Leaf是美團點評公司基礎研發平臺推出的一個唯一ID生成器服務,其具備高可靠性、低延遲、全局唯一等特點,目前已經被廣泛應用于美團金融、美團外賣、美團酒旅等多個部門。Leaf根據不同業務的需求分別實現了Leaf-segment和Leaf-snowflake兩種方案,前者基于數據庫的自增主鍵,后者基于Snowflake算法。接下來介紹這兩種方案的技術原理。 需要注意的是,Leaf和前幾節介紹的幾種技術方案非常相似,只是多了一些思考和優化,這也是我們在本節中重點著墨的部分。
4.5.1 Leaf-segment 方案
Leaf-segment方案與4.4.2節介紹的批量緩存架構方案類似,只不過它沒有依賴數據庫的自增主鍵,而是在數據庫中為每個業務場景都記錄目前可用的唯一ID號段。具體的數據表設計如表4-1所示。

不同業務方的唯一ID需求用biz_tag字段區分,每個biz_tag的ID相互隔離。當某業務請求攜帶biz_tag訪問Leaf服務時,數據庫會通過執行如下語句生成唯一ID:
BEGIN
UPDATE table SET max_id = max_id + step WHERE biz_tag = xxx
SELECT tag, max_id, step FROM table WHERE biz_tag = xxx
COMMIT
比如在數據表中外賣業務方的biz tag為waimai_ordertag,此時max_id為10000, step 為2000,那么外賣業務方下次得到的唯一ID號段是10001-12000, max_id的值被更新為12000。
通過修改step字段值,可以方便地控制一個業務訪問數據庫的頻率:
-
如果step為1,則說明每次生成唯一ID時業務方都要訪問數據庫;
-
如果step為1000,則說明每用 完1000個唯一ID時,業務方才再次訪問數據庫。
美團技術團隊官網給出了Leaf-segment方案的大致架構圖,如圖4-14所示。
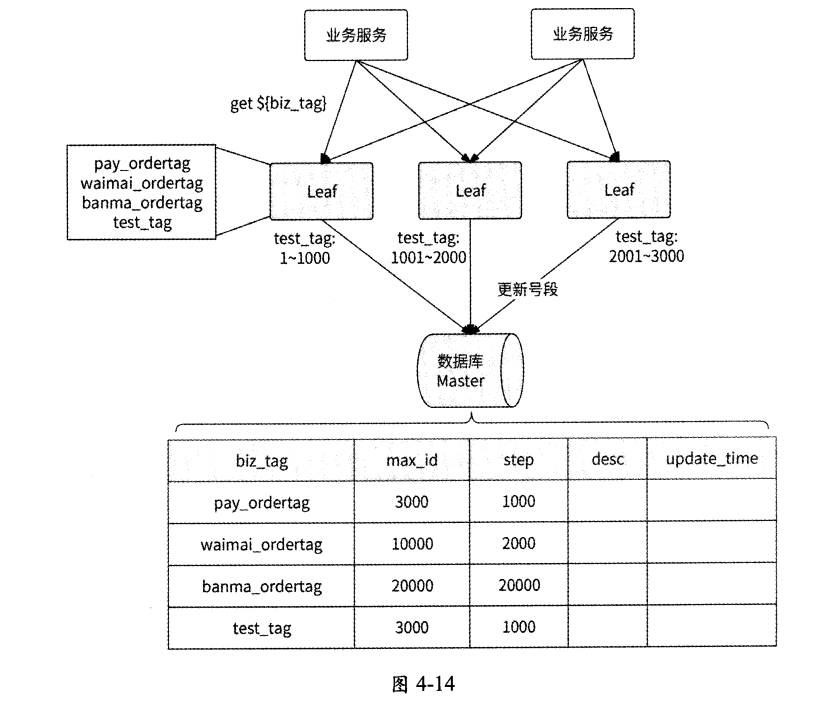
從架構圖中可以看到,Leaf-segment方案與4.4.2節介紹的批量緩存架構方案確實大同小異,服務實例在本地緩存一批可用的唯一ID號段供業務請求使用,當某業務請求發現唯一ID號段用完時,再從數據庫中批量獲取新的唯一ID號段。如果此時數據庫發生網絡抖動或慢查詢,則會導致訪問數據庫的業務請求被阻塞,整個服務的響應變慢。
Leaf-segment方案針對這個問題做了優化:當使用可用的唯一ID號段到達某個檢查點時,Leaf服務實例就異步地從數據庫中獲取下一個可用的唯一ID號段,而不需要等到唯一ID號段用完才訪問數據庫,這樣可以防止唯一ID號段用完時阻塞業務請求。
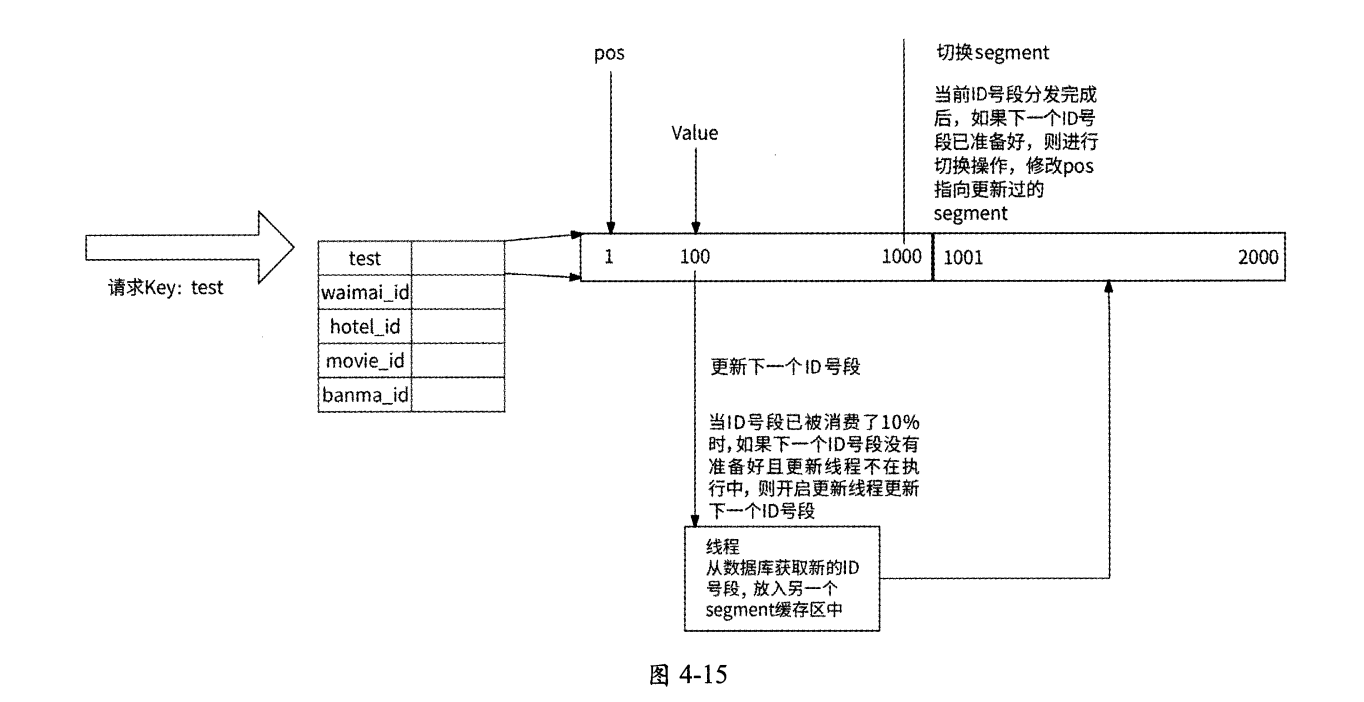
具體來說,Leaf服務實例內部有兩個唯一ID號段緩存區:
-
第一個緩存區用于對外提供服務,業務請求從這里獲取唯一ID;
-
第二個緩存區用于提前向數據庫加載下一個 可用的唯一 id號段。
當第一個緩存區已經下發10%可用的唯一ID時,Leaf服務實例將啟動一個線程異步訪問數據庫,并將獲取到的下一個可用的唯一ID號段保存到第二個緩存區。這樣一來,當某業務請求發現第一個緩存區中已無可用的唯一ID時,Leaf服務實例就直接切換到第二個緩存區繼續下發可用的唯一ID,如此循環往復,業務請求不會被阻塞在訪問數據庫的過程中。
這個技術優化的示意圖如圖4-15所示(參考自美團技術團隊官網)。
4.5.2 Leaf-snowflake方案
使用Leaf-segment方案可以生成趨勢遞增的唯一ID,但是ID值會反映實際的數據量,并不適用于訂單ID生成的場景。如果將此方案應用在訂單ID生成的場景中,則很容易被競品公司計算出訂單的總量,這等于把業務的數據表現直接實時暴露給其他公司。為了解決這個問題,美團點評公司提供了Leaf-snowflake方案,這個方案和4.3節介紹的基于時間戳的方案類似。
Leaf-snowflake方案在唯一ID的設計上完全沿用Snowflake算法,即使用1+41+10+12的方式組裝ID;至于worker ID的分配問題,Leaf snowflake方案借助了ZooKeeper持久順序節點的特性,每個Leaf服務實例都會在ZooKeeper的leaf_forever節點下注冊一個持久順序節點,將對應的順序數字作為worker ID。假設現在有4個服務實例注冊了持久順序節點,leaf_forever節點的結構可能如圖4-16所示。
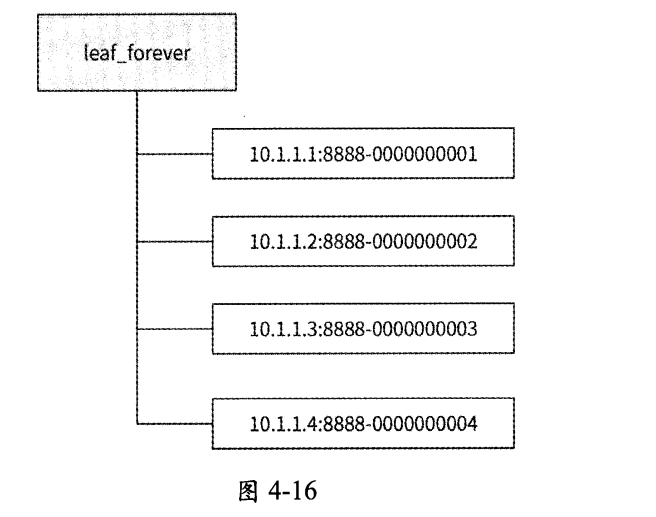
每個服務實例都攜帶IP地址和端口號在leaf_forever節點下注冊持久順序節點(格式為IP:port),然后ZooKeeper會自動生成一個自增序號作為每個順序節點的后綴,這個序號就可被分配作為實例的worker ID。Leaf-snowflake方案分配worker ID的流程如下。
- Leaf服務實例啟動時,連接ZooKeeper。
- 服務實例查詢leaf_forever節點是否存在。如果不存在,則跳至第4步,否則繼續。
- 服務實例讀取leaf_forever節點下的子節點列表,然后根據自身的IP地址和端口號遍歷子節點列表,查詢自己是否注冊過子節點。
- 如果未找到子節點,則實例在leaf_forever節點下創建子節點,將所得到的節點后綴序號作為worker ID。
- 如果找到子節點,則將此子節點的后綴序號取出作為worker ID。
- 獲取到worker ID后,Leaf服務實例就啟動成功了;否則,啟動失敗。
Leaf服務實例在獲取到worker ID后會將其保存到本地文件中,這樣可以做到對ZooKeeper的弱依賴。將來,如果ZooKeeper出現故障,而此時Leaf服務實例恰好重啟,那么就可以從本地文件中得到worker ID,避免了無法正常啟動的問題。
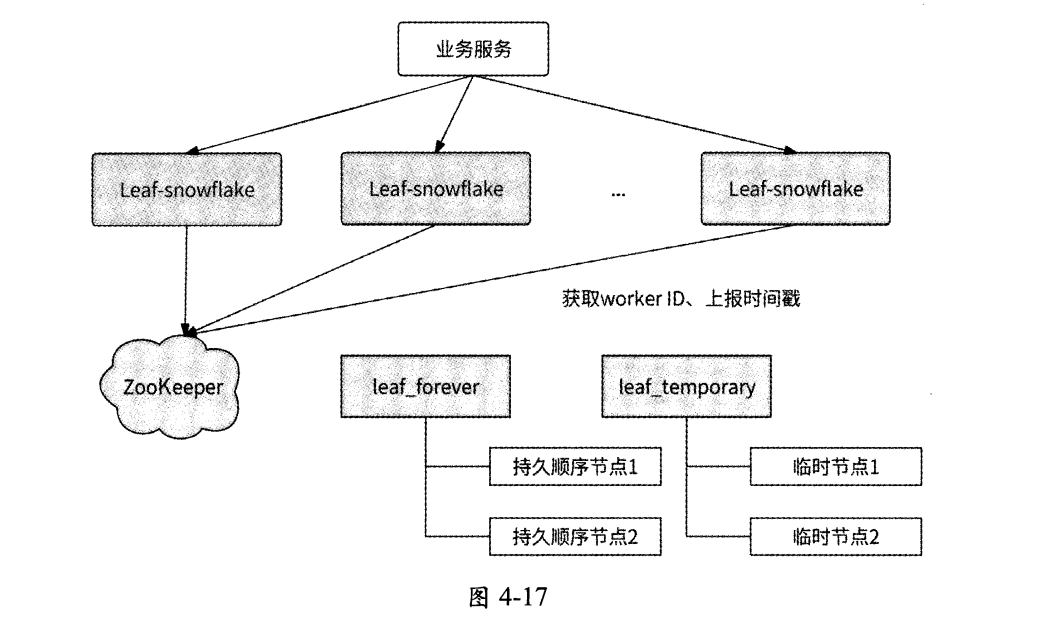
每個Leaf服務實例都會每隔3s將自身的系統時間上報到其在leaf_forever節點下注冊的子節點,并且還會在另一個ZooKeeper節點leaf_temporary下創建一個臨時節點,leaf_temporary下的臨時節點列表代表了此時正在運行的Leaf服務實例集合。也就是說, Leaf服務實際上與兩個ZooKeeper父節點交互:
- leaf_forever節點
- leaf_temporary節點
如圖4-17所示:
Leaf-snowflake方案使用這兩個節點來解決時鐘回撥問題,具體的工作流程如下。
- 如果Leaf服務實例在leaf_forever節點下未注冊持久順序節點,那么在注冊節點 時將順便寫入自身的系統時間。
- 如果Leaf服務實例已在leaf_forever節點下注冊持久順序節點,則對比持久順序節點記錄的時間與自身的系統時間。如果自身的系統時間更小,則認為發生了時鐘回撥,服務實例啟動失敗。
- 否則,獲取leaf_temporary節點下的所有臨時節點信息,然后向這些臨時節點代表的Leaf服務實例發送RPC請求查詢它們的系統時間,并計算出平均時間,用于表示Leaf服務集群的系統時間。
- 如果平均時間與Leaf服務實例自身的系統時間的差值小于某個閾值,則認為本服務實例的系統時間是準確的,服務實例可以正常啟動。
- 否則,說明本服務實例的系統時間相較于Leaf集群中的其他服務實例發生了大幅度的時鐘漂移,服務實例啟動失敗。
- 啟動成功的Leaf服務實例每隔3s將自身的系統時間上報到在leaf_forever節點下注冊的持久順序節點。
Leaf-snowflake方案通過檢查服務實例上報的自身系統時間和其他Leaf服務實例的平均時間來解決時鐘回撥問題,按照美團點評公司技術博客中的說法,這個策略有效地避免了時鐘回撥對業務造成的影響。另外,此方案也建議關閉NTP時鐘同步功能。
本章小結
分布式唯一ID應該具備占用空間小、可用作數據庫主鍵的能力,所以一般用遞增的long類型整數來表示。
遞增可以分為單調遞增和趨勢遞增。
單調遞增的唯一ID生成器可以基于Redis INCRBY命令實現,或者基于數據庫的自增主鍵實現。采用批量生成ID的方式可以提高唯一ID生成器的性能,ID生成器服務實例將一批唯一ID緩存到本地對外提供服務,當可用的唯一ID消耗完時再生成下一批唯一ID。不過,為了保證唯一ID單調遞增,此時只能有一個服務實例對外工作。由于單調遞增的唯一ID生成器服務無法兼顧高可用性和高性能,所以應用相對具有局限性。
如果把單調遞增改為趨勢遞增,那么唯一ID生成器服務將打破局限性。一種方案是使用數據庫分庫分表架構生成自增主鍵,同時利用數據庫自帶的自增主鍵調整自增步長和設置初始值來防止各分表生成的自增主鍵沖突。這種方案可以提高數據庫的高可用性與性能,但是可擴展性較差。另一種方案是使用批量緩存架構,即在批量獲取單調遞增的唯一ID的基礎上采用多服務實例生成趨勢遞增的唯一ID。這兩種方案都是基于數據庫的自增主鍵生成唯一ID的,數值的可讀性過強,在某些場景中有泄露業務數據的風險。基于時間戳生成唯一ID可以解決這個問題。
如何基于時間戳設計唯一ID生成器呢? Snowflake算法為我們提供了很好的思路:將分布式環境下的各變量體現到唯一ID的二進制位上,比如不同的機房、不同的服務實例、不同的時間、相同時間不同的請求。每個ID生成器服務實例都需要有唯一表示自己的worker ID,可以使用數據庫的自增主鍵、分布式協調服務ZooKeeper或etcd來實現;同時,服務實例維護從系統上線時間開始經過的總毫秒數、當前毫秒內已生成的ID數量,以便區分時間和并發請求。最后,一定要防止時鐘漂移問題影響ID的唯一性。
美團點評公司的唯一ID生成器服務Leaf實現了兩種生成唯一ID的方案:Leaf-segment和Leaf-snowflake。前者采用了批量緩存ID的思想,后者是對Snowflake算法的應用。



![[2025CVPR-圖象分類方向]SPARC:用于視覺語言模型中零樣本多標簽識別的分數提示和自適應融合](http://pic.xiahunao.cn/[2025CVPR-圖象分類方向]SPARC:用于視覺語言模型中零樣本多標簽識別的分數提示和自適應融合)




----設計模式(抽象工廠))




)




)
