? 最近看到 Google AI 發布了一個叫?MLE-STAR(Machine Learning Engineering via Search and Targeted Refinement)的新系統,說實話,第一眼看完論文和相關介紹后,我是有點震撼的。這不只是一次簡單的“LLM + 自動化”拼湊,而是真正把機器學習工程(ML Engineering)這個復雜流程,用智能代理(agent)的方式往前推了一大步。
? 咱們平時做項目的時候都知道,一個完整的 ML pipeline 涉及數據預處理、特征工程、模型選擇、調參、集成學習,還有各種 bug 調試和數據泄露檢查。這些活兒不僅瑣碎,還特別考驗經驗。以前我們也用過一些自動化工具,比如 AutoML,或者基于 LLM 的代碼生成 agent,但總覺得“差點意思”——要么太依賴模型自己“記住”的東西,要么改代碼像“一把梭”,整個腳本重寫一遍,效率低,效果也不穩定。
? 而這次 Google Cloud 團隊推出的 MLE-STAR,我覺得是真正抓住了痛點。
它到底解決了什么問題?
? 文章里提到幾個關鍵瓶頸,我深有體會:
1.?LLM 記憶的局限性:很多 agent 寫代碼時,總是習慣性地用 scikit-learn 套個 Random Forest 或 XGBoost 就完事了。不是不好,但在某些任務上,比如圖像、音頻,明明有更先進的模型(比如 ViT、EfficientNet),但它“想不起來”或者“不敢用”。這就導致方案不夠前沿。
2.?粗粒度的迭代方式:以前的 agent 往往是“全盤重寫”——跑一次結果不好,就整個代碼重新生成一遍。這種“all-at-once”的修改,缺乏針對性,很難深入優化某個模塊,比如特征編碼方式或者歸一化策略。
3.?容易出錯,還難發現:生成的代碼經常有運行錯誤、數據泄露(比如在訓練時不小心用了 test set 的統計信息),或者干脆漏掉了某個數據文件。這些問題在真實項目中是致命的,但很多 agent 根本不檢查。
? MLE-STAR 正是在這幾個方面做了系統性的突破。
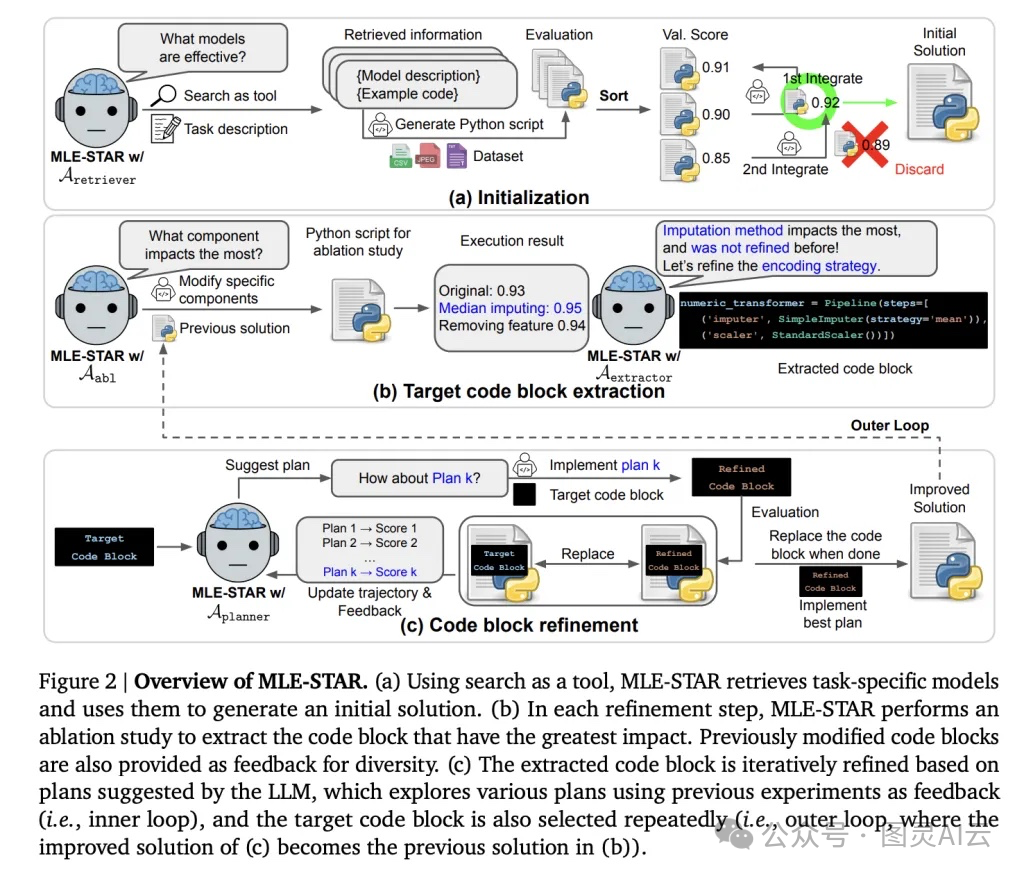
它的核心創新,我覺得可以用“搜、改、合、查”四個字來概括
1.?搜:Web Search–Guided Model Selection
? 這是讓我眼前一亮的設計。MLE-STAR 不再只靠 LLM 自己“腦補”模型,而是會主動調用?web-scale search,去檢索當前任務最相關的模型和代碼片段。比如你給它一個圖像分類任務,它會去搜最新的 model cards、Kaggle kernels、GitHub 項目,然后把 EfficientNet、ViT 這些真正 state-of-the-art 的架構納入候選。
? 這就相當于,它不是靠“背書”做題,而是開卷考試,還能查資料——你說這優勢多大?
2.?改:Nested, Targeted Code Refinement(嵌套式、針對性代碼優化)
? 這個機制特別聰明。它用了雙層循環優化:
??外層循環(Ablation-driven):它會做“消融實驗”(ablation study),自動分析當前 pipeline 中哪個模塊對性能影響最大——是數據預處理?特征工程?還是模型結構?
??內層循環(Focused Exploration):一旦鎖定關鍵模塊,它就只針對那一塊做精細化迭代。比如發現 categorical feature 的編碼方式是瓶頸,它就會嘗試 One-Hot、Target Encoding、Embedding 等多種方式,逐一測試。
? 這種“先定位,再攻堅”的策略,比盲目重寫整個腳本高效太多了,也更接近人類專家的思維方式。
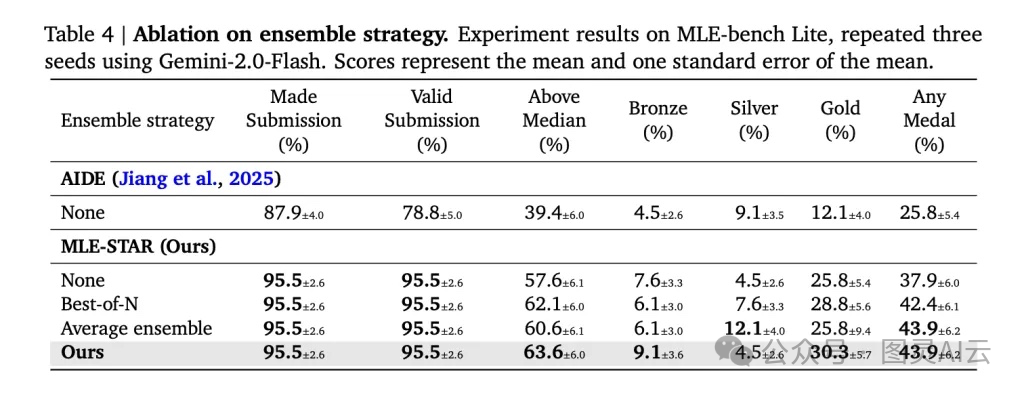
3.?合:Self-Improving Ensembling Strategy(自進化的集成策略)
? 集成學習(Ensemble)一直是 Kaggle 拿獎的利器,但大多數 agent 只會簡單地“投票”或“平均”。MLE-STAR 不一樣,它能主動設計復雜的集成方案,比如 stacking,甚至自己構建 meta-learner(元學習器),或者搜索最優權重組合。
? 更關鍵的是,它是在多個候選方案的基礎上動態組合,而不是只挑一個“最好”的。這就大大提升了魯棒性和上限。
4.?查:Robustness through Specialized Agents(專項檢查機制)
? 這一點在工程上太重要了。MLE-STAR 內置了三個“質檢員”:
??Debugging Agent:遇到 Python 報錯,它會自動修復,直到代碼能跑通,最多試幾次;
??Data Leakage Checker:專門檢查有沒有數據泄露,比如標準化時用了 test set 的均值;
??Data Usage Checker:確保所有提供的數據文件都被充分利用,避免遺漏重要信息。
? 這些檢查機制,看似“輔助”,實則是保證結果可信的關鍵。沒有它們,再好的模型也可能因為一個小 bug 而前功盡棄。
效果怎么樣?數據說話
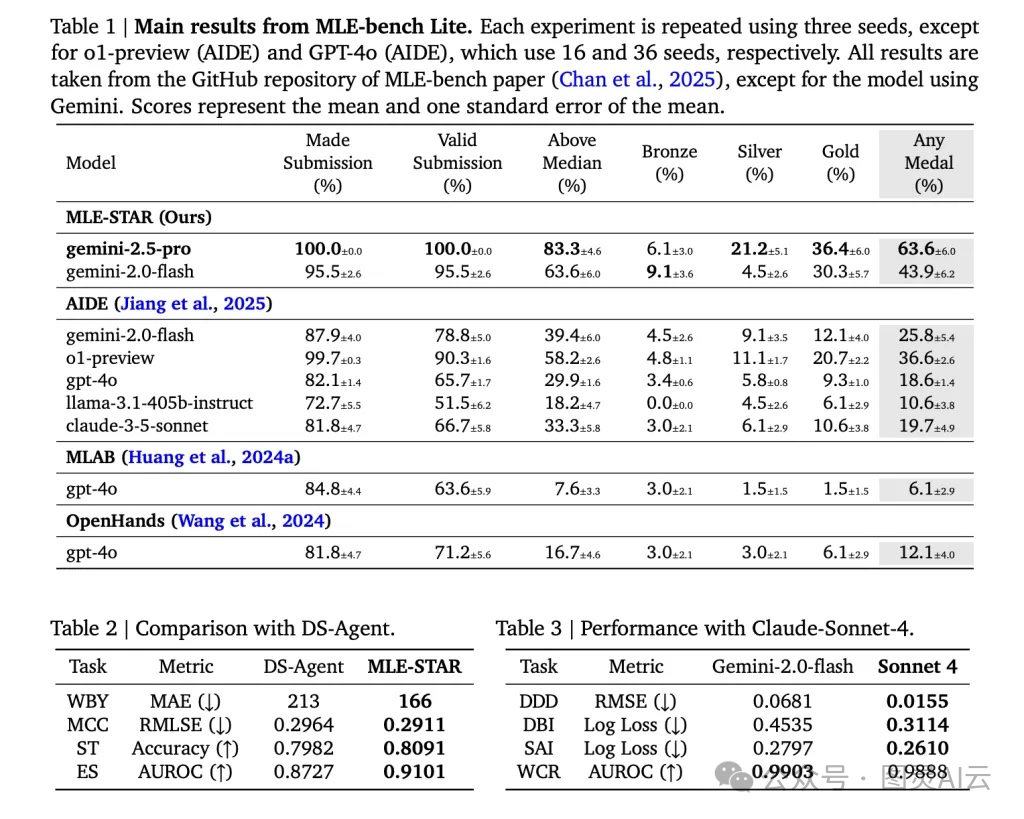
? 他們在?MLE-Bench-Lite?這個 benchmark 上做了測試,包含 22 個來自 Kaggle 的真實競賽任務,涵蓋表格、圖像、音頻、文本等多種模態。結果非常亮眼:
指標 | MLE-STAR (Gemini-2.5-Pro) | 最佳基線 AIDE |
獲獎率(Any Medal) | 63.6% | 25.8% |
金牌率(Gold Medal) | 36.4% | 12.1% |
超過中位數 | 83.3% | 39.4% |
有效提交率 | 100% | 78.8% |
? 你看,獲獎率直接翻了兩倍多,金牌率更是三倍以上。尤其是在圖像任務上,MLE-STAR 主動選擇了 ViT、EfficientNet 這些現代架構,而不是守著 ResNet 不放,說明它真的“跟上了時代”。
? 而且,它的有效提交率是 100%,意味著生成的代碼都能跑通,沒有語法錯誤或文件缺失——這對自動化系統來說,是個巨大的工程勝利。
我的一些思考
? 說實話,看到這個系統,我第一反應是:“這已經不只是工具,而是一個會學習、會反思、會協作的 ML 工程伙伴了。”
? 它不像傳統的 AutoML 那樣“黑箱”,也不像純 LLM 生成那樣“隨性”,而是建立了一套有邏輯、有反饋、有安全邊界的工作流。特別是那個“ablation-driven”的外層循環,讓我覺得它有點像人類研究員在做實驗設計——先分析瓶頸,再集中突破。
? 另外,它還支持?human-in-the-loop,比如專家可以手動注入最新的模型描述,幫助系統更快采納前沿技術。這種“人機協同”的設計,既保留了自動化效率,又不失靈活性,非常務實。
? 更讓人高興的是,Google 把這套系統基于?Agent Development Kit (ADK)?構建,并且開源了代碼和教程。這意味著我們普通研究者和工程師也能上手試用、二次開發,甚至把它集成到自己的 pipeline 中。這種開放態度,對整個社區都是好事。
總結一下
? MLE-STAR 真的代表了當前 ML 自動化的一個新高度。?它通過“搜索打底、聚焦優化、智能集成、嚴格檢查”這一整套機制,不僅提升了性能,更重要的是提升了可靠性和可解釋性。
? 如果你在做 AutoML、智能 agent、或者 MLOps 相關的工作,這個項目非常值得深入研究。我已經在 GitHub 上 star 了他們的 repo,也打算用他們的 notebook 先跑一個 demo 試試。
? 未來,也許我們不再需要從頭寫每一個 pipeline,而是和像 MLE-STAR 這樣的 agent 一起協作——它負責執行和迭代,我們負責定義問題和把控方向。這或許就是下一代機器學習工程的樣子。
詳見
1. 論文:https://www.arxiv.org/abs/2506.15692
2. 代碼:https://github.com/google/adk-samples/tree/main/python/agents/machine-learning-engineering
3. 相關文檔:https://research.google/blog/mle-star-a-state-of-the-art-machine-learning-engineering-agents/

)







Python爬蟲入門教程:從零開始學習網頁抓取(爬蟲教學)(Python教學))






到大語言模型落地手記(RAG/Agent/MCP),一場耗時5+3年的技術沉淀—“代碼可跑,經驗可抄”—【一個處女座的程序猿】攜兩本AI)

--使用CUB庫實現基本功能)
