信噪比感知的低光照圖像增強
摘要
本文提出了一種新的低光照圖像增強解決方案,通過聯合利用信噪比(SNR)感知的變換器(transformer)和卷積模型,以空間變化的操作方式動態增強像素。對于極低信噪比(SNR)的圖像區域使用長程操作,對于其他區域使用短程操作。我們提出利用SNR先驗來指導特征融合,并設計了一種新的自注意力模型來構建SNR感知變換器,以避免來自極低SNR噪聲圖像區域的令牌(tokens)參與計算。大量實驗表明,在七個具有代表性的基準數據集上,使用相同的網絡結構,我們的框架始終比最先進(SOTA)方法獲得更好的性能。此外,我們進行了一項有100名參與者的大規模用戶研究,以驗證我們結果的優越感知質量。代碼可在 https://github.com/dvlab-research/SNR-Aware-Low-Light-Enhance 獲取。
1 引言
低光照成像對于許多任務至關重要,例如夜間物體和動作識別[18, 27]。低光照圖像通常對人類感知來說可見度差。同樣,當下游視覺任務直接以低光照圖像作為輸入時,其性能也會受到影響。
已經提出了幾種方法來增強低光照圖像。當前事實上的方法是開發神經網絡,學習操縱顏色、色調和對比度來增強低光照圖像[12, 15, 56, 41],而一些近期工作則考慮了圖像中的噪聲[48, 29]。本文中,我們的關鍵見解是:低光照圖像中的不同區域可能具有不同的亮度、噪聲、可見度等特性。極低亮度區域被噪聲嚴重破壞,而同一圖像中的其他區域可能仍具有合理的可見度和對比度。為了獲得更好的整體圖像增強效果,我們應該自適應地考慮低光照圖像中的不同區域。
為此,我們通過探索信噪比(SNR)[54, 3]來研究圖像空間中信號與噪聲之間的關系,以實現空間變化的增強。具體來說,較低SNR的區域通常不清晰。因此,我們利用更長空間范圍的非局部圖像信息進行圖像增強。另一方面,相對較高SNR的區域通常具有更高的可見度和更少的噪聲。因此,局部圖像信息通常就足夠了。圖2展示了一個用于說明的低光照圖像示例。進一步討論見第3.1節。

我們在RGB域中解決低光照圖像增強的方案是聯合利用長程和短程操作。在最深的隱藏層中,我們設計了兩個分支。具有transformer結構[38]的長程分支用于捕獲非局部信息,而具有卷積殘差塊[17]的短程分支捕獲局部信息。在增強每個像素時,我們根據像素的信噪比動態地確定局部(短程)和非局部(長程)信息的貢獻。因此,在高SNR區域,局部信息在增強過程中起主要作用;而在極低SNR區域,非局部信息則更有效。為了實現這種空間變化操作,我們構建了一個SNR先驗并用它來指導特征融合。此外,我們修改了變換器結構中的注意力機制,提出了SNR感知變換器。與現有變換器結構不同,并非所有令牌都參與注意力計算。我們僅考慮具有足夠SNR值的令牌,以避免來自極低SNR區域的噪聲影響。
我們的框架能有效增強具有動態噪聲水平的低光照圖像。我們在7個代表性數據集上進行了大量實驗:LOL (v1 [45], v2-real [53], & v2-synthetic [53])、SID [5]、SMID [4] 和 SDSD (indoor & outdoor) [39]。如圖1所示,在所有數據集上使用相同結構,我們的框架均優于10種SOTA方法。此外,我們進行了有100名參與者的大規模用戶研究,以驗證我們方法的有效性。定性比較如圖3所示。總的來說,我們的貢獻有三個方面:
- 我們提出了一個新的信噪比感知框架,該框架同時采用變換器結構和卷積模型,利用SNR先驗實現空間變化的低光照圖像增強。
- 我們設計了一個用于低光照圖像增強的SNR感知變換器,它具有一個新的自注意力模塊。
- 我們在七個代表性數據集上進行了大量實驗,表明我們的框架始終優于一系列豐富的SOTA方法。
2 相關工作
無學習的低光照圖像增強。 為了增強低光照圖像,直方圖均衡化和伽馬校正(gamma correction)是擴展動態范圍和增加圖像對比度的基本工具。這些基本方法在增強真實世界圖像時往往會產生不希望的偽影。基于Retinex的方法將反射分量視為圖像增強的合理近似,能夠產生更真實自然的結果[28, 35]。然而,在增強復雜的真實世界圖像時,這類方法經常會導致局部顏色失真[40]。
基于學習的低光照圖像增強。 近年來提出了許多基于學習的低光照圖像增強方法[2, 14, 20, 22, 29, 31, 42, 48, 49, 50, 52, 53, 59, 60, 62, 63]。Wang等人[40]提出預測光照圖來增強曝光不足的照片。Sean等人[33]設計了一種策略來學習三種不同類型的空間局部濾波器進行增強。Yang等人[51]提出了一種半監督方法來恢復低光照圖像的線性帶表示。此外,還有無監督方法[7, 14, 19]。例如,Guo等人[14]構建了一個輕量級網絡來估計逐像素和高階曲線以進行動態范圍調整。
與之前的工作不同,我們的新方法基于一個信噪比感知框架來增強低光照圖像,該框架包含一個新的SNR感知變換器設計和一個卷積模型,以空間變化的方式自適應地增強低光照圖像。如圖1所示,我們的框架在七個不同基準數據集上使用相同結構始終取得更好的性能。
3 我們的方法
圖444展示了我們框架的概覽。輸入是一個低光照圖像,我們首先使用一個簡單而有效的策略從中獲取SNR圖(詳見第3.2節)。我們建議利用SNR來指導我們的框架,為具有不同信噪比的圖像區域自適應地學習不同的增強操作。
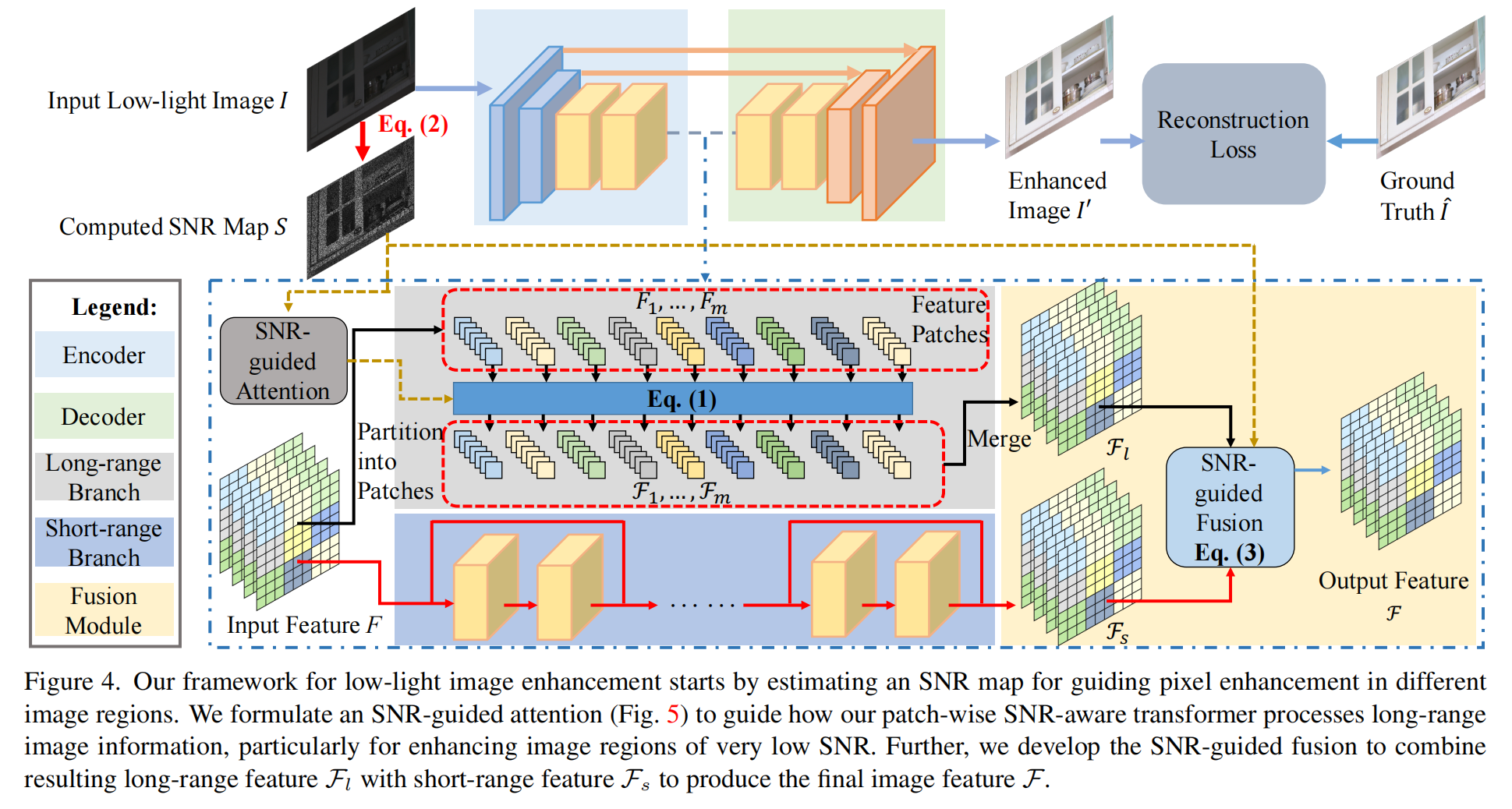
圖4: 我們的低光照圖像增強框架首先估計一個SNR圖,用于指導不同圖像區域的像素增強。我們構建了一個SNR引導的注意力(圖5)機制,指導我們的基于塊的SNR感知變換器如何處理長程圖像信息,特別是用于增強極低SNR的圖像區域。此外,我們開發了SNR引導的融合,將得到的長程特征 Fl\mathcal{F}_{l}Fl? 與短程特征 Fs\mathcal{F}_{s}Fs? 結合,生成最終的圖像特征 F\mathcal{F}F。
在我們框架的最深隱藏層中,我們設計了兩個不同的分支用于長程和短程操作。它們分別通過變換器[38]和卷積結構實現,旨在實現高效操作。為了實現長程操作同時避免極低光照區域噪聲的影響,我們用SNR圖來指導變換器中的注意力機制。為了采用不同的操作,我們開發了一種基于SNR的融合策略,從長程和短程特征中獲得組合表示。此外,我們使用從編碼器到解碼器的跳躍連接來增強圖像細節。
長程和短程分支
空間變化操作的必要性。 傳統的低光照圖像增強網絡在最深的隱藏層采用卷積結構。這些操作主要是短程的,用于捕獲局部信息。對于并非極度黑暗的圖像區域,局部信息可能足以恢復,因為這些像素仍然包含一定量的可見圖像內容(或信號)。但對于極度黑暗的區域,局部信息不足以增強像素,因為相鄰局部區域的可見度也很弱,且主要被噪聲主導。
為了解決這個關鍵問題,我們利用變化的局部和非局部信息交互來動態增強不同區域的像素。局部和非局部信息是互補的。其效果可以根據圖像上的SNR分布來確定。一方面,對于高SNR的圖像區域,局部信息應起主要作用,因為局部信息足以進行增強。它通常比長距離的非局部信息更準確。
另一方面,對于極低SNR的圖像區域,我們更關注非局部信息,因為局部區域可能包含很少的圖像信息而主要被噪聲主導。與之前的方法不同,我們在框架的最深隱藏層中(見圖4)明確地制定了一個用于極低SNR圖像區域的長程分支和一個用于其他區域的短程分支。
兩個分支的實現。 短程分支基于卷積殘差塊的結構實現,用于捕獲局部信息;而長程分支基于變換器[38]的結構實現,因為變換器擅長通過全局自注意力機制捕獲長程依賴關系,這在許多高級[10, 16, 21, 30, 46, 57, 58]和低級任務[6, 44]中已得到證明。
在長程分支中,我們首先將特征圖 FFF(由編碼器從輸入圖像 I∈RH×W×3I\in\mathbb{R}^{H\times W\times 3}I∈RH×W×3 中提取)劃分為 mmm 個特征塊,即 Fi∈Rp×p×C,i={1,...,m}F_{i}\in\mathbb{R}^{p\times p\times C},i=\{1,...,m\}Fi?∈Rp×p×C,i={1,...,m}。假設特征圖 FFF 的大小為 h×w×Ch\times w\times Ch×w×C,塊大小為 p×pp\times pp×p。那么有 m=hp×wpm=\frac{h}{p}\times\frac{w}{p}m=ph?×pw? 個特征塊覆蓋整個特征圖。
如圖 444 所示,我們的SNR感知變換器是基于塊的。它由多頭自注意力(MSA)模塊[38]和前饋網絡(FFN)[38]組成,兩者都包含兩個全連接層。變換器的輸出特征 F1,...,Fm\mathcal{F}_{1},...,\mathcal{F}_{m}F1?,...,Fm? 與輸入特征塊大小相同。我們將 F1,...,FmF_{1},...,F_{m}F1?,...,Fm? 展平為一維特征,并執行以下計算:
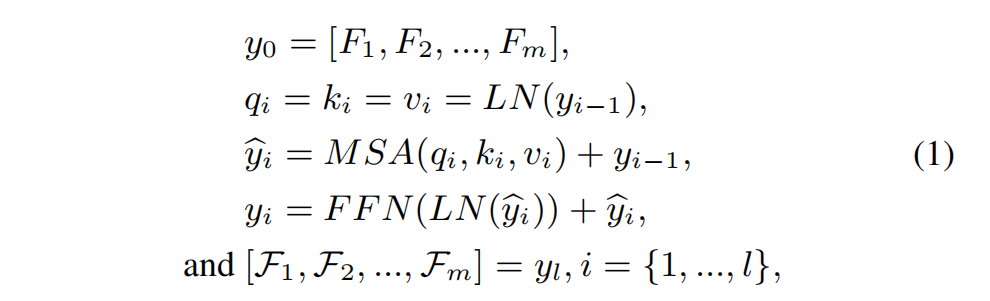
其中 LNLNLN 表示層歸一化;yiy_{i}yi? 表示第 iii 個變換器塊的輸出;MSAMSAMSA 表示我們的SNR感知多頭自注意力模塊(見圖5),將在第3.3節詳述;qiq_{i}qi?、kik_{i}ki? 和 viv_{i}vi? 分別表示第 iii 個多頭自注意力模塊中的查詢(query)、鍵(key)和值(value)向量;lll 表示變換器中的層數。變換后的特征 F1,...,Fm\mathcal{F}_{1},...,\mathcal{F}_{m}F1?,...,Fm? 可以合并形成2D特征圖 Fl\mathcal{F}_{l}Fl?(見圖4)。
基于SNR的空間變化特征融合
SNR圖。 如圖4所示,我們的框架首先估計一個SNR圖。僅給定單個輸入圖像 III,估計其中的噪聲量并準備一個干凈的 III 版本來確定每個像素的SNR值是困難且繁瑣的。類似于之前的無學習去噪方法[8, 1],我們將噪聲視為空間域中相鄰像素間的不連續過渡。噪聲分量可以建模為噪聲圖像與相關干凈圖像之間的距離。在本工作中,我們用它來估計 III 的SNR圖,并使其成為我們空間變化特征融合的有效先驗。給定 I∈RH×W×3I\in\mathbb{R}^{H\times W\times 3}I∈RH×W×3,我們首先計算其灰度圖 Ig∈RH×WI_{g}\in\mathbb{R}^{H\times W}Ig?∈RH×W,然后計算SNR圖 S∈RH×WS\in\mathbb{R}^{H\times W}S∈RH×W:
I^g=denoise(Ig),N=abs(Ig?I^g),S=I^g/N,\widehat{I}_{g}=denoise(I_{g}),\quad N=abs(I_{g}-\widehat{I}_{g}),\quad S= \widehat{I}_{g}/N,Ig?=denoise(Ig?),N=abs(Ig??Ig?),S=Ig?/N, (2)
其中 denoisedenoisedenoise 是一個無學習的去噪操作(實驗見第4.2和4.3節),例如局部像素平均;absabsabs 表示絕對值;N∈RH×WN\in\mathbb{R}^{H\times W}N∈RH×W 是估計的噪聲圖。盡管由于提取的噪聲不準確,得到的SNR值是近似的,但如我們大量實驗所驗證,使用這種SNR圖的框架仍然是有效的。
使用SNR圖進行空間變化特征融合。 如圖4所示,我們使用編碼器 E\mathcal{E}E 從輸入圖像 III 中提取特征 FFF。然后該特征分別由長程和短程分支處理,產生長程特征 Fl∈Rh×w×C\mathcal{F}_{l}\in\mathbb{R}^{h\times w\times C}Fl?∈Rh×w×C 和短程特征 Fs∈Rh×w×C\mathcal{F}_{s}\in\mathbb{R}^{h\times w\times C}Fs?∈Rh×w×C。為了自適應地結合這兩個特征,我們將SNR圖調整大小為 h×wh\times wh×w,將其值歸一化到范圍 [0,1][0,1][0,1],并將歸一化的SNR圖 S′S^{\prime}S′ 作為插值權重來融合 Fl\mathcal{F}_{l}Fl? 和 Fs\mathcal{F}_{s}Fs?:
F=Fs×S′+Fl×(1?S′),\mathcal{F}=\mathcal{F}_{s}\times S^{\prime}+\mathcal{F}_{l}\times(1-S^{\prime}),F=Fs?×S′+Fl?×(1?S′), (3)
其中 F∈Rh×w×C\mathcal{F}\in\mathbb{R}^{h\times w\times C}F∈Rh×w×C 是輸出特征,將被傳遞給解碼器以生成最終的輸出圖像。由于SNR圖中的值動態地揭示了輸入圖像不同區域的噪聲水平,這種融合可以自適應地結合局部(短程)和非局部(長程)圖像信息來生成 F\mathcal{F}F。
變換器中的SNR引導注意力
傳統變換器結構的局限性。 盡管傳統變換器可以捕獲非局部信息來增強圖像,但它們存在關鍵問題。在原始結構中,注意力是在所有塊之間計算的。為了增強一個像素,長程注意力可能來自任何圖像區域,而不管其信號和噪聲水平如何。事實上,極低SNR的區域主要由噪聲主導。因此,它們的信息是不準確的,會嚴重干擾圖像增強。在此,我們提出SNR引導的注意力來改進變換器在此特定任務中的表現。
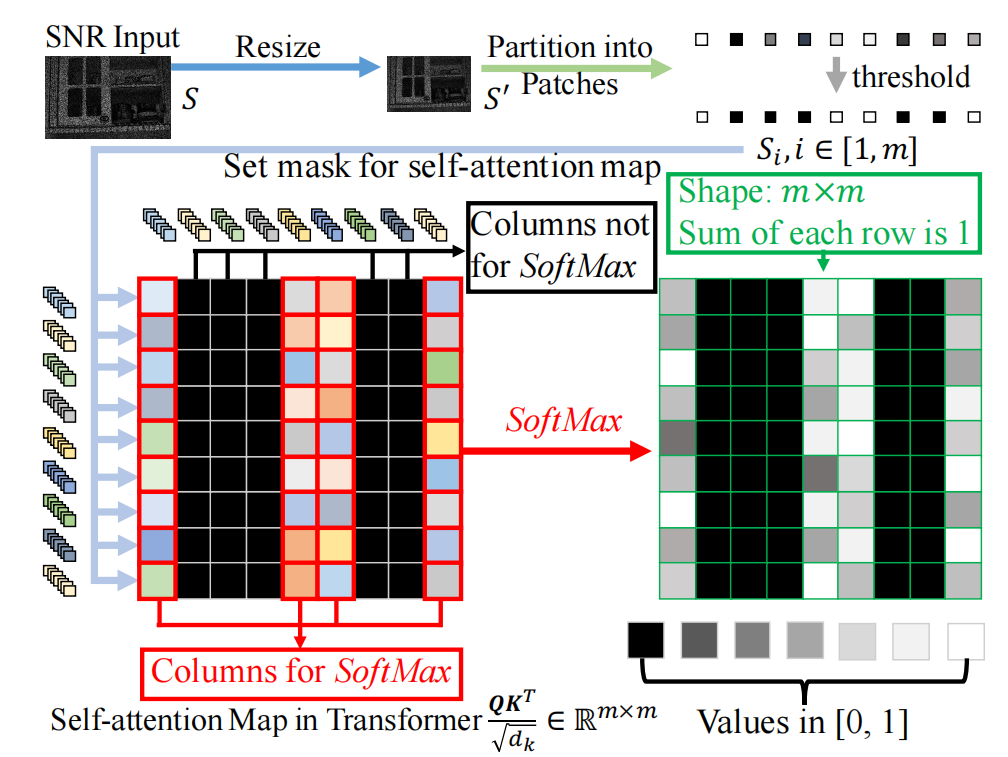
圖5: 圖解:變換器中的SNR引導注意力。黑色方塊表示被SoftMax忽略的元素;彩色方塊表示特征令牌之間的相似度。它們用于SoftMax計算。
SNR感知變換器。 圖5展示了我們的SNR感知變換器及其新的自注意力模塊。給定輸入圖像 I∈RH×W×3I\in\mathbb{R}^{H\times W\times 3}I∈RH×W×3 和相關的SNR圖 S∈RH×WS\in\mathbb{R}^{H\times W}S∈RH×W,我們首先將 SSS 調整為 S′∈Rh×wS^{\prime}\in\mathbb{R}^{h\times w}S′∈Rh×w 以匹配特征圖 FFF 的大小。然后我們按照將 FFF 分塊的方式將 S′S^{\prime}S′ 劃分為 mmm 個塊,并計算每個塊的平均值,即 Si∈R1,i={1,...,m}S_{i}\in\mathbb{R}^{1},i=\{1,...,m\}Si?∈R1,i={1,...,m}。我們將這些值打包成向量 S∈Rm\mathcal{S}\in\mathbb{R}^{m}S∈Rm。它在變換器的注意力計算中充當掩碼(mask),可以避免來自極低SNR圖像區域的消息在變換器中傳播(見圖5)。向量 S\mathcal{S}S 的第 iii 個元素的掩碼值表示為:
Si={0,Si<s1,Si≥s,?i={1,...,m},\mathcal{S}_{i}=\begin{cases}0,&S_{i}<s\\ 1,&S_{i}\geq s\end{cases},\,i=\{1,...,m\},Si?={0,1,?Si?<sSi?≥s?,i={1,...,m}, (4)
其中 sss 是一個閾值。接下來,我們將 S\mathcal{S}S 堆疊 mmm 份以形成矩陣 S′∈Rm×m\mathcal{S}^{\prime}\in\mathbb{R}^{m\times m}S′∈Rm×m。假設多頭自注意力(MSAMSAMSA)模塊(式(1))的頭數為 BBB,則變換器第 iii 層中第 bbb 個頭自注意力的計算 Attentioni,bAttention_{i,b}Attentioni,b? 公式化為:
Qi,b=qiWbq,Ki,b=kiWbk,?Vi,b=viWbv,and\mathbf{Q}_{i,b}=q_{i}W^{q}_{b},\mathbf{K}_{i,b}=k_{i}W^{k}_{b}, \,\mathbf{V}_{i,b}=v_{i}W^{v}_{b},\qquad\text{and}Qi,b?=qi?Wbq?,Ki,b?=ki?Wbk?,Vi,b?=vi?Wbv?,and (5)
Attentioni,b(Qi,b,Ki,b,Vi,b)=Softmax(Qi,bKi,bTdk+(1?S′)σ)Vi,b,Attention_{i,b}(\mathbf{Q}_{i,b},\mathbf{K}_{i,b},\mathbf{V}_{i ,b})=\text{Softmax}(\frac{\mathbf{Q}_{i,b}\mathbf{K}_{i,b}^{T}}{\sqrt{d_{k}}}+(1- \mathcal{S}^{\prime})\sigma)\mathbf{V}_{i,b},Attentioni,b?(Qi,b?,Ki,b?,Vi,b?)=Softmax(dk??Qi,b?Ki,bT??+(1?S′)σ)Vi,b?, (6)
其中 qiq_{i}qi?、kik_{i}ki?、vi∈Rm×(p×p×C)v_{i}\in\mathbb{R}^{m\times(p\times p\times C)}vi?∈Rm×(p×p×C) 是式(1)中的輸入2D特征;WbqW^{q}_{b}Wbq?、WbkW^{k}_{b}Wbk?、Wbv∈R(p×p×C)×CkW^{v}_{b}\in\mathbb{R}^{(p\times p\times C)\times C_{k}}Wbv?∈R(p×p×C)×Ck? 表示第 bbb 個頭的投影矩陣;Qi,b\mathbf{Q}_{i,b}Qi,b?、Ki,b\mathbf{K}_{i,b}Ki,b?、Vi,b∈Rm×Ck\mathbf{V}_{i,b}\in\mathbb{R}^{m\times C_{k}}Vi,b?∈Rm×Ck? 分別是注意力計算中的查詢、鍵和值特征。
Softmax() 和 Attentioni,b()Attention_{i,b}()Attentioni,b?() 的輸出形狀分別是 m×mm\times mm×m 和 m×Ckm\times C_{k}m×Ck?,其中 CkC_{k}Ck? 是自注意力計算中的通道數。此外,dk\sqrt{d_{k}}dk?? 用于歸一化,σ\sigmaσ 是一個小的負標量 ?1e9-1e9?1e9。所有 BBB 個頭的輸出被拼接起來。所有值經過線性投影,產生變換器第 iii 層中 MSAMSAMSA 的最終輸出。這樣,我們確保長程注意力僅來自具有足夠SNR的圖像區域。
損失函數
數據流。 給定輸入圖像 III,我們首先應用帶有卷積層的編碼器提取特征 FFF。編碼器中的每個階段包含一個卷積層和LeakyReLU[47]的堆疊。編碼器后使用殘差卷積塊。然后,我們將 FFF 前向傳播到長程和短程分支以產生特征 Fl\mathcal{F}_{l}Fl? 和 Fs\mathcal{F}_{s}Fs?。最后,我們將 Fl\mathcal{F}_{l}Fl? 和 Fs\mathcal{F}_{s}Fs? 融合成 F\mathcal{F}F,并使用解碼器(與編碼器對稱)將 F\mathcal{F}F 轉換為殘差 RRR。最終的輸出圖像 I′I^{\prime}I′ 是 I′=I+RI^{\prime}=I+RI′=I+R。
損失項。 我們使用兩個重建損失項來訓練我們的框架,即Charbonnier損失[25]和感知損失(perceptual loss)。Charbonnier損失寫為:
Lr=∥I′?I^∥2+?2,L_{r}=\sqrt{\|I^{\prime}-\widehat{I}\|_{2}+\epsilon^{2}},Lr?=∥I′?I∥2?+?2?, (7)
其中 I^\widehat{I}I 是真實值(ground truth),在所有實驗中 ?\epsilon? 設置為 10?310^{-3}10?3。感知損失使用 L1L_{1}L1? 損失比較 I^\widehat{I}I 和 I′I^{\prime}I′ 之間的VGG特征距離:
Lvgg=∥Φ(I′)?Φ(I^)∥1,L_{vgg}=\|\Phi(I^{\prime})-\Phi(\widehat{I})\|_{1},Lvgg?=∥Φ(I′)?Φ(I)∥1?, (8)
其中 Φ()\Phi()Φ() 是從VGG網絡[37]中提取特征的操作。總體損失函數是:
L=Lr+λLvgg,L=L_{r}+\lambda L_{vgg},L=Lr?+λLvgg?, (9)
其中 λ\lambdaλ 是一個超參數。
4 實驗
數據集和實現細節
我們在幾個數據集上評估我們的框架,這些數據集在低光照圖像區域可觀察到噪聲。它們是LOL (v1 & v2) [45, 53]、SID [5]、SMID [4] 和 SDSD [39]。
LOL在v1和v2版本中都有明顯噪聲。LOL-v1 [45]包含485對低光/正常光圖像用于訓練,15對用于測試。每對包括一個低光照輸入圖像和一個關聯的曝光良好的參考圖像。LOL-v2 [53]分為LOL-v2-real和LOL-v2-synthetic。LOL-v2-real包含689對低光/正常光圖像用于訓練,100對用于測試。大多數低光照圖像是通過改變曝光時間和ISO(其他相機參數固定)收集的。LOL-v2-synthetic是通過分析RAW格式的照度分布創建的。
對于SID和SMID,每個輸入樣本是一對短曝光和長曝光圖像。SID和SMID都有嚴重的噪聲,因為低光照圖像是在極暗環境下捕獲的。對于SID,我們使用索尼相機捕獲的子集,并遵循SID提供的腳本,使用rawpy的默認ISP將低光照圖像從RAW轉換到RGB。對于SMID,我們使用其全部圖像,并將RAW數據也轉換為RGB,因為我們的工作在RGB域中進行低光照圖像增強。我們根據[4]的設置劃分訓練和測試集。
最后,我們采用SDSD數據集[39](靜態版本)進行評估。它包含一個室內子集和一個室外子集,兩者都提供低光和正常光圖像對。
我們在PyTorch[34]中實現我們的框架,并在配備2080Ti GPU的PC上進行訓練和測試。我們使用高斯分布隨機初始化網絡參數從頭開始訓練我們的方法,并采用標準數據增強,例如垂直和水平翻轉。我們框架的編碼器有三個卷積層(步長分別為1, 2, 和2),編碼器后有一個殘差塊。解碼器與編碼器對稱,上采樣機制使用像素洗牌層(pixel shuffle layer)[36]實現。為了最小化損失,我們采用Adam[23]優化器,動量設置為0.9。
與當前方法的比較
我們將我們的方法與一系列豐富的低光照圖像增強SOTA方法進行比較,包括Dong [9]、LIME [15]、MF [11]、SRIE [12]、BIMEF [55]、DRD [45]、RRM [28]、SID [5]、DeepUPE [40]、KIND [61]、DeepLPF [33]、FIDE [48]、LPNet [26]、MIR-Net [59]、RF [24]、3DLUT [60]、A3DLUT [42]、Band [52]、EG [20]、Retinex [29] 和 Sparse [53]。此外,我們將我們的框架與兩種用于低級任務的近期變換器結構進行了比較,即IPT [6]和Uformer [44]。
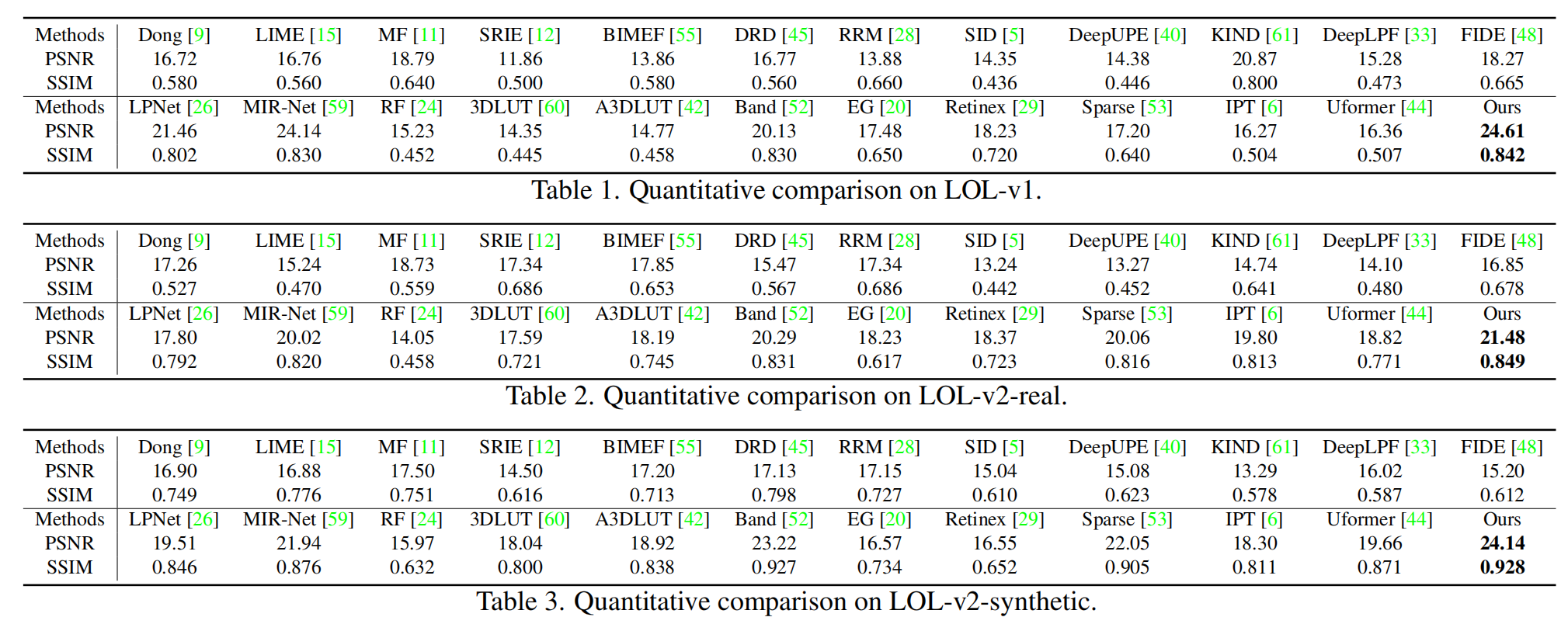
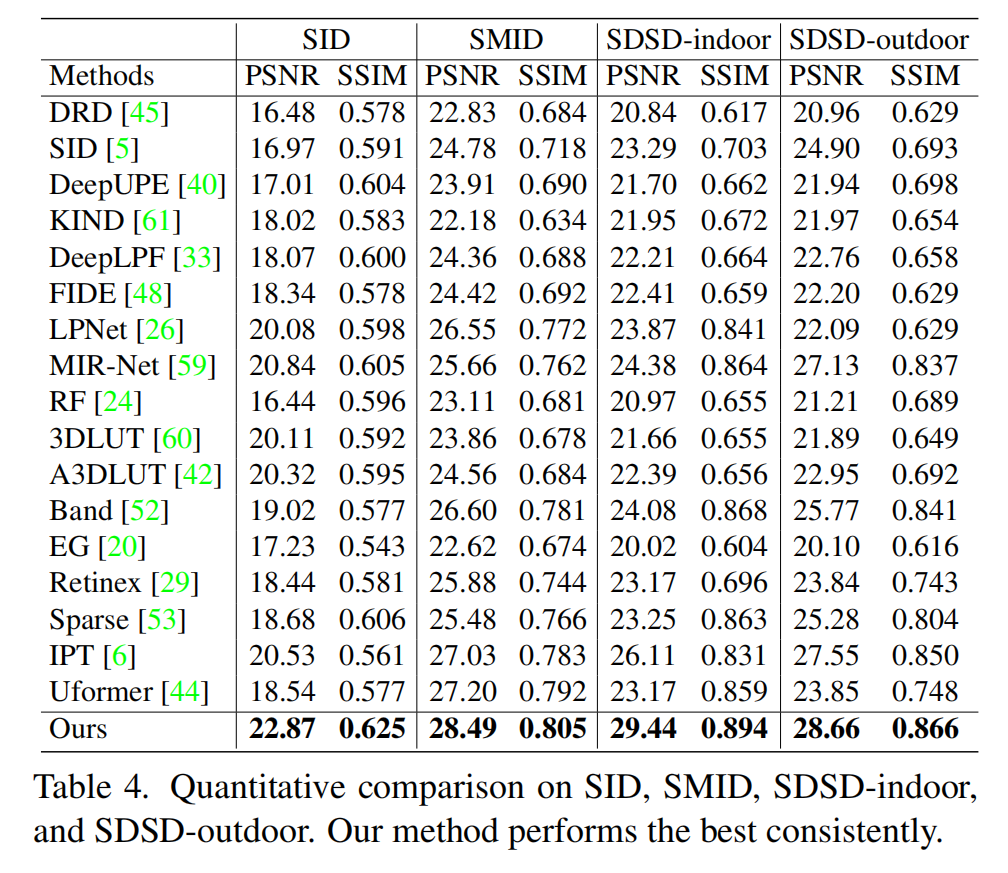
定量分析。 我們采用峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和結構相似性指數(Structural Similarity Index, SSIM)[43]進行評估。通常,較高的SSIM意味著結果中具有更多高頻細節和結構。表1-3顯示了在LOL-v1、LOL-v2-real和LOL-v2-synthetic上的比較結果。我們的方法超越了所有基線。請注意,這些數字要么來自各自的論文,要么通過運行各自的公開代碼獲得。在LOL-v1上,我們的方法(24.61/0.842)也優于[22](22.81/0.827)和[62](21.71/0.834)。表4比較了在SID、SMID、SDSD-indoor和SDSD-outdoor上的方法。我們的方法取得了最佳性能。
定性分析。 首先,我們在圖6(頂行)中展示視覺樣本,將我們的方法與在LOL-v1上取得最佳PSNR性能的基線進行比較。我們的結果顯示出更好的視覺質量,具有更高的對比度、更精確的細節、顏色一致性和更好的亮度。圖6還展示了在LOL-v2-real和LOL-v2-synthetic上的視覺比較。雖然這些數據集中的原始圖像有明顯的噪聲和弱光照,但我們的方法仍然可以產生更真實的結果。此外,在具有復雜紋理的區域,我們的輸出展現出更少的視覺偽影。


噪聲嚴重的低光照圖像。圖7還展示了在SMID、SDSD-indoor和SDSD-outdoor上的視覺結果。這些結果也表明我們的方法在增強圖像亮度和揭示細節的同時抑制噪聲是有效的。
用戶研究。 我們進一步進行了有100名參與者的大規模用戶研究,以評估人類對我們方法和五種最強基線(根據在SID、SMID和SDSD上的平均PSNR選擇)增強由iPhone X或華為P30拍攝的低光照照片的感知效果。總共在多種環境(包括道路、公園、圖書館、學校、人像等)中拍攝了30張低光照照片,其中50%圖像像素的強度低于30%。
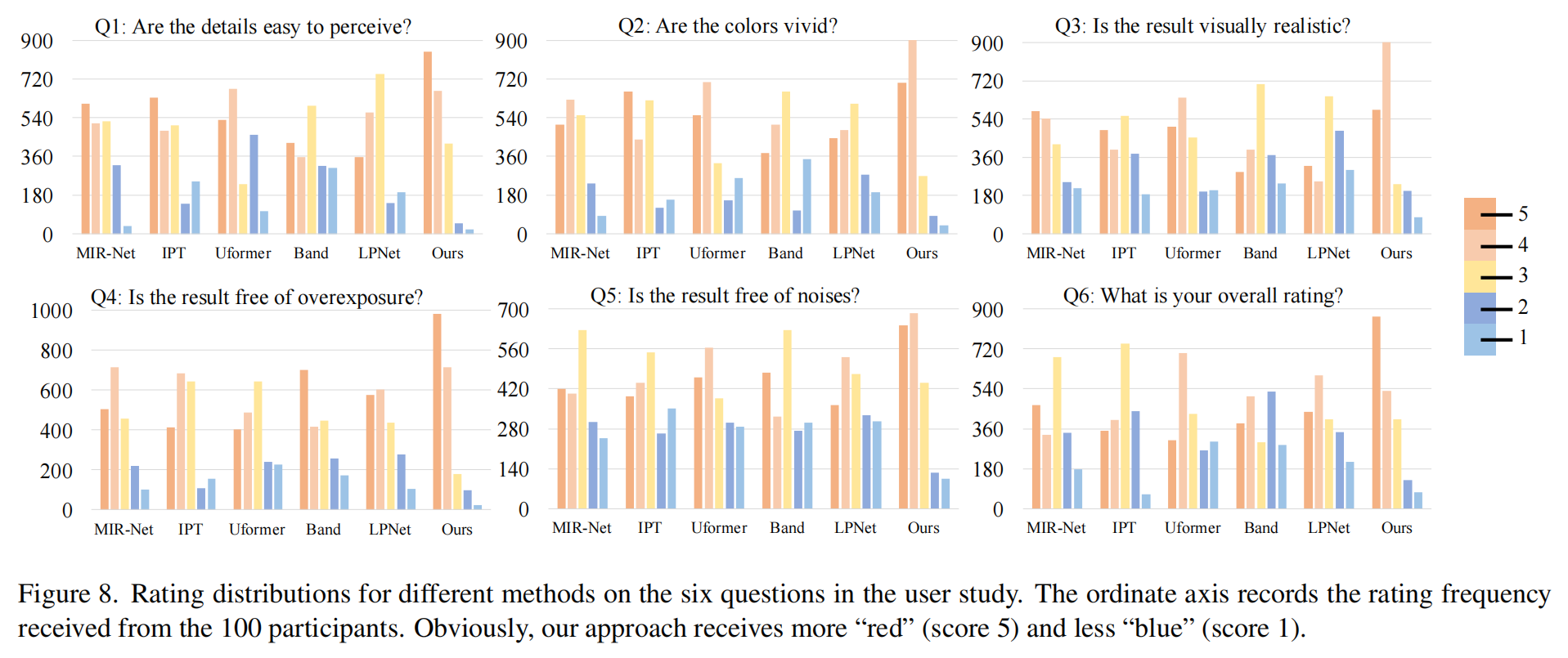
遵循[40]的設置,我們通過用戶對圖8所示的六個問題進行評分來評估結果,評分采用李克特量表(Likert scale),從1(最差)到5(最好)。所有方法都在SDSD-outdoor上訓練,因為[39]表明訓練好的模型可以有效地增強手機拍攝的低光照圖像。圖8報告了不同方法的評分分布,其中我們的方法獲得了更多的“紅色”(5分)和更少的“藍色”(1分)評分。此外,我們使用配對t檢驗(使用MS Excel中的T-TEST函數)對我們的方法與其他每種方法的評分進行了統計分析。在顯著性水平0.001下,所有t檢驗結果都具有統計顯著性,因為所有p值均小于0.001。
消融研究
我們考慮了四種消融設置,分別從我們的框架中移除不同的組件。

- “Ours w/o LLL” 移除了長程分支,因此框架只有卷積操作。
- “Ours w/o SSS” 移除了短程分支,保留了完整的長程分支和SNR引導的注意力。
- “Ours w/o SASASA” 在"Ours w/o SSS"的基礎上進一步移除了SNR引導的注意力,只保留了最深層的基本變換器結構。
- “Ours w/o AAA” 移除了SNR引導的注意力。
我們在所有七個數據集上進行了消融研究。表5總結了結果。與所有消融設置相比,我們的完整設置產生了最高的PSNR和SSIM。“Ours w/o LLL”、“Ours w/o SSS” 和 “Ours w/o SASASA” 展示了單獨使用卷積操作或變換器結構的缺點,從而證明了聯合利用短程(卷積模型)和長程(變換器結構)操作的有效性。結果還顯示了 “SNR引導注意力”(“Ours w/o AAA” vs. “Ours”)和 “SNR引導融合”(“Ours w/o SSS” vs. “Ours”)的效果。
SNR先驗的影響
輸入我們框架的SNR是通過對輸入幀應用無學習的去噪操作(式(2))獲得的。在所有實驗中,考慮到其速度,我們采用局部均值作為去噪操作。在本節中,我們分析采用其他操作(包括非局部均值[1]和BM3D[8])時的影響。圖9顯示了結果,表明我們的框架對獲取SNR輸入的策略不敏感。所有這些結果都優于基線。

5 結論
我們提出了一個新穎的SNR感知框架,該框架聯合利用短程和長程操作,以空間變化的方式動態增強像素。采用SNR先驗來指導特征融合。SNR感知變換器通過一個新的自注意力模塊構建。包括用戶研究在內的大量實驗表明,使用相同的網絡結構,我們的框架在代表性基準數據集上始終取得最佳性能。
我們未來的工作是探索其他語義信息來增強空間變化機制。此外,我們計劃通過同時考慮時域和空域變化操作,將我們的方法擴展到處理低光照視頻。另一個方向是探索生成方法[13, 32]來處理低光照圖像中接近黑色的區域。
的詳解、常見場景、常見問題及最佳解決方案的綜合指南)

![[leetcode] 位運算](http://pic.xiahunao.cn/[leetcode] 位運算)
函數,eval()函數,include)





)




 —— 仿真環境搭建(以Ubuntu 22.04,ROS2 Humble 為例))
)



