1 為什么要在 Elasticsearch 上做 LTR?
適用版本: Elasticsearch ≥ 8.12.0
前置條件: 需擁有包含 “Serverless LTR” 的訂閱等級(詳見官方訂閱矩陣)
技術棧: Elasticsearch + Python + Eland + XGBoost / LightGBM / scikit-learn
- 相關性瓶頸:經典 BM25 只能“打基礎”,很難兼顧業務特征(點擊率、銷量、評分……)。
- 端到端成本:把向量檢索或深度模型接到 ES 之外,需要額外的服務網關、時延和 DevOps。
- Elasticsearch 8.12.0 新特性:官方 Serverless LTR 能直接在 search → rescore 階段調用訓練好的模型,既繼承 ES 的伸縮性,又省去了微服務運維。
2 整體流程概覽
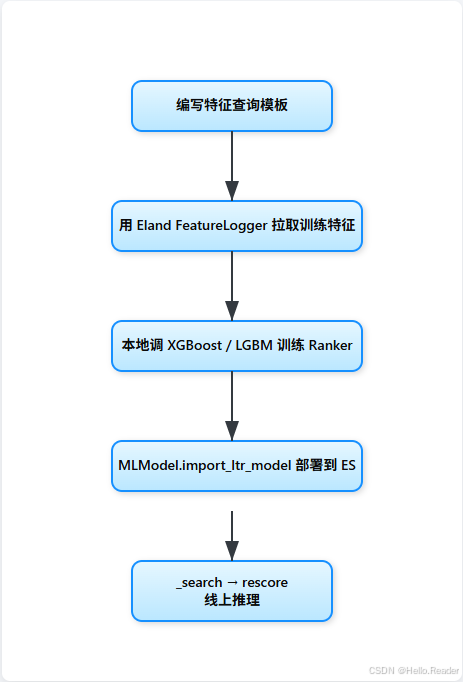
3 環境準備
pip install "elasticsearch>=8.12" eland pandas scikit-learn xgboost lightgbm
export ELASTICSEARCH_URL="http://localhost:9200"
export ELASTIC_PASSWORD="elastic_password"
貼士:離線訓練最好用一套隔離的 ES 集群,避免大規模特征抽取沖擊線上查詢。
4 定義特征抽取模板(QueryFeatureExtractor)
from eland.ml.ltr import QueryFeatureExtractor, LTRModelConfigfeature_extractors = [# 1?? BM25 分數QueryFeatureExtractor(feature_name="title_bm25",query={"match": {"title": "{{query}}"}}),# 2?? Title 命中詞數QueryFeatureExtractor(feature_name="title_matched_term_count",query={"script_score": {"query": {"match": {"title": "{{query}}"}},"script": {"source": "return _termStats.matchedTermsCount();"}}}),# 3?? 直接把文檔字段當特征QueryFeatureExtractor(feature_name="popularity",query={"script_score": {"query": {"exists": {"field": "popularity"}},"script": {"source": "return doc['popularity'].value;"}}}),# 4?? 查詢詞長度QueryFeatureExtractor(feature_name="query_term_count",query={"script_score": {"query": {"match": {"title": "{{query}}"}},"script": {"source": "return _termStats.uniqueTermsCount();"}}}),
]ltr_config = LTRModelConfig(feature_extractors)
為什么不用自己寫腳本?
Eland 與 Elasticsearch 同步開發&測試,可確保訓練階段與線上推理的特征完全一致,避免“訓練-服務漂移”。
5 采集訓練數據(FeatureLogger)
from eland.ml.ltr import FeatureLogger
from elasticsearch import Elasticsearch
import pandas as pdes = Elasticsearch(ELASTICSEARCH_URL, basic_auth=("elastic", ELASTIC_PASSWORD))
MOVIE_INDEX = "movies_demo"logger = FeatureLogger(es, MOVIE_INDEX, ltr_config)# 假設我們已有一份人工評判文件 judgements.csv
judgements = pd.read_csv("judgements.csv") # query, doc_id, relevancerecords = []
for _, row in judgements.iterrows():feats = logger.extract_features(query_params={"query": row.query},doc_ids=[row.doc_id])record = feats[0].to_dict()record["label"] = row.relevancerecords.append(record)df_train = pd.DataFrame(records)
df_train.to_csv("ltr_train.csv", index=False)
性能提示:FeatureLogger 會自動合并批量請求、最小化查詢次數,但大量特征 × 大量樣本仍可能對 ES 造成壓力。調低
size或切分批次能進一步減負。
6 訓練 Ranker
以下以 XGBRanker 為例(LightGBM、RandomForest、DecisionTree 均可):
from xgboost import XGBRanker
import numpy as npX = df_train[feature_extractors_names].values
y = df_train["label"].values
group = df_train.groupby("query").size().to_numpy() # 每個 query 的樣本數ranker = XGBRanker(objective="rank:pairwise",n_estimators=300,max_depth=6,learning_rate=0.1)
ranker.fit(X, y, group=group)
7 模型部署一鍵化(MLModel.import_ltr_model)
from eland.ml import MLModelMODEL_ID = "movies_ltr_xgboost_v1"MLModel.import_ltr_model(es_client=es,model=ranker,model_id=MODEL_ID,ltr_model_config=ltr_config,es_if_exists="replace" # 本例重復執行時覆蓋
)
執行后,Eland 會自動:
- 將模型序列化為 ES 接受的 [Eland ML Pack] 格式;
- 調用 Create Trained Model API 上傳;
- 生成
inference_config,包含上文 4 個特征查詢模板。
8 線上調用:Search + Rescore
POST movies_demo/_search
{"query": {"match": {"title": "science fiction"}},"rescore": {"window_size": 100,"query": {"rescore_query": {"ltr_model": {"model_id": "movies_ltr_xgboost_v1","params": { "query": "science fiction" }}},"query_weight": 0.2,"rescore_query_weight": 1.0}}
}
window_size控制重新排序的命中窗口,100-500 較常見;params.query必須與特征模板中的{{query}}對應;query_weight越小,模型重排權重越大。
9 模型管理運維
| 操作 | API | 說明 |
|---|---|---|
| 查看模型 | GET _ml/trained_models/<id> | 包含元數據、大小、創建時間 |
| 移除舊版 | DELETE _ml/trained_models/<id> | 勿忘同時清理索引模板里舊 rescore 配置 |
| 批量遷移 | POST _ml/trained_models/_revert | 結合 CI/CD 做藍綠發布 |
| 性能監控 | _nodes/stats inference | 關注推理延遲 & CPU/內存 |
10 最佳實踐與踩坑
| 場景 | 建議 |
|---|---|
| 特征庫膨脹 | 控制在 20-40 個以內;復雜邏輯交給模型學習權重,而不是寫 N 個腳本評分 |
| 交叉驗證 | 使用 group k-fold,確保同一 query 不同時出現在 train&test |
| 線上流量回滾 | 給舊 BM25 排序保留 20% 流量,異常時快速切換 |
| 版本化 | movies_ltr_xgboost_v1 → v2,避免熱更新導致 cache 沖突 |
| 安全與訂閱 | 開啟 HTTPS + token;無服務器版本僅在滿足訂閱級別時可用 |
11 總結
借助 8.12.0 新增的 Serverless LTR + Eland:
- 開發側:用 Python 就能完成 特征抽取 → 訓練 → 部署 閉環,無需自研特征解析與序列化。
- 運維側:模型與索引共生,統一在 ES 集群里監控、熱更新,簡化了線上鏈路。
- 業務側:短期內即可驗證“學習排序 vs 傳統 BM25”的收益,并可逐步升級至更復雜的多階段檢索 / 向量召回方案。
開源筆記本示例:https://github.com/elastic/elasticsearch-labs/tree/main/notebooks/ltr
趕緊試試把你的點擊日志、評分字段喂給 XGBoost,讓搜索結果 “更懂業務” 吧!










 -- 分布式鎖Redission底層機制)








