本文介紹了基于Wenet語音識別工具包的實時敏感詞屏蔽技術方案。該方案通過客戶端緩存25秒直播內容,利用Wenet的流式識別和斷句檢測功能,實時檢測講師語音中的敏感詞,并將對應位置的語音替換為"嗶"聲。文章詳細闡述了Wenet的兩種識別方式(流式/非流式)、三種部署方案及其性能指標,重點說明了客戶端4.x的接入方案:采用流式識別+智能斷句方式,在子線程處理敏感詞檢測,主推流流程不受影響,最大延遲不超過25秒。該技術可在直播過程中實現敏感內容的實時自動屏蔽。
?直播敏感語音,實現"嗶嗶"屏蔽技術。?

直播場景實際應用中的需求:在客戶端直播的時候,實時檢測講師的語音內容,檢測到敏感詞后,自動把對應的語音內容用“嗶”聲代替 。
客戶端緩存25s直播內容,在語音識別引擎識別到屏蔽詞后,找到屏蔽詞在語音緩存的位置,將語音內容替換為“嗶”聲的語音內容。
1.?wenet簡述:
Wenet是出門問問語音團隊聯合西工大語音實驗室開源的一款面向工業落地應用的語音識別工具包,該工具用一套簡潔的方案提供了語音識別從訓練到部署的服務。
1.1. wenet識別方式
流式:語音以實時流的方式推入引擎;(識別結果不太準確,較快)
非流式:語音以一整段語音的方式推入引擎。(識別結果較準確,較慢)
斷句檢測:如果語音以流式推入引擎,則需要斷句檢測,原理參考:
WeNet 更新:支持 Endpoint 檢測
Endpoint 檢測是語音識別系統的重要組成部分,可以提高人機交互的效能和質量。它的任務是確定用戶何時結束講話,這對于實時長語音轉寫和語音搜索等交互式語音應用非常重要。
最近,WeNet 的更新則支持了 endpoint 的檢測。有了 endpoint 檢測,我們就可以愉快地進行實時長語音轉寫了。下面將從實現原理和應用方面介紹 endpoint 檢測和實時長語音轉寫的使用。
①. 識別出文字之前,檢測到了 5s 的靜音;
②. 識別出文字之后,檢測到了 2s 的靜音;
③. 解碼到概率較小的 final state,且檢測到了 1s 的靜音;
④. 解碼到概率較大的 final state,且檢測到了 0.5s 的靜音;
⑤. 已經解碼了 20s。
注意:wenet同時支持流失、非流失、以及斷句檢測。當數據以流失輸入wenet時,wenet可在返回流式結果的同時智能斷句,并返回整句的最終結果。
1.2. wenet部署方案
①. 部署在端上:win64、mac-intel64、Linux-64;
APP直接調用wenet接口(C++)-(本次demo采用)
②. 部署在服務器上:Linux-docker
APP調用websocket接口,上傳音頻,由服務器通過websocket返回結果。
1.3. wenet延時性能
①. 處理延時:處理10s音頻不超過1s;
②. 模型帶來的流式延時:不超過0.4s;
③. 斷句并重打分計算:不超過0.14s。
1.4. 參考資料
https://github.com/wenet-e2e/wenet
Welcome to wenet’s documentation! — wenet documentation
https://zhuanlan.zhihu.com/p/349586567
1.5.WeNet Endpoint?實現
WeNet 中 endpoint 檢測相關代碼的實現在?decoder/ctc_endpoint.h?和?decoder/ctc_endpoint.cc?中。
// 遍歷每一個時間步
for (int t = 0; t < ctc_log_probs.size(0); ++t) {torch::Tensor logp_t = ctc_log_probs[t];// 獲取當前時間步 blank 標簽的概率float blank_prob = expf(logp_t[config_.blank].item<float>());// 解碼幀數加一num_frames_decoded_++;// 判斷 blank 標簽的概率是否大于閾值(默認 0.8)if (blank_prob > config_.blank_threshold) {// 是,則尾部 blank 標簽的幀數加一num_frames_trailing_blank_++;} else {// 否,則尾部 blank 標簽的幀數置零num_frames_trailing_blank_ = 0;}
}三條規則的表示如下所示,可以手動添加更多的規則或者更改規則中的時間,以滿足各種不同場景下的需求。
// rule1 times out after 5000 ms of silence, even if we decoded nothing.
CtcEndpointRule rule1;
// rule2 times out after 1000 ms of silence after decoding something.
CtcEndpointRule rule2;
// rule3 times out after the utterance is 20000 ms long, regardless of
// anything else.
CtcEndpointRule rule3;CtcEndpointConfig(): rule1(false, 5000, 0), rule2(true, 1000, 0), rule3(false, 0, 20000) {}2. 基于保利威客戶端4.x接入方案
2.1. 采用的識別方式
①.流失:數據以流失推入wenet;
②.斷句:由于流失實時識別結果并不準確,且不帶時間戳,無法準確定位音頻。因此,使用wenet的斷句功能,斷句后獲取整句結果;
2.2. 原理
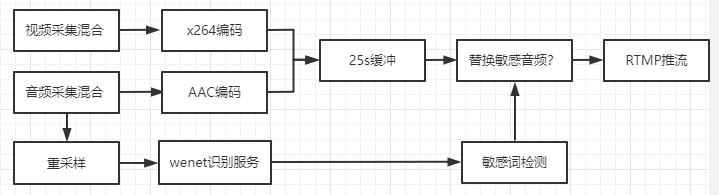
①. 接入方式:4.x采用直接調用wenet-C++接口的方式接入;
②. 延時直播:識別方式采用流失+智能斷句的方式,斷句最長會導致20s延時,加上其他延時,因此,最長不超過25s。?
③. 主流程不打斷:OBS的采集→編碼→緩沖→推流,該流程不會進行任何阻塞。 wenet識別→敏感詞檢測均在子線程處理,若無法找到敏感詞對應的音頻數據包,則會直接丟棄。
 配圖企業直播客戶端軟件接入敏感語音屏蔽技術
配圖企業直播客戶端軟件接入敏感語音屏蔽技術
?我的熱門文章匯總:
- 開通微信視頻號直播需要滿足哪些條件?
- 徹底永久關閉WIN10系統的自動更新(操作步驟)
- 視頻碼率、幀率、分辨率、視頻標清、高清、全高清的全面介紹與參考表
- Thinkpad電腦系列產品進入Bios設置和U盤啟動(重裝系統)
- 網線水晶頭接法圖解詳細8根線芯順序排序圖示
我的在線教育原創文章匯總:
- Vue3框架對接保利威云點播播放器的實踐(實例)
- 視頻點播web端AI智能大綱(自動生成視頻內容大綱)的代碼與演示
- html5視頻播放器的斷點續播和記憶播放是如何做的?
- 視頻安全之視頻防盜鏈和視頻防盜錄
- 課程學習網站視頻禁止拖拽快進是如何做的?


核心機制剖析:持久化與共享的終極解決方案)





![[自動化Adapt] GUI交互(窗口/元素) | 系統配置 | 非侵入式定制化](http://pic.xiahunao.cn/[自動化Adapt] GUI交互(窗口/元素) | 系統配置 | 非侵入式定制化)


+數據結構數組、樹、隊列【舊文搬運】)







