1. ?背景與問題定義?
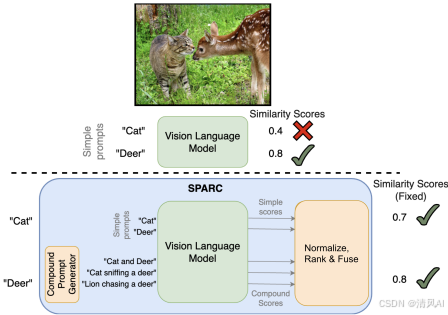
- 視覺語言模型(如CLIP)在單標簽識別中表現出色,但在零樣本多標簽識別(MLR)任務中表現不佳。MLR要求模型識別圖像中多個對象(例如,圖像包含“貓”和“沙發”),而無需任何特定訓練數據或微調。
- 現有方法依賴于提示調優(prompt tuning)或架構修改,這限制了其零樣本適用性。VLMs的分數存在圖像級偏差(image-level bias,即同一圖像在不同提示下分數變化)和提示級偏差(prompt-level bias,即同一提示在不同圖像下分數變化),這些偏差導致MLR性能下降,尤其是在基于平均精度均值(mAP)的排名任務中。
- 核心挑戰包括:VLMs對復合提示(如“貓和沙發”)表現出“OR-like”行為(即高分數可能僅因一個對象存在),而非理想的“AND-like”行為(即僅當所有對象同時存在時高分數)。
?
2. ?核心貢獻?
SPARC的核心創新包括兩個主要部分:
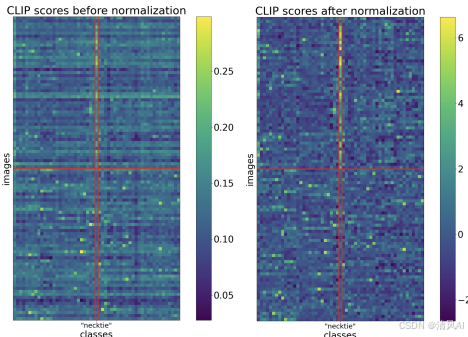
- ?分數標準化(Score Normalization)??:研究發現,VLM分數受圖像級和提示級偏差影響,導致mAP顯著下降。簡單標準化(即減去平均值并除以標準差)能有效去除這些偏差。例如:
- ?圖像級標準化?:針對單個圖像,對所有提示分數進行歸一化,消除圖像特定偏差。
- ?提示級標準化?:針對單個提示,對所有圖像分數進行歸一化,消除提示特定偏差。
實驗證明,僅標準化就能提升mAP 6-10%在COCO、VOC和NUSWIDE數據集上。標準化后,分數更可靠,便于比較和融合。
?
復合提示與自適應融合(Compound Prompts and Adaptive Fusion)??:
- ?復合提示生成?:基于現實對象組合(如“貓和沙發”)創建提示,利用上下文關聯增強檢測。提示包括成對(“A and B”)和三元組(“A, B, and C”)形式,并通過大語言模型(LLM)生成自然句子。提示選擇使用粗略共現概率(例如,過濾掉低概率組合),平均每類生成≤20個提示。
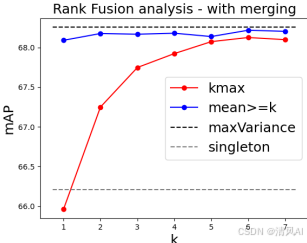
- ?自適應融合?:研究發現,最大復合分數(如最高排名的提示分數)常因“OR-like”行為導致假陽性(即高分數可能僅因一個對象存在)。相反,第二高分數更可靠,因它捕捉對象組合的“AND-like”行為(即僅當所有對象存在時高分數)。SPARC引入基于主成分分析(PCA)的自適應融合:
- 提取復合分數的順序統計量(如第k高分數)。
- 計算最大化方差方向(即第一主成分)作為權重,融合順序統計量和單例提示分數。
- 最終分數通過合并原始單例分數和融合分數獲得。
?
3. ?方法細節?
SPARC算法(Algorithm 1)分為三步:
- ?輸入?:圖像集和類名。
- ?步驟?:
- ?生成復合提示?:使用類名創建復合提示,基于共現概率過濾(例如,閾值τ?=0.05用于成對提示)。
- ?獲取分數并標準化?:查詢VLM獲取單例提示分數和復合提示分數,然后應用圖像級和提示級標準化(公式1-2)。
- ?自適應融合?:對每類計算順序統計量,使用PCA融合(公式3-5),例如,最終分數ζ?? = s?? + 融合分數。
- ?噪聲模型?:VLMs分數可建模為s??? = θ?? · f(y??, y??) + θ?? + ε,其中f函數顯示“OR-like”行為(高分數因單對象)和“AND-like”行為(高分數因所有對象)。標準化有效處理θ??和θ??偏差,而融合減輕f函數的歧義。
4. ?實驗驗證?
實驗在三個數據集(COCO、VOC、NUSWIDE)和九個CLIP骨干(如ViT-L/14、RN50)上進行:
- ?基準比較?:SPARC相比Vanilla ZSCLIP(單例提示),平均mAP提升12.6%(COCO)、8.8%(VOC)、7.9%(NUSWIDE)。改進一致,所有骨干提升6-15%。
- ?互補性?:SPARC與現有方法(如TagCLIP、TaI-DPT)集成,進一步提升mAP(平均1.6-1.7%)。例如,在TagCLIP上集成后mAP從81.3%升至82.9%。
- ?消融實驗?:
- ?標準化模塊?:單獨標準化提升單例提示mAP 7.7%;與復合提示結合提升8.6%。
- ?融合策略?:自適應融合優于固定策略(如k-th最高分數或平均值)。第二高分數比最高分數更可靠,因最高分數易受假陽性影響。
?
5. ?結論與意義?
- SPARC是一種完全零樣本方法,無需訓練數據或VLM內部訪問,通過系統性提示設計和分數解釋提升MLR性能。關鍵發現包括:標準化有效去除偏差;復合提示的第二高分數優于最大分數;自適應融合優化排名。
- 該方法揭示了VLM評分行為的新見解(如“OR/AND”歧義),并為零樣本MLR提供可擴展框架。SPARC互補現有方法,代碼公開于GitHub。
- 總體意義:SPARC展示了通過分數分析而非架構修改實現魯棒MLR的潛力,適用于機器人、醫學影像等零樣本場景。
總結而言,SPARC通過標準化和自適應融合解決了VLMs在零樣本MLR中的核心偏差問題,顯著提升mAP,同時保持模型無關和數據集獨立特性。
論文地址:https://openaccess.thecvf.com/content/CVPR2025/papers/Miller_SPARC_Score_Prompting_and_Adaptive_Fusion_for_Zero-Shot_Multi-Label_Recognition_CVPR_2025_paper.pdf




----設計模式(抽象工廠))




)




)



html基礎和開發工具)
