引言
歡迎踏上這段深入了解 Apache Flink 演進歷程的旅程,Apache Flink 是一項重新定義了實時數據處理的技術。本博客文章基于王峰(阿里云開放數據平臺負責人、Apache Flink Committer)在 2025 年 Flink Forward Asia 新加坡大會上的演講內容編輯而成,深入探討了企業如何利用 Apache Flink 從傳統的實時數據分析轉向尖端的實時 AI 應用。我們將探索 Flink 十年的發展歷程、它在現代數據架構中的關鍵作用、與湖倉環境的協同效應,以及它在賦能實時 AI 智能體和應用方面的變革潛力。
01
Apache Flink 的十年發展歷程

Apache Flink 的非凡旅程始于 2009 年,當時名為 Stratosphere,是德國柏林工業大學的一個研究項目。五年后,核心團隊成立了dataArtisans 公司,并將該項目貢獻給 Apache 軟件基金會,重命名為 Flink。又過了五年,阿里巴巴收購了 dataArtisans,將其更名為 Ververica,并投入大量資源推動 Flink 成為實時數據分析中流處理的事實標準。創新仍在繼續,最近的項目包括用于實時數據集成的 Flink CDC(變更數據捕獲)和 Apache Paimon——一種源自 Flink 社區、現已成為獨立 Apache 項目的實時數據湖格式。Flink 2.0 的正式發布為社區開啟了新篇章,為下一個十年的進步奠定了基礎。
從技術角度來看,Flink 在現代數據架構和生態系統中占據著核心地位。
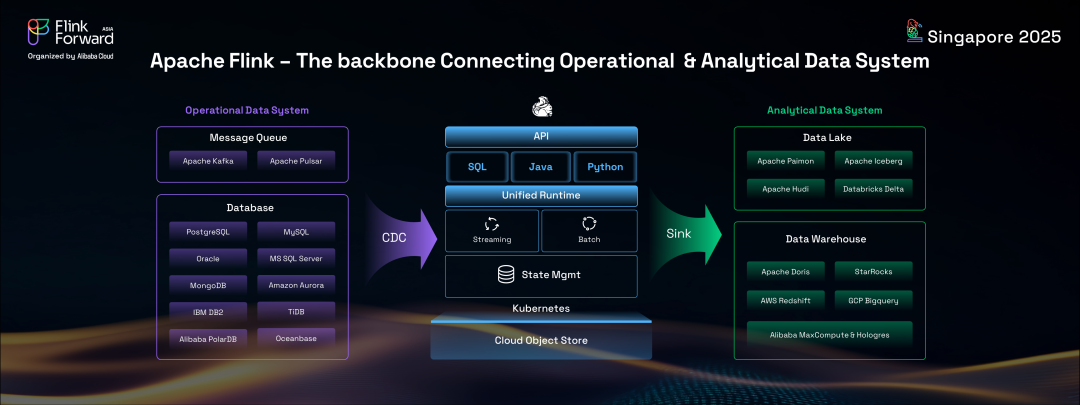
它充當著骨干,驅動實時數據流從操作系統流向分析系統。Flink 高效地從數據庫和消息隊列中捕獲各種實時事件,執行復雜的流處理,然后無縫地將結果同步到數據湖和數據倉庫。在過去十年中,Apache Flink 的架構已演進為完全云原生,簡化了開發者在云環境中的部署。因此,包括阿里云在內的大多數云供應商現在都提供 Apache Flink 的托管服務,使全球企業更容易使用該技術。
02
Apache Flink 在現代數據生態系統中的作用和湖倉集成
Apache Flink 在現代數據架構中的核心作用不容否認。它作為關鍵紐帶,實現從操作數據系統到分析系統的實時數據流。Flink 的能力擴展到從數據庫和消息隊列捕獲各種實時事件,執行復雜的流處理,然后將處理后的數據與數據湖和數據倉庫無縫同步。這種集成對于尋求從不斷演變的數據流中獲得即時洞察的企業至關重要。
數據架構中最重要的進步之一是湖倉的興起。這種新一代數據平臺結合了數據湖和數據倉庫的最佳特性,既提供了靈活性,又具備結構化數據管理能力。雖然湖倉架構上的許多工作負載仍以離線或批處理模式運行,但在湖倉環境中對實時數據分析的日益增長的需求突顯了一個關鍵需求。這正是 Apache Flink 變得不可或缺的地方。通過將Flink的流處理技術與湖倉架構集成,企業可以實現端到端的實時解決方案。
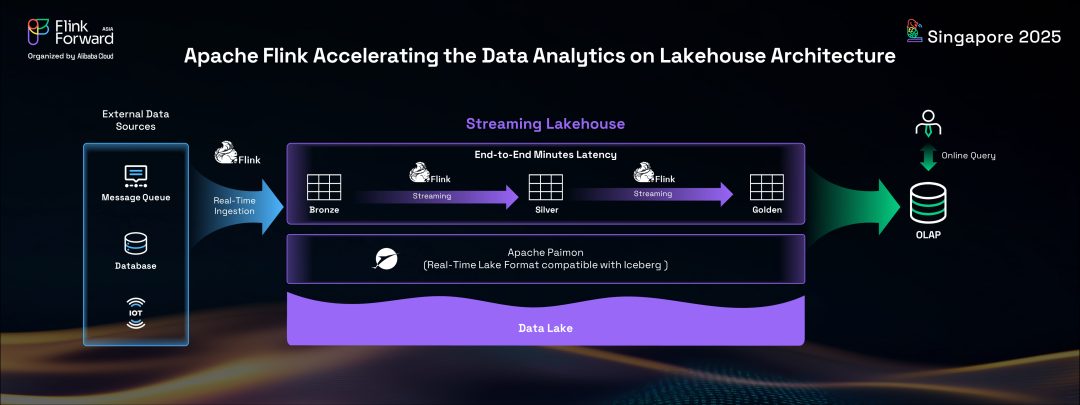
當前主流的數據湖格式 Iceberg 雖然功能強大,但由于其面向批處理的特性,并非天然為實時操作而設計。為了解決這一問題,Flink 社區在 2022 年孵化了 Apache Paimon(原名Flink Table Store)。Paimon 專門為湖倉架構中的實時數據更新而設計,是一種純粹面向流的格式。Apache Flink 和 Apache Paimon 的協同作用創造了一個新范式:流式湖倉(Streaming Lakehouse)。這種基于流技術構建的架構實現了端到端的實時數據管道,具有分鐘級的時效性,為企業提供了前所未有的敏捷性和響應能力。
03
使用 Apache Flink 釋放實時數據價值
Apache Flink 的快速增長和廣泛采用,使其成為全球流處理的事實標準,這不僅僅歸因于其優秀的技術設計和持續創新。從根本上說,Flink 釋放了實時數據的真正價值,使企業能夠顯著提高業務效率并做出實時業務決策。例如,在各個行業中,管理層和營銷團隊現在可以通過由 Apache Flink 持續更新的實時 BI 報告和儀表板做出即時業務決策。電商公司可以在 Flink 上構建實時推薦系統,向客戶推送相關產品,增加參與度和交易量。金融系統利用 Flink 進行實時欺詐檢測,展示了其在眾多用例中的多功能性。

阿里巴巴作為 Apache Flink 的主要貢獻者和最大用戶之一,提供了一個令人信服的例子,說明如何使用 Flink 及其生態系統構建實時數據平臺。自 2016 年以來,阿里巴巴一直基于 Apache Flink 構建其統一的流數據平臺,將其所有業務和數據應用從離線升級到實時分析。

這包括天貓、淘寶、全球速賣通和 Lazada 等全球電商巨頭,以及菜鳥等物流運營和在線旅游服務。在雙十一全球網購節等高峰活動期間,阿里巴巴的流數據平臺運行在數百萬個 CPU 核心上,每秒處理數十億條記錄。為了支持如此龐大的實時工作負載,阿里巴巴的流處理團隊開發了 Apache Flink 的增強版本,稱為 Flash,這是一個下一代向量化流處理引擎。該引擎與 Apache Flink 100% 兼容,但提供了顯著更快的性能,通過使用向量化模型用 C++ 重寫核心組件來實現,同時保持相同的 API 和分布式運行時框架。
為了將這種尖端流技術的好處擴展到阿里巴巴集團之外,整個流數據平臺被遷移到阿里云,提供名為實時計算(RTC)的 Apache Flink 托管服務。
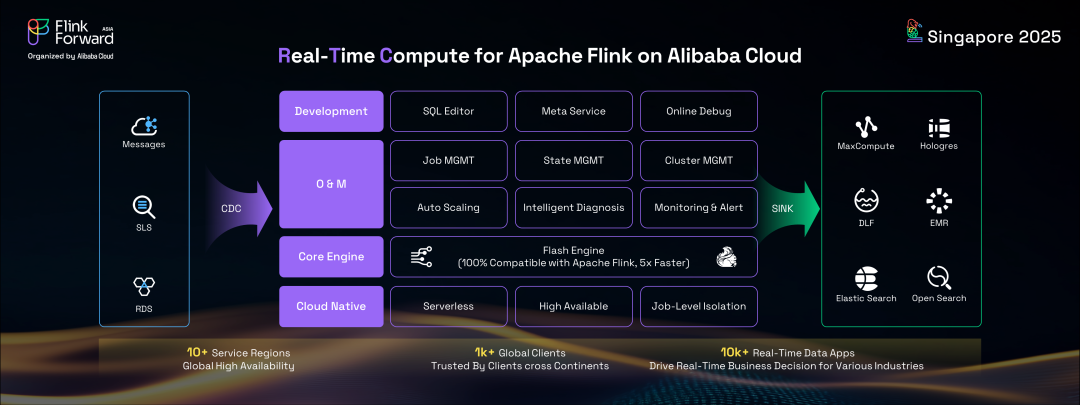
RTC 是一個全面的一站式實時數據平臺,包括 Web SQL 界面、元服務、在線調試以及云中 Flink 作業的操作和管理工具,所有這些都由核心 Flash 引擎提供支持。迄今為止,RTC 為10多個國家和地區的 1000 多個全球客戶提供服務,運行著 10000 多個 Flink 作業,為阿里云上無數行業客戶的實時業務決策提供驅動力。
04
Apache Flink 的未來:賦能實時 AI

雖然 Apache Flink 已經牢固確立了其作為全球實時數據分析事實標準的地位,但其未來遠遠超出了這一領域。在當前的人工智能時代,Flink 準備為 AI 系統和應用提供實時能力。眾所周知,計算能力、模型算法和數據是推動 AI 技術演進的三大基礎支柱。
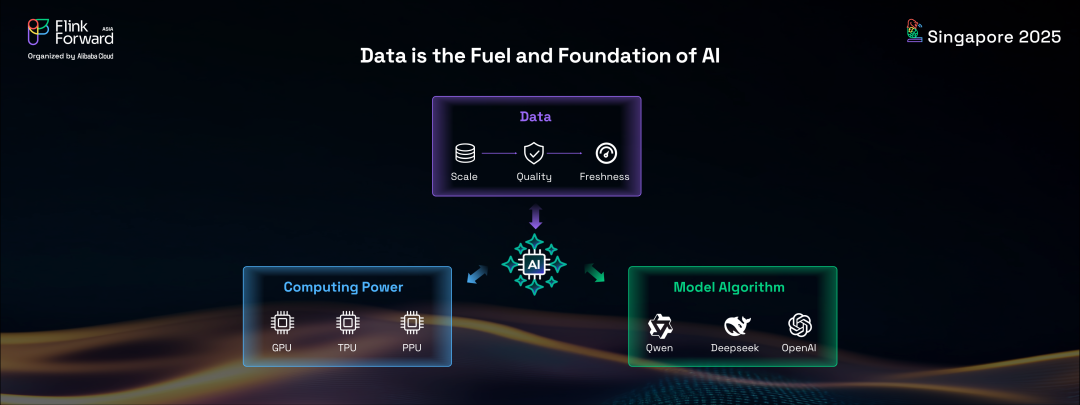
其中,數據發揮著特別關鍵的作用。規模定律表明,AI 模型隨著參數數量的增加而變得更加強大,現代AI模型正在規模上增長,變得多模態,并要求用于訓練的數據集越來越大。然而,在線公共數據的供應是有限的。未來的進步將更少依賴于數量,更多依賴于數據質量和新鮮度。

正如前面討論所強調的,數據越新鮮,其價值就越高,這一原則在 AI 世界中尤其成立。考慮一下 AI 系統或智能體缺乏實時或新鮮數據的后果。例如,客戶服務聊天機器人如果沒有客戶檔案、訂單或查詢上下文的最新信息,就難以提供準確的答案。類似地,推薦系統如果無法獲得客戶行為、行動或興趣的實時洞察,就無法提供相關建議。這些例子清楚地表明,實時能力是有效 AI 系統的固有特征。

在未來,所有 AI 應用都需要是實時的,為客戶提供即時和動態的體驗。
Apache Flink 獨特地定位于使當前的生成式AI系統實時化。
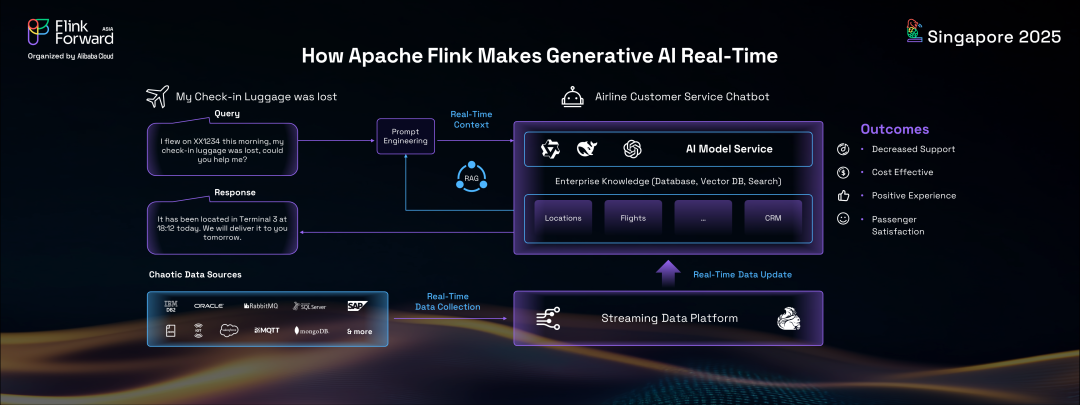
以航空公司客戶服務聊天機器人為例。如果乘客的行李丟失,沒有實時數據的傳統聊天機器人可能無法提供準確信息。然而,通過在 AI 系統背后構建由Flink驅動的強大流數據平臺,可以收集來自各種來源的實時數據并輸入到 AI 中,確保聊天機器人始終保持更新并能夠提供精確答案。這展示了 Flink 如何能夠轉換生成式AI系統,增強用戶體驗和準確性。
05
事件驅動 AI 智能體:下一個前沿
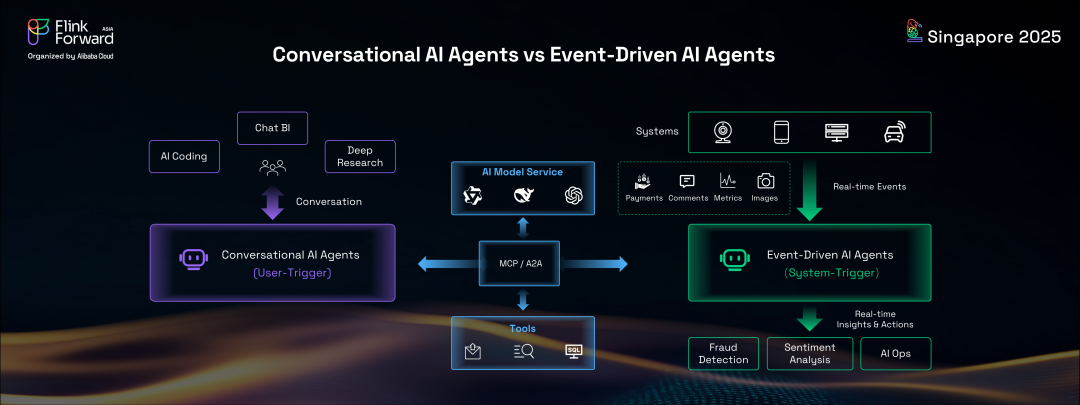
AI領域另一個快速興起的趨勢是 AI 智能體或智能體 AI(Agentic AI)的崛起。雖然存在許多類型的 AI 智能體,但它們基本上可以分為兩種主要類型:對話式 AI 智能體和事件驅動 AI 智能體。對話式 AI 智能體,如 AI 編程工具、聊天BI和深度研究助手,通常由人類用戶主動觸發,用戶與它們互動以提問和接收答案。相比之下,事件驅動 AI 智能體由系統觸發,對來自汽車、手機、機器、PC 或服務器等各種來源發出的實時事件做出反應。這些智能體提供全面的智能洞察并采取及時行動,以反應模式而非主動模式運行。例子包括欺詐檢測智能體、情感分析智能體和 AI 運維智能體。
考慮一個具體的用例:直播帶貨。
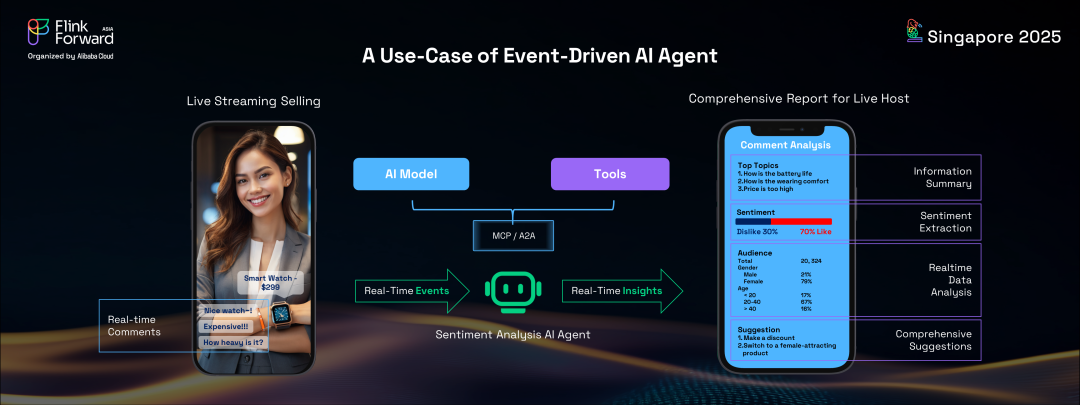
在這種流行的電商趨勢中,觀眾發送源源不斷的消息、評論和問題,在屏幕上快速刷新。主播幾乎不可能跟上或閱讀所有這些消息,更不用說從觀眾反饋中獲得洞察了。然而,通過部署由 Flink 驅動的情感分析智能體,主播可以獲得實時、全面的儀表板。這個儀表板不僅會顯示傳統的統計報告,如按地點和年齡劃分的觀眾人口統計,還會提供實時情感分析,指示觀眾偏好、討論話題,甚至提供動態建議。這種實時反饋循環使主播能夠動態調整策略,吸引更多觀眾注意力并推動更多交易。
構建這種事件驅動 AI 智能體需要強大的分布式運行時框架。
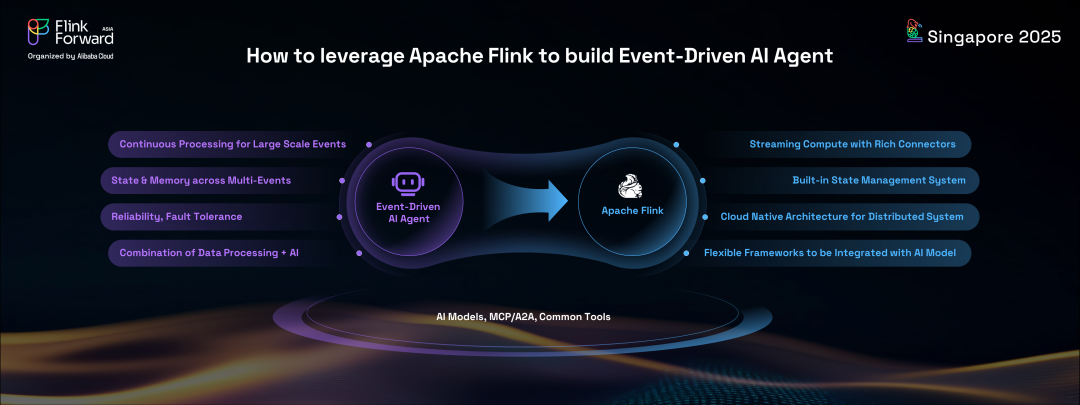
除了核心 AI 模型、MCP 協議和通用工具外,這些智能體還需要強大的能力來持續處理大規模事件、高效的事件收集以及跨多個事件的強大狀態管理或 AI 記憶。此外,這些在線分布式系統的可靠性和容錯性至關重要。鑒于 Apache Flink 作為成功的事件驅動數據處理器的優勢,它是構建事件驅動AI智能體實時運行時框架的理想選擇。
為了簡化在 Apache Flink 上開發事件驅動AI智能體,來自阿里巴巴、Confluent、Ververica 和 LinkedIn 的開發者共同發起了一個名為 Flink Agents 的開源項目。
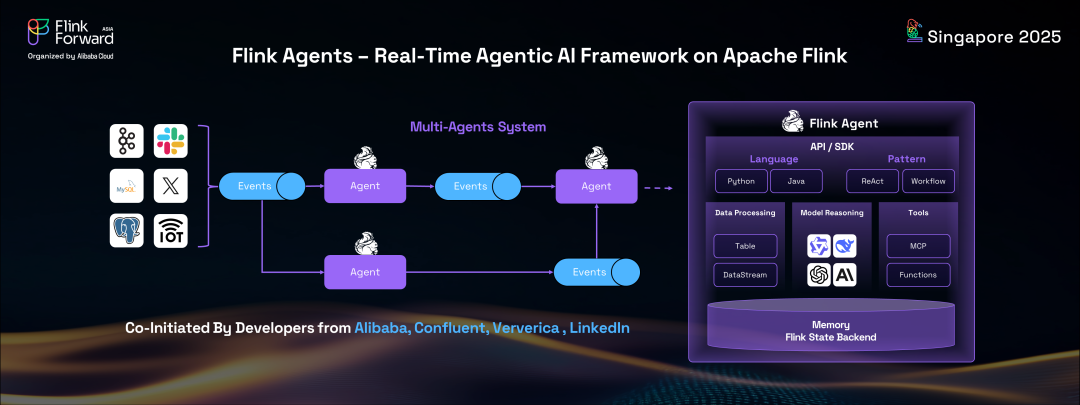
該項目旨在在 Apache Flink 之上建立一個智能體 AI 框架,專門針對事件驅動AI智能體量身定制。該框架提供 Java 和 Python API,支持構建 AI 智能體的靜態工作流和 ReAct 模式。利用 Flink 豐富的連接器和強大的 CDC 流處理能力,Flink Agents 使開發者可以輕松收集和處理實時事件,為用戶提供即時洞察和建議。Flink 固有的有狀態流計算引擎,具有強大的內置狀態后端和狀態管理系統,作為跨多個事件的強大 AI 記憶,進一步鞏固了其在這一領域的作用。
06
Flink 與生成式 AI:深度集成
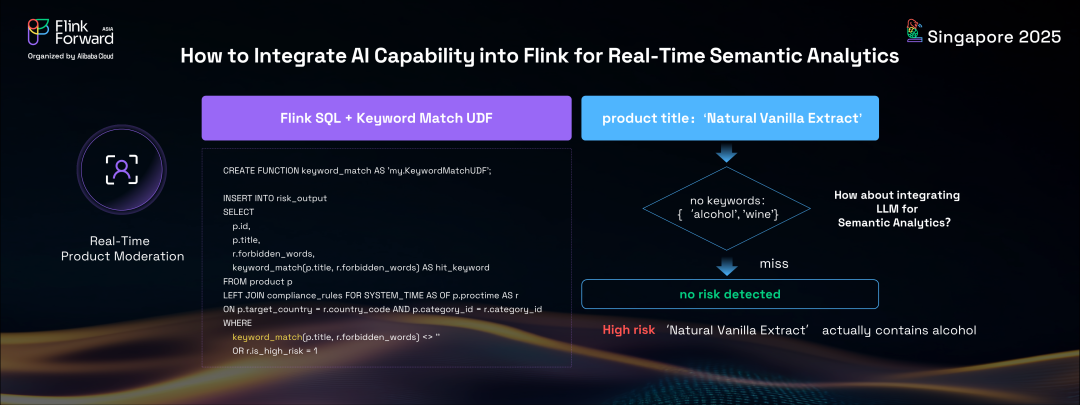
在討論的最后部分,我們探索將強大的AI能力,特別是生成式 AI,集成到 Apache Flink 中的激動人心的集成。Flink 現在可以為客戶執行實時語義分析,為智能數據處理開辟了新的可能性。讓我們考慮一個具體的用例:電商平臺上的產品審核。每個產品在上架前都必須經過嚴格的審核以確保合規。傳統上,這涉及編寫 Flink SQL 來連接產品發布流與合規規則表,并使用字符串匹配函數檢查產品標題中的禁用關鍵詞。這種基于規則的方法雖然有效,但有其局限性。
在當前的 AI 時代,越來越傾向于智能的、基于語義的解決方案。通過將生成式AI能力,特別是大語言模型(LLM),集成到 Apache Flink 中,Flink 用戶可以前所未有地輕松執行實時語義分析。幸運的是,Flink 2.0 引入了一個名為 Flink SQL 中的 AI 函數的新功能。
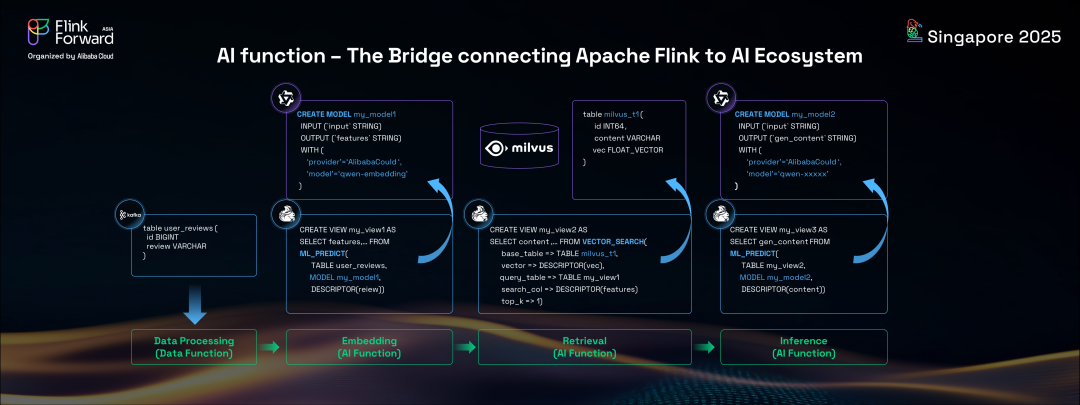
這個功能允許 Flink 用戶直接在 Flink SQL 語句中調用AI語言模型服務并執行向量搜索,與傳統的 SQL 數據處理并行。這意味著開發者可以使用 Flink SQL 創建或定義 AI 模型,指定模型名稱、端點、API 密鑰和系統提示等選項。將支持與 OpenAI 協議兼容的模型。
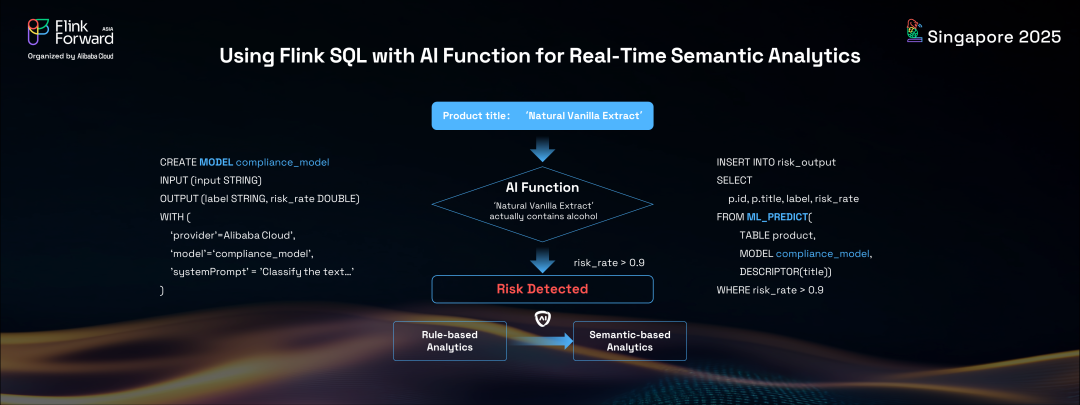
然后,開發者可以直接在傳統 Flink SQL 中調用這些 AI 模型服務進行實時流推理。即使對于 RAG(檢索增強生成)解決方案,開發者也可以在 SQL 語句中方便地以實時模式執行嵌入和向量搜索。這種新的 Flink AI SQL 能力無縫結合了傳統關系代數與生成式 AI,實現了結構化和非結構化數據的實時語義分析。回到我們的產品審核示例,使用新的 Flink AI 解決方案,我們可以用更先進的方式解決同樣的問題。通過創建復雜模型并在 Flink SQL 中使用 AI 函數ML_predict,我們可以對產品標題進行語義分析以檢查合規性。這種 AI 驅動的、基于語義的解決方案提供了優于傳統基于規則方法的結果和更好的體驗,甚至可以檢測到標題中沒有明確禁用關鍵詞的不合規產品。
07
結論與展望
總之,Apache Flink 不僅在實時數據分析方面蓬勃發展,而且正在成為當前 AI 系統和應用實時基礎設施的關鍵組件。雖然今天的大多數 AI 模型都是離線訓練并在數天、數周甚至數月內緩慢更新,但未來有著不同的前景。我相信在未來,大多數強大的 AI 模型將實時訓練和更新,使 AI 系統能夠像人類一樣持續學習。在那時,Apache Flink 作為實時計算引擎,將在 AI 世界中發揮更加重要的作用,使 AI 模型、系統和應用充分發揮其潛力。謝謝。
















)
)
)
