensor和標簽張量y_train_tensor配對打包在一起。它能確保數據和標簽一一對應。當你從
train_dataset中取第i個元素時,你會同時得到X_train_tensor的第i行和y_train_tensor的第i行。
為i什么需要它?
數據與標簽的綁定:在訓練時,模型需要同時拿到一條數據和它對應的正確答案。
TensorDataset就是實現這種綁定的最簡單直接的方式。遵循標準接口:它創建了一個符合PyTorch標準的
Dataset對象。所有Dataset對象都有共同的行為(比如可以用len()獲取總長度,可以用[]索引來獲取數據),這使得它可以無縫地被下一步的DataLoader所使用。當你的數據已經全部在內存中并是Tensor格式時,TensorDataset是創建數據集的首選。
使用語法
torch.utils.data.TensorDataset(*tensors)你需要傳入一個或多個張量作為參數。
關鍵要求:所有傳入的張量的第一個維度(也就是樣本數量)必須相等。在我們的例子中,
X_train_tensor(形狀[891, 特征數])和y_train_tensor(形狀[891, 1])的第一個維度都是891,所以滿足這個要求。
2. DataLoader:自動化數據加載器
有什么用?
DataLoader是PyTorch中最核心的數據加載工具。它接收一個Dataset對象(比如我們剛創建的train_dataset),并把它包裝成一個強大的Python迭代器(iterator)。在我們訓練模型時,可以直接遍歷這個
train_loader,它會自動地、高效地為我們提供一個個小批量(mini-batch) 的數據。
為什么需要它?(這是PyTorch訓練流程的精髓)
實現小批量梯度下降:我們不可能一次性把整個數據集(891條數據)都扔進模型去訓練,這會占用巨大內存且效率低下。標準的做法是“小批量梯度下降(Mini-batch Gradient Descent)”,即每次只用一小部分數據(比如64條)來計算損失、更新模型權重,然后重復這個過程。
DataLoader的核心工作就是幫我們自動完成這個分批操作。數據打亂(
shuffle=True):這是防止模型過擬合、提升泛化能力的關鍵。設置為True后,DataLoader會在每個訓練周期(epoch)開始前,都重新隨機打亂數據的順序。這樣可以確保模型不會學到數據的排列順序,而是學習數據本身內在的模式。在訓練時,這個參數幾乎必須設為True。內存管理與效率:通過分批加載,我們無需一次性將所有數據載入到昂貴的GPU顯存中,使得訓練大數據集成為可能。
DataLoader還支持多線程預加載數據(通過num_workers參數),可以實現CPU加載數據和GPU計算的并行,大大提升訓練效率。
使用語法
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, ...)dataset: 我們要加載的Dataset對象,這里是train_dataset。batch_size: 每個批次包含的樣本數量。64是一個非常常見的大小,通常設為2的冪次方以提高硬件效率。最后一批的數量可能會小于batch_size。shuffle=True: 一個布爾值。True表示在每個epoch開始時打亂數據順序。對于訓練集,我們用True;對于驗證集和測試集,我們通常用False,因為評估時我們希望順序是固定的,便于比較結果。
搭建網絡
import torch.nn as nn
import torch.nn.functional as Fclass TitanicNet(nn.Module):def __init__(self, input_features):super(TitanicNet, self).__init__()# 定義網絡層self.fc1 = nn.Linear(input_features, 64) # 輸入層 -> 第一個隱藏層self.fc2 = nn.Linear(64, 32) # 第一個隱藏層 -> 第二個隱藏層self.fc3 = nn.Linear(32, 1) # 第二個隱藏層 -> 輸出層self.dropout = nn.Dropout(0.2) # Dropout層,防止過擬合def forward(self, x):# 定義數據在網絡中的流向(前向傳播)x = F.relu(self.fc1(x)) # 使用ReLU激活函數x = self.dropout(x) # 應用dropoutx = F.relu(self.fc2(x)) # 使用ReLU激活函數x = self.dropout(x) # 應用dropoutx = self.fc3(x) # 輸出層不需要激活函數,因為我們將使用BCEWithLogitsLossreturn x1. 整體框架: class TitanicNet(nn.Module)
有什么用?
這段代碼定義了一個名為
TitanicNet的Python類,它就是我們神經網絡的模型骨架。所有在PyTorch中自定義的模型,都應該**繼承(inherit)**自
torch.nn.Module這個基類。
為什么需要它?
繼承
nn.Module后,我們的TitanicNet類就能自動獲得PyTorch提供的各種強大功能,比如:自動追蹤模型中所有可學習的參數(權重和偏置)。
方便地將整個模型移動到GPU上(用
.to(device))。輕松地在訓練模式 (
.train()) 和評估模式 (.eval()) 之間切換(這對于Dropout和BatchNorm等層至關重要)。加載和保存整個模型的狀態。
這是一種約定,是PyTorch約定俗成的東西。
2. __init__ 方法:定義模型的網絡層
有什么用?
__init__方法是這個類的構造函數。在PyTorch模型中,它的核心任務是定義并初始化模型需要用到的所有網絡層。這些網絡層被定義好后,會作為類的屬性(比如
self.fc1)存儲起來,等待在forward方法中被調用。
為什么需要它?
這里是“藍圖規劃”階段。我們在這里一次性把所有需要的“磚瓦”都準備好,但先不關心它們怎么連接。這讓模型的結構非常清晰。
語法詳解
super(TitanicNet, self).__init__(): 必須調用!這行代碼的作用是調用父類nn.Module的構造函數,完成一些必要的內部初始化,否則模型無法正常工作。self.fc1 = nn.Linear(input_features, 64):nn.Linear(in_features, out_features): 定義一個全連接層(Fully Connected Layer),也叫線性層。它會對輸入數據做一次線性變換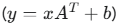
in_features: 輸入特征的數量。input_features就是我們處理好的數據X_train_tensor的列數。out_features: 輸出特征的數量,也就是該層神經元的個數。這里是64。
self.fc2 = nn.Linear(64, 32): 定義第二個全連接層。注意,它的輸入維度64必須和上一層fc1的輸出維度64完全一致。self.fc3 = nn.Linear(32, 1): 定義輸出層。它的輸出維度是1,因為我們要做的是二分類任務(生還 vs. 未生還),最終只需要一個數值來代表預測結果。self.dropout = nn.Dropout(0.2):nn.Dropout(p): 定義一個Dropout層。它是一種非常有效的正則化手段,用于防止模型過擬合。p=0.2: 表示在訓練過程中,每次數據流過這個層時,都有20%的神經元會被隨機“丟棄”(暫時使其輸出為0)。這強迫網絡不能過度依賴任何一個神經元,從而學習到更魯棒的特征。重要:Dropout只在訓練模式(
.train())下生效,在評估模式(.eval())下會自動失效.
3. forward 方法:連接網絡層,定義數據流
語法詳解
x = F.relu(self.fc1(x)):self.fc1(x): 首先,輸入數據x流過第一個全連接層。F.relu(...):relu是修正線性單元(Rectified Linear Unit),是一種激活函數。它的公式是 f(x)=max(0,x)。為什么需要激活函數? 如果沒有像
ReLU這樣的非線性激活函數,那么無論我們堆疊多少個線性層,整個網絡本質上還是一個線性模型,無法學習復雜的非線性規律。ReLU是目前最常用、最高效的激活函數之一。
x = self.dropout(x): 在激活之后,應用dropout。x = self.fc3(x): 數據流過最后的輸出層。為什么最后一層沒有激活函數??因為我們計劃使用的損失函數是
BCEWithLogitsLoss。這個損失函數內部已經集成了Sigmoid激活函數,并且這么做在數值上更穩定。所以,它期望的輸入是未經激活的原始輸出值,這些原始值被稱為 logits。
# 確定輸入特征的數量
input_dims = X_train_tensor.shape[1]
model = TitanicNet(input_features=input_dims)
print(model)
1. input_dims = X_train_tensor.shape[1]
有什么用?
這行代碼的作用是動態地獲取我們訓練數據
X_train_tensor的特征數量(也就是數據的列數),并將其存儲在變量input_dims中。
為什么需要它?
模型的“入口”尺寸必須匹配:回憶一下我們定義的
TitanicNet模型,它的__init__方法需要一個參數input_features,這個參數決定了模型第一層nn.Linear(input_features, 64)的輸入神經元數量。這個數量必須和我們喂給它的數據的特征數完全一樣,否則數據就塞不進模型的入口,程序會報錯。代碼的靈活性:我們當然可以手動數一下有幾個特征,然后寫一個固定的數字(比如
input_features=10)。但這是非常不好的編程習慣。如果我們將來調整了數據預處理步驟,增刪了某個特征,就必須手動回來修改這個數字,很容易忘記而出錯。像現在這樣,直接從數據X_train_tensor的形狀中獲取特征數,意味著無論我們的數據有多少列,代碼都能自動適應,無需任何修改。
使用語法
tensor.shape: 這是PyTorch張量的一個屬性,它返回一個元組(tuple),表示張量在各個維度上的大小。對于X_train_tensor,它的形狀是[樣本數量, 特征數量]。.shape[1]: 我們通過索引[1]來獲取這個元組中的第二個元素,也就是特征數量。
2. model = TitanicNet(input_features=input_dims)
有什么用?
這行代碼根據我們之前定義的
TitanicNet類(藍圖),創建了一個具體、可用的模型實例(對象),并賦值給變量model。
為什么需要它?
class TitanicNet(...)只是它定義了模型應該長什么樣。而model = TitanicNet(...)這一步,才建造出一個實際的模型。這個
model對象現在是一個包含了我們所有網絡層(fc1,fc2,fc3,dropout)的集合體。PyTorch已經為這些層自動初始化了隨機的權重(weights)和偏置(biases)。這個model就是我們接下來要進行訓練、評估和預測的主體。
使用語法
這是標準的Python類實例化語法。
TitanicNet(input_features=input_dims): 調用類的名字,并傳入構造函數__init__所需要的參數。這里,我們把剛剛動態獲取的特征數input_dims傳遞給了input_features參數。
# 定義損失函數
# BCEWithLogitsLoss 結合了 Sigmoid 和 BCELoss,數值上更穩定
criterion = nn.BCEWithLogitsLoss()# 定義優化器
# Adam 是一種常用的自適應學習率優化算法
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 設置訓練參數
EPOCHS = 100
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
model.to(device) # 將模型移動到GPU(如果可用)print(torch.__version__)
print(torch.version.cuda) # 應該顯示 CUDA 版本1. criterion = nn.BCEWithLogitsLoss():定義損失函數
有什么用?
這行代碼定義了我們的損失函數(Loss Function),也叫代價函數(Cost Function)或評判標準(Criterion)。
它的核心任務是衡量模型的預測結果與真實標簽之間的差距。差距越大,損失值就越高,說明模型預測得越“差”。
為什么需要它?
為訓練提供目標:整個神經網絡的訓練過程,就是一個想方設法最小化損失函數值的過程。損失函數為模型的學習指明了方向和目標。
選擇
BCEWithLogitsLoss的原因:BCE是二元交叉熵(Binary Cross-Entropy)的縮寫,這是解決二分類問題(如我們的“生還/未生還”)的標準損失函數。WithLogits是它的精髓所在。正如我們之前在定義模型時討論的,我們的模型最后一層輸出的是未經激活的原始數值(logits)。BCEWithLogitsLoss這個損失函數會在內部自動幫我們完成Sigmoid激活,然后再計算二元交叉熵損失。數值穩定性:您的注釋非常正確,將Sigmoid和BCE合并在一個函數里計算,可以避免在某些情況下(比如logits的絕對值很大時)出現浮點數溢出問題,比我們自己手動加Sigmoid層再用
BCELoss要更穩定、更安全。
使用語法
criterion = nn.損失函數類(): 我們通過實例化一個損失函數類來創建一個可用的損失函數對象。對于BCEWithLogitsLoss的基礎用法,不需要傳入任何參數。
2. optimizer = torch.optim.Adam(...):定義優化器
有什么用?
這行代碼定義了我們的優化器(Optimizer)。如果說損失函數是指出“錯在哪里”,那么優化器就是負責“如何改正”的工具。
它根據損失函數計算出的梯度(指明了讓損失變小的方向),來更新模型中所有的權重和偏置,從而讓模型在下一次預測時表現得更好。
為什么需要它?
驅動模型學習:優化器是模型學習的引擎。在訓練循環中,我們喊一聲
optimizer.step(),模型的所有參數就會根據計算好的梯度進行一次微調。沒有優化器,模型就只是一個靜態的結構,無法學習。選擇
Adam的原因:Adam(自適應矩估計)是目前最流行、最通用的優化器之一。相比傳統的隨機梯度下降(SGD),Adam能夠為模型中的每一個參數自適應地調整學習率。在絕大多數任務中,它都能快速、穩定地收斂,是一個非常優秀的“萬金油”選擇,非常適合作為入門和首選。
使用語法
optimizer = torch.optim.優化器類(params, ...)params = model.parameters(): 這是最重要的參數。我們必須明確告訴優化器,它需要更新哪些參數。model.parameters()是nn.Module提供的一個便捷方法,它會自動返回我們模型中所有需要學習的參數(所有nn.Linear等層里的權重和偏置)。lr=0.001:lr代表學習率(Learning Rate)。它控制了每次更新參數時的“步子”大小。這是一個至關重要的超參數。0.001是Adam優化器一個非常常用且效果不錯的初始值。
3. device = ... 和 model.to(device):配置計算設備
有什么用?
這幾行代碼的作用是自動檢測當前環境是否有可用的NVIDIA GPU(以及CUDA環境),并將我們的模型遷移到指定的計算設備上。
為什么需要它?
大幅加速訓練:神經網絡的計算核心是海量的矩陣運算。GPU(圖形處理器)的設計天生就擅長這種并行計算,其速度比CPU快幾十甚至上百倍。對于任何稍具規模的模型,使用GPU訓練都是必須的,否則可能需要花費數小時甚至數天的時間。
統一設備:在PyTorch中,要進行計算,模型和數據必須在同一個設備上。我們在這里先把模型用
.to(device)放到了GPU上,之后在訓練循環中,我們還需要把每一批次的數據也放到同一個device上。
使用語法
EPOCHS = 100: 定義訓練的總輪數,即我們要把整個訓練數據集從頭到尾過多少遍。torch.cuda.is_available(): 返回True或False,判斷CUDA環境是否可用。device = torch.device(...): 創建一個設備對象。"cuda"代表GPU,"cpu"代表CPU。通過一個三元表達式,我們的代碼實現了自動選擇。model.to(device): 這是nn.Module的方法,它會將模型內部所有的參數和緩沖區都移動到指定的device上。
第四步,開始訓練
# 訓練循環
for epoch in range(EPOCHS):model.train() # 將模型設置為訓練模式epoch_loss = 0.0for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)# 1. 梯度清零optimizer.zero_grad()# 2. 前向傳播outputs = model(inputs)# 3. 計算損失loss = criterion(outputs, labels)# 4. 反向傳播loss.backward()# 5. 更新權重optimizer.step()epoch_loss += loss.item()if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{EPOCHS}], Loss: {epoch_loss/len(train_loader):.4f}')整體結構:Epoch 與 Batch 的雙重循環
整個訓練循環是一個雙層for循環:
外層循環 (
for epoch in range(EPOCHS):):遍歷世代(Epoch)。一個Epoch代表我們的模型已經完整地看過一遍所有的訓練數據。我們讓模型反復看很多遍(這里是100遍),以期它能充分學習到數據中的規律。內層循環 (
for inputs, labels in train_loader:):遍歷批次(Batch)。在每一個Epoch中,我們不是一次性處理所有數據,而是通過train_loader,一小批一小批地處理數據。
訓練循環詳解
我們來逐步分析循環內部的每一個動作:
model.train()
有什么用?:在每個Epoch開始時,調用這行代碼來明確地告訴PyTorch:“現在開始是訓練模式了!”
為什么需要它?:這是非常關鍵的一步。它會“激活”模型中只在訓練時才使用的層,比如我們之前定義的
Dropout層。反之,在評估模型時,我們會調用model.eval()來“關閉”這些層,以保證評估結果的確定性。
inputs, labels = inputs.to(device), labels.to(device)
有什么用?:將當前批次的數據(
inputs)和標簽(labels)一起發送到我們之前設定的計算設備上(cpu或cuda)。為什么需要它?:為了進行計算,模型和它要處理的數據必須位于同一個設備上。我們之前已經把
model放到了device上,所以現在也必須把每一批數據放上去。
訓練的核心五步
這五步是所有PyTorch標準訓練流程,順序幾乎是固定的。
1. optimizer.zero_grad() - 梯度清零
有什么用?:清除上一個批次計算出的所有參數的梯度。
為什么需要它?:PyTorch的梯度在反向傳播時是累加的。如果我們不清零,當前批次計算出的梯度就會被加到上一個批次的梯度上,這會導致完全錯誤的更新方向。所以,在為新的一批數據計算梯度之前,必須“清掃”一下,確保每次更新都只基于當前批次的數據。
2. outputs = model(inputs) - 前向傳播
有什么用?:將輸入數據
inputs喂給模型,得到模型的預測輸出outputs(也就是logits)。為什么需要它?:這是模型進行“預測”的過程。數據按照我們在
forward方法中定義的路徑,在網絡中走了一遍,得出了一個初步的答案。
3. loss = criterion(outputs, labels) - 計算損失
有什么用?:用我們定義的損失函數
criterion,來比較模型的預測outputs和真實標簽labels之間的差距。為什么需要它?:這是為了量化模型“錯得有多離譜”。得到的
loss是一個單獨的數值,這個數值就是我們接下來要努力減小的目標。
4. loss.backward() - 反向傳播
有什么用?:PyTorch的
autograd(自動微分)引擎會根據loss,自動計算出模型中每一個可學習參數(權重和偏置)的梯度。為什么需要它?:梯度指明了能讓損失函數值上升最快的方向。因此,梯度的反方向就是我們調整參數、降低損失的最佳方向。這一步就是為了找到這個“方向圖”。
5. optimizer.step() - 更新權重
有什么用?:命令我們的優化器
optimizer,根據上一步計算出的梯度,來更新模型的所有參數。為什么需要它?:這是真正發生“學習”的一步。
loss.backward()只負責計算方向,optimizer.step()則負責真正地朝著這個正確的方向“邁出一步”,對模型的權重進行微調。
epoch_loss += loss.item()
有什么用?:
loss本身是一個帶計算圖的張量。.item()方法可以從中提取出純粹的Python數字。我們把每個batch的loss累加起來,是為了計算整個epoch的平均loss。為什么需要它?:這是為了監控訓練過程。通過觀察每個epoch的平均loss是否在穩步下降,我們就能判斷模型是否在有效地學習。
print(f'Epoch ...')
有什么用?:每隔10個epoch,打印一次當前的epoch數和這個epoch的平均損失。
為什么需要它?:這里的
epoch_loss/len(train_loader)就是用總損失除以總批次數,得到平均損失。

第五步,評估模型并且生成測試結果文件
X_np1 = test_processed_df.to_numpy(dtype=np.float32) # 強制指定float32
X_test_tensor = torch.from_numpy(X_np1) # NumPy->PyTorch自動類型匹配# 1. 進行預測
model.eval() # 將模型設置為評估模式,這會禁用Dropout
with torch.no_grad(): # 在這個代碼塊中,不計算梯度,以節省計算資源X_test_tensor = X_test_tensor.to(device)test_outputs = model(X_test_tensor)# test_outputs是logits,需要通過sigmoid轉換為概率test_probs = torch.sigmoid(test_outputs).cpu()# 根據概率(閾值為0.5)轉換為0或1的預測結果test_preds = (test_probs > 0.5).int().squeeze()# 2. 創建提交文件
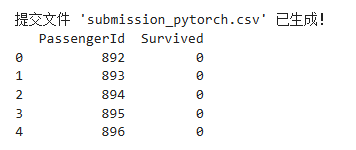
submission_df = pd.DataFrame({'PassengerId': test_passenger_ids,'Survived': test_preds.numpy()
})submission_df.to_csv('submission_pytorch.csv', index=False)print("\n提交文件 'submission_pytorch.csv' 已生成!")
print(submission_df.head())X_np1 = test_processed_df.to_numpy(dtype=np.float32) ?# 強制指定float32
X_test_tensor = torch.from_numpy(X_np1) ?# NumPy->PyTorch自動類型匹配
將我們預處理好的測試集特征test_processed_df,轉換成PyTorch模型能夠接收的Tensor格式。
進行預測(模型推理 )
這一部分是模型應用的核心,包含了幾個非常關鍵的步驟。
model.eval()
有什么用?:將模型切換到評估模式。
為什么需要它?:這是
model.train()的對應操作,至關重要。在評估模式下,PyTorch會自動關閉Dropout層(因為預測時我們希望使用整個網絡的能力,而不是隨機丟棄神經元)和BatchNorm層(如果模型中有的話)。這能保證我們的預測結果是確定性的、可復現的。
with torch.no_grad():
有什么用?:創建一個上下文管理器,臨時關閉所有梯度的計算。
為什么需要它?:在預測階段,我們只是單純地讓數據通過模型得到結果,完全不需要計算梯度(梯度是訓練時用來更新權重的)。關閉梯度計算可以帶來兩大好處:
節省內存:不需要為反向傳播保存中間狀態。
加快速度:跳過了梯度計算的開銷,讓前向傳播更快。
這是所有模型推理代碼的標準優化操作。
預測流程詳解
1.X_test_tensor.to(device): 將測試數據張量也放到與模型相同的設備上。
2.test_outputs = model(X_test_tensor): 進行預測。將測試數據喂給模型,得到模型的原始輸出(logits)。
3.test_probs = torch.sigmoid(test_outputs).cpu(): 轉換成概率。
torch.sigmoid(...): 模型的輸出是logits,為了將其解釋為“生還的概率”(一個0到1之間的數),我們必須用sigmoid函數對其進行激活。.cpu(): 模型的計算可能在GPU上完成,得到的test_outputs也在GPU上。為了方便后續使用NumPy或Pandas處理,我們通常會用.cpu()方法將結果數據拷回CPU內存。
4.test_preds = (test_probs > 0.5).int().squeeze(): 得出最終類別。
(test_probs > 0.5): 以0.5為閾值,將概率轉換為布爾值(True/False)。概率大于0.5的被認為是True(預測為生還)。.int(): 將布爾值True/False轉換為整數1/0,得到我們最終的預測類別。.squeeze(): 此時張量的形狀是[樣本數, 1],.squeeze()會移除所有大小為1的維度,將其變成[樣本數],這更方便我們后續創建DataFrame。
submission_df = pd.DataFrame
({ 'PassengerId': test_passenger_ids, 'Survived': test_preds.numpy() })
submission_df.to_csv('submission_pytorch.csv', index=False)
有什么用?:將我們的預測結果與乘客ID配對,生成一個符合Kaggle等競賽平臺要求的CSV文件。
為什么需要它?:這是將我們的模型成果轉化為最終交付物的步驟。
使用語法:
pd.DataFrame({...}): 用一個字典來創建一個Pandas DataFrame。字典的鍵成為列名。'PassengerId': test_passenger_ids: 還記得我們最開始就保存下來的測試集乘客ID嗎?現在它派上了用場,確保每個預測結果都能和正確的乘客對應上。'Survived': test_preds.numpy(): 為了將PyTorch張量放入DataFrame,需要先用.numpy()方法將其轉換回NumPy數組。.to_csv('...', index=False): 將DataFrame保存為CSV文件。index=False是一個非常重要的參數,它告訴Pandas不要將DataFrame自身的行索引(0, 1, 2...)寫入到文件中,避免提交格式錯誤。
最后,關于提高準確率
以上就是我們的整個競賽流程,但是如果安裝標準流程,實際上準確率并不夠高,接下來我從幾個方向幫助大家后續提高準確率
1. 特征工程?
對于像泰坦尼克號這樣的表格類數據問題,特征工程往往是提升模型表現最有效的方法。我們的模型能學到的上限,很大程度上取決于我們喂給它的數據質量。
創造更有信息的特征:創建FamilySize (家庭大小): SibSp (兄弟姐妹/配偶數) + Parch (父母/子女數) + 1 (自己) = FamilySize。家庭大小可能和生還率有關(例如,獨自一人 vs. 小家庭 vs. 大家庭)。
2. 模型結構?
增加或減少層的深度和寬度:
更寬: 可以嘗試增加每層神經元的數量,比如 128 -> 64。
更深: 可以再增加一個隱藏層,比如 128 -> 64 -> 32。
注意: 更大更深的網絡不一定更好,它會增加過擬合的風險,需要更強的正則化手段來配合。
使用批量歸一化:
在全連接層之后、激活函數之前加入nn.BatchNorm1d層。可以加速模型收斂,穩定訓練過程,并在一定程度上起到正則化作用。
修改后的forward可能像這樣: x = self.batchnorm1(F.relu(self.fc1(x)))。
3. 訓練過程
調整超參數 :
學習率 :
0.001是一個很好的起點,但可以嘗試更小(如0.0005)或更大(如0.005)的值。優化器 (Optimizer):
Adam很棒,但也可以試試AdamW(Adam的改進版,帶有權重衰減)或者RMSprop。訓練輪數 (Epochs): 訓練更多輪可能會有提升,但要小心過擬合。
使用學習率調度器 :
在訓練過程中動態地調整學習率,通常是逐漸降低。比如,使用
torch.optim.lr_scheduler.ReduceLROnPlateau,當模型性能在幾輪內沒有提升時自動降低學習率。這在訓練后期非常有幫助。
4. 更高級的策略
交叉驗證 (Cross-Validation):
之前的做法只是簡單地將原始訓練集用于訓練。更可靠的做法是使用K折交叉驗證。
例如,進行5折交叉驗證:將訓練集分成5份,輪流用其中4份進行訓練,剩下1份用于驗證。這樣我們就訓練了5個模型。最終提交時,可以用這5個模型對測試集預測結果的平均值或投票,這通常會比單一模型的結果要穩定和準確得多。
模型集成 (Ensembling):
不要只依賴一個神經網絡。可以訓練幾個不同結構的模型,或者完全不同類型的模型(比如經典的梯度提升樹XGBoost, LightGBM,或隨機森林),然后將它們的預測結果融合起來。模型集成是競賽中刷榜常用方式。
)



架構中,SoC(系統級芯片)與FPGA(現場可編程門陣列)之間的數據交互)
DFS)










)


)