前言
因為我司「七月在線」準備于25年7月底復現下NaVILA,而在研究NaVILA的過程中,注意到了這個NaVid
- 雖然NaVid目前已經不是VLN sota了,但其首次展示了VLM在無需地圖、里程計或深度輸入的情況下,能夠實現優秀的導航性能
- 且對后來的很多VLN工作——比如對NaVILA 都有比較大的啟發、借鑒意義,且VLN論文中 其實提供了 “不少更好理解NaVILA” 的背景知識或基礎,比如VLN-CE、MP3D等等
- 總之,如果相對VLN有相對完整深入的理解,NaVid是必看工作之一
加之導航在人形落地中的重要性,故
? 一方面,為了加強我司現有同事和將來同事對VLN的深入
故成此文
第一部分?NaVid
1.1 引言與相關工作
1.1.1 引言
如原NaVid論文所述
- 作為具身人工智能的基礎任務,視覺與語言導航VLN
32-Vision-and-language navigation: A survey of tasks, methods, and future directions
70-Visual language navigation: A survey and open challenges
要求智能體在多樣化且尤其是未見過的環境中,依據自由形式的語言指令進行導航 - 比如VLN要求機器人能夠理解復雜且多樣的視覺觀測,同時解析細粒度的指令
13-Touchdown: Natural language navigation and spatial reasoning in visual street environments
99-Talk2nav: Long-range vision-and-language navigation with dual attention and spatial memory
如“上樓梯并在門口停下”,因此該任務始終具有挑戰性
為應對這一挑戰,大量研究
- 85-Lm-nav: Robotic navigation with large pretrained models of language, vision, and action
- 18-History aware multimodal transformer for vision-and-language navigation
- 104-Scaling data generation in vision-and-language navigation
- 98-Multimodal large language model for visual navigation
- 69-Langnav: Language as a perceptual representation for navigation
- 48-Iterative vision-and-language navigation
- 4-Etpnav:Evolving topological planning for vision-language navigation in continuous environments
在簡化場景下展開,即在離散環境中進行決策——例如在MP3D模擬器[12-Matterport3d: Learning
from rgb-d data in indoor environments]中的R2R[46-Beyond the nav-graph: Vision and language navigation in continuous environments]
- 具體而言,真實環境被抽象為連通圖,導航過程被建模為在這些圖上的航點集之間的跳躍。盡管這些方法發展迅速并取得了令人矚目的成果
85-Lm-nav: Robotic navigation with large pretrained models of language, vision, and action
121-Navgpt:Explicit reasoning in vision-and-language navigation with large language models
63-Discuss before moving: Visual language navigation via multi-expert discussions
104-Scaling data generation in vision-and-language navigation
但離散化的環境設置也帶來了額外的挑戰,例如,需要使用地標圖
45-Beyond the nav-graph: Visionand-language navigation in continuous environments
47-Waypoint models for instruction-guided navigation in continuous environments
以及一個用于在地標之間導航的本地模型
84-Ving: Learning open-world navigation with visual goals
87-Gnm: A general navigation model to drive any robot
83-Fast marching methods - 為了實現更為真實且直接的建模,連續環境中的導航(如R2R-CE、RxR-CE)受到越來越多的關注
大量優秀的研究致力于縮小仿真到現實(Sim-to-Real)之間的差距
47-?Waypoint models for instruction-guided navigation in continuous environments
37-Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation
108-Vision and language navigation in the real world via online visual language mapping
9-?Sim-to-real transfer for vision-and-language navigation
然而,由于模型輸入中的RGBD、里程計數據或地圖等數據稀缺以及領域差異,這些方法在泛化能力上仍面臨嚴重挑戰
泛化問題在大規模現實世界部署中,特別是在已見場景到新環境、仿真到現實(Sim-to-Real)等轉變過程中,構成了一個關鍵但尚未充分研究的挑戰 - 近年來,大型視覺語言模型(VLMs)的興起在眾多研究領域展現了前所未有的潛力
109-?The dawn of lmms: Preliminary explorations with gpt-4v(vision)
52-Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
3-?Bevbert: Topo-metric map pre-training for language-guided navigation
且大型語言模型(LLMs)已被證明在離散環境中的視覺語言導航(VLN)規劃任務中表現出色
63-Discuss before moving: Visual language navigation via multi-expert discussions
69-Langnav: Language as a perceptual representation for navigation
121-?Navgpt: Explicit reasoning in vision-and-language navigation with large language models
14-Mapgpt:Map-guided prompting for unified vision-and-language navigation
74-March in chat: Interactive prompting for remote embodied referring expression
故,自然而然的一個問題是,那連續環境中呢?
來自1 Peking University、2 Beijing Academy of Artificial Intelligence、3 CASIA、4 University of Adelaide、5 Australian National University、6 GalBot的研究者,首次嘗試利用基礎VLMs的強大能力,將VLN泛化到現實世界,并提出了一種基于視頻的VLM導航智能體,命名為NaVid

- 其對應的項目地址為:pku-epic.github.io/NaVid
- 其對應的paper地址為:NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
該方法完全依賴機器人單目攝像頭捕獲的視頻和人類發布的指令,作為端到端規劃下一步動作的輸入
為了更好的闡述清楚NaVid,做個同類對比
- 與AGI模型 [109-?The dawn of lmms: Preliminary explorations with gpt-4v (vision)],或所謂的導航通用模型 [120-?Towards learning a generalist model for embodied navigation] 相比,這些模型能進行粗略的導航規劃
而NaVid是一個實用的視覺-語言-動作(VLA)模型,能夠推理出帶有定量參數(如移動距離、旋轉角度)的可執行動作,使其能夠在真實環境中部署 - 與采用LLM作為規劃器的VLN模型相比,NaVid對VLN進行了更為真實的建模
具體而言,NaVid直接在連續環境中推導低層次可執行動作,并以視頻形式編碼視覺觀測
而不是像以往LLM方法那樣在離散空間建模VLN或用文本描述編碼歷史觀測
69-Langnav: Language as a perceptual representation for navigation
121-Navgpt:Explicit reasoning in vision-and-language navigation with large language models
63-Discuss before moving: Visual language navigation via multi-expert discussions
14-?Mapgpt:Map-guided prompting for unified vision-and-language navigation - 區別于現有的專用VLN模型,NaVid在動作規劃過程中不依賴里程計數據、深度信息或地圖,從而避免了由里程計噪聲、深度感知或導航地圖領域差異帶來的泛化難題,使NaVid易于部署
作者宣稱,他們所提出的NaVid是首個用于連續環境中VLN的視頻VLM,實現了僅憑RGB信息的導航,類似于人類的導航行為
總之,NaVid 利用預訓練視覺編碼器對視覺觀測進行編碼,并采用預訓練的大型語言模型(LLM)推理導航動作。通過這種方式,大規模預訓練中獲得的通用知識被遷移到視覺-語言導航(VLN)任務中,從而促進學習并提升泛化能力
受先進的視頻基礎視覺語言模型 LLaMA-VID [57-Llama-vid: An image is worth 2 tokens in large language models]的啟發,作者用兩種類型的 token 表示機器人視覺觀測中的每一幀
- 第一種為基于指令查詢的token,能夠提取與給定指令高度相關的視覺特征
- 第二種為與指令無關的 token,能夠全局編碼細粒度視覺信息,其 token 數量決定了所編碼特征的細致程度。歷史觀測的 token 數量可以與當前觀測的不同
因此,在 NaVid 中,機器人的歷史軌跡被編碼為視頻形式的視覺 token,這相比以往基于 LLM的 VLN 模型中采用離散編碼空間
18-?History aware multimodal transformer for vision-and-language navigation
19-Think global,act local: Dual-scale graph transformer for vision-andlanguage navigation
或使用文本描述[69, 121, 63, 14]的方法
69-Langnav: Language as a perceptual representation for navigation
121-?Navgpt: Explicit reasoning in vision-and-language navigation with large language models
63-Discuss before moving: Visual language navigation via multi-expert discussions
14-?Mapgpt: Map-guided prompting for unified vision-and-language navigation
NaVid能夠提供更豐富且更具適應性的上下文信息
總之,這種基于視頻的建模對模型輸入施加了嚴格的約束,因為它不涉及除單目視頻之外的其他信息,例如深度、里程計數據或地圖。如果能夠正確利用,這種方法有助于緩解由于里程計噪聲以及以往VLN工作中深度感知或導航地圖的領域差異所帶來的泛化挑戰
此外,作者在仿真環境和真實環境中對所提出的 NaVid 進行了大量實驗評估
- 具體來說,NaVid 在 VLN-CER2R 數據集上達到了當前最先進SOTA水平的性能,并在跨數據集評測(R2R-RxR)中表現出顯著提升
- 此外,在仿真到現實(Sim-to-Real)部署中展現出卓越的魯棒性,在四個不同的室內場景中基于 200 條指令,使用僅 RGB 視頻作為輸入,成功率約為 66%
1.1.2 相關工作
第一,關于視覺與語言導航(VLN)
- 在離散化的仿真場景中,圍繞學習根據人類指令在未訪問環境中導航的研究已取得重大進展 7-Vision-andlanguage navigation: Interpreting visually-grounded navigation instructions in real environments
49-Room-across-room(RxR): Multilingual vision-and-language navigation with dense spatiotemporal grounding
72-Reverie: Remote embodied visual referring expression in real indoor environments
97-Vision-and-dialog navigation
在這些場景中,智能體通過在預定義導航圖上的節點間瞬移,并對齊語言與視覺觀測以進行決策
64-Self-monitoring navigation agent via auxiliary progress estimation
101-Reinforced cross-modal matching and self-supervised imitation learning for visionlanguage navigation
27-?Speaker-follower models for vision-andlanguage navigation
96-?Learning to navigate unseen environments: Back translation with environmental dropout
42-Tactical rewind: Self-correction via backtracking in vision-and-language navigation
29-Counterfactual vision-and-language navigation via adversarial path sampler
71-Object-and-action aware model for visual language navigation
35-Language and visual entity relationship graph for agent navigation
盡管這種方法高效,但直接將離散空間中訓練的VLN模型應用于現實世界的機器人場景并不現實 - 因此,更加貼近真實環境的連續空間視覺與語言導航(VLN-CE)被提出
45-Beyond the nav-graph: Visionand-language navigation in continuous environments
81-Habitat: A platform for embodied ai research
允許智能體通過預測低層控制指令
78-?Language-aligned waypoint (law) supervision for vision-and-language navigation in continuous environments
40-Sasra: Semanticallyaware spatio-temporal reasoning agent for vision-andlanguage navigation in continuous environments
15-Topological planning with transformers for vision-and-language navigation
31-?Cross-modal map learning for vision and language navigation
16-Weakly-supervised multi-granularity map learning for vision-and-language navigation
或由航點預測器估算的可導航子目標中選擇,自由地導航到模擬器中任何無障礙空間
37-Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation
47-?Waypoint models for instruction-guided navigation in continuous environments
44-Sim-2-sim transfer for vision-and-language navigation in continuous environments - 與此同時,得益于從大規模網頁圖文對中學習通用視覺-語言表征的成功
20-Uniter: Universal image-text representation learning
56-Oscar: Object-semantics aligned pre-training for vision-language tasks
91-Vl-bert: Pre-training of generic visual-linguistic representations
53-Visualbert: A simple and performant baseline for vision and language
95-Lxmert: Learning crossmodality encoder representations from transformers
許多VLN模型受益于大型視覺-語言模型
55-Robust navigation with language pretraining and stochastic sampling
36-?A recurrent vision-andlanguage bert for navigation
18-?History aware multimodal transformer for vision-and-language navigation
19-Think global, act local: Dual-scale graph transformer for vision-andlanguage navigation
及針對VLN的預訓練
34-Towards learning a generic agent for vision-and-language navigation via pre-training
67-Improving vision-and-language navigation with image-text pairs from the web
33-Airbert: In-domain pretraining for vision-and-language navigation
107-Cross-modal semantic alignment pre-training for visionand-language navigation
73-Hop: History-and-order aware pre-training for vision-and-language navigation
最近,通過擴展導航訓練數據,VLN智能體在廣泛認可的R2R基準 [46-Beyond the nav-graph: Vision and language navigation in continuous environments]上的表現已接近人類水平 [104-Scaling data generation in vision-and-language navigation]
這一重大進展表明,將VLN技術應用于現實世界機器人已變得日益可行且時機成熟
第二,對于仿真到現實的VLN遷移
盡管取得了巨大進展,現有VLN方法主要在仿真環境中構建和評估,極大忽略了現實世界環境的復雜性和不可預知性
- 仿真到現實的VLN遷移仍是一個研究不足的話題;迄今為止,唯一系統性研究該問題的文獻來自Anderson等人[8-Sim-to-real transfer for vision-and-language navigation],其論證了由于動作空間和視覺域的差異,成功率下降超過50%的性能差距
此外,還需強調泛化到自由形式語言指令的挑戰——即使在數百萬域內視覺數據上訓練,智能體也常常無法理解不同風格的指令
104-Scaling data generation in vision-and-language navigation
41-A new path:Scaling vision-and-language navigation with synthetic instructions and imitation learning - 鑒于此,許多最新研究利用大型(視覺)語言模型卓越的泛化能力來促進VLN(視覺語言導航)的泛化
相關研究
121-?Navgpt: Explicit reasoning in vision-and-language navigation with large language models
69-Langnav: Language as a perceptual representation for navigation
120-Towards learning a generalist model for embodied navigation
63-Discuss before moving: Visual language navigation via multi-expert discussions
14-?Mapgpt:Map-guided prompting for unified vision-and-language navigation
82-Velma:Verbalization embodiment of llm agents for vision and language navigation in street view
58-?Mo-vln: A multi-task benchmark for open-set zero-shot vision-andlanguage navigation
或通過注入常識知識[74-March in chat: Interactive prompting for remote embodied referring expression]來增強系統能力
作者遵循這一趨勢,進一步探索如何利用統一的大模型進行低層級動作預測,以及其在真實場景中的泛化能力。該方法旨在通過利用LLMs的全面理解和多樣化能力
121-?Navgpt: Explicit reasoning in vision-and-language navigation with large language models
69-Langnav: Language as a perceptual representation for navigation
120-?Towards learning a generalist model for embodied navigation
63-Discuss before moving: Visual language navigation via multi-expert discussions
14-Mapgpt: Map-guided prompting for unified vision-and-language navigation
74-March in chat: Interactive prompting for remote embodied referring expression
不僅推動VLN領域的發展,還彌合仿真環境與現實應用中多樣化挑戰之間的差距
第三,對于大型模型作為具身智能體
- 近年來,研究者開始探索將大型模型集成到不同的具身智能領域
26-Palm-e: An embodied multimodal language model
121-?Navgpt: Explicit reasoning in vision-and-language navigation with large language models
59-The development of llms for embodied navigation
86-Lmnav: Robotic navigation with large pre-trained models of language, vision, and action
90-?Llmplanner: Few-shot grounded planning for embodied agents with large language models
82-Velma:Verbalization embodiment of llm agents for vision and language navigation in street view
39-Inner monologue: Embodied reasoning through planning with language models
例如,PaLM-E[26-Palm-e: An embodied multimodal language model]提出將多種模態的token(包括文本token)輸入到大型模型中
然后模型為移動操作、運動規劃等任務生成高層次的機器人指令以及桌面操作 - 更進一步
RT-2 [11-Rt-2: Vision-language-action models transfer web knowledge to robotic control] 為機器人生成低層次動作,實現閉環控制
GR-1 [106] 引入了一種專為多任務語言條件視覺機器人操作[111] 設計的 GPT 風格模型
[?75-?Improving language understanding by generative pre-training,
121-Navgpt,
63-Discuss before moving: Visual language navigation via multi-expert discussions?]
該模型能夠根據「語言指令、觀測到的圖像和機器人狀態」預測:機器人動作及未來圖像
RoboFlamingo[54-Vision-language foundation models as effective robot imitators] 提出了一個視覺-語言操作框架,利用預訓練的視覺-語言模型來制定機器人操作策略
其目標是為機器人操作提供一種高性價比、高性能的解決方案
[22-Toward next-generation learned robot manipulation,
94-?A survey of robot manipulation in contact.Robotics and Autonomous Systems,
111-Homerobot: Open-vocabulary mobile manipulation,
89-Cliport: What and where pathways for robotic manipulation]
允許用戶通過大模型對機器人進行微調
EMMA-LWM[112-Language-guided world models: A model-based approach to ai control] 通過語言交流開發了面向駕駛智能體的世界模型,并在數字游戲環境中展現了令人信服的結果[100-Grounding language to entities and dynamics for generalization in reinforcement learning]
深入探討這些工作后,本文聚焦于另一個關鍵的具身領域:視覺與語言導航,該任務要求機器人在未知環境中根據人類指令完成導航
1.1.3 問題表述
本工作的連續環境下視覺與語言導航(VLN-CE)任務表述如下:
- 在時刻
,給定由?
?個單詞組成的自然語言指令
以及由一系列幀組成的視頻觀測
智能體需要為下一步規劃一個低級動作
該動作將使智能體到達下一個狀態,并獲得新的觀測 - 總體而言,可以將決策過程表述為一個部分可觀測馬爾可夫決策過程(POMDP),記作
在本工作中,觀測空間對應于僅由單目RGB 相機采集的視頻,不涉及其他額外數據,動作空間則結合了定性動作類型與定量動作參數,在該領域中也被稱為低級動作[45-Beyond the nav-graph: Visionand-language navigation in continuous environments]
這種建模方式實現了一種自然的范式,其中觀測完全基于視覺且易于獲取,而動作則可以直接執行,類似于人類的導航行為
1.2?Navid的完整方法論
1.2.1 總體架構
通過上文已知,NaVid是首個將VLM通用知識遷移到現實視覺語言導航VLN智能體的系統
作者在通用型視頻視覺語言模型 LLaMA-VID [57-Llama-vid: An image is worth 2 tokens in large language models]的基礎上構建了 NaVid。對于他們提出的NaVid,他們繼承了 LLaMA-VID 的主要架構,并在此基礎上融入了任務特定的設計,從而促進通用知識向 VLN-CE 的遷移,使其泛化難題更易解決
如圖2所示
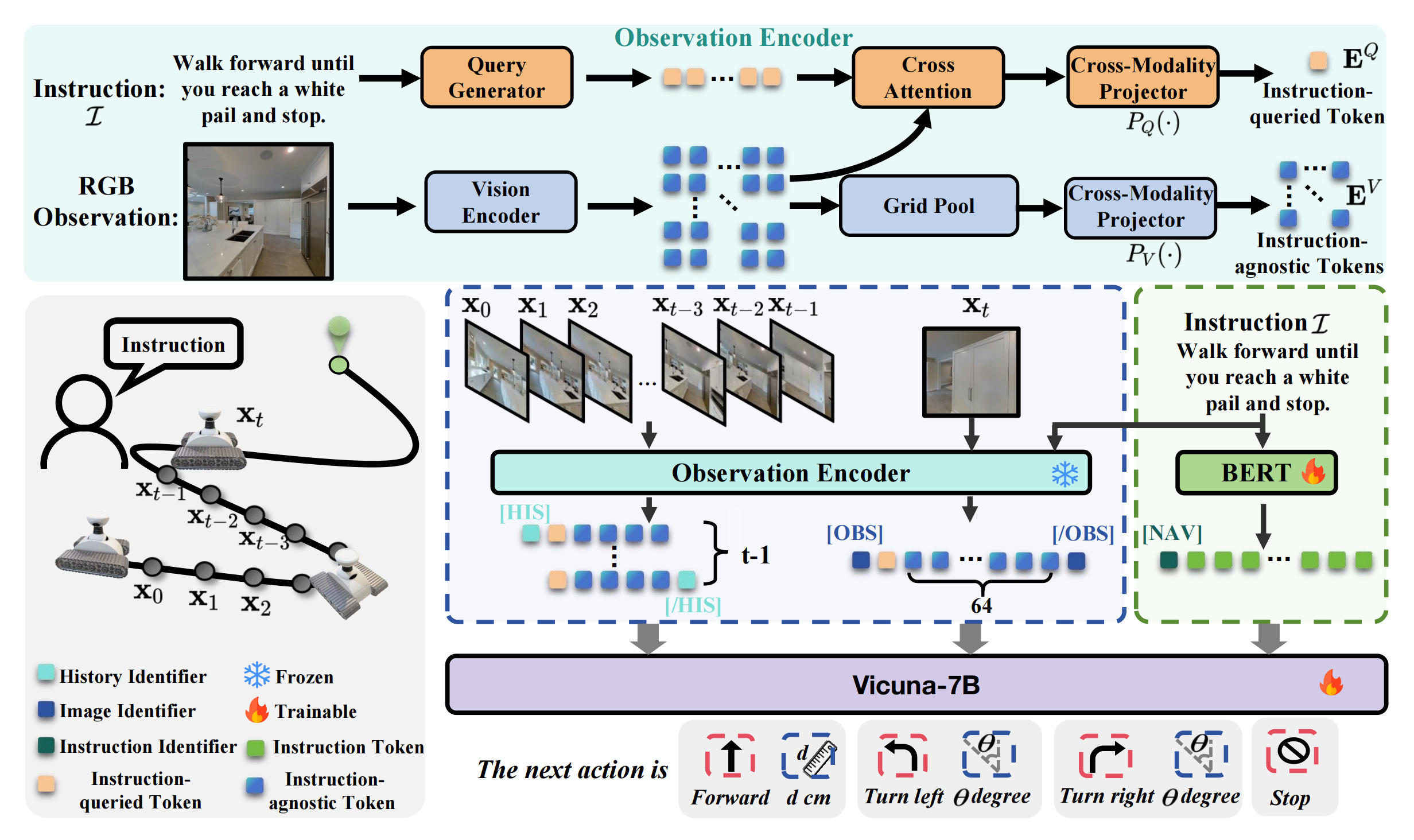
- NaVid的輸入包括來自在線視頻觀測的RGB幀
對于每一幀,使用觀測編碼器結合指令提取視覺信息,獲得觀測token,包括指令query token(橙色塊)和指令無關token(藍色塊)
For each frame, we use an observation encoder to extract the visual information with the instruction to obtain observation tokens, including, instruction-queried tokens (orange blocks) and instruction-agnostic tokens(blue blocks).
在當前時刻t,歷史幀和當前幀
被分別編碼為觀測token,歷史幀有4個指令無關token,當前幀有64個指令無關token
- 作者的方法通過文本編碼器獲得語言token
- 最后,通過特殊token [HIS]、[OBS] 和 [NAV] 進行分割,將觀測token與語言token拼接后輸入Vicuna-7B,從而獲得下一步動作
進一步
- NaVid 由視覺編碼器、查詢生成器、大型語言模型(LLM)和兩個跨模態投影器組成
As illustrated in Fig. 2, NaVid consists of a vision encoder,a query generator, a LLM, and two cross-modality projectors.
給定截至時間 t 的觀測,即包含
為簡明起見,作者將投影后的token稱為觀測token
通常,指令也被分詞為一組token,稱為指令token- 作者將觀測token與指令token拼接后輸入 LLM,以推斷出以語言形式表達的VLN 行為
需要注意的是,作者的工作重點在于任務特定建模,而非模型架構,詳見下文
1.2.2?NaVid 的 VLN-CE 建模:涉及觀測編碼和動作規劃
首先,對于觀測編碼
給定截至時刻的捕獲單目視頻,記為
,作者用一個指令查詢的視覺token和若干個與指令無關的視覺token來表示每一幀「we represent each frame with one instruction-queried visual token and several instruction-agnostic visual tokens」
被指令查詢的token 提取與給定指令特定相關的視覺特征,而與指令無關的token則全局編碼細粒度的視覺信息
對于每一幀,首先通過視覺編碼器獲得其視覺嵌入
,其中Nx為patch 數量——
設置為256,
為嵌入維度
- 為了獲得指令查詢的tokens,作者采用基于Q-Former的查詢生成器,利用查詢生成器
生成指令感知查詢
,其中
表示每幀的查詢數量,
為每個查詢的維度
查詢生成過程可表述為:
其中
和
分別是幀
是一個基于Q-Former 的transformer,通過
類似于Q-Former
—————
52-?Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
——————————————
中的操作
指令查詢的tokens是通過
之間的交叉注意力獲得的,公式如下
其中
表示用于獲取指令相關token 的跨模態投影器,
是在查詢維度上的平均操作,使得
- 對于與指令無關的token,作者直接進行網格池化操作和跨模態投影以獲得它們,可以表示為
其中GridPool (·) 是一種網格池化操作[57],將tokens 從壓縮到
,得到
關于網格池化的詳細描述可以在補充材料中找到
注意,像LLaMA-VID [57] 那樣用兩個tokens 表示每一幀并不滿足VLN-CE 任務的要求,正如下文實驗所證實的那樣。這是因為LLaMA-VID 主要面向高層次的問答任務,而NaVid 需要為機器人規劃可執行的動作。因此,作者在此采用網格池化,使與指令無關的tokens 能夠保留足夠的幾何信息,從而使NaVid 中的LLM 擁有足夠的上下文來推理機器人動作的定量參數
作者的池化操作在二維特征圖上以特定的步幅進行
具體來說,作者將來自EVA-CLIP 的二維特征圖以網格方式劃分,并在每個網格上執行平均池化
例如,作者使用步幅H/2 將H × H 特征圖劃分為2 × 2 網格,其中每個網格產生一個token,最終總共得到四個token

對于VLN-CE,當前幀作為導航動作推理的主要依據,而歷史幀則為追蹤導航進度提供了重要的上下文。鑒于它們在保持幾何信息方面的不同需求,作者在對歷史幀和當前幀進行編碼時采用了不同數量的與指令無關的token。在本研究中,除非另有說明,作者將當前幀的與指令無關的token數量設置為64,而每個歷史幀設置為4。這不僅有助于模型學習,還提升了效率
此外,為了進一步促進NaVid的訓練,作者在將不同類型的信息輸入NaVid內部的大語言模型(LLM)之前,通過特殊token對其進行明確區分
- 具體而言,作者采用特殊token
?和
分別對歷史幀和當前幀編碼的token進行分隔
其中,和
表示對應token序列的開始
而和
標記其結束
- 此外,他們還使用另一個特殊token
,用于提示LLM開始處理指令的文本token,并以語言形式輸出機器人動作
因此,NaVid 的輸入可以總結如下
在此格式中,{歷史幀{historical_frames}、{當前幀{current_frame}、{指令內容instruction _content}和{答案內容answer_content}分別代表歷史幀、當前幀、指令和推理動作的占位符Input: <HIS > {historical frames} </HIS ><OBS > {current frame} < /OBS >) < NAV >{instruction content} Output: {answer content}
其次,對于動作規劃
NaVid以語言形式為VLN-CE規劃下一步動作。其每一步輸出的動作均由兩個變量組成,與VLN-CE的設定保持一致
- 其中一個變量為動作類型,從離散集合
中選擇
- 另一個變量為與不同動作類型對應的定量參數
對于FORWARD,NaVid進一步推斷具體的移動距離;
對于TURN-LEFT和TURN-RIGHT,NaVid還預測具體的旋轉角度
系統采用正則表達式解析器[43-Extending regular expressions with context operators and parse extraction],用于提取動作類型和參數,以便模型評估及實際部署
1.2.3?NaVid的訓練:涉及非專家導航軌跡收集、VLN-CE與輔助任務的聯合訓練
現有的導航仿真數據在多樣性、真實性和規模上仍然有限。作者設計了一種混合訓練策略,以最大化這些數據的利用率,使NaVid能夠盡可能有效地泛化到新場景或現實世界
為此,混合訓練策略提出了兩種關鍵方法:
- 一是收集非oracle導航軌跡并將其納入訓練循環;
- 二是設計輔助任務,以提升NaVid在導航場景理解和指令執行方面的能力
1.2.3.1 非專家導航軌跡收集
受 Dagger 技術 [80-A reduction of imitation learning and structured prediction to no-regret online learning] 啟發,作者收集了非專家導航軌跡,并將其納入NaVid 的訓練過程中。如果不采用這種方法,NaVid 在訓練期間只能接觸到專家導航軌跡,這與實際應用環境不符,并且會降低所學導航策略的魯棒性
為此,作者首先收集專家導航軌跡,包括單目視頻觀測、指令和機器人動作,來自于VLN-CE R2R數據集
- 具體來說,作者從61個MP3D室內場景[12-Matterport3d: Learning from rgb-d data in indoor environments]中收集數據,總計包含32萬步級樣本
- 隨后,在這些oracle軌跡數據上訓練NaVid,并將獲得的智能體部署到VLN-CE環境中,進一步收集非oracle導航軌跡
- 最終,獲得了另外18萬步級樣本。來自oracle和非oracle軌跡的樣本被合并,用于NaVid的最終訓練,如圖3上方所示
用戶:假設你是一臺被編程用于導航任務的機器人
你獲得了一段歷史觀測的視頻和一張當前觀測的圖像<image>
你的任務是:向前走,進入并沿著工作區中間前進。一直向前走,直到你到達地板上靠近帶有黑色椅子的桌子旁的一個白色水桶處并停下
分析這一系列圖像,以決定你的下一個動作,該動作可能包括向左或向右轉動特定角度,或向前移動一定距離
助手:下一個動作是向前移動75厘米?
1.2.3.2 VLN-CE與輔助任務的聯合訓練
作為導航智能體,除了規劃導航動作外,精確理解環境和遵循給定指令是兩項不可或缺的能力。為促進智能體學習,作者將VLN-CE動作規劃與兩個輔助任務結合,以協同訓練的方式進行
- 針對環境理解,作者設計了一個名為指令推理的輔助任務。給定一個基于視頻的導航軌跡,NaVidis 被要求推導出該軌跡對應的指令
該輔助任務可以通過上文1.2.2節(原論文第四節 B 部分)介紹的共享數據組織格式輕松實現,其中{instruction content}和{answer content}可以分別實例化為請求描述機器人導航軌跡的提示和數據集中提供的人類標注指令
指令推理輔助任務包含 1 萬條軌跡,示例見圖 3 下方
用戶:假設你是一臺為導航設計的機器人。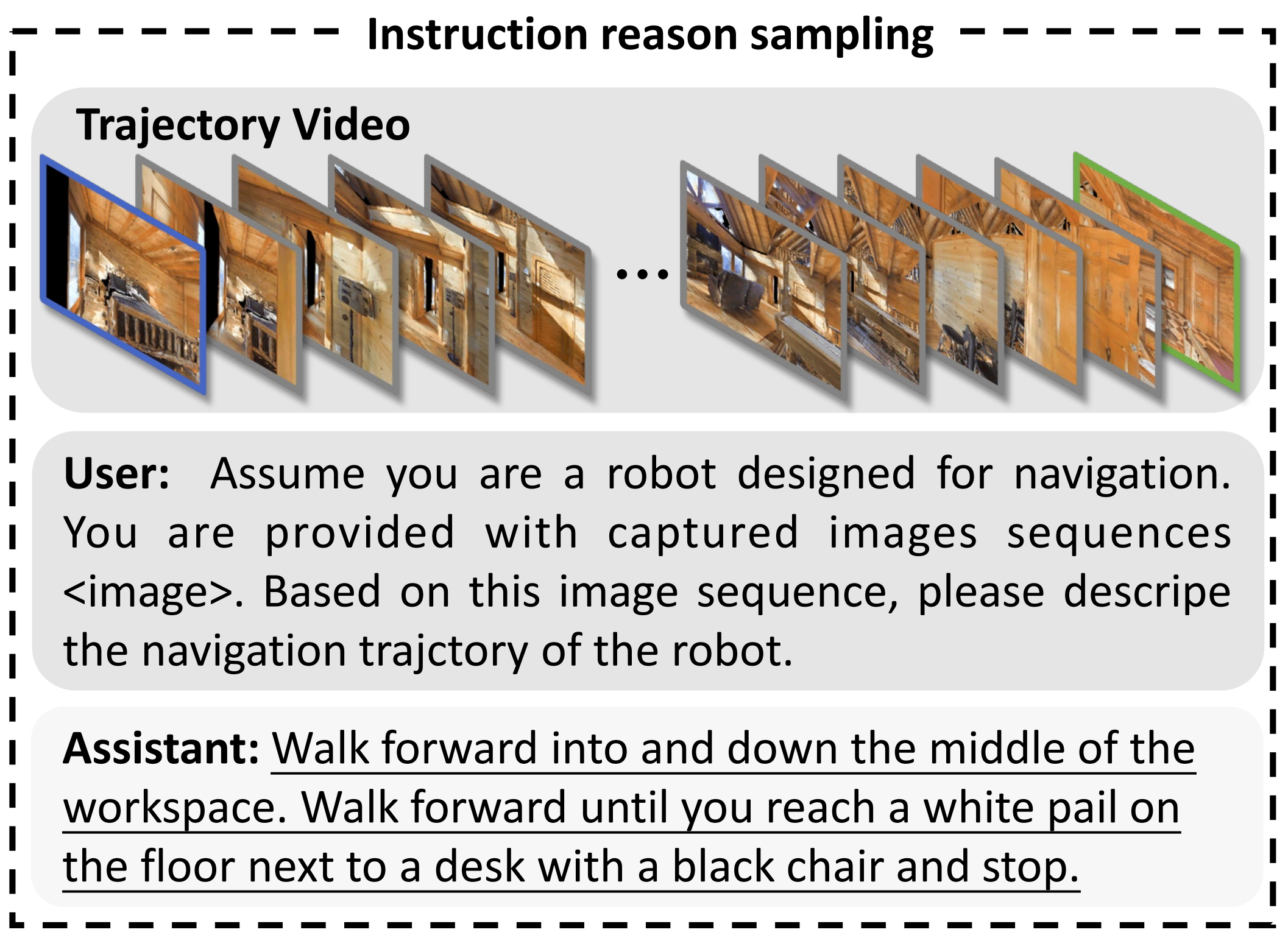
你獲得了一組捕獲的圖像序列<image>。 請根據該圖像序列,描述機器人的導航軌跡。
助手:向前走,進入并沿著工作區中間前進。向前走,直到你到達地板上靠近帶有黑色椅子的書桌旁的一個白色桶,然后停下 - 此外,為了增強指令跟隨能力并防止在預訓練中獲得的通用知識遺忘,作者還將基于視頻的問答樣本納入聯合訓練。詳細信息可參見文獻[57]。為簡明起見,此處不再贅述
1.2.4 實現細節:訓練配置、評估配置
- 對于訓練配置
NaVid 在一臺配備 24 塊 NVIDIA A100GPU 的集群服務器上訓練約 28 小時,總計 672GPU 小時
對于視頻-字幕數據,以 1 幀每秒的速率采樣幀,以去除連續幀之間的冗余信息。對于導航-動作數據,保留所有幀,通常不超過 300幀
在訓練過程中,所有模塊,包括 EVA-CLIP[92]、QFormer [23]、BERT [24] 和 Vicuna-7B[21],均加載默認的預訓練權重
且按照文獻 [57-LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models] 的策略,作者僅優化 LLaMA 和文本編碼器的可訓練參數,且僅訓練 1 個 epoch - 評估配置
在NaVid預測語言動作后,作者利用正則表達式匹配[43]來期望獲得有效動作。作者發現,這一簡單算法在VLN-CE val-unseen R2R評估中獲取有效動作的成功率達到100%。在真實世界導航中,使用遠程服務器運行NaVid,以接收觀測數據(以及文本指令),并控制本地機器人執行預測的動作
在導航過程中,智能體每幀輸出一個動作大約需要1.2到1.5秒。通過采用如量化[61, 60]等加速技術,這一速度有望進一步提升
1.3 實驗
1.3.1 實驗設置
- 對于模擬環境
作者在VLN-CE基準測試上評估他們的方法,該基準測試為在重建的逼真室內場景中執行低級動作提供了連續環境 [45-Beyond the nav-graph: Visionand-language navigation in continuous environments]
他們在VLN-CE中考慮了R2R [46] 和 RxR [49],這兩個是VLN領域最具代表性的基準。為保證公平對比,所有方法均在10,819個R2R訓練集上進行訓練,并在1,839個R2R驗證-不可見集和1,517個RxR驗證-不可見集上進行評估,以分別評測跨分割和跨數據集的性能 - 對于真實環境
為了評估他們方法在真實環境中的表現,作者遵循文獻[8, 108]的實驗設置,并設計了包含不同室內場景和不同難度指令的綜合實驗
作者選擇了四個不同的室內場景,包括會議室、辦公室、實驗室和休息室。在指令設計上,他他們設置了兩種類型的指令:
1)簡單地標指令跟隨任務,要求智能體理解目標的語義并移動到目標的相對位置;
2)復雜的復合指令跟隨任務,要求智能體完成2-5個地標跟隨任務的組合指令
對于每個選定的場景,作者設計了25條簡單地標指令和25條復雜復合指令,總共形成200個指令跟隨案例
另,作者在所有真實環境實驗中均使用Turtlebot4進行
該機器人配備了Kinect DK相機,用于捕捉深度和RGB圖像
- 對于需要里程計的基線方法,作者使用Turtlebot4自帶的RPLIDAR A1M8激光雷達,并利用Nav2 [65-The marathon 2: A navigation system]工具箱進行定位與建圖
- 激光雷達與相機的標定遵循前人工作[118-Extrinsic calibration of a camera and laser range finder (improves camera calibration)],具體細節請參見補充材料
需要注意的是,已有更先進的跟蹤與定位系統[62, 113, 114],這些系統有可能進一步提升性能
對于機器人配置的細節
- 作者對實際機器人進行了詳細描述(見圖10)。他們的機器人基于Turtlebot 4,并使用Azure KinectDK采集RGB和深度圖像(作者的方法僅使用RGB圖像)
- 此外,作者在機器人頂部部署了PRLIDARA1M8激光雷達,用于采集一維激光點云,該點云被激光雷達里程計算法用于計算位置和朝向[66]
基于上述機器人,作者設計了一個結合視覺與語言導航的NaVid流程(見圖11)
- NaVid部署在配備A100 GPU的服務器上,該服務器通過互聯網接收來自機器人的壓縮圖像,并返回解析后的指令
- 機器人接收諸如“左轉”或“前進”等指令,并驅動機器人執行相應動作
在移動過程中,機器人持續跟蹤運動狀態,以確保旋轉或前進動作與指令保持一致

對于評估指標
- 作者遵循標準的VLN評估指標[7, 46, 50,51]來評估導航性能,包括成功率(SR)、oracle成功率(OS)、按路徑長度加權的成功率(SPL)[6]、軌跡長度(TL)以及距離目標的導航誤差(NE)
其中,SPL是主要評估指標,因為它同時反映了導航的準確性與效率[5] - 需要注意的是,在VLN-CE中,如果智能體在距離目標3米以內調用STOP動作,則該回合被視為成功;而在真實環境中,此距離為1.5米。關于評估指標的更多細節,請參見補充材料
基線方法
為了與NaVid進行公平比較,作者對比了在VLN-CE環境中直接預測低層次動作原語的方法的性能:
- Seq2Seq [45] 是一種簡單的序列到序列基線方法,采用循環策略直接根據RGBD觀測預測動作。RGB-Seq2Seq表示僅使用RGB觀測
- CMA [45] 利用指令與RGBD觀測之間的跨模型注意力機制來預測動作。RGB-CMA表示僅使用RGB觀測
- WS-MGMap [16] 利用多粒度地圖,其中包含了物體的幾何、紋理和語義信息
1.3.2?模擬環境下的對比:涉及VLN-CE R2R、VLN-CE RxR
第一,對于VLN-CE R2R
作者首先在VLN-CE R2R Val-Unseen數據集上進行實驗,以評估方法的跨分割泛化能力。結果見表I「VLN-CE R2R Val-Unseen 的對比。?:方法使用高級動作空間。?:方法使用與 [37] 提出的相同航點預測器。?:方法使用除 MP3D 場景 [12] 外的額外視覺數據」

- 此處作者標注了各方法所需的具體觀測信息,而作者的方法僅使用RGB觀測。與相關的VLN-CE設置(低級動作空間)相比,作者認為他們的方法在SPL、NE等指標上取得了SOTA表現——在沒有使用深度和里程計信息的情況下,本方法在OS 上表現出色,在SR 上也具有可比的性能
- 對于與作者方法設置相同的Seq2Seq-RGB 和CMA-RGB 方法,NaVid顯著優于這些方法,將SR 從5.00 % 提升至37.4%,SPL 從4.43 % 提升至35.9 %
本方法在SPL 方面比SOTA 方法WS-MGMap 高出1.6 %。結果表明,僅利用RGB 觀測,作者宣稱NaVid就能展現出SOTA 級別的性能,驗證了其有效性
為了探索NaVid 在更長記憶需求(更多步數)方面所面臨的挑戰,作者報告了在不同步長指令下的性能表現,這些指令通常需要30 到90 步才能完成,跨度約為5 到20米
- 結果如圖4(a) 所示,顯示NaVid在從短距離(低于30 步)到長距離(超過90 步)的范圍內都保持了穩定的性能
- 此外,作者在圖4(b) 中繪制了訓練過程中每步的episode 數量。盡管約有5.91 % 的episode 超過了90 步,NaVid在大多數episode(范圍為35 步到75步-約占74.3%的實驗)表現優秀
作者認為,這一穩健的表現可能歸因于他們采用了聯合調優導航數據與網絡級視頻數據的策略,其中包括最長300幀的序列,因此使NaVid能夠處理比大多數VLN任務所需更長的歷史上下文
第二,對于VLN-CE RxR
為了評估方法的跨數據集性能,作者在R2R軌跡-指令樣本上訓練模型,并比較其在RxR Val-Unseen數據劃分上的零樣本表現
RxR數據集包含更細粒度的指令,描述了豐富的地標和更長的路徑,這為評估方法的泛化能力提供了較大的語言與視覺鴻溝
如表II所示「在 VLN-CE RxR Val-Unseen 上跨數據集性能比較。請注意,A2Nav 是一種零樣本方法,利用 GPT 作為規劃器」

NaVid在NE、OS、SR和SPL等指標上均大幅優于現有方法。需要注意的是
- Seq2Seq的軌跡長度(TL)極小,主要由于其指令跟隨能力較差(SR為3.51%),導致提前終止
- 與當前零樣本VLN-CE RxR的SOTA方法A2Nav [17]相比,NaVid在SR和SPL上分別提升了41.7%(從16.8到23.8)和236.5%(從6.3到21.2)
- 此外,采用相同設置的Seq2Seq-RGB和CMA-RGB基線在所有指令上均失敗,進一步說明了僅用RGB方法的挑戰性
這證明了NaVid通過將基于視頻的大型視覺-語言模型引入VLN以應對自由形式語言導航任務,具備良好的泛化潛力
第三,看下與大型基礎模型的對比
接下來作者希望評估主流大型模型各變體的性能
在視覺語言導航任務中使用基礎模型
- GPT-4V [109] 和 Emu [93] 支持帶有圖像輸入的多輪對話,因此在每一輪對話中,作者輸入一張新的觀測到的 RGB 圖像
- LLaVA [60] 是單輪對話圖像模型,因此作者采用觀測到歷史的技術來編碼歷史信息
LLaMA-VID [57] 能夠基于視頻輸入回答問題,這里的視頻輸入可以替換為導航觀測序列
對于已公開訓練數據集和代碼的 LLaVA 和LLaMA-VID,作者使用提出的導航數據對這些模型進行聯合微調,分別得到改進后的模型 LLaVA-Nav 和 LLaMA-VID-Nav。所有基線模型都經過了精心調優和提升,詳細信息可見補充材料
考慮到在GPT-4V 和LLaVA 中提升歷史信息等極高的計算成本,作者隨機抽取了100 個episode,作為VLN-CER2R Val-Unseen 子集的一個子劃分(所抽取episode 的ID 可在補充材料中找到以便復現)
結果見表III

作者發現,未在所提出的導航數據上訓練的方法表現非常差
- 尤其是,Emu、LLaVA 和LLaMA-VID 經常輸出與動作無關的答案,如環境描述或導航評論,這使得智能體很難導航
- 一個更強大的模型GPT-4V,在精心設計的in-context prompt [121, 38] 下,能夠相對穩定地輸出有效動作,但其性能仍然較低,SR僅為5 %
- 在使用所提出的導航數據進行微調后,作者發現LLaVA-Nav 和LLaMA-VID-Nav 有了顯著提升,這證明了所收集導航數據的重要性。此外,在導航數據上訓練還能提升指令遵循能力,使LLaMA-VID-Nav 的有效動作回答比例從0 % 提升到91.3 %
第四,看下與不同導航歷史表示方法的對比
作者將所提出的基于視頻的NaVid建模方法與其他用于表示過往軌跡的替代方案進行了比較。他們調整了用于識別不同表示方式的特殊token機制,同時保持其他設計元素不變,以確保對比的公平性
作者對這些替代方案進行了細致的實現,并收集了適用于訓練的導航和描述數據。其詳細實現方式如下所述
- 基于文本
作者使用文本來描述導航歷史作為輸入(包括當前幀)
借鑒NavGPT [121]的方法,作者采用視覺基礎模型(LLaVA [60])對每一幀的環境進行描述,并每10幀將逐幀文本觀測與GPT-4 [2]結合
需要注意的是,使用GPT-4V [109]替換LLaVA可能會帶來更好的性能,但會導致不可接受的高成本。該模型與LLaVA [60]中的文本問答數據集聯合微調 - 地圖-文本
作者將當前的俯視二維地圖與文本導航歷史信息(A)一同作為輸入
俯視二維地圖通過Habitat仿真器 [81] 獲得,并直接采用默認風格。俯視地圖中包含指示機器人位置和朝向的箭頭,并使用灰色表示可通行區域
俯視地圖被編碼為256個token。該模型與LLaMA-VID [57]和LLaVA[60]中使用的文本及圖像問答數據集聯合微調 - 自我視角文本
該模型利用當前的自我中心圖像以及文本導航歷史信息(A)作為輸入。自我中心圖像直接來自Habitat模擬器,自我中心圖像視圖被編碼為256個token
該模型與LLaMA-VID [57]和LLaVA [60]中使用的文本及圖像問答數據集進行聯合微調
- 作者發現,在VLN任務中,將過去的軌跡建模為文本或二維地圖明顯不如以視頻形式建模,SPL從35.9%下降到20.8%/8.97%。這證明了作者提出的視頻化軌跡建模的必要性和優越性
- 作者認為,原因在于將過去的軌跡表示為文本或二維地圖會大幅壓縮豐富的視覺信息,從而增加理解軌跡歷史的難度
- 此外,文本歷史表示的推理時間平均每個動作步驟約為2.7秒,幾乎是基于視頻表示的兩倍。推理時間延長主要源于需要額外的LLaVA查詢來生成圖像描述,以及GPT查詢以總結導航歷史
第五,與LM-Nav及其變體的對比
LM-Nav 是一個基線方法,利用離散化的環境設置和現成的大型基礎模型。在這里,LM-Nav(GPT-3.5 和 CLIP)采用 GPT-3.5進行指令分解,CLIP 用于地標定位
- 此外,作者還進行了消融實驗,LM-Nav(Vicuna-7B 和 EVA-CLIP),將 LM-Nav 的基礎模型替換為 NaVid 所使用的模型
且還實現了一個強基線,LM-Nav(GPT-4 和 EVA-CLIP),其構建模塊采用了更先進的基礎模型 - 需要注意的是,LM-Nav 需要預先構建地標圖,因此作者利用 Habitat模擬器中的真實地標數據來構建該圖
此外,由于LM-Nav 所用的視覺導航模型(ViNG)[84] 未公開,作者為 LM-Nav 提供了地標之間的真實最短路徑,以便其能夠有效導航至每個地標
最終在 RxRVal-Unseen 分割集上對所有方法進行了評估,其中NaVid 在訓練過程中未曾見過這些指令和場景
結果如表V所示

作者觀察到
- NaVid在RxR Val-Unseen分割上的表現顯著優于LM-Nav,盡管LM-Nav采用了預定義的oracle地標
這一優越性能可以歸因于LM-Nav僅關注地標,忽略了動詞及其他指令性命令(例如,“向右轉并走到椅子旁”或“轉身面對沙發”)
這種設計忽視了指令中的空間上下文,可能導致LM-Nav將目標定位到語義相同但實際位置錯誤的地標
這一問題在室內環境中尤為常見,因為許多物體可能屬于相同的語義類別 - 此外,像CLIP和EVA-CLIP這樣的模型在物體密集擺放且視角受阻的場景中,可能會在圖像定位方面遇到困難
作者認為,NaVid憑借其端到端的訓練方法,在視覺-語言導航(VLN)任務中展現出了更強的適應性和有效性
1.3.3?真實環境下的對比
為了進一步評估各方法在更具挑戰性的情境下的泛化能力,作者在真實環境中進行了大規模實驗
在本實驗中,作者選擇了兩種廣泛使用的基線方法Seq2Seq和CMA,以及一種具有競爭力的方法MS-MGMap(見表I)
每種方法均在四個不同的環境中進行測試,并針對兩類不同難度的指令(每個場景包含25條簡單指令和25條復雜指令)進行評估。關于真實環境實驗的詳細描述,請參見第V-A節及補充材料,實驗結果見表VI,作者發現,他們的方法在所有基線方法上均表現出顯著提升

- 端到端方法Seq2Seq、CMA等方法表現極差,作者認為這主要是由于VLN-CE與真實世界在深度和色彩域上的仿真到現實差距
- 與端到端方法相比,基于地圖的方法WS-MGMap通過利用動態語義地圖展現出更好的性能。經過精細的參數和算法調整,基于地圖的方法被廣泛認為是在現實世界中具有潛力的穩健策略[115, 77]
- 然而,NaVid通過挖掘VLM在VLN中的泛化能力,僅依賴RGB視頻即可完成大多數指令(約84%)以及相當復雜的指令(約48%)
為了進一步研究NaVid在不同指令下的泛化能力,作者展示了真實場景實驗的部分視覺結果(見表VI),這些實驗要求NaVid根據非常具體的地標和動作執行指令
- 在圖5中
作者給出了兩組相似的指令,要求機器人在不同的停止條件下向前移動。他們發現,在這兩種情況下,機器人都能夠按照指令向前移動,并在接近指定停止條件時成功停下。這表明NaVid具備理解指令并為機器人生成正確動作的能力
- 此外,他們還進行了更具挑戰性的實驗,要求機器人執行復雜指令。相關視覺結果見圖6
此時機器人需要轉向并向前移動,最終停在指定目標附近。這些指令尤其具有挑戰性,因為機器人面向的物體與目標(椅子)屬于同一語義類別。盡管如此,作者宣稱,NaVid依然能夠通過轉向目標方向并在正確目標附近停下,準確完成指令。這些實驗的視頻可見于附加的補充材料中
1.3.4 消融實驗
作者為了驗證他們方法中各個組件的有效性,他們在表 VII 中對訓練策略和網絡結構進行了消融實驗

- 通過實驗,作者發現協同微調數據對性能至關重要。這證明缺乏協同微調數據可能會導致大型基礎模型失去了泛化能力
- 正如預期,指令推理樣本和Dagger 導航動作樣本表現出提升。這啟發作者,收集更多與導航相關的數據可能進一步提升他們方法的性能,這也許是VLM 用于VLN 的后續方向
在架構消融實驗中,作者保留了內容token(指令查詢token 和與指令無關的token),并移除了特殊token:任務標識token [NAV] ,或觀察標識token [HIS] 和[OBS]
作者觀察到,移除特殊token 會導致性能明顯下降,這證明了特殊token 的有效性。Waypoint預測變體用連續的位置和朝向替換了 (詳細實現見補充材料)。然而,結果表明,直接輸出連續的位置和朝向對VLMs 來說極具挑戰性,使得VLMs 難以學習導航技能
為了全面評估指令無關視覺 token 的有效性,作者對不同視覺 token 設置進行了比較
- 具體而言,作者分析了 NaVid 在每幀采用不同數量視覺token 的表現,注意到更高的 token 數量能夠保留更多視覺信息
在本實驗中,作者分別采用了每幀 1、4 和 16 個視覺 token,這些 token 分別以 H、H/2 和 H/4 的步幅對特征圖(H × H)進行平均池化
結果如表 VIII 所示
從實驗結果可以看出,增加每幀指令無關(視覺)token 數量能夠提升性能,因為更多的視覺 token 為動作預測提供了更豐富的視覺信息
- 然而,視覺 token 數量的增加也會導致推理時間延長
作者發現
從設置(1-1 token)到設置(2-4 token),成功率提升了 56.4%,但推理時間也增加了 40.2%;
而從設置(2-4 token)到設置(3-16 token),成功率僅提升了 1.60%,但推理時間卻大幅增加了 122%
這表明,每幀采用四個視覺token 能夠在編碼導航歷史時提供足夠的視覺信息,同時保持合理的計算開銷,實現最佳平衡
此外,作者還進行了分解實驗,以驗證導航數據在圖8中的重要性。在這里,作者將訓練過程分為兩個階段:
- pre-dagger(0到33萬步)
在pre-dagger階段,作者隨機采樣導航數據進行訓練
結果發現,數據量不足(少于28萬條)時,SR、OS、SPL和NE等指標的提升較為緩慢。然而,當數據量增加到33萬條時,性能有明顯提升,表明模型開始掌握VLN任務 - post-dagger(33萬到51萬步)
在post-dagger階段,性能提升變得非常有限。其主要原因在于,R2R訓練集上的dagger方法未能為VLM提供足夠多樣化的環境或指令信息以供學習
1.4 討論與結論
本文提出了一種基于視頻的視覺-語言導航方法NaVid,用于視覺與語言導航任務。NaVid在不依賴里程計、深度傳感器或地圖的情況下,實現了當前最優的導航性能
具體來說,作者通過集成自定義特殊token,將基于視頻的視覺語言模型擴展為能夠同時編碼歷史和當前導航數據
- 為學習視覺指令跟隨能力,作者從R2R(32萬條)和Dagger(18萬條)中收集了共計51萬條動作規劃樣本,以及1萬條指令推理樣本。在模擬環境下的大量實驗表明
作者的方法僅以單目視頻作為輸入,即可達到SOTA級別的性能 - 此外,作者還在真實環境中部署了NaVid,展示了其在實際場景中執行VLN任務的泛化能力。局限性
盡管NaVid取得了令人鼓舞的成果,但仍存在若干局限性
- 首先,NaVid的計算成本較高,導致延遲時間過長,從而影響導航效率。一個有說服力的緩解方法是采用動作塊技術[119]或量化技術[61]
- 其次,在超長任務指令下,NaVid可能會因上下文token過長而出現性能下降[25],且高質量長視頻標注數據的缺乏進一步加劇了這一問題
為應對這些挑戰,可以采用更先進的大型模型[57]作為骨干,并利用長視頻數據[102]
對于未來工作
- 作者希望進一步探索將NaVid擴展到其他具身人工智能任務的潛力,例如移動操作[110, 88, 116]。為此,作者計劃研究多種動作設計,以實現對機器人機械臂和移動底座的同時控制
- 此外,收集帶有標注的移動操作視頻數據集對于幫助他們的模型理解指令,以及對象與機器人之間的物理交互至關重要
且還將致力于提升模型的運行效率,使其能夠在更高速度或更低成本的硬件上運行
// 待更
第二部分 從Matterport3D仿真器到Room-to-Room(R2R)
2017年11月,來自的研究者提出了
- 其對應的項目網站為:bringmeaspoon.org
- 其對應的paper為:Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments
在這個工作中
- 為了推動和促進視覺與語言方法在解釋基于視覺的導航指令問題中的應用,作者提出了 Matterport3D Simulator——一個基于真實圖像的大規模RL環境[11]
- 利用該模擬器(未來可支持多種具身視覺與語言任務),作者首次提供了針對真實建筑中基于視覺的自然語言導航的基準數據集——Room-to-Room(R2R)數據集
- 近年來循環神經網絡方法在圖像與自然語言聯合理解方面的成功,推動了視覺-語言導航(VLN)任務的發展,并促成了下文所述的 Room-to-Room(R2R)數據集的出現。該數據集的設計目標,正是為了簡化視覺與語言方法在此類看似遙遠問題上的應用
- 以往針對機器人自然語言指令的研究,往往忽視了視覺信息處理這一關鍵環節。例如,使用渲染圖像而非真實圖像 [7,27,62],限制了視覺信息的獲取范圍
2.1?Matterport3D 仿真器:基于Matterport3D數據集構建的RL環境
為了實現可復現的VLN方法評估,作者提出了Matterport3D模擬器。該模擬器是一個基于Matterport3D數據集[11]構建的大規模交互式RL環境,該數據集包含90個真實建筑規模室內環境的10,800張高密度采樣全景RGB-D圖像
與合成RL環境[7,27,62]相比,采用真實世界的圖像數據能夠保留視覺和語言的豐富性,從而最大化訓練Agent遷移到現實應用的潛力
2.1.1?Matterport3D 數據集
大多數 RGB-D 數據集均源自視頻序列,例如NYUv2 [42]、SUN RGB-D [48] 和 ScanNet[15]。這些數據集通常只提供一到兩條穿越場景的路徑,因此難以用于模擬機器人運動
與這些數據集相比,最近發布的 Matterport3D 數據集[11] 提供了全面的全景視圖。據作者所知,截止到2017年11月,它也是目前可用的最大規模 RGB-D 研究數據集
- 具體而言,Matterport3D 數據集由 90 個建筑級場景的194,400 張 RGB-D 圖像構建而成,共包含 10,800 個全景視圖——點位分布在每個場景可步行的整個平面上,平均間隔為 2.25 米
每個全景視圖由 18 張 RGB-D 圖像組成,這些圖像均從單一三維位置、約等于站立者高度進行采集
每張圖像都帶有精確的六自由度(6 DoF)相機位姿標注,整體上這些圖像覆蓋了除極點外的整個球面 - 數據集還包括全局對齊的有紋理三維網格,并對區域(房間)和物體進行了類別和實例分割標注。在視覺多樣性方面,所選的 Matterport 場景涵蓋了包括住宅、公寓、酒店、辦公室和教堂等多種類型和規模的建筑,這些建筑具有極高的視覺多樣性,對計算機視覺提出了真正的挑戰
數據集中許多場景可在 Matterport 3Dspaces gallery2 中進行瀏覽
2.1.2?仿真器:觀測、動作空間、實現細節、偏差
2.1.2.1?觀測
- 為了構建模擬器,作者允許一個具身智能體通過采用與全景視角重合的姿態,在場景中虛擬“移動”。智能體的姿態由三維位置
、朝向
以及相機俯仰角
,其中
是三維位置的集合與場景中全景視點相關的點
- 在每一步,模擬器輸出與智能體第一人稱攝像頭視角對應的RGB圖像觀測。圖像是通過對每個視點預先計算的立方體貼圖圖像進行透視投影生成的。未來對模擬器的擴展還將支持深度圖像觀測(RGB-D),以及以渲染的對象類別和對象實例分割形式的額外工具(基于底層Matterport3D網格注釋)
2.1.2.2?動作空間
實現模擬器的主要挑戰在于確定與狀態相關的動作空間
- 顯然,咱們希望防止智能體穿越墻壁和地板,或進入其他不可通行的空間區域。因此,在每一步,模擬器還會輸出一組下一步可達的視點
。智能體通過選擇一個新的視點
,并指定相機的朝向
和俯仰角(
)調整來與模擬器交互。動作是確定性的
- 為了確定
,對于每個場景,模擬器包含一個加權無向圖,該圖覆蓋全景視點,記為
,其中邊的存在表示機器人可以在兩個視點之間導航轉換——該邊的權重反映了它們之間的直線距離
給定導航圖G,下一個可達視點的集合定義如下:
其中,是當前視點,
是由攝像機在第?
圖3展示了一個典型導航圖的部分示例

每個導航圖平均包含117個視點,平均頂點度為4.1。相比之下,網格世界的導航圖由于存在墻壁和障礙物,平均度必須小于4
- 因此,盡管智能體的移動被離散化,但在大多數高級任務的背景下,這并不構成顯著限制。即使在實際機器人中,也未必實際或必要在每獲得新的RGB-D相機視圖時就持續重新規劃高層目標
- 實際上,即使是在理論上支持連續運動的3D模擬器中,智能體在實際操作時通常也采用離散化的動作空間 [62,16,18,47]
2.1.2.3 實現細節
Matterport3D 模擬器使用 C++ 和 OpenGL 編寫
- 除了 C++ API 外,還提供了 Python 綁定,使得該模擬器可以輕松與 Caffe [25] 和TensorFlow [1] 等深度學習框架,以及 ParlAI[39] 和 OpenAI Gym [9] 等強化學習平臺結合使用
用戶可針對圖像分辨率、視場角等參數進行多種配置 - 此外,作者還開發了一個基于 WebGL的瀏覽器可視化庫,用于通過 AmazonMechanical Turk 收集導航軌跡的文本標注,并計劃向其他研究人員開放該工具
2.2?Room-to-Room(R2R)數據集:基于Matterport3D環境收集
基于Matterport3D環境,作者收集了Room-to-Room(R2R)數據集,該數據集包含21,567條開放詞匯、眾包的導航指令,平均長度為29個單詞。每條指令描述了一條通常穿越多個房間的軌跡
如圖1所示

相關任務要求智能體根據自然語言指令,在此前未見過的建筑中導航至目標位置。作者通過多種基線方法以及基于已在其他視覺與語言任務中成功應用的方法[4,14,19]的序列到序列模型,探討了該任務的難度,尤其是在未見環境下的操作難度
// 待更



html基礎和開發工具)




 ——在職考研 199 管綜 + 英語二 30 周「順水行舟」上岸指南)
)


![ndk { setAbiFilters([‘armeabi-v7a‘, “arm64-v8a“]) }](http://pic.xiahunao.cn/ndk { setAbiFilters([‘armeabi-v7a‘, “arm64-v8a“]) })





進程地址空間)
