一、項目背景與需求
視頻介紹
【圖像算法 - 09】基于深度學習的煙霧檢測:從算法原理到工程實現,完整實戰指南
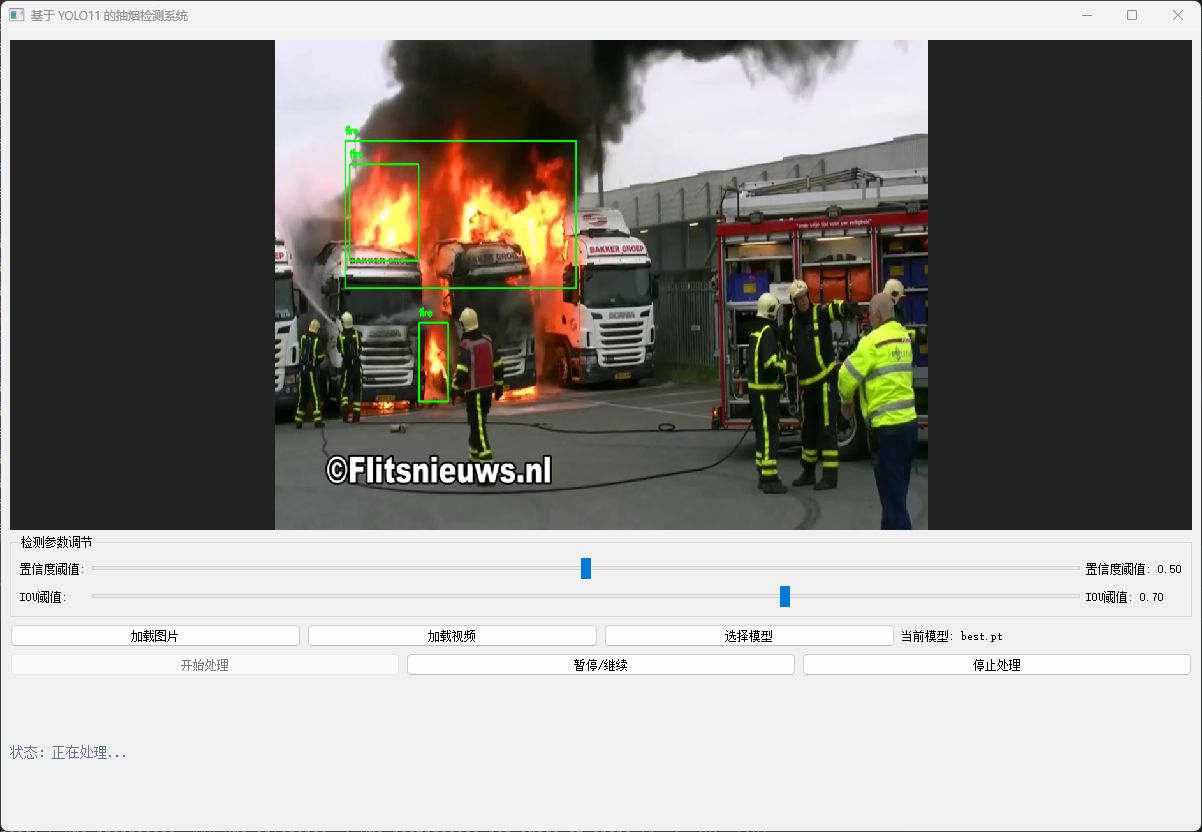
今天我們使用深度學習來訓練一個煙霧明火檢測系統。這次我們使用了大概一萬五千張圖片的數據集訓練了這次的基于深度學習的煙霧明火檢測模型,然后在推理的基礎上使用PyQt設計了可視化的操作界面。

二、為什么選擇深度學習?

在煙火檢測領域,傳統算法與深度學習的技術路徑存在本質差異,這些差異直接影響檢測效果、適用場景和落地難度。以下從核心邏輯、技術細節、優劣勢等維度展開對比,解釋兩者的不同:
1. 核心邏輯:“人工設計” vs “自動學習”
-
傳統算法:依賴 ”人工設計特征 + 規則判斷“
核心邏輯是:通過人類對煙火的先驗知識(如顏色、形狀、動態特性),手動設計特征提取規則,再用簡單分類器判斷是否為煙火。
例如:- 顏色特征:用 HSV 閾值篩選紅色 / 橙色區域(火焰典型色)、灰色 / 白色區域(煙霧典型色);
- 動態特征:通過幀差法檢測區域的閃爍(火焰)或緩慢擴散(煙霧);
- 形狀特征:用邊緣檢測判斷是否存在不規則、動態變化的輪廓(火焰)或模糊擴散的區域(煙霧)。
-
深度學習:依賴 “數據驅動 + 自動特征學習”
核心邏輯是:無需人工設計特征,通過神經網絡從大量標注數據中自動學習煙火的本質特征(包括人類難以描述的細微特征),端到端完成 “輸入圖像 / 視頻→輸出是否為煙火” 的判斷。
例如:- 用 CNN(如 ResNet、YOLO)自動提取煙火的空間特征(紋理、梯度、高階組合特征);
- 用 RNN/LSTM 或 3D-CNN 學習煙火的時間動態特征(如火焰的跳躍、煙霧的流動趨勢);
- 模型通過反向傳播不斷優化,最終形成對煙火的 “抽象認知”。
2. 技術細節:從特征到泛化能力的全面差異
| 對比維度 | 傳統算法 | 深度學習 |
|---|---|---|
| 特征提取方式 | 手工設計(顏色、形狀、運動、紋理等規則) | 自動學習(神經網絡從數據中挖掘深層特征) |
| 數據依賴 | 對數據量要求低(依賴先驗規則,無需大量樣本) | 強依賴大規模標注數據(數據量不足易過擬合) |
| 魯棒性 | 弱(受場景干擾大): - 光照變化(如夕陽誤判為火焰)、遮擋(部分遮擋即失效)、復雜背景(如紅色廣告牌誤判)會嚴重影響效果; - 對煙火形態變化(如小火苗、濃 / 淡煙霧)適應性差。 | 強(復雜場景適應性好): - 能學習到抗干擾特征(如區分火焰與夕陽的細微紋理差異); - 對遮擋、形態變化的容忍度高(通過大量多樣本訓練實現)。 |
| 計算成本 | 低(輕量級算法,可在 CPU / 嵌入式設備運行) | 高(需 GPU 加速,模型參數量大,計算耗時) |
| 泛化能力 | 差(規則固定,換場景需重新設計特征) | 強(通過遷移學習可快速適配新場景) |
| 典型方法 | 顏色閾值分割、幀差法、SVM 分類器、AdaBoost 等 | CNN(ResNet)、目標檢測模型(YOLO、Faster R-CNN)、3D-CNN(處理視頻)等 |
3. 適用場景:各有側重,按需選擇
-
傳統算法:適合簡單場景、資源受限的場景
例如:固定攝像頭監控空曠區域(如倉庫、森林),煙火形態單一、背景簡單(無復雜干擾物),且設備算力有限(如嵌入式攝像頭、低端 CPU)。優勢是部署成本低、實時性強(毫秒級響應),但需人工針對場景調參。
-
深度學習:適合復雜場景、高精度需求的場景
例如:城市街道(背景復雜,有車輛、行人干擾)、室內場所(光照多變、可能有遮擋),需要區分 “煙火” 與 “類似物”(如紅色燈籠、蒸汽)。優勢是檢測精度高、泛化能力強,但需 GPU 支持,部署成本較高(需服務器或邊緣計算設備)。
二、數據集
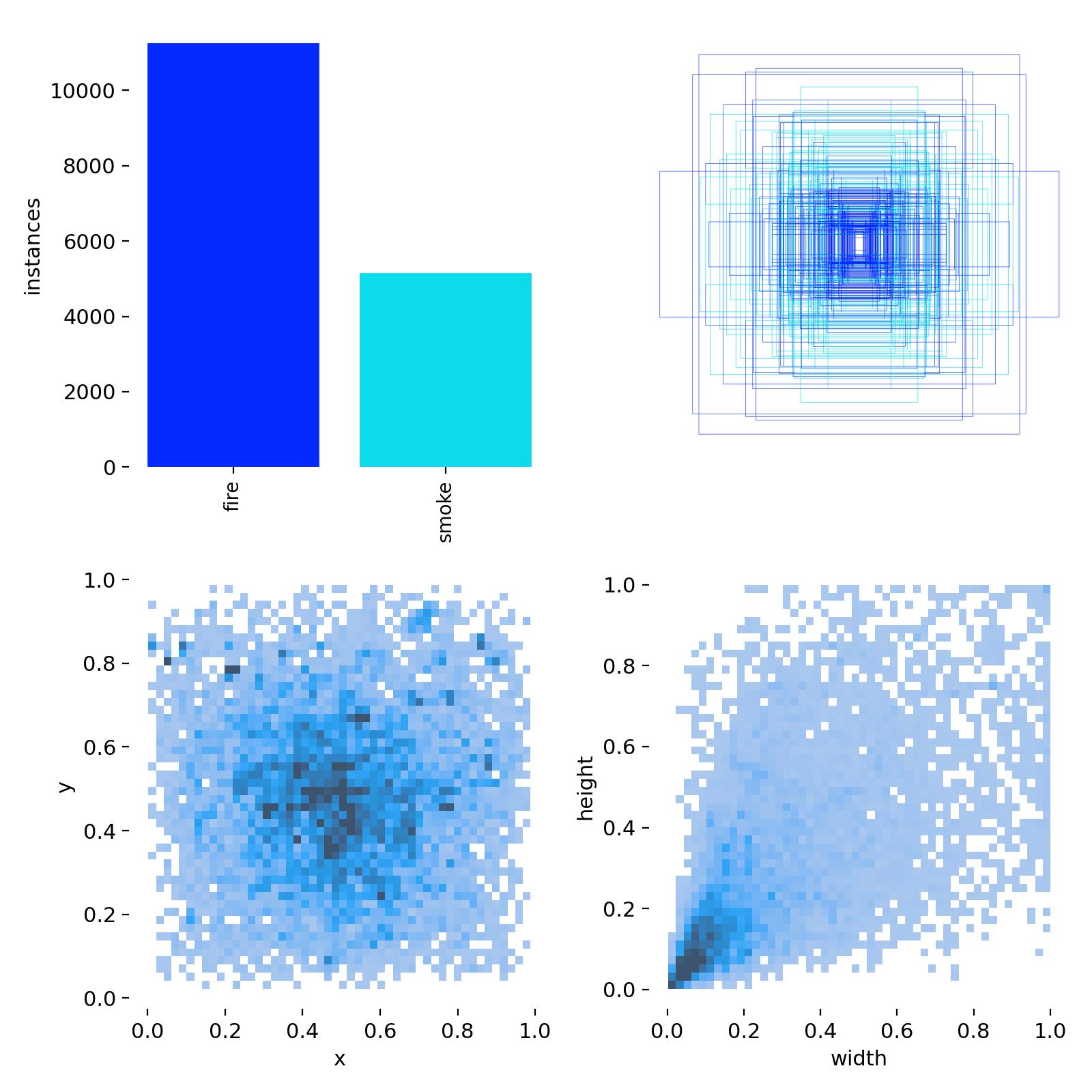
此次訓練使用的煙霧明火數據集,有兩類,即smoke、fire。然后下面是數據集的統計分析圖。一共有10000余火焰目標、近6000的煙霧目標,標簽的中心坐標分布比較均勻,居中較多,同時都不靠近邊緣;目標,即抽煙目標的長寬同樣比較集中,屬于小目標的范圍(小于圖像長寬的0.2倍)。
三、網絡選擇
這里我們選擇的是yolo11s的網絡結構,其參數如下表所示:
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 181 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 181 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 231 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 357 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 357 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
四、模型訓練
本次訓練使用的預訓練模型是YOLO11s.pt(COCO數據集訓練所得),epochs設置為100,batch設置為16,imgsz設置為640,其他均采用默認參數,訓練時間大概4小時。
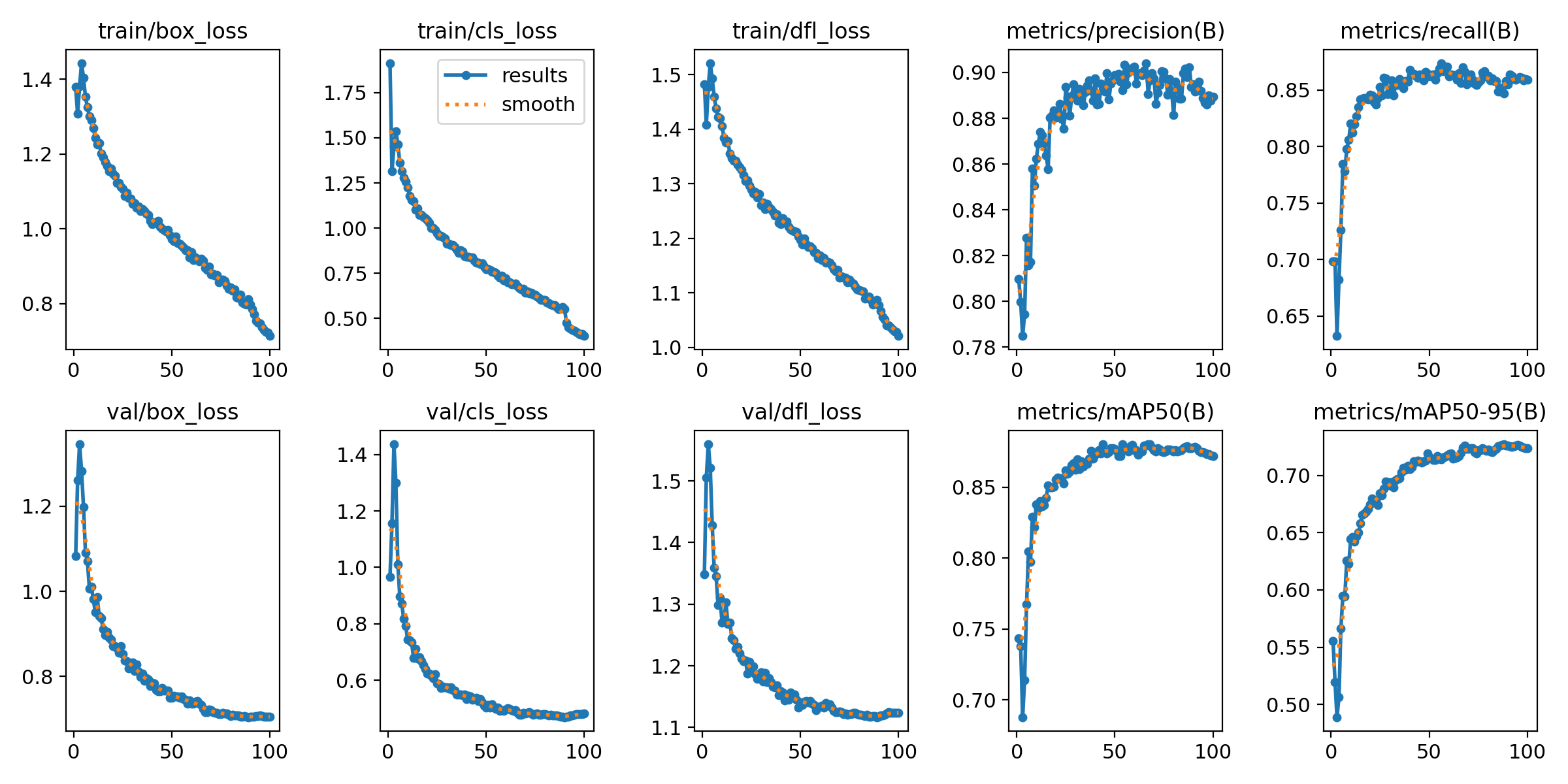
五、可視化模型推理


)



—— 數據結構的基本概念)







核心機制剖析:持久化與共享的終極解決方案)




