AI:新書預告—從機器學習避坑指南(分類/回歸/聚類/可解釋性)到大語言模型落地手記(RAG/Agent/MCP),一場耗時5+3年的技術沉淀—“代碼可跑,經驗可抄”—【一個處女座的程序猿】攜兩本AI實戰書終于正式來了!
導讀:大家好!今天2025年7月,我是「一個處女座的程序猿」博主,本人的兩本新書《數據驅動:機器學習實戰之道》和《語言之舞:大語言模型代碼實戰與部署應用》終于要在2025年的這個夏天,與大家見面了!
過去幾年,有很多網友在博客評論區問博主的那些問題:“特征工程怎么避免過擬合?”“大模型怎么部署才不崩?”“有沒有能直接用的代碼模板?”——博主沒有忘。這5年,博主把答案從博客搬進了書稿,從碎片整理成體系,現在終于能給出一份更完整的答卷了。
說實話,這兩本書,是博主分別用心打磨了 5 年與 3 年的成果——從無數個不眠之夜、數百次論文、教材、代碼倉庫的研讀與實踐,到無數次實戰項目的反復測試,尤其是第二本大模型的書籍,博主與倪靜教授多次進行修改和迭代,終于要在這個夏天與大家見面。接下來,博主作為代表,將帶大家一起扒一扒這兩本書的來龍去脈。
5年磨一劍,3年鑄一舞,兩本AI實戰新書重磅來襲!雙書預售在即,愿與君共赴這場代碼與智慧的共舞!
目錄
相關文章
LLMs:LLM一天,人間一年—2024年度大模型技術三+四大趨勢梳理(數據/算法/算力+RAG/Agent/Text2SQQL/混合部署)與2025年大模型技術趨勢(強大推理/多模態)展望和探討
一、寫書背景
1.1、為什么寫這兩本書?——“淋過雨,所以想撐傘”
1.2、書里有什么不一樣的干貨?——“不說正確的廢話,只給能跑的代碼”
1.2.1、《數據驅動:機器學習實戰之道》—— 讓數據科學從實驗室走向生產線
1.2.2、《語言之舞:大語言模型代碼實戰與部署應用》—— 手把手帶你把LLM“接進”業務系統
1.3、博主是怎么“死磕”這兩本書的?
1.4、關于作者:一位“卷王”式的技術博主
二、新書內容速覽:理論+實戰+前沿,直擊AI學習痛點
2.1、第1本:《數據驅動:機器學習實戰之道》——五年沉淀的工程化指南
2.1.1、寫在前面:側重機器學習實戰,耗時5年,原稿70萬字,出稿預估35萬字
2.1.2、核心特色
2.1.3、內容架構
2.2、第2本:《語言之舞:大語言模型代碼實戰與部署應用》——三年追趕技術閃電
2.2.1、寫在前面
2.2.2、核心特色
2.2.3、內容架構
三、新書上市 & 讀者專屬福利
3.1、成書背后:博主的“偏執”與誠意
3.2、購書指引 & 讀者專屬福利
四、結尾
4.1、感悟
4.2、后記
推薦歷年還不錯的總結系列文章
LLMs:LLM一天,人間一年—2024年度大模型技術三+四大趨勢梳理(數據/算法/算力+RAG/Agent/Text2SQQL/混合部署)與2025年大模型技術趨勢(強大推理/多模態)展望和探討
LLMs:LLM一天,人間一年—2024年度大模型技術三+四大趨勢梳理(數據/算法/算力+RAG/Agent/Text2SQQL/混合部署)與2025年大模型技術趨勢(強大推理/多模態)展望和探討_大模型推理成本趨勢 圖-CSDN博客
AGI:走向通用人工智能的【哲學】之現實世界的虛擬與真實——帶你回看1998年的經典影片《The Truman Show》感悟“什么是真實”
AGI:走向通用人工智能的【哲學】之現實世界的虛擬與真實——帶你回看1998年的經典影片《The Truman Show》感悟“什么是真實”_the truman show對真實的理解-CSDN博客
DayDayUp:2020,再見了,不平凡的一年,讓我懂得了珍惜,讓我明白了越努力越幸運
DayDayUp:2020,再見了,不平凡的一年,讓我懂得了珍惜,讓我明白了越努力越幸運_因為相信所以看見 春茗聚會通知-CSDN博客
DayDayUp:2021,再見了,無論是躺平還是內卷—愿大家改變不可接受的,接受不可改變的—心若有向往,何懼道阻且長
DayDayUp:2021,再見了,無論是躺平還是內卷—愿大家改變不可接受的,接受不可改變的—心若有向往,何懼道阻且長_keep loving keep living什么意思-CSDN博客
DayDayUp:7月25日,如何打造技術品牌影響力?頂級大咖獨家傳授—阿里云乘風者計劃專家博主&CSDN TOP1“一個處女座程序猿”《我是如何通過寫作成為百萬粉絲博主的?》演講全文回顧
DayDayUp:7月25日,如何打造技術品牌影響力?頂級大咖獨家傳授—阿里云乘風者計劃專家博主&CSDN TOP1“一個處女座程序猿”《我是如何通過寫作成為百萬粉絲博主的?》演講全文回顧-CSDN博客
成為頂級博主的秘訣是什么?《乘風者周刊》專訪“處女座程序猿”牛亞運
成為頂級博主的秘訣是什么?《乘風者周刊》專訪“處女座程序猿”牛亞運-阿里云開發者社區
一、寫書背景
1.1、為什么寫這兩本書?——“淋過雨,所以想撐傘”
博主至今清楚記得2019年寫第一篇機器學習實戰筆記時,自己還在實驗室熬夜調參。那時踩過的坑、繞過的彎路,后來都成了博客里“避坑指南”的素材。但后臺留言讓博主意識到:知識需要系統沉淀,經驗需要可復現的載體。于是:
● 《數據驅動》寫了5年:從70萬字初稿刪減到388頁精要,聚焦 “工業級ML流水線”,涵蓋數據清洗→特征工程→模型監控全鏈條,尤其強化了生產環境中最棘手的 “數據漂移預警”和“內存優化”實戰方案;
● 《語言之舞》磨了3年:博主和倪靜教授,從GPT-3追到Llama-4、Qwe系列,反復重寫3章架構解析,只為把Transformer、RAG、Agent等前沿技術,拆解成可運行的代碼塊。書中還附贈 企業級LLM落地清單,直擊中小團隊算力瓶頸痛點。
有位讀者曾問我:“你圖什么?”
我圖后來者少熬點夜——這是真心話。
從 2019年開始構思第一本書稿,到現在它的原稿已近 70 萬字;第二本也有 68 萬字原始積累。
回望過去,這些年博主在 AI 領域跑了很多項目,補過無數個坑,也在社區做了大量分享。每當讀者問到“如何下手”、“為什么出錯”,博主都希望有一本結合理論與實戰的手冊,可以幫助大家少走彎路。
1.2、書里有什么不一樣的干貨?——“不說正確的廢話,只給能跑的代碼”
1.2.1、《數據驅動:機器學習實戰之道》—— 讓數據科學從實驗室走向生產線
● 獨創“特征三化”框架:用歸一化+編碼化+向量化解決臟數據,配套金融/醫療場景案例;
● 模型調優避坑指南:L1/L2正則化效果可視化作圖 + 過擬合修復代碼模板(附內存壓縮技巧);
● 部署監控實戰:基于A/B測試的模型發布策略 + 生產環境漂移檢測工具鏈。
● 出版社編輯笑稱這是“處女座式排版”——388頁塞進35個可復用代碼模塊,幾乎每章都附上完整代碼和數據鏈接,力求代碼可跑,大家拿去運行就對了。
1.2.2、《語言之舞:大語言模型代碼實戰與部署應用》—— 手把手帶你把LLM“接進”業務系統
● 主流模型全解析:LLaMA-3、GLM-4、Qwen-2架構對比 + 微調實戰(含成本對比表)10;
● 企業級落地指南:從Docker分布式部署到提示工程框架庫,降低80%試錯成本;
● 前沿技術深度解耦:RAG增強檢索、Agent任務編排、模型監控協議——附可修改的Python套件。
● 書中藏了個彩蛋:第5章案例代碼頁腳寫著 “此處代碼在凌晨3點調試通過,建議讀者白天運行,以免懷疑人生”。
1.3、博主是怎么“死磕”這兩本書的?
● 追論文追到怕:5年機器學習稿迭代100+版,3年大模型書啃完300+篇論文;
● 刪稿比寫稿痛:138萬字原稿濃縮到73萬出版稿,刪掉冗余理論,保留90%實戰案例;
● 你們的留言救了這本書:30%案例源自博客評論區高頻問題——比如“模型上線即崩”的解決方案,就來自某位算法專家的踩坑經歷。
1.4、關于作者:一位“卷王”式的技術博主
昵稱:一個處女座的程序猿
>> 過往履歷:人工智能碩學歷,6項發明專利+9項軟著主導者,國家級/省市級等算法競賽累計十多項獲獎(含5項一等獎),以及SCI國際期刊論文;
>> 社區影響:CSDN歷史貢獻總榜常年位居第一,CSDN十大博客之星三連冠,達摩院評測官,以及CSDN/阿里/掘金/51CTO/知乎/華為/Google等社區專家博主等十余項頭銜,截止到2023年底,全網粉絲超100萬(目前全網應該已超200萬),文章閱讀量破4000萬(目前全網應該已超8000萬);
>> 寫作歷程:
● 耗時多年:第一本《數據驅動:機器學習實戰之道》(5年) + 第二本《語言之舞:大語言模型代碼實戰與部署應用》(3年);
● 字數爆炸:原稿合計138萬字,精煉后仍超70萬字;
● 熬夜無數:凌晨三點修改代碼示例、通宵對比模型架構已成日常;
● 知識儲備:查閱上百篇arxiv論文、跑通幾十個開源模型、踩遍數百個技術坑;
>> 渡人初心:從“填坑筆記”起步,因一句“自己淋過雨,總想替人撐傘”被粉絲稱為技術圈“救火隊長”。
>> 幕后花絮:為了打磨這兩部用心“作品”,真的是熬了無數次夜,查閱相關論文書籍太多了,本人很低調,但這的確是看了無數的論文與書籍帶來的收獲,同樣地,也經歷了數百次實戰調優與代碼重構。
一句話總結:“我不只是寫書,更像是把5+3年技術生涯濃縮成了兩本‘通關秘籍’。”










二、新書內容速覽:理論+實戰+前沿,直擊AI學習痛點
2.1、第1本:《數據驅動:機器學習實戰之道》——五年沉淀的工程化指南

2.1.1、寫在前面:側重機器學習實戰,耗時5年,原稿70萬字,出稿預估35萬字
博主把它當作“我與讀者一起構建數據科學管道”的全流程指南:從數據采集、清洗、可視化,到模型訓練、發布及監控,每一步都有我親測的 `.py` 示例,確保你跑得通、改得動。
2.1.2、核心特色
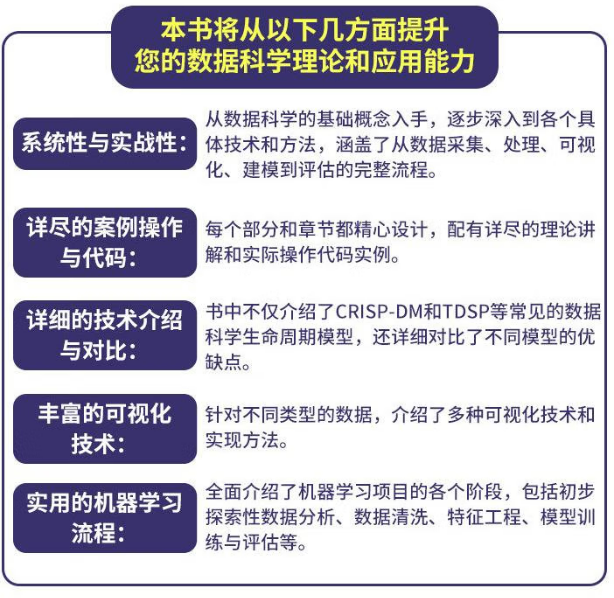
>> 關鍵詞:從零到精通 | 代碼即答案 | 案例覆蓋全
>> 核心定位:從數據到模型的全流程工業化落地,拒絕“紙上煉丹”!
● 0基礎友好:從數據可視化到模型部署,每個步驟都有“傻瓜式”代碼和注釋。
● 知行合一:每章既有理論框架,也有完整可跑通的實戰案例,直擊行業需求。
● 全景視角:覆蓋 CRISP?DM、TDSP、EDA、特征三化、模型調優到 A/B 測試與生產監控,一條流水線跑到底。
● 易學易用:統一的代碼風格+詳盡注釋,讓“小白”也能快速上手。
● 前沿兼容:最新的訓練方法、部署工具與優化策略,一次性學到最前沿。
>> 模塊化實戰設計:
● 數據層:獨創“特征三化”(歸一化/編碼化/向量化)處理臟數據;原始數據→清洗→可視化(直方圖、熱力圖、動態交互圖);
● 模型層:從線性回歸到 XGBoost 的超參調優與過擬合修復策略;過擬合解決方案對比(L1/L2正則化可視化+代碼優化內存壓縮術);
● 運維層:模型監控工具鏈實戰,基于 REST API 的模型發布、A/B 測試和“數據漂移”預警;
● 案例工具箱:388頁濃縮70萬字原稿,配套30+可復用代碼模板(覆蓋金融/醫療場景)。
>> 特別彩蛋:
● 附贈代碼包:掃碼獲取書中所有代碼,復現案例無壓力。
● 作者親測:每章案例均在本地GPU和云服務器上跑通,確保“可復制”。
Github地址:https://github.com/monkeyongithub/ml-book-code
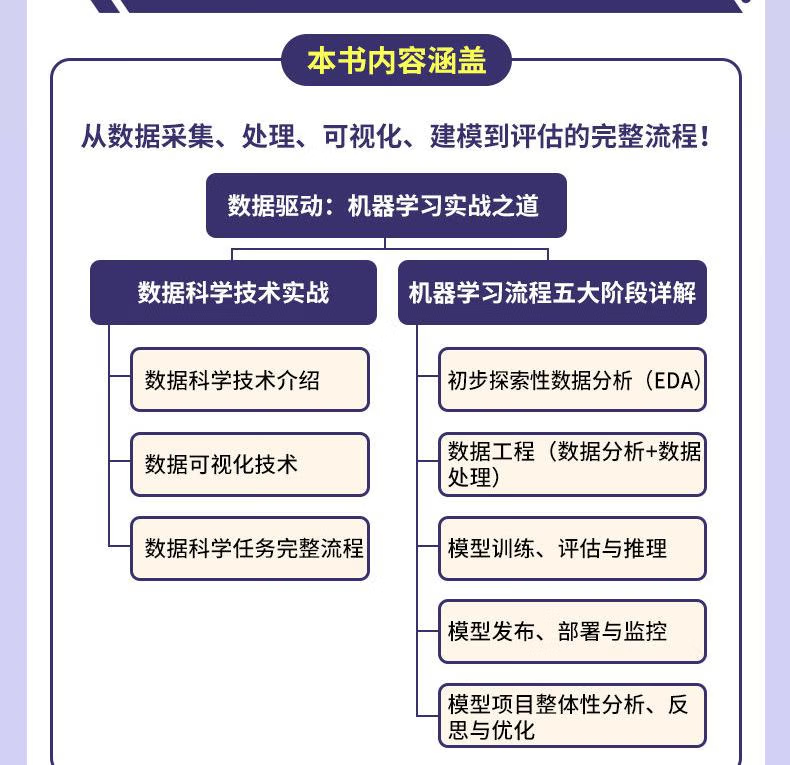
2.1.3、內容架構
《數據驅動》:機器學習的“全棧手冊”
>> 第一部分:數據科學基礎:數據科學技術實戰,涉及數據科學生命周期、可視化技術、完整項目流程
● 數據生命周期管理(CRISP-DM vs TDSP)
● 數據可視化:從直方圖到動態圖表的10+種實戰技巧
>> 第二部分:機器學習五大階段:涉及EDA、數據工程、模型訓練與推理、部署監控、項目優化
● EDA:用箱線圖揪出數據中的“壞蘋果”
● 數據工程:缺失值處理、特征三化(歸一化/編碼化/向量化)
● 模型訓練:從線性回歸到XGBoost的調參秘籍
● 模型部署:A/B測試、API接口設計、生產環境監控
● 項目優化:L1/L2正則化對比、數據增強策略、分布式優化
(注:內容架構,因為字數限制原因,未來會以出版社最終定稿為準,但核心章節不會有太大差異)

2.2、第2本:《語言之舞:大語言模型代碼實戰與部署應用》——三年追趕技術閃電

2.2.1、寫在前面
這本書是博主和倪靜教授對大語言模型(LLMs)領域的系統沉淀:從發展史到一線實踐,從核心技術要素到高級應用,每一章都融入了我在實際項目中打磨的經驗,以及倪靜教授多年在教學上對大模型技術的理論研究和企業合作中的案例實踐。我們把“大模型從學術到落地”的痛點一網打盡:從 Transformer 原理到 RAG、Agent,到 Docker & 分布式訓練,全流程實戰示例均由博主親自調試。
2.2.2、核心特色
>> 關鍵詞:LLM從理論到落地 | 跟大神學微調?| 前沿技術全解析
>> 核心定位:讓LLM落地從“魔法”變“手藝”!
● 理論+實戰:不僅講原理,更用實戰案例帶你跑通整個流程。
● 體系化:從 SLM → NLM → PLM → LLM 四次浪潮,一條線帶你看懂技術演進與架構迭代。
● 大模型全家桶:GPT、LLaMA、GLM、Qwen全系列實戰,模型微調、推理、部署全覆蓋,一本書跑遍主流模型。 以及RAG、Agent、MCP等高級技術實戰演練。
● 部署不迷路:Docker部署、分布式訓練、模型監控,手把手教你上線LLM。
● 工具全景:涵蓋訓練/推理框架、Docker 部署、分布式配置、提示庫推薦。
>> 前沿技術覆蓋:
● 全棧拆解:從Transformer架構到RAG、Agent增強技術,代碼復現主流模型(LLaMA/Qwen/GLM/Deep Seek);
● 部署避坑指南:Docker分布式訓練+模型監控體系,解決“上線即崩”痛點;
● 企業級適配:提示工程框架庫、微調成本優化表,直擊中小企業資源瓶頸。
● 特色章節:十大主流訓練框架橫向評測(含Hugging Face生態深度適配)。
>> 特別彩蛋:
● 作者私藏工具清單:LLM訓練框架、提示詞庫、部署工具全匯總。
● 進階版“避坑指南”:模型過擬合、資源耗盡、微調瓶頸的解決方案。
Github地址:https://github.com/monkeyongithub/llm-book-code

2.2.3、內容架構
《語言之舞》:LLM的“通關秘籍”
>> 第一部分:LLM的前世今生
● 大語言模型發展史:從SLM到LLM的四次技術浪潮
● 核心要素(數據、架構、評估與優化):Transformer架構的“靈魂畫手”級解析
>> 第二部分:構建你的第一個LLM
● 構建流程(預訓練→微調→推理):數據預處理:清洗、分詞、向量化全流程
● 微調與推理實戰:基于LLaMA-3和Qwen-2的代碼模板,部署與監控(Docker、分布式、運維)
>> 第三部分:從實驗室到生產
● 企業級項目落地:提示工程基礎,RAG實現知識庫問答、Agent自動化工作流
● 挑戰與未來展望:常用框架與提示庫,多模態LLM、模型壓縮、倫理挑戰
(注:內容架構,因為字數限制原因,未來會以出版社最終定稿為準,但核心章節不會有太大差異)

三、新書上市 & 讀者專屬福利
上市時間:2025年7月中下旬
渠道平臺:京東 / 當當 / 淘寶,電子工業出版社 & 機械工業出版社官方旗艦店 ?
在各大平臺搜索書名、關鍵詞,《數據驅動:機器學習實戰之道》或《語言之舞:大語言模型代碼實戰與部署應用》,即可預定。
博主也會在正式最近幾天,在微信公眾號、微博、知乎、CSDN 等平臺放出第一批購買鏈接和粉絲專屬優惠。
3.1、成書背后:博主的“偏執”與誠意
● 時間成本:累計5+3年寫作時長,5年機器學習稿迭代150+版,3年大模型書追更300+論文;
● 內容打磨:原稿138萬字濃縮至73萬出版稿,刪減冗余理論,保留90%代碼案例;
● 粉絲共創:書中30%案例源自博客評論區“高頻求助問題”,真正對癥下藥。
● 彩蛋預警:書中藏有作者“禿頭趕稿”的趣味注釋——“此處代碼在凌晨3點調試通過,建議讀者白天運行,以免懷疑人生”;
3.2、購書指引 & 讀者專屬福利
● 上市時間:2025年7月中下旬(京東/當當/淘寶,電子工業出版社、機械工業出版社等旗艦店);
● 早鳥福利:首周購書贈配套代碼庫+作者直播答疑門票;
● 粉絲通道:私信博主暗號“渡己渡人”,后續,將可獲贈經博主整理(目前還未結束)的《LLM調優避坑清單》電子手冊!
| 《數據驅動:機器學習實戰之道》 | T1、京東圖書(機械工業出版社旗艦店):https://item.jd.com/10156712292354.html T2、淘寶天貓圖書(機械工業出版社旗艦店):https://e.tb.cn/h.h81kfSl4jXEbkY2?tk=ylZ14cP1BJQ T3、當當平臺(當當自營店):http://product.dangdang.com/11954503932.html T4、京東圖書(當當自營店):https://item.jd.com/10162534946860.html 注意:不同店鋪價格不一樣,可能相差較大,建議前去平臺查找書名,然后查找價格最便宜的下單即可! |
| 《語言之舞:大語言模型應用實戰全書》 | T1、京東圖書(電子工業出版社官方旗艦店):https://item.jd.com/10165602994409.html T2、京東圖書(博文視點旗艦店):https://item.jd.com/10165603699289.html T3、淘寶天貓圖書(電子工業出版社旗艦店):https://e.tb.cn/h.h81Vu0tDZJcdieo?tk=cpCT4ckv65G T4、當當平臺(當當自營店):https://product.dangdang.com/29919200.html 注意:不同店鋪價格不一樣,可能相差較大,建議前去平臺查找書名,然后查找價格最便宜的下單即可! |
如果你是:
想轉行AI的職場人
在讀計算機/數據科學學生
對LLM部署和調參感興趣的開發者
那么,這兩本書就是你的“技術加速器”!
四、結尾
4.1、感悟
寫書的過程,是博主對自己知識體系的一次次打磨,也是博主與讀者共同成長的旅程。希望這兩本書,能為你點亮“實踐之路”,讓你在 AI 的世界里更自信、更高效。
預熱就到這里了,之后博主會陸續分享章節摘錄、實戰視頻、代碼倉庫等干貨,敬請關注!
4.2、后記
最后,說兩句心里話:
寫書是場苦修,但每次看到讀者說“這段代碼跑通了”“項目終于上線了”,我都覺得值了。技術會老,代碼會變,但開發者之間“不藏私”的接力傳承,永遠是這個行業最浪漫的事。
我圖的很簡單——讓你比我少熬幾個夜,少踩幾個坑。
因為自己淋過雨,所以總想替別人撐把傘。
新書不是終點,而是我們對話的新起點!
江湖路遠,代碼相見……
倒計時已啟動,請鎖定 2025年7月中下旬,和博主一起揭開這兩本“技術通關秘籍”的面紗!
最后的彩蛋:博主的第三本新書,《大語言模型驅動的智能體(LLM Agent):從理論到實戰》目前已累計58萬字,預估今年年底,也會如約將與大家見面!敬請期待!
一個處女座的程序猿
2025年7月16日凌晨

--使用CUB庫實現基本功能)

)
)

ARM體系架構)







)




