文章目錄
- ==有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主==
- 一、項目背景
- 二、研究目標與意義
- 三、數據獲取與處理
- 四、文本分析與主題建模方法
- 1. 傳統方法探索
- 2. 主題模型比較與優化
- 3. 深度語義建模與聚類
- 五、研究成果與應用價值
- 六、總結與展望
- 總結
- 每文一語
有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主
一、項目背景
隨著互聯網技術和移動終端的廣泛普及,在線旅游平臺成為游客獲取信息和表達意見的主要渠道。游客在旅行過程中積累了豐富的個體體驗,并通過在線評論的方式在平臺上進行分享。這些評論不僅真實反映了游客對景區服務、設施、環境等方面的評價,也蘊含了大量的潛在用戶需求。然而,由于在線評論數量龐大、內容形式復雜、語言表達自由,傳統的人工篩選與分析方法已難以滿足景區運營方對于高效洞察游客需求的實際要求。
因此,如何利用自然語言處理和深度學習等先進技術手段,從海量的用戶評論中自動提取有價值的信息,成為當前旅游管理與智慧景區建設中的一個研究熱點與實際需求。
二、研究目標與意義
本項目旨在通過采集與挖掘三亞地區四個主要旅游景點的在線評論數據,構建多層次的文本分析模型,識別游客對不同景區項目和服務的偏好與關注點。項目結合淺層統計方法與深度語義模型,建立一套適用于旅游評論分析的主題提取與聚類框架,以此為景區管理者提供更具針對性的優化建議,實現精準化服務和個性化營銷。
該研究不僅有助于提高景區服務質量與游客滿意度,也為旅游大數據分析提供了可復制、可擴展的方法路徑,具有重要的理論價值與實際應用前景。
三、數據獲取與處理
為了保證研究數據的廣泛性與代表性,項目選取了攜程旅行網作為數據源,圍繞三亞市的四個熱門景點展開分析,分別為:亞特蘭蒂斯水世界、蜈支洲島、亞龍灣熱帶天堂森林公園和天涯海角。
通過自編Python網絡爬蟲程序,團隊成功獲取了來自上述景點的數萬條游客評論數據。每條評論包括但不限于評論文本、評分等級、點贊數、發布時間和用戶身份信息等。為了規避平臺的反爬蟲機制,數據采集過程中采用了動態請求頭、訪問延遲控制與模擬用戶瀏覽等策略,有效保障了數據獲取的穩定性與連續性。
在數據預處理階段,首先對來自各景區的原始評論文件進行合并,并剔除了重復記錄和缺失字段,確保數據完整性。隨后利用中文分詞工具(如jieba)進行文本分詞,同時引入常用停用詞庫,對評論內容進行清洗與規范化,為后續的文本建模打下基礎。
四、文本分析與主題建模方法
1. 傳統方法探索
初期嘗試使用TF-IDF(Term Frequency-Inverse Document Frequency)方法對評論文本進行關鍵詞提取與主題判斷。雖然該方法在信息檢索中具有良好表現,但在實際應用中發現其對長文本與語義邊界識別能力不足,難以揭示評論中隱含的多層次主題關系。
2. 主題模型比較與優化
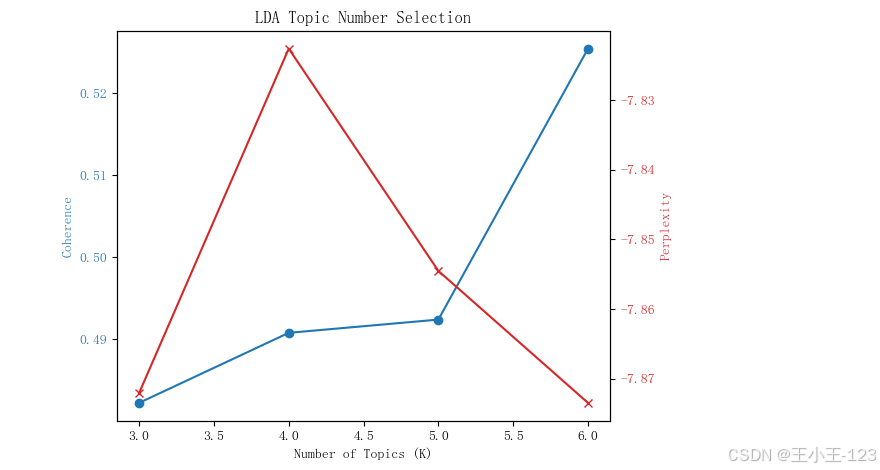
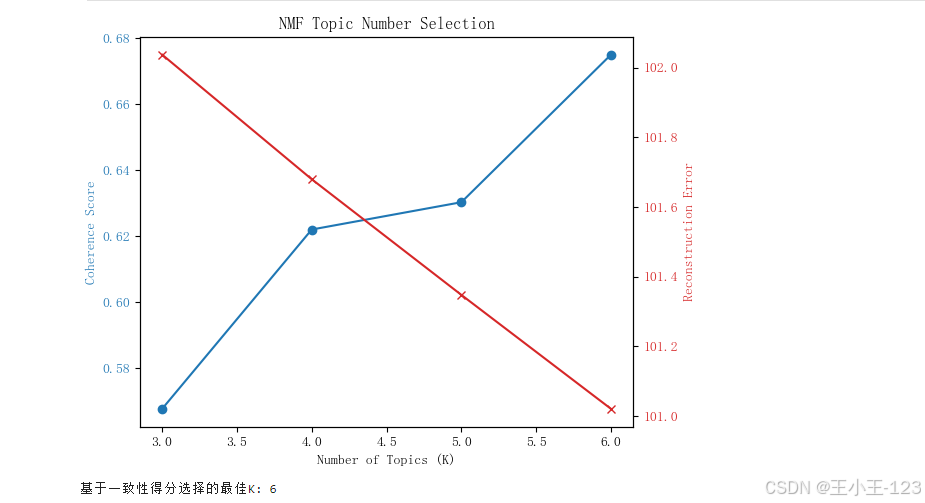
為了更全面地理解游客評論背后的核心主題,項目引入了兩種主流的主題建模方法:LDA(Latent Dirichlet Allocation)和NMF(Non-negative Matrix Factorization)。在模型訓練過程中,分別計算了主題一致性(coherence)和困惑度(perplexity)指標,綜合評估兩種模型在不同主題數下的表現。
研究結果表明:NMF模型在本數據集上展現出更高的語義聚焦能力,生成的主題更具可讀性,能夠準確識別游客對具體項目的關注,如“蜈支洲島的潛水體驗”、“亞龍灣的玻璃棧道”、“天涯海角的拍照打卡”等具體偏好。這種細粒度的主題劃分對景區項目優化和資源配置具有較高的實用價值。
3. 深度語義建模與聚類
為進一步提升語義提取的精度,項目引入了基于BERT預訓練語言模型的句向量生成方法。BERT(Bidirectional Encoder Representations from Transformers)能夠捕捉評論語句中上下文間的深層語義關系,尤其在處理口語化、非結構化文本方面具有顯著優勢。
在得到每條評論的高維句向量后,利用K-Means算法對評論進行聚類分析,最終提取出若干個高相似度的評論群組。這些群組之間具有明確的情感傾向和內容特征,便于景區管理者快速掌握游客在交通、服務態度、排隊時間、項目體驗等方面的主要反饋內容。
五、研究成果與應用價值
本項目結合多種文本分析技術,成功構建了一個適用于旅游評論數據的“獲取—清洗—建模—分析—應用”的完整流程。研究成果不僅從數據層面清晰呈現了游客關注的熱點話題與潛在痛點,還通過可視化手段將模型輸出結果轉化為直觀、易解讀的圖表和主題詞云,極大提升了非技術用戶的理解效率。
該分析框架已在三亞市某大型景區運營團隊中進行試點應用,為其定制營銷活動、優化導覽路徑、增強游客互動等方面提供了有力支撐。未來,該框架還可推廣至全國其他旅游熱點城市,支持更加智能、精準的文旅管理體系建設。
六、總結與展望
本研究通過融合機器學習與深度學習模型,創新性地構建了面向旅游評論數據的多層次語義識別機制,有效提升了用戶需求挖掘的效率與精度。下一步,項目計劃引入情感分析與多模態數據融合(如圖文評論分析),進一步豐富游客畫像與情境識別能力。同時,將探索實時分析與反饋機制的部署方式,為旅游行業的數字化轉型與智慧景區建設提供更具前瞻性的解決方案。


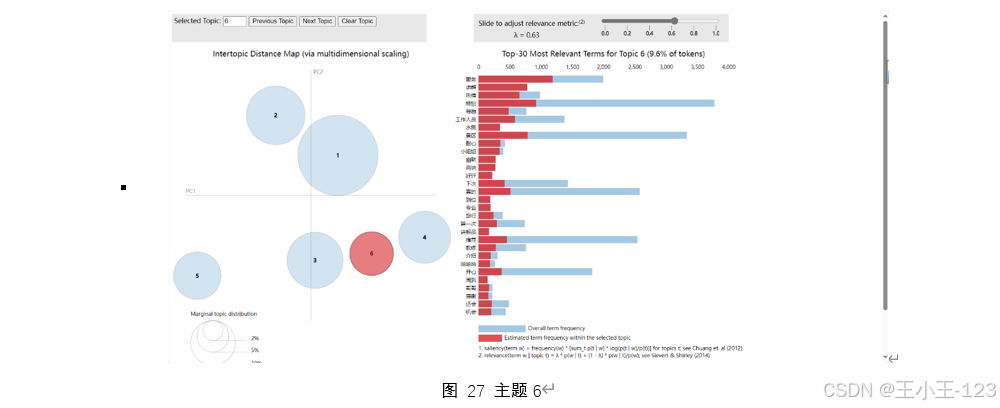

該主題清晰指向了“三亞天涯海角”景區。核心關鍵詞有“石頭”、“海邊”、“拍照”、“門票”、“沙灘”等。天涯海角景區最具代表性的標志就是海邊獨特造型的巨型石頭,而拍照打卡和欣賞海景正是游客來到此地的主要目的之一。從游客的實際評論出發,可以觀察到游客更加關注于景區自然環境的美麗以及景點的標志性特征,NMF模型精準抓住這一景區特點,清晰地體現出與景點關聯度高的關鍵詞,表現出相較于其他主題模型更高的景區特征提取能力。
總結
在本研究中,我嘗試將多種文本主題提取技術應用于旅游評論數據,旨在探索一種既具備語義聚合能力,又具備良好可解釋性的分析路徑。研究從中文分詞后的評論語料出發,先后采用傳統的主題模型方法,并逐步引入語義向量表達與深度學習手段,通過對比實驗評估不同方法的適用性與效果。
在初步階段,選用了TF-IDF方法作為文本特征提取的起點,并通過人工解讀關鍵詞來理解語義主題。但由于該方法依賴詞頻權重,缺乏語境理解能力,其在主題邊界識別方面存在明顯不足。隨后,我引入了LDA(潛在狄利克雷分配)模型,并結合“困惑度”和“主題一致性”等指標,輔助判斷最佳主題數。實驗表明,盡管LDA可以初步對評論文本進行方向性劃分,但生成的主題之間存在較大重疊,關鍵詞容易分散在多個主題中,語義聚焦不明顯。尤其是在旅游評論這類包含大量感性表達和場景描述的文本中,LDA難以有效剝離具體地名、項目名稱與情緒性詞匯的混合,導致主題抽象不清晰,更適用于結構統一、用詞規范的文本場景。
為優化建模效果,我進一步嘗試了NMF(非負矩陣分解)模型,在TF-IDF特征基礎上對評論文本進行線性分解,形成更具辨析力的主題空間。結果顯示,NMF在提取景區特征和游客興趣點方面表現更優,特別是在主題集中性和關鍵詞清晰度方面具有顯著優勢。例如,該方法能夠有效聚合出“親子娛樂”“自然景觀拍照”“講解服務體驗”等具體主題類別。詞云結果也表明,NMF生成的主題內關鍵詞語義更為統一,主題邊界更清晰,展現出其在非結構化內容聚類中的良好表現。
為了進一步增強模型對上下文信息的理解能力,我引入了基于BERT預訓練語言模型的語義表示方法,并結合K-Means聚類算法對評論進行向量化處理與聚類分析。該方法通過上下文敏感的句子編碼方式,準確捕捉評論中的深層語義特征。實驗結果表明,相較于傳統主題模型,BERT向量與K-Means組合能顯著提高語義聚類的純度,主題區分度更強,邊界更明確。例如,有的聚類集中體現“視覺景觀”“自然生態”等景區特色,部分則強調“項目互動性”“親子游玩”等功能需求,還有一類明顯聚焦于“島嶼風格與特色項目組合”等細分主題。這種基于句向量的深度建模在處理口語化、內容跳躍性強的旅游評論時,表現出更高的適配性和識別能力。
總體而言,BERT-KMeans方法在語義辨析與主題清晰度方面遠優于LDA與NMF,尤其適合應對用戶表達多樣、意圖模糊的文本場景。實驗結果也表明,借助深度語言模型進行語義建模,為旅游評論類數據提供了更高質量的主題分析結果,具備良好的推廣潛力和實際應用價值。
每文一語
抓住機會,學習一個新的境界
 的核心介紹與使用教程)
)
)

集合類詳解)
 等待事件(1)-概述)

)











)