溫馨提示:
本篇文章已同步至"AI專題精講" Idefics3:構建和更好地理解視覺-語言模型:洞察與未來方向
摘要
視覺-語言模型(VLMs)領域,接收圖像和文本作為輸入并輸出文本的模型,正在快速發展,然而在多個關鍵方面(如數據、架構和訓練方法)仍未達成共識。本文可以視為構建VLM的教程。我們首先提供當前最先進方法的全面概述,突出每種方法的優缺點,解決該領域面臨的主要挑戰,并提出未被充分探討的研究方向。接著,我們詳細介紹了構建Idefics3-8B的實際步驟,這是一種強大的VLM,相比其前身Idefics2-8B在性能上有顯著提升,同時僅在開放數據集上進行訓練,并采用簡單的管道。這些步驟包括創建Docmatix,一個旨在提高文檔理解能力的數據集,其規模是以往數據集的240倍。我們發布了該模型以及為其訓練創建的數據集。
1 引言
視覺-語言模型(VLMs)接收圖像和文本作為輸入,并輸出文本,在文檔和圖形理解(Hu et al., 2024)、解決視覺數學問題(Gao et al., 2023)或將網頁截圖轉化為代碼(Lauren?on et al., 2024)等多個應用中非常有效。強大的開放大型語言模型(Touvron et al., 2023;Jiang et al., 2023;Team et al., 2024)和視覺編碼器(Zhai et al., 2023;Sun et al., 2023;Radford et al., 2021)的進步,使得研究人員可以在這些單模態預訓練模型的基礎上,創建能夠以更高精度解決這些任務的先進VLM(Dai et al., 2023;Liu et al., 2023;Bai et al., 2023;Lin et al., 2023;Li et al., 2023;Wang et al., 2023)。
盡管該領域取得了進展,文獻中仍突出顯示了在開發管道的關鍵方面(如數據、架構和訓練方法)的設計選擇存在多種分歧,表明該領域尚未達成共識。例如,許多最近的模型(Koh et al., 2023;Li et al., 2023;Liu et al., 2023)選擇在將圖像隱藏狀態序列與文本嵌入序列連接后,將其作為輸入送入語言模型,而Llama 3-V模型(Dubey et al., 2024)則使用交替的基于Transformer的跨注意力機制,將視覺信息融合進LLM,類似于Flamingo(Alayrac et al., 2022)。這些在VLM開發中的不同核心選擇,往往在研究論文中沒有進行消融或解釋,使得很難區分哪些決策對模型性能的影響,并評估每種方法在計算和數據效率上的權衡。
在本文中,我們首先引導讀者了解該領域中的主要研究問題,提供一個詳細的概述,討論當前的VLM方法,分析每種方法的優缺點,具體涉及:(a)用于連接預訓練語言模型與視覺編碼器的不同架構,(b)VLM訓練中采用的各種數據類型,它們的實用性以及通常引入的階段,(c)VLM的訓練方法,通常為提高效率和穩定性,分為多個階段,(d)在模型評估中遇到的挑戰。我們提出了未來的研究方向,特別是在數據方面,以提高模型性能。
在此概述的基礎上,我們詳細介紹了構建Idefics3-8B2這一強大VLM的實際步驟。Idefics3-8B在文檔理解任務上明顯超過其前身Idefics2-8B,在DocVQA(Mathew et al., 2021)上取得了13.7分的提升。為了特別提升在此任務上的能力,我們創建了Docmatix3數據集,包含240萬張圖像和950萬個問答對,來源于130萬個PDF文檔,規模是以往開放數據集的240倍。我們發布了我們的模型以及用于其訓練的數據集。
2 分析VLM架構選擇
2.1 連接單模態預訓練模型
自Frozen(Tsimpoukelli et al., 2021)和Flamingo(Alayrac et al., 2022)引入以來,大多數VLM都是基于單模態預訓練骨干模型(語言模型和/或視覺編碼器)構建的,而不是從頭開始訓練全新的模型(Koh et al., 2023;Li et al., 2023;Liu et al., 2023)。強大的開源LLM(Dubey et al., 2024;Jiang et al., 2023;Team et al., 2024)和圖像編碼器(Zhai et al., 2023;Sun et al., 2023;Radford et al., 2021)的可用性,減少了訓練這些模型的成本,使研究人員能夠在這些模型的基礎上,創建高性能的VLM(Dai et al., 2023;Koh et al., 2023;Liu et al., 2023;Vallaeys et al., 2024)。這兩個預訓練模型通常通過交叉注意力或自注意力架構連接。
2.1.1 交叉注意力架構
交叉注意力架構在Flamingo(Alayrac et al., 2022)中被引入。由視覺骨干編碼的圖像隱藏狀態用于通過新初始化的交叉注意力層調節凍結的語言模型,這些層交替插入在預訓練語言模型層之間。在這些層中,鍵和值來自視覺特征,而查詢來自語言輸入。實際上,交叉注意力模塊通常插入到LLM的每四個Transformer塊后,并增加大約1/4個LLM大小的新初始化參數。這一顯著的參數增加提升了模型的表達能力,使得模型能夠在不解凍LLM進行訓練的情況下,仍能在文本任務上表現良好。
Idefics1(Lauren?on et al., 2023)和OpenFlamingo(Awadalla et al., 2023)是Flamingo的開源復現版本。最近,Llama 3-V(Dubey et al., 2024)也采用了這種方法,將Llama 3適配為多模態。
2.1.2 自注意力架構
自注意力架構(或完全自回歸架構)在FROMAGe(Koh et al., 2023)和BLIP2(Li et al., 2023)中被引入,在這種架構中,視覺編碼器的輸出被視為令牌,并與文本令牌序列連接。整個序列然后作為輸入送入語言模型。視覺令牌序列可以選擇性地進行池化,以縮短序列,使模型在訓練和推理時都更加高效。我們將映射視覺隱藏空間到文本隱藏空間的層稱為模態投影層。圖1突出顯示了自注意力架構的不同組件。
大多數最近的VLM現在采用了這種設計,包括Llava(Liu et al., 2023)、Qwen-VL(Bai et al., 2023)、DeepSeek-VL(Lu et al., 2024)、SPHINX(Lin et al., 2023)、VILA(Lin et al., 2023)、MiniGemini(Li et al., 2024)、Monkey(Li et al., 2023)、MM1(McKinzie et al., 2024)、Idefics2(Lauren?on et al., 2024)、MiniCPM-V(Yao et al., 2024)、InternLM(Dong et al., 2024)或InternVL(Chen et al., 2024)。
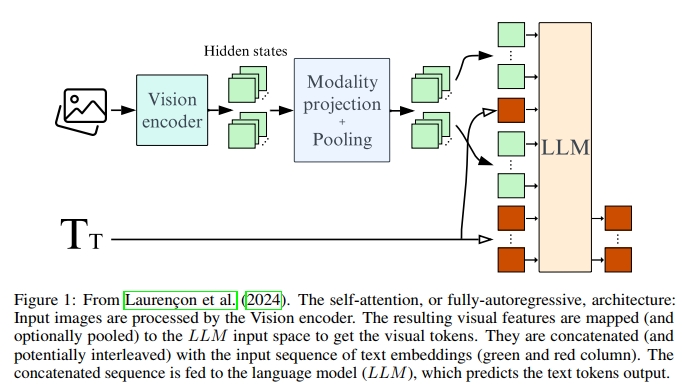
2.1.3 哪種架構表現最佳?
Lau et al. (2024) 探討了這兩種主要架構類型的性能比較。預訓練的單模態模型包括用于大語言模型(LLM)的 Mistral-7B (Jiang et al., 2023) 和用于視覺編碼器的 SigLIP-SO400M (Zhai et al., 2023)。使用自注意力架構的模型共有 83 億個參數,其中包括 7.4 億個新初始化的參數,而使用交叉注意力架構的模型共有 100 億個參數,其中包括 25 億個新初始化的參數。
作者證明,當在訓練過程中保持骨干網絡凍結時,交叉注意力架構的表現顯著優于自注意力架構。然而,當使用 LoRA (Hu et al., 2022) 訓練部分視覺編碼器和語言模型,并增加額外的 2 億可訓練參數時,盡管交叉注意力架構的參數更多,但其表現卻不如自注意力架構。
盡管如此,這項研究并未評估視覺語言模型(VLM)在僅文本基準上的表現。直觀來看,當在訓練過程中解凍部分語言模型時,我們需要將 LLM 訓練數據混合中的數據納入 VLM 訓練數據中,以保持在僅文本基準上的表現。
2.1.4 預訓練骨干網絡對性能的影響
多項研究發現,每個獨立的單模態預訓練骨干網絡的性能與最終 VLM 的表現相關。例如,在 Lauren?on et al. (2024) 中,作者展示了用 Mistral-7B (Jiang et al., 2023)(MMLU(Hendrycks et al., 2021)上得分 60.1%)替代 LLaMA-1-7B (Touvron et al., 2023)(MMLU 上得分 35.1%)后,所有基準測試上的性能都有了顯著提升。類似地,用 SigLIP-SO400M (Zhai et al., 2023)(在 ImageNet 上得分 83.2%)替代 CLIP-ViT-H (Radford et al., 2021)(在 ImageNet 上得分 78.0%),也在所有基準測試上帶來了顯著的性能提升,且沒有改變 VLM 的總參數數量。
由于視覺編碼器通常是在不同的數據集上訓練并針對不同任務進行優化,一些模型,如 SPHINX (Lin et al., 2023),結合了多個編碼器的表示,例如 DINOv2 (Oquab et al., 2023) 和 CLIP (Radford et al., 2021),從而創造出更豐富的視覺嵌入序列,盡管這樣做會犧牲計算效率。
近年來的研究主要集中在提高開放語言模型(Touvron et al., 2023;Dubey et al., 2024;Team et al., 2024;Jiang et al., 2023;Zheng et al., 2024;Conover et al., 2023;Mehta et al., 2024;Abdin et al., 2024;Hu et al., 2024;DeepSeek-AI et al., 2024;Bai et al., 2023)。相比之下,發布的開放視覺編碼器很少,其中 SigLIP-SO400M 因其僅 4 億個參數卻具有良好的性能-參數比而脫穎而出。這表明,仍然需要大規模訓練的開源視覺編碼器。
2.2 考察其他架構選擇
2.2.1 視覺編碼器真的是必需的嗎?
Fuyu (Bavishi et al., 2023) 直接將圖像塊輸入語言模型,在進行簡單的線性投影以調整維度后,不使用視覺編碼器。這種架構有兩個主要優勢:它獨立于其他預訓練模型,并且保留了原始圖像的所有信息。后者非常重要,因為原始圖像的細節可能是準確回答提示所必需的。另一方面,預訓練的視覺編碼器將圖像轉換為與用戶提示無關的表示。因此,視覺編碼器旨在盡可能多地捕捉信息,但仍可能遺漏與提示相關的細節。VisFocus (Abramovich et al., 2024) 嘗試通過將用戶的提示整合到視覺編碼器中來解決這個問題。然而,這種方法在交織的圖像-文本對話中不太自然,因為提示可能會引用之前的問題。
盡管有這些優勢,這種架構尚未表現出優于其他方法的性能。Fuyu 在基準測試中的得分顯著低于同一時期發布的類似規模的最佳模型。PaliGemma (Beyer et al., 2024) 也嘗試了這種方法,并報告了與使用預訓練視覺編碼器相比的性能顯著下降。作者建議,繞過一個在數十億圖像上預訓練的視覺編碼器可能導致訓練時間更長,才能達到類似的性能。
此外,在語言模型內處理圖像表示可能會降低其在僅文本基準上的表現。即使這種方法在多模態基準上優于其他方法,大多數 VLM 仍未在僅文本基準上進行評估,因此目前尚不清楚省略視覺編碼器是否會影響文本基準表現。
最后,這種方法尚未使用高效的池化策略來避免通過直接操作原始像素而顯著減少信息。展望未來,對于視頻理解等任務或擴展到其他模態,開發一種可以高效減少傳遞給語言模型的視覺 token 數量的架構,將有助于保持合理的序列長度。
2.2.2 應該如何將視覺編碼器連接到語言模型?
許多模型,如 FROMAGe (Koh et al., 2023) 和 LLaVA (Liu et al., 2023),在視覺編碼器和 LLM 之間使用一個簡單的線性層,確保所有編碼的視覺信息被保留,因為沒有應用池化策略。然而,這種方法會導致一個很長的視覺 token 序列,使得訓練和推理效率較低。為了解決這個問題,Qwen-VL (Bai et al., 2023) 通過在一組嵌入和圖像隱藏狀態之間使用單層交叉注意力模塊來減少視覺 token 的數量。類似地,Idefics2 (Lauren?on et al., 2024) 在感知器重采樣器 (Jaegle et al., 2021; Alayrac et al., 2022) 內部使用交叉注意力模塊,展示了視覺 token 數量可以壓縮到 64 個(除以 77),同時保持大多數任務的性能,除了那些需要大量 OCR 功能的任務。
InternLM-XComposer2-4KHD (Dong et al., 2024) 也顯示,對于 OCR 任務相關的基準(如 InfoVQA (Mathew et al., 2022) 和 DocVQA (Mathew et al., 2021)),每幅圖像的視覺 token 數量增加是必需的。
盡管感知器重采樣器的效率較高,但它的使用在幾篇論文中受到質疑,這些論文建議更有效地利用圖像的二維結構。例如,HoneyBee (Cha et al., 2024) 引入了 C-Abstractor,通過將 2D 位置嵌入重新引入到視覺特征中,之后使用 ResNet 塊 (Xie et al., 2017)。在 mPLUG-DocOwl-1.5 (Hu et al., 2024) 中,引入了 H-Reducer,使用卷積將圖像隱藏狀態的數量減少了 4 倍。InternVL (Chen et al., 2024) 也使用簡單的像素洗牌策略實現了 4 倍的壓縮。最近,MiniCPM-V 2.6 (Yao et al., 2024) 和 Idefics2 一樣,選擇了感知器重采樣器,使用 64 個可學習的嵌入,但通過添加 2D 位置嵌入進行了增強。
2.2.3 圖像切分策略:增加視覺token數量的技巧
圖像切分策略在UReader (Ye et al., 2023)和SPHINX (Lin et al., 2023)中有所介紹,它通過將原始圖像分割成多個子圖像,每個子圖像都由視覺編碼器單獨編碼。切片的數量可以是固定的,例如每張圖像始終使用四個切塊,或者根據圖像的原始分辨率變化,例如每隔N個像素進行切分。
當切片數量基于原始分辨率時,模型會使用不同數量的視覺token進行訓練。這種方法在推理時尤其具有優勢:對于較簡單的任務,所需的視覺token較少,從而節省計算資源;而對于需要進行大量OCR計算的任務,可以通過提高圖像分辨率來分配更多的計算資源。這種靈活性對于那些既需要在高計算資源下對單張圖像進行推理,又需要處理包含大量幀的視頻,同時通過降低每幀的分辨率來保持合理序列長度的模型非常有益。
大多數視覺編碼器的設計是基于相對較低的固定圖像分辨率,因此不太適合處理大圖像。圖像切分策略通過將多個較小的子圖像傳遞給視覺編碼器,而不是直接傳遞原始的大圖像,解決了這一問題。由于視覺編碼器的權重在每個子圖像中共享,這種方法也提高了訓練效率。
然而,由于圖像的切片并非獨立的,單獨編碼每個切片可能并非最優,可能會導致喪失全局上下文。為了解決這一問題,當前的策略是在切片列表中加入下采樣后的原始圖像,并將其調整為視覺編碼器支持的分辨率。盡管這樣有助于保留一些全局上下文,但并不是完美的解決方案,因為原始圖像的分辨率較低,難以捕捉更精細的細節,并且其分辨率依賴于原始圖像的分辨率。
我們能做得比圖像切分策略更好嗎?圖像切分策略的替代方案以及未來研究的一個有前景的方向是開發一種能夠原生處理不同分辨率圖像的視覺編碼器,包括非常大的圖像,而不改變原始寬高比,可能還需要引入一種有效處理長上下文的機制。該模型可以通過使用 Patch’n’Pack (Dehghani et al., 2023) 策略高效地訓練,基于原始分辨率為每個圖像生成不同數量的視覺token,從而能夠直接對整個圖像進行編碼,無需將其切分成多個子圖像。
3 VLM的訓練方法和數據集
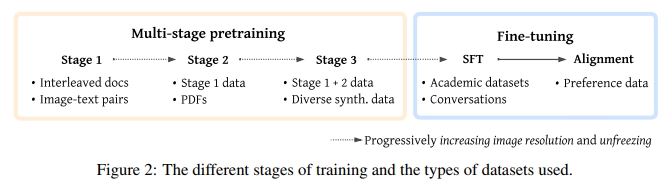
VLM的訓練通常分為多個階段,主要是由于以下原因:(a)大規模高質量數據的有限可用性,(b)高效訓練的內存約束,以及(c)穩定性問題。在這些階段中,逐步引入更高質量的數據,逐漸增加圖像的最大分辨率,并且逐步解凍更多的模型部分。圖2展示了訓練的關鍵階段以及每個階段使用的數據集類型。如前所述,訓練過程從兩個單模態預訓練骨干模型開始:一個語言模型和一個視覺編碼器。

溫馨提示:
閱讀全文請訪問"AI深語解構" Idefics3:構建和更好地理解視覺-語言模型:洞察與未來方向


)

)



)
)


 的核心介紹與使用教程)
)
)

集合類詳解)
 等待事件(1)-概述)

)