GraphRAG 入門教程:從原理到實戰

1. 什么是 GraphRAG?
GraphRAG 是一種結構化的、分層的檢索增強生成(Retrieval-Augmented Generation,簡稱 RAG)方法
- 和傳統的 RAG 不同,GraphRAG 不僅僅依賴文本相似度搜索,而是先把文本轉成 知識圖譜(-Knowledge Graph),再基于圖譜結構來檢索和生成答案。
- 【回答質量高,但 token 消耗大、生成時間久,所以使用代價較高,個人部署不建議 ~~~ 】
簡單來說:
- 傳統 RAG:找到和問題最像的文本片段 → 直接生成答案。
- GraphRAG:先提取實體和關系 → 構建知識圖譜 → 檢索更精準的信息 → 生成更豐富的答案。
這樣做的好處是:
- 更好地處理跨文檔、多跳推理的問題。
- 能發現信息之間的隱含聯系,而不僅是關鍵詞匹配。
2. GraphRAG 原理
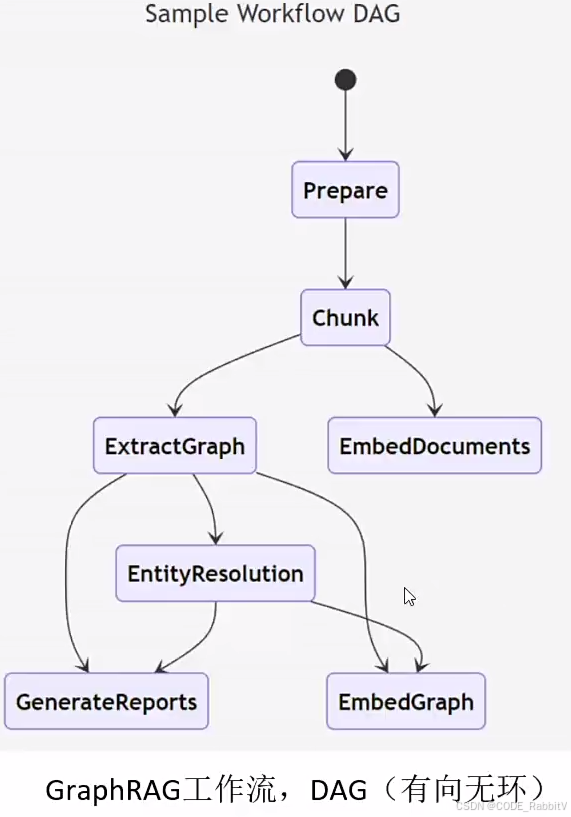
GraphRAG 核心思想:
- 從原始文本中提取知識圖譜
- 節點(實體)+ 邊(關系)
- 構建社區層級(Community Levels)
- 發現信息的群體結構,比如哪些實體屬于同一主題、組織或地理位置。
- 為這些社區生成摘要
- 讓模型理解某個社區的整體背景。
- 結合 RAG 任務執行問答
- 通過圖譜檢索找到最相關的信息,再生成答案。
類比一下:傳統 RAG 是“在書里找幾段相關的句子”,GraphRAG 是“先畫一張信息關系圖,再從圖上找到最優路徑來回答問題”。
3. GraphRAG 的流程
GraphRAG 的整體流程可以分為兩大部分:索引階段 和 查詢階段。
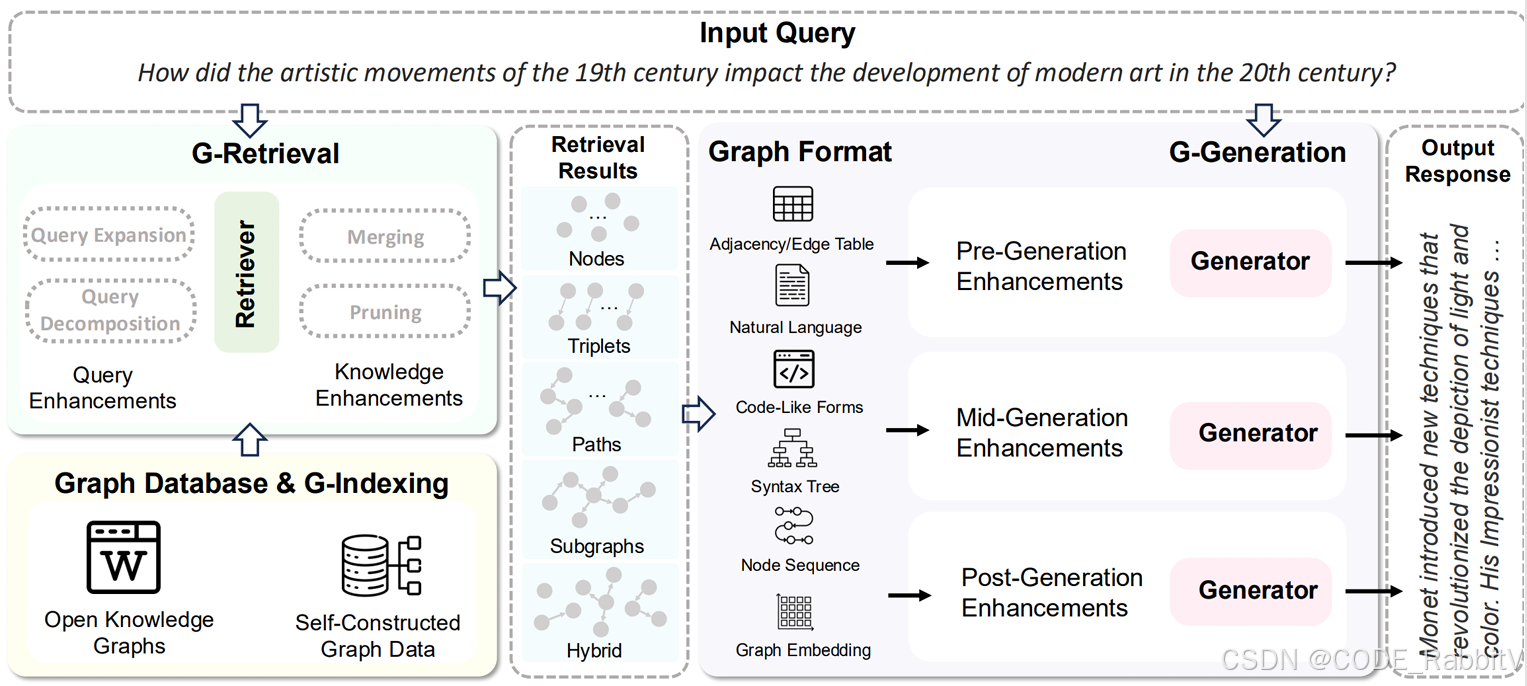
3.1 索引階段(Indexing)
- 切分文本: 把大文本庫切成可處理的小單元(TextUnits)。
- 提取實體、關系和關鍵聲明:用 LLM 從文本中抽取人物、地點、事件等實體及它們之間的關系。
- 構建知識圖譜:節點是實體,邊是關系。
- 社區檢測與聚類:用 Leiden 等算法將圖譜分成若干社區。
- 生成社區摘要:用 LLM 總結社區關鍵信息。
- 存儲到圖數據庫:方便后續高效檢索。
3.2 查詢階段(Querying)
- 解析用戶問題:分解查詢、識別涉及的實體。
- 全局檢索:從社區摘要中獲取整體背景。
- 局部檢索:深入鄰居節點和相關關系,獲取細節。
- 生成答案:將檢索結果交給 LLM,生成自然語言回答。
4. 示例對比
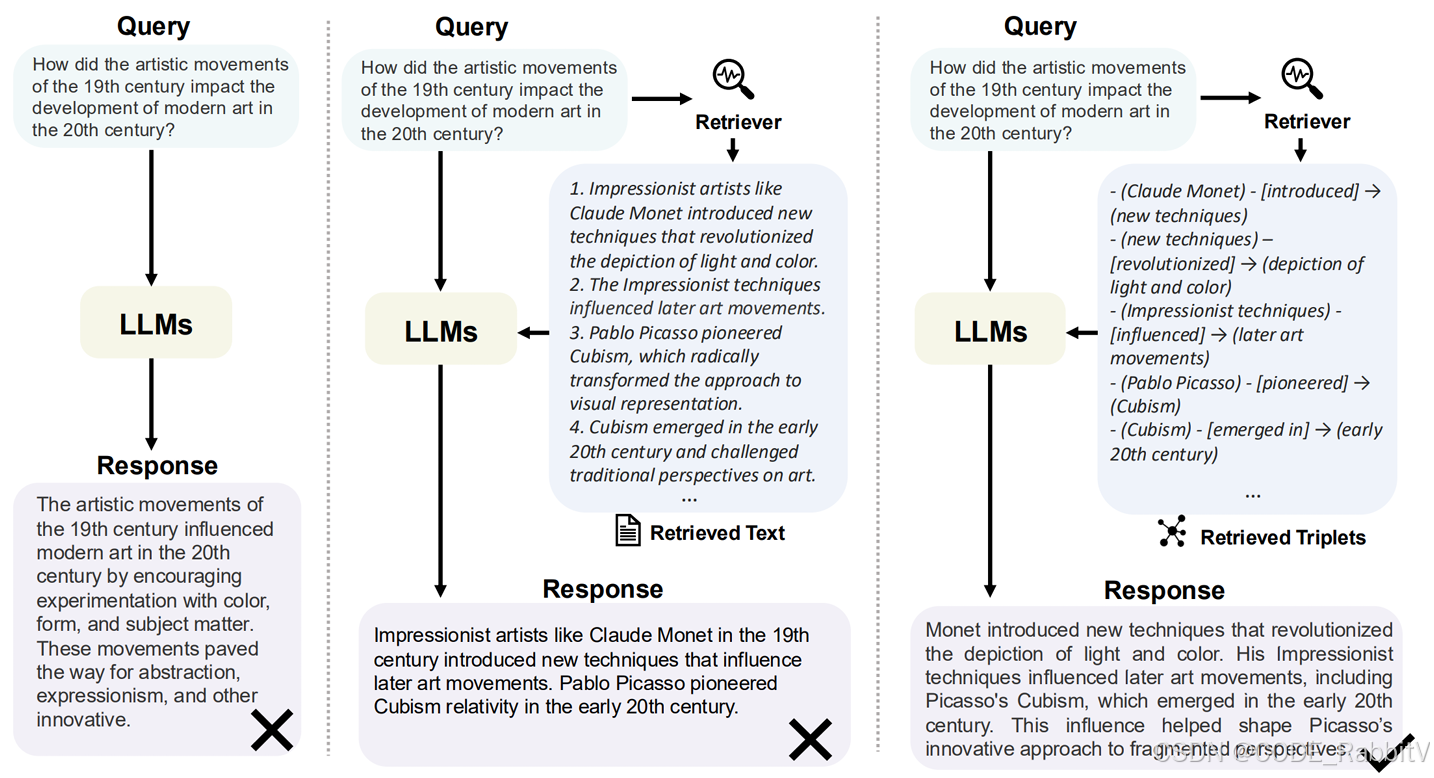
假設問題是:
“Query:19世紀的藝術運動是如何影響20世紀現代藝術的發展的?”
-
傳統 LLM 直接回答:
“19 世紀的藝術運動通過鼓勵對色彩、形式和主題的實驗,影響了 20 世紀的現代藝術……”
籠統,沒有細節鏈路!
-
普通 RAG 回答(檢索文本片段):
檢索:1. 像克勞德·莫奈這樣的印象派藝術家引入了新技術,徹底改變了對光和顏色的描繪。2. 印象派的技法影響了后來的 …
回答:莫奈引入新技術,改變了光和色彩的描繪;印象派影響了后來的藝術運動;畢加索開創立體主義……回答依舊可能割裂!
-
GraphRAG 回答(基于知識圖譜):
檢索:(莫奈)- [引進] →(新技術)- [革新] →(光和顏色的描繪)…
回答:“莫奈引入的新技術徹底改變了光和色彩的描繪,他的印象派技巧影響了后來的藝術運動,包括 20 世紀初出現的畢加索立體主義。這種影響幫助塑造了畢加索對碎片化視角的創新方法。”優勢:
- 有因果鏈條(莫奈 → 新技術 → 印象派 → 立體主義)
- 信息更連貫
5. 實戰:如何跑 GraphRAG
官方代碼地址:https://github.com/microsoft/graphrag
Step 1. 克隆代碼
git clone https://github.com/microsoft/graphrag.git
cd graphrag
Step 2. 安裝依賴、初始化 & 配置
pip install poetry
poetry install
poetry run poe index --init--root .
- 正確運行后,此處會在 graphrag 目錄下生成 output、prompts、.env、settings.yaml 文件
- 之后需要對 .env 文件配置 GRAPHRAG_API_KEY、修改 settings.yaml 設置 model
Step 3. 準備數據,放到 ./input 目錄下
- 準備一個包含多篇文檔的文本數據集(比如企業內部報告)
- 格式可以是
.txt/.csv/.json
Step 4. 構建索引 (文本越長越久)
python -m graphrag.index --init
之后會看到類似如下的一些生成信息:
create_base_text_units
...create base_extracted_entities
...create_summarized_entities
...create_base_entity_graph
...create_final_entity
...create_final_communities
...
...
...All workflows completed successfully.
- 正確運行后,會在 ./cache 文件夾下面生成4個文件夾,方便后續進行提問

Step 5. 運行查詢
python -m graphrag.query--root ./cases --method global "你的問題" ## global 模式
local答案生成(代價高):針對具體問題,GraphRAG通過結合元素和元素摘要生成初步答案,這些答案來源于GraphRAG中的特定社區;global答案生成 (代價非常高):對于需要涵蓋整個數據集的全局性問題,GraphRAG采用Map-Reduce機制,將所有社區的初步答案組合起來。
6. 適用場景
GraphRAG 特別適合:
- 跨文檔問答:多個文檔中信息關聯的問題。
- 多跳推理:需要從多個實體關系鏈推理出答案。
- 知識管理:企業內部知識庫、科研資料等。
- 長文本總結:社區層級摘要可以提煉核心脈絡。
7. 總結
GraphRAG 讓 RAG 不再是“找最像的文本”,而是“基于關系圖譜推理回答”。
它的關鍵價值在于:
- 結構化信息 → 讓知識更可檢索、可推理。
- 分層摘要 → 快速獲得全局視野與細節。
- 更適合復雜、跨域的問題。
如果你平時做的問答任務經常遇到:
- 回答內容碎片化、不連貫
- 模型找不到跨文檔的關鍵信息
那 GraphRAG 值得你嘗試。


架構中,SoC(系統級芯片)與FPGA(現場可編程門陣列)之間的數據交互)
DFS)










)


)

![[激光原理與應用-181]:測量儀器 - 頻譜型 - 干涉儀,OCT(光學相干斷層掃描技術)](http://pic.xiahunao.cn/[激光原理與應用-181]:測量儀器 - 頻譜型 - 干涉儀,OCT(光學相干斷層掃描技術))