文章目錄
- 前言-官網鏈接
- 一、時序數據管理的時代挑戰
- 二、時序數據庫選型的六大核心維度
- 1. 數據模型設計
- 2. 寫入與查詢性能
- 3. 存儲效率
- 4. 系統擴展性
- 5. 生態兼容性
- 6. 運維復雜度
- 三、IoTDB的技術架構解析
- 1. 存儲引擎創新
- 2. 計算引擎優勢
- 3. 分布式架構設計
- 四、行業解決方案對比
- 1. 能源電力場景
- 2. 智能制造場景
- 3. 對比國外產品
- 五、選型實踐建議
- 六、應用編程示意
- Java
- Python
- C++
- Go
- 七、未來發展趨勢
- 結語
前言-官網鏈接
下載鏈接:https://iotdb.apache.org/zh/Download/
企業版官網鏈接:https://timecho.com
時序數據管理已成為工業物聯網、智能制造、能源電力等領域的核心技術需求。面對海量設備產生的時序數據洪流,企業如何選擇合適的時序數據庫?本文將從大數據視角出發,系統分析時序數據庫選型的關鍵維度,并重點解析Apache IoTDB及其商業版TimechoDB的獨特價值。

一、時序數據管理的時代挑戰
隨著工業4.0和物聯網技術的快速發展,全球時序數據呈現爆炸式增長。據IDC預測,到2025年,全球物聯網設備產生的數據量將達到79.4ZB,其中超過60%為時序數據。這種數據形態具有顯著特點:
- 高頻采集:工業傳感器通常以毫秒級頻率產生數據
- 維度豐富:單臺設備可能包含數百個監測指標
- 嚴格有序:時間戳是數據的核心維度
- 價值密度低:原始數據中僅有少量異常片段具有分析價值
傳統關系型數據庫在處理這類數據時面臨三大困境:寫入吞吐量不足、存儲成本高昂、查詢效率低下。這促使專門優化的時序數據庫(Time-Series Database, TSDB)成為技術市場的剛需。
二、時序數據庫選型的六大核心維度
1. 數據模型設計
優秀的時序數據庫需要提供符合工業場景的數據建模能力。IoTDB采用"設備-測點"的層級數據模型,天然匹配工業設備的管理體系。其樹狀結構支持:
// 示例:IoTDB的數據建模方式
CREATE TIMESERIES root.factory.d1.sensor1 WITH DATATYPE=FLOAT, ENCODING=RLE
CREATE TIMESERIES root.factory.d1.sensor2 WITH DATATYPE=INT32, ENCODING=TS_2DIFF
這種模型相比InfluxDB的tag-set模型更貼近設備管理實際,比TimescaleDB的關系模型更輕量化。
2. 寫入與查詢性能
工業場景對性能有嚴苛要求:
- 寫入吞吐:單節點應達到百萬級數據點/秒
- 查詢延遲:簡單查詢應在毫秒級響應
測試數據顯示,IoTDB在標準硬件環境下可實現:
- 單機寫入:150萬數據點/秒
- 集群寫入:線性擴展至千萬級
- 時間窗口查詢:百億數據亞秒響應
3. 存儲效率
時序數據的壓縮能力直接影響總擁有成本(TCO)。IoTDB通過以下技術創新實現超高壓縮比:
- 自適應編碼算法(RLE, Gorilla, TS-2DIFF等)
- 列式存儲結構
- 多級壓縮策略
實際案例顯示,某風電企業使用IoTDB后,存儲空間僅為原方案的1/20,年節省存儲成本超300萬元。
4. 系統擴展性
從邊緣到云端的全場景支持成為現代企業的剛需。IoTDB提供獨特的"端-邊-云"協同架構:
[邊緣設備] --低延遲--> [邊緣IoTDB] --異步同步--> [云端IoTDB集群]
這種架構既保證了現場控制的實時性,又滿足中心化分析需求,相比Druid、ClickHouse等方案更具靈活性。
5. 生態兼容性
與企業現有技術棧的無縫集成至關重要。IoTDB提供:
- 大數據生態:Hadoop、Spark、Flink連接器
- 可視化工具:Grafana、Superset原生支持
- 工業協議:OPC UA、Modbus、MQTT適配器
6. 運維復雜度
我們調研發現,60%的時序數據庫項目失敗源于運維復雜度。IoTDB通過以下設計降低門檻:
- 類SQL語法(降低學習成本)
- 一體化監控平臺(內置300+指標)
- 智能調參工具(自動優化內存/線程配置)
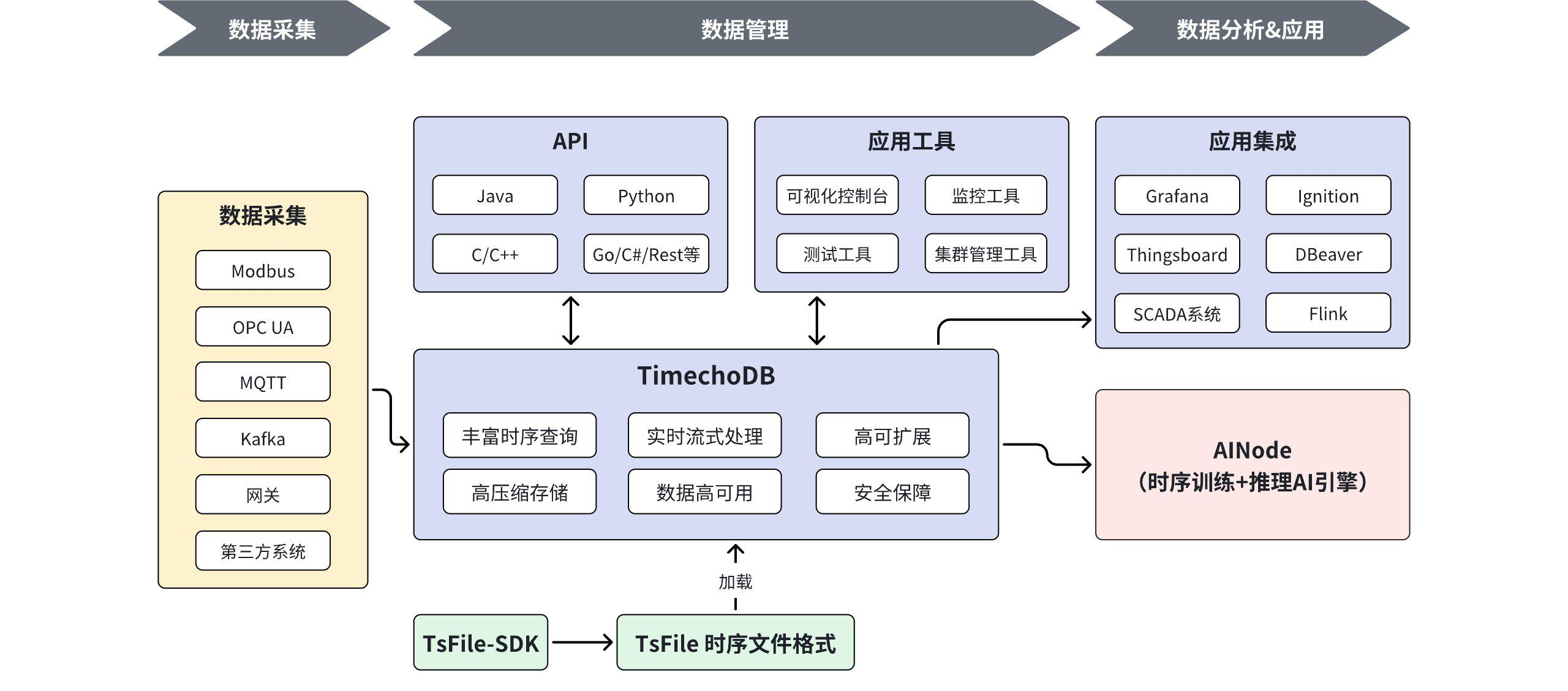
三、IoTDB的技術架構解析
1. 存儲引擎創新
IoTDB獨創的TsFile格式實現存儲效率突破:
- 分層存儲:熱數據SSD/冷數據HDD自動遷移
- 自適應索引:根據查詢模式動態調整索引策略
- 時間分區:支持按年/月/日自動分區
(圖示:元數據層+數據層+索引層的三級存儲結構)
2. 計算引擎優勢
- 流批一體:相同SQL既可查詢歷史數據,也能處理實時流
- 原生計算:內置100+時序專用函數(如滑動窗口、趨勢分析)
- AI集成:支持在庫內執行時序預測、異常檢測
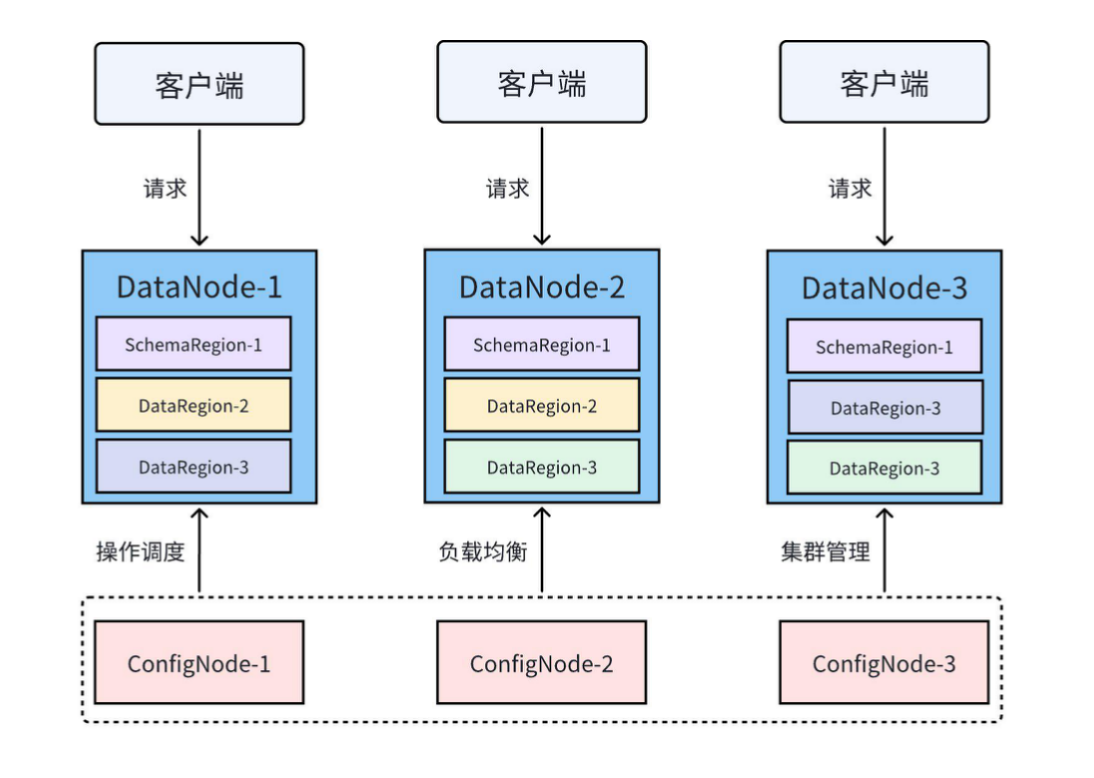
3. 分布式架構設計
IoTDB集群采用獨特的3C3D架構:
- ConfigNode:負責元數據管理(3節點確保高可用)
- DataNode:處理數據存儲與查詢(可線性擴展)
這種設計相比InfluxDB的sharding方案更易管理,比TimescaleDB的PG擴展方案性能更高。
四、行業解決方案對比
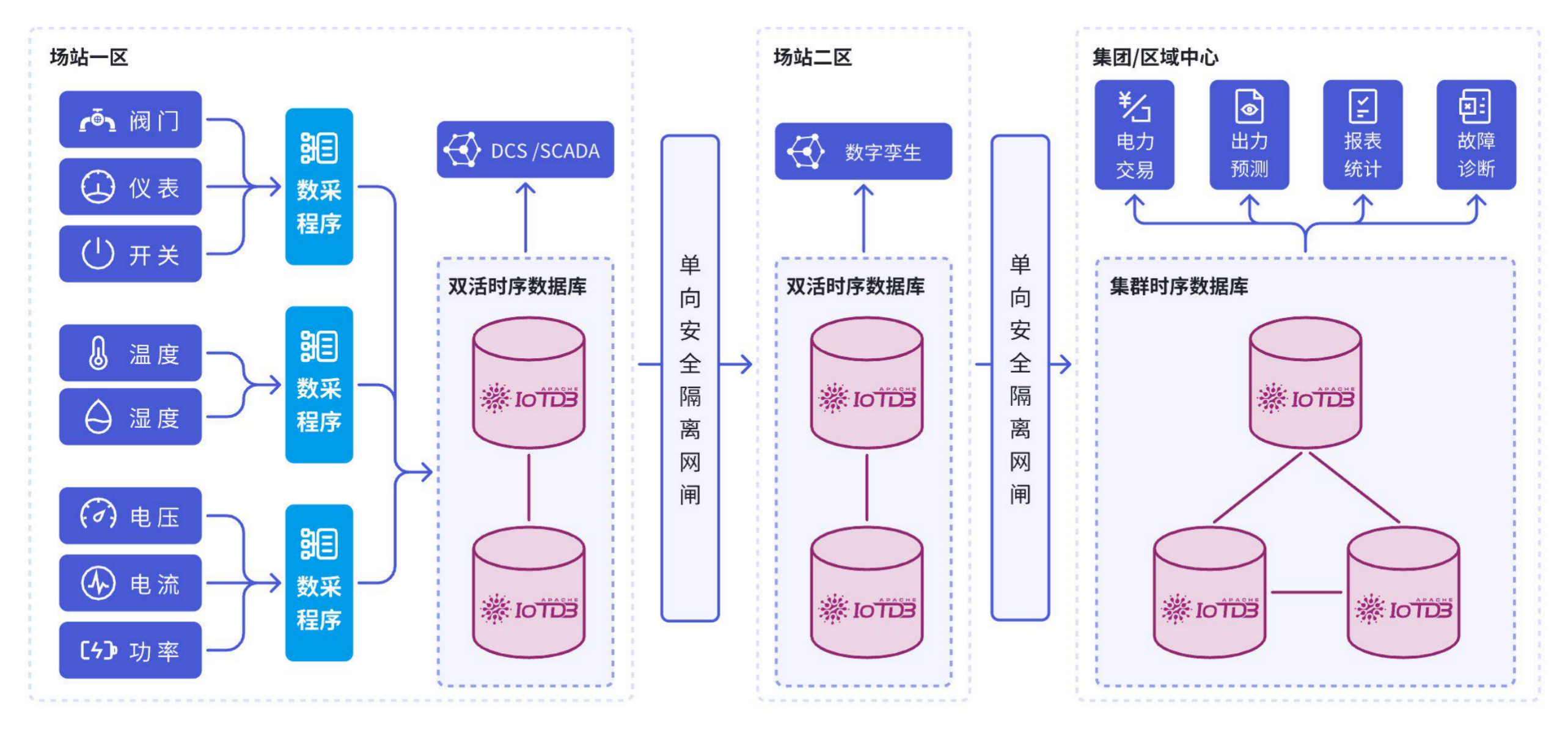
1. 能源電力場景
某省級電網采用IoTDB后實現:
- 采集點規模:200萬+
- 日新增數據:50TB
- 查詢性能:故障追溯從小時級降至秒級
關鍵優勢:網閘穿透、斷點續傳等工業特性
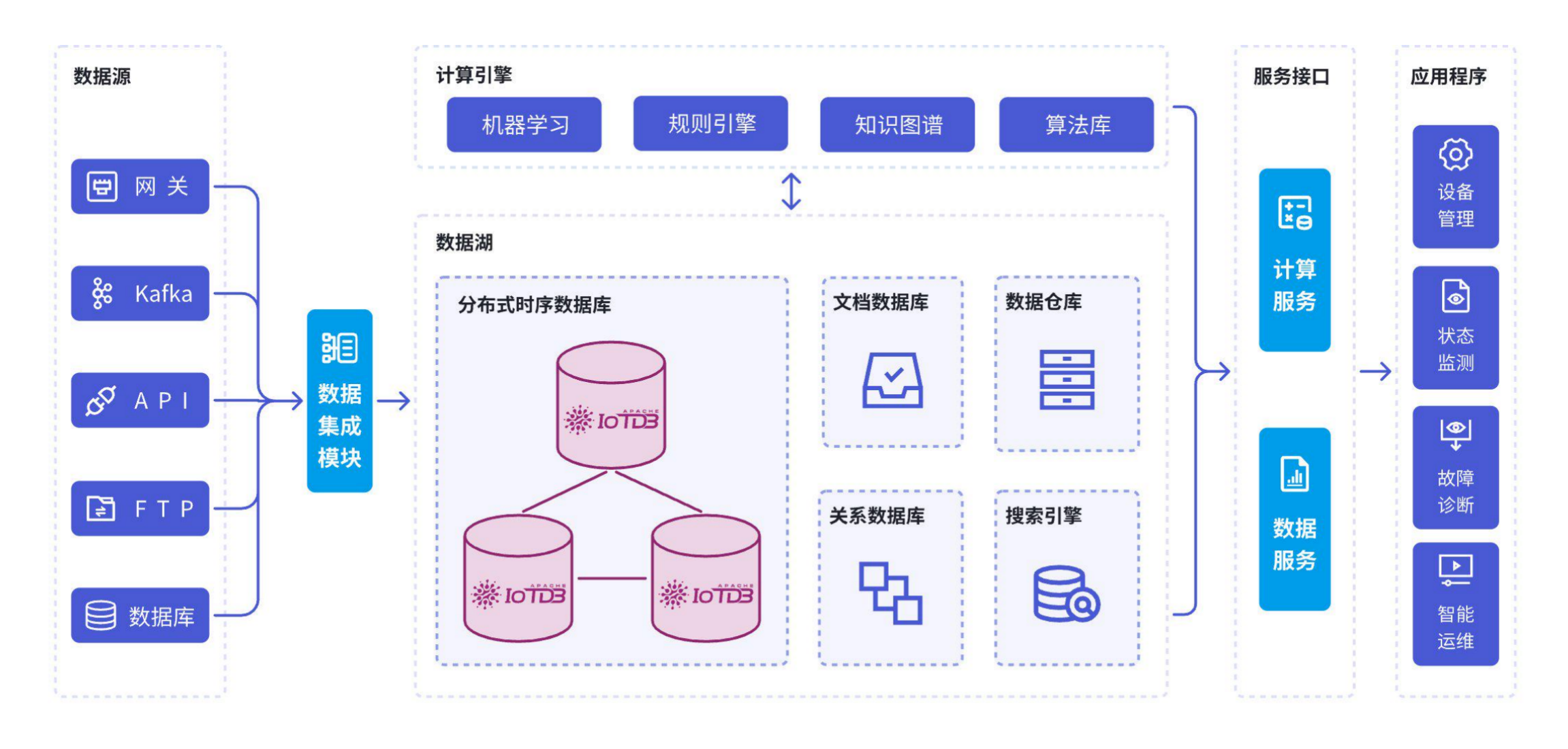
2. 智能制造場景
汽車工廠應用案例:
- 設備數量:5000+
- 采樣頻率:100ms
- 存儲成本:降低82%
核心價值:邊緣預處理減少90%網絡傳輸
3. 對比國外產品
| 維度 | InfluxDB | TimescaleDB | IoTDB |
|---|---|---|---|
| 壓縮比 | 5-10x | 3-5x | 15-20x |
| 單機寫入 | 50萬點/秒 | 30萬點/秒 | 150萬點/秒 |
| 工業協議 | 需插件 | 需插件 | 原生支持 |
| 國產化 | 無認證 | 無認證 | 全棧適配 |
五、選型實踐建議
-
需求分析階段
- 評估數據規模(設備數×測點數×頻率)
- 明確查詢模式(實時監控/歷史分析)
- 確定SLA要求(可用性、延遲)
-
概念驗證(POC)要點
- 測試真實數據集的壓縮率
- 模擬峰值寫入壓力
- 驗證關鍵查詢性能
-
部署策略
- 小規模試點→逐步擴展
- 建立多級存儲策略
- 規劃備份恢復方案
-
長期演進
- 關注時序數據分析需求
- 預留AI集成能力
- 考慮多云部署可能性
六、應用編程示意
Java
package org.apache.iotdb;import org.apache.iotdb.isession.SessionDataSet;
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;import java.util.ArrayList;
import java.util.List;public class SessionExample {private static Session session;public static void main(String[] args)throws IoTDBConnectionException, StatementExecutionException {session =new Session.Builder().host("172.0.0.1").port(6667).username("root").password("root").build();session.open(false);List<MeasurementSchema> schemaList = new ArrayList<>();schemaList.add(new MeasurementSchema("s1", TSDataType.FLOAT));schemaList.add(new MeasurementSchema("s2", TSDataType.FLOAT));schemaList.add(new MeasurementSchema("s3", TSDataType.FLOAT));Tablet tablet = new Tablet("root.db.d1", schemaList, 10);tablet.addTimestamp(0, 1);tablet.addValue("s1", 0, 1.23f);tablet.addValue("s2", 0, 1.23f);tablet.addValue("s3", 0, 1.23f);tablet.rowSize++;session.insertTablet(tablet);tablet.reset();try (SessionDataSet dataSet = session.executeQueryStatement("select ** from root.db")) {while (dataSet.hasNext()) {System.out.println(dataSet.next());}}session.close();}
}Python
from iotdb.Session import Session
from iotdb.utils.IoTDBConstants import TSDataType
from iotdb.utils.Tablet import Tabletip = "127.0.0.1"
port = "6667"
username = "root"
password = "root"
session = Session(ip, port, username, password)
session.open(False)measurements = ["s_01", "s_02", "s_03", "s_04", "s_05", "s_06"]
data_types = [TSDataType.BOOLEAN,TSDataType.INT32,TSDataType.INT64,TSDataType.FLOAT,TSDataType.DOUBLE,TSDataType.TEXT,
]
values = [[False, 10, 11, 1.1, 10011.1, "test01"],[True, 100, 11111, 1.25, 101.0, "test02"],[False, 100, 1, 188.1, 688.25, "test03"],[True, 0, 0, 0, 6.25, "test04"],
]
timestamps = [1, 2, 3, 4]
tablet = Tablet("root.db.d_03", measurements, data_types, values, timestamps
)
session.insert_tablet(tablet)with session.execute_statement("select ** from root.db"
) as session_data_set:while session_data_set.has_next():print(session_data_set.next())session.close()C++
#include "Session.h"
#include <iostream>
#include <string>
#include <vector>
#include <sstream>int main(int argc, char **argv) {Session *session = new Session("127.0.0.1", 6667, "root", "root");session->open();std::vector<std::pair<std::string, TSDataType::TSDataType>> schemas;schemas.push_back({"s0", TSDataType::INT64});schemas.push_back({"s1", TSDataType::INT64});schemas.push_back({"s2", TSDataType::INT64});int64_t val = 0;Tablet tablet("root.db.d1", schemas, /*maxRowNum=*/ 10);tablet.rowSize++;tablet.timestamps[0] = 0;val=100; tablet.addValue(/*schemaId=*/ 0, /*rowIndex=*/ 0, /*valAddr=*/ &val);val=200; tablet.addValue(/*schemaId=*/ 1, /*rowIndex=*/ 0, /*valAddr=*/ &val);val=300; tablet.addValue(/*schemaId=*/ 2, /*rowIndex=*/ 0, /*valAddr=*/ &val);session->insertTablet(tablet);tablet.reset();std::unique_ptr<SessionDataSet> res = session->executeQueryStatement("select ** from root.db");while (res->hasNext()) {std::cout << res->next()->toString() << std::endl;}res.reset();session->close();delete session;return 0;
}Go
package mainimport ("fmt""log""github.com/apache/iotdb-client-go/client"
)func main() {config := &client.Config{Host: "127.0.0.1",Port: "6667",UserName: "root",Password: "root",}session := client.NewSession(config)if err := session.Open(false, 0); err != nil {log.Fatal(err)}defer session.Close() // close session at end of main()rowCount := 3tablet, err := client.NewTablet("root.db.d1", []*client.MeasurementSchema{{Measurement: "restart_count",DataType: client.INT32,Encoding: client.RLE,Compressor: client.SNAPPY,}, {Measurement: "price",DataType: client.DOUBLE,Encoding: client.GORILLA,Compressor: client.SNAPPY,}, {Measurement: "description",DataType: client.TEXT,Encoding: client.PLAIN,Compressor: client.SNAPPY,},}, rowCount)if err != nil {fmt.Errorf("Tablet create error:", err)return}timestampList := []int64{0, 1, 2}valuesInt32List := []int32{5, -99999, 123456}valuesDoubleList := []float64{-0.001, 10e5, 54321.0}valuesTextList := []string{"test1", "test2", "test3"}for row := 0; row < rowCount; row++ {tablet.SetTimestamp(timestampList[row], row)tablet.SetValueAt(valuesInt32List[row], 0, row)tablet.SetValueAt(valuesDoubleList[row], 1, row)tablet.SetValueAt(valuesTextList[row], 2, row)}session.InsertTablet(tablet, false)var timeoutInMs int64timeoutInMs = 1000sql := "select ** from root.db"dataset, err := session.ExecuteQueryStatement(sql, &timeoutInMs)defer dataset.Close()if err == nil {for next, err := dataset.Next(); err == nil && next; next, err = dataset.Next() {record, _ := dataset.GetRowRecord()fields := record.GetFields()for _, field := range fields {fmt.Print(field.GetValue(), "\t")}fmt.Println()}} else {log.Println(err)}
}七、未來發展趨勢
時序數據庫技術正在向三個方向演進:
- 智能化:內置時序預測、根因分析等AI能力
- 一體化:融合事務處理與實時分析(HTAP)
- 云原生化:深度整合K8s、Serverless等云技術
IoTDB在這些方向已取得突破:
- 最新版本集成TensorFlow/PyTorch運行時
- 支持混合負載隔離執行
- 提供K8s Operator簡化云部署
結語
時序數據庫選型是數字化轉型的關鍵決策。通過本文分析可見,IoTDB憑借其原生物聯網設計、卓越的存儲效率、完整的生態體系,已成為工業場景的理想選擇。特別是其商業版TimechoDB提供的企業級特性,如雙活部署、多級存儲、可視化工具等,能夠進一步降低運維復雜度,保障生產系統穩定運行。
建議企業在實際選型中,既要考慮當前需求,也要預留技術演進空間,選擇像IoTDB這樣兼具創新性和實用性的時序數據庫解決方案。


以pinia為中心的開發模板)



全面指南)

)









:Oracle DATE(7)到MySQL時間類型精度沖突解決方案)
