言不信者行不果,行不敏者言多滯.
目錄
4. 集合類
4.1 集合類概述
4.1.1 集合框架遵循原則
4.1.2 集合框架體系
?4.2 核心接口和實現類解析
4.2.1 Collection 接口體系
4.2.1.1 Collection 接口核心定義
4.2.1.2?List接口詳解
4.2.1.3 Set 接口詳解
4.2.1.4?Queue/Deque接口詳解
4.2.2 Map 接口體系詳解
?4.3 集合類選擇
4.3.1 集合類選擇指南
4.3.2?集合類選擇決策樹
4.4?性能優化建議
4.5 總結
續前篇:編程語言Java——核心技術篇(三)異常處理詳解-CSDN博客
4. 集合類
Java集合框架(Java Collections Framework, JCF)是Java語言中用于存儲和操作數據集合的一組接口和類。它提供了一套標準化的數據結構實現,使開發者能夠高效地處理數據。
4.1 集合類概述
4.1.1 集合框架遵循原則
集合框架的設計遵循了幾個重要原則:
-
接口與實現分離:所有具體集合類都實現自標準接口(如List、Set、Map),這使得程序可以靈活切換不同的實現而不影響業務邏輯。
-
算法復用:Collections工具類提供了大量通用算法(如排序、查找、反轉等),這些算法可以應用于任何實現了相應接口的集合類。
-
性能優化:針對不同使用場景提供了多種實現,如需要快速隨機訪問選擇ArrayList,需要頻繁插入刪除選擇LinkedList。
-
擴展性:通過迭代器模式(Iterator)和比較器(Comparator)等設計,使集合框架易于擴展和定制。
-
類型安全:通過泛型機制在編譯期檢查類型一致性,避免了運行時的類型轉換錯誤。
4.1.2 集合框架體系
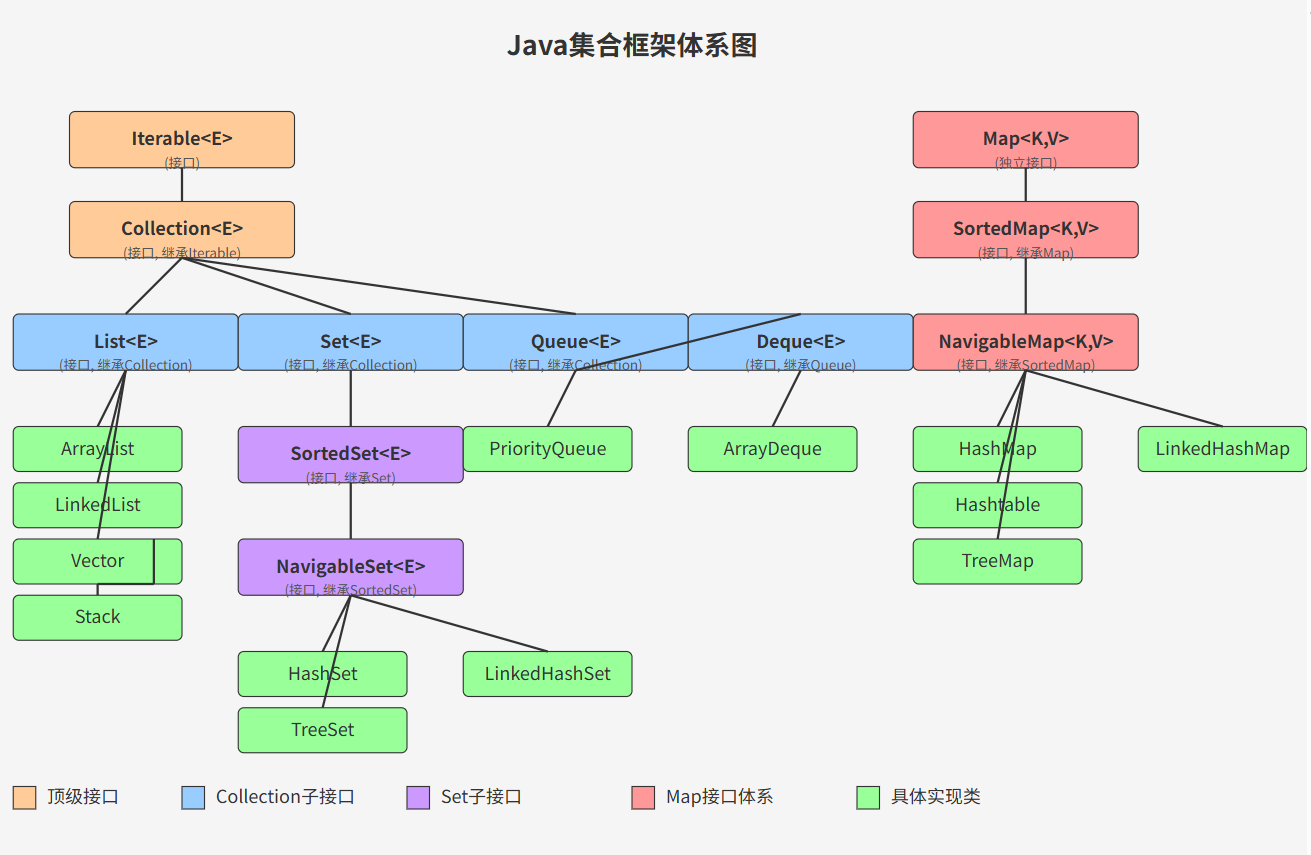
這張圖很清楚了,兩個頂級父類接口Iterable和Map,剩下的List,Set和Queue等都是兩個接口的實現子接口,在下來才是各種實現類。如果只但看各個接口之間的繼承關系還有下面這張圖:
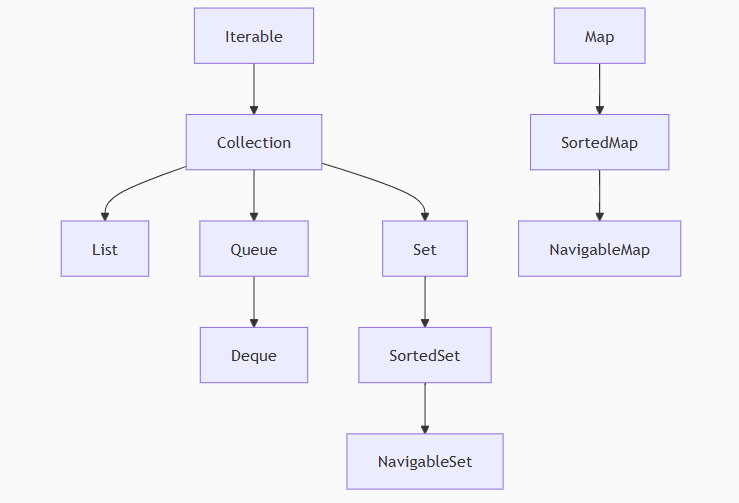
我感覺這兩個圖可以詳細地記一下,因為適用性挺廣的,存放數據和操作都會頻繁地遇到集合類。?
?4.2 核心接口和實現類解析
4.2.1 Collection 接口體系
4.2.1.1 Collection 接口核心定義
Collection是單列集合的根接口,定義了集合的通用行為:
public interface Collection<E> extends Iterable<E> {// 基本操作int size();boolean isEmpty();boolean contains(Object o);Iterator<E> iterator();Object[] toArray();<T> T[] toArray(T[] a);// 修改操作boolean add(E e);boolean remove(Object o);// 批量操作boolean containsAll(Collection<?> c);boolean addAll(Collection<? extends E> c);boolean removeAll(Collection<?> c);boolean retainAll(Collection<?> c);void clear();// Java 8新增boolean removeIf(Predicate<? super E> filter);Spliterator<E> spliterator();Stream<E> stream();Stream<E> parallelStream();
}4.2.1.2?List接口詳解
1. 核心特性:
-
有序集合:元素按插入順序存儲,可通過索引精確訪問
-
元素可重復:允許存儲相同元素(包括null)
-
位置訪問:提供基于索引的增刪改查方法
特有方法:
// 位置訪問
E get(int index);
E set(int index, E element);
void add(int index, E element);
E remove(int index);// 搜索
int indexOf(Object o);
int lastIndexOf(Object o);// 范圍操作
List<E> subList(int fromIndex, int toIndex);// Java 8新增
default void replaceAll(UnaryOperator<E> operator);
default void sort(Comparator<? super E> c);2. 實現類對比
| 對比維度 | ArrayList | LinkedList | Vector |
|---|---|---|---|
| 底層數據結構 | 動態數組 | 雙向鏈表 | 動態數組 |
| 內存布局 | 連續內存空間 | 離散節點存儲 | 連續內存空間 |
| 初始容量 | 10 (首次添加時初始化) | 無固定容量概念 | 10 |
| 擴容機制 | 1.5倍增長 (int newCapacity = oldCapacity + (oldCapacity >> 1)) | 無需擴容,動態增加節點 | 2倍增長 (capacityIncrement>0時按指定值增長) |
| 隨機訪問性能 | O(1) - 直接數組索引訪問 | O(n) - 需要遍歷鏈表 | O(1) |
| 頭部插入性能 | O(n) - 需要移動所有元素 | O(1) - 修改頭節點引用 | O(n) |
| 尾部插入性能 | O(1)攤銷 (考慮擴容) | O(1) - 修改尾節點引用 | O(1) |
| 中間插入性能 | O(n) - 平均需要移動一半元素 | O(n) - 需要先找到位置 | O(n) |
| 刪除操作性能 | O(n) - 類似插入 | O(1) - 找到節點后只需修改引用 | O(n) |
| 內存占用 | 較少 (僅需存儲元素和數組引用) | 較高 (每個元素需要額外前后節點引用) | 與ArrayList類似 |
| 緩存友好性 | 好 (空間局部性原理) | 差 | 好 |
| 線程安全性 | 非線程安全 | 非線程安全 | 線程安全 (方法級synchronized) |
| 迭代器安全性 | 快速失敗 (fail-fast) | 快速失敗 | 線程安全但迭代時仍需外部同步 |
| 序列化支持 | 自定義序列化 (transient數組+size) | 自定義序列化 | 同ArrayList |
| 最佳適用場景 | 讀多寫少,隨機訪問頻繁 | 寫多讀少,頻繁在頭尾操作 | 需要線程安全的場景 (已過時) |
?3. ArrayList 示例
// 創建ArrayList
List<String> arrayList = new ArrayList<>();// 添加元素
arrayList.add("Java");
arrayList.add("Python");
arrayList.add(1, "C++"); // 在指定位置插入// 訪問元素
String lang = arrayList.get(0); // "Java"// 遍歷方式1:for循環
for (int i = 0; i < arrayList.size(); i++) {System.out.println(arrayList.get(i));
}// 遍歷方式2:增強for循環
for (String language : arrayList) {System.out.println(language);
}// 遍歷方式3:迭代器
Iterator<String> it = arrayList.iterator();
while (it.hasNext()) {System.out.println(it.next());
}// 刪除元素
arrayList.remove("Python"); // 按對象刪除
arrayList.remove(0); // 按索引刪除// 轉換為數組
String[] array = arrayList.toArray(new String[0]);// Java 8操作
arrayList.removeIf(s -> s.length() < 3); // 刪除長度小于3的元素
arrayList.replaceAll(String::toUpperCase); // 全部轉為大寫ArrayList常用的方法都在這里了。我們可以把ArrayList就看成一個動態數組,實際上ArrayList比較適合查詢數組內地各個元素,但在增刪改上地性能較差。
4. LinkedList 示例
// 創建LinkedList
LinkedList<String> linkedList = new LinkedList<>();// 添加元素
linkedList.add("Apple");
linkedList.addFirst("Banana"); // 添加到頭部
linkedList.addLast("Orange"); // 添加到尾部
linkedList.add(1, "Grape"); // 在指定位置插入// 隊列操作
linkedList.offer("Pear"); // 添加到隊尾
String head = linkedList.poll(); // 移除并返回隊頭// 棧操作
linkedList.push("Cherry"); // 壓棧
String top = linkedList.pop(); // 彈棧// 獲取元素
String first = linkedList.getFirst();
String last = linkedList.getLast();// 遍歷方式:降序迭代器
Iterator<String> descIt = linkedList.descendingIterator();
while (descIt.hasNext()) {System.out.println(descIt.next());
}這里刻意強調一下棧操作。LinkedList 實現了 Deque(雙端隊列)接口,因此可以作為棧(Stack)使用。棧是一種后進先出(LIFO)的數據結構,實際上就是數據接口的知識。
// 將元素推入棧頂(實際添加到鏈表頭部)入棧
LinkedList<String> stack = new LinkedList<>();
stack.push("A"); // 棧底 ← "A" → 棧頂
stack.push("B"); // 棧底 ← "A" ← "B" → 棧頂
stack.push("C"); // 棧底 ← "A" ← "B" ← "C" → 棧頂String top = stack.pop(); // 移除并返回棧頂元素 "C" 出棧
// 現在棧狀態:棧底 ← "A" ← "B" → 棧頂String peek = stack.peek(); // 返回 "B"(棧頂元素)
// 棧保持不變:棧底 ← "A" ← "B" → 棧頂4.2.1.3 Set 接口詳解
1. 核心特性:
-
元素唯一性:不包含重復元素(依據equals()判斷)
-
無序性:不保證維護插入順序(TreeSet/LinkedHashSet除外)
-
數學集合:支持并集、交集、差集等操作
2. 實現類對比
| 對比維度 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 底層實現 | 基于HashMap | 繼承HashSet,使用LinkedHashMap | 基于TreeMap |
| 數據結構 | 哈希表+鏈表/紅黑樹 | 哈希表+鏈表+雙向鏈表 | 紅黑樹 |
| 元素順序 | 無序 | 插入順序 | 自然順序/Comparator定義順序 |
| null值支持 | 允許一個null元素 | 允許一個null元素 | 不允許null元素 |
| 基本操作復雜度 | 平均O(1) | 平均O(1) | O(log n) |
| 內存開銷 | 較低 | 較高 (額外維護雙向鏈表) | 較高 (樹結構開銷) |
| 構造方法 | 可指定初始容量和負載因子 | 同HashSet | 可提供Comparator |
| 迭代順序 | 不穩定 | 插入順序穩定 | 排序順序穩定 |
| 性能特點 | 插入刪除極快 | 插入刪除稍慢于HashSet | 插入刪除較慢但有序 |
| 額外方法 | 無 | 無 | 提供first(), last(), subSet()等導航方法 |
| 線程安全性 | 非線程安全 | 非線程安全 | 非線程安全 |
| 哈希沖突解決 | 鏈地址法,JDK8后鏈表轉紅黑樹 | 同HashSet | 不適用 |
| 擴容機制 | 默認16→32→64... 負載因子0.75 | 同HashSet | 無需擴容 |
| 比較方式 | equals()和hashCode() | 同HashSet | Comparable或Comparator |
| 典型應用場景 | 需要快速判斷元素是否存在 | 需要保持插入順序的集合 | 需要有序集合或范圍查詢 |
3.? HashSet 示例
// 創建HashSet
Set<String> hashSet = new HashSet<>();// 添加元素
hashSet.add("Java");
hashSet.add("Python");
hashSet.add("Java"); // 重復元素不會被添加// 判斷包含
boolean hasJava = hashSet.contains("Java"); // true// 刪除元素
hashSet.remove("Python");// 遍歷
for (String language : hashSet) {System.out.println(language);
}// 集合運算
Set<String> otherSet = new HashSet<>(Arrays.asList("C++", "Java", "JavaScript"));hashSet.retainAll(otherSet); // 交集
hashSet.addAll(otherSet); // 并集
hashSet.removeAll(otherSet); // 差集4.?LinkedHashSet示例
// 創建LinkedHashSet(保持插入順序)
Set<String> linkedHashSet = new LinkedHashSet<>();linkedHashSet.add("First");
linkedHashSet.add("Second");
linkedHashSet.add("Third");// 遍歷順序與插入順序一致
for (String item : linkedHashSet) {System.out.println(item); // 輸出順序:First, Second, Third
}// 移除并添加,順序會變
linkedHashSet.remove("Second");
linkedHashSet.add("Second");// 現在順序:First, Third, SecondLinkedHashSet能夠保持插入順序,即刪除時后面元素會自動補位,增添元素時會自動退位;但HashSet不會,不管組內元素如何變化,其他元素均不變。
5.?TreeSet示例
// 創建TreeSet(自然排序)
Set<String> treeSet = new TreeSet<>();treeSet.add("Orange");
treeSet.add("Apple");
treeSet.add("Banana");// 自動排序輸出
for (String fruit : treeSet) {System.out.println(fruit); // Apple, Banana, Orange
}// 定制排序
Set<Integer> customSort = new TreeSet<>((a, b) -> b - a); // 降序
customSort.addAll(Arrays.asList(5, 3, 9, 1));// 輸出:9, 5, 3, 1// 導航方法
TreeSet<Integer> nums = new TreeSet<>(Arrays.asList(1, 3, 5, 7, 9));Integer lower = nums.lower(5); // 3 (小于5的最大元素)
Integer higher = nums.higher(5); // 7 (大于5的最小元素)
Integer floor = nums.floor(4); // 3 (小于等于4的最大元素)
Integer ceiling = nums.ceiling(6); // 7 (大于等于6的最小元素)// 范圍視圖
Set<Integer> subSet = nums.subSet(3, true, 7, false); // [3, 5]4.2.1.4?Queue/Deque接口詳解
1. Queue核心方法:
| 操作類型 | 拋出異常的方法 | 返回特殊值的方法 |
|---|---|---|
| 插入 | add(e) | offer(e) |
| 移除 | remove() | poll() |
| 檢查 | element() | peek() |
?2. 實現類對比
| 對比維度 | PriorityQueue | ArrayDeque | LinkedList |
|---|---|---|---|
| 底層結構 | 二叉堆(數組實現) | 循環數組 | 雙向鏈表 |
| 排序特性 | 自然順序/Comparator | 無 | 無 |
| 容量限制 | 無界(自動擴容) | 可選有界(默認16) | 無界 |
| null值允許 | 不允許 | 不允許 | 允許 |
| 基本操作復雜度 | 插入O(log n),獲取O(1) | 兩端操作O(1) | 兩端操作O(1),中間操作O(n) |
| 線程安全性 | 非線程安全 | 非線程安全 | 非線程安全 |
| 內存使用 | 緊湊(數組) | 非常緊湊 | 較高(節點開銷) |
| 擴容策略 | 小規模+50%,大規模+25% | 雙倍增長 | 動態增加節點 |
| 迭代順序 | 按優先級順序 | FIFO/LIFO順序 | 插入順序 |
| 特殊方法 | comparator() | 無 | 大量列表操作方法 |
| 最佳適用場景 | 任務調度,需要自動排序 | 高性能棧/隊列實現 | 需要同時作為隊列和列表使用 |
| 實現接口 | Queue | Deque | List, Deque |
?3.?PriorityQueue示例
// 創建優先級隊列(自然排序)
PriorityQueue<Integer> pq = new PriorityQueue<>();pq.add(30);
pq.add(10);
pq.add(20);// 取出時會按順序
while (!pq.isEmpty()) {System.out.println(pq.poll()); // 10, 20, 30
}// 定制排序
PriorityQueue<String> customPq = new PriorityQueue<>((s1, s2) -> s2.length() - s1.length()); // 按長度降序customPq.add("Apple");
customPq.add("Banana");
customPq.add("Pear");// 輸出:Banana, Apple, Pear2. ArrayDeque示例
// 創建ArrayDeque
Deque<String> deque = new ArrayDeque<>();// 作為棧使用
deque.push("First");
deque.push("Second");
String top = deque.pop(); // "Second"// 作為隊列使用
deque.offer("Third");
deque.offer("Fourth");
String head = deque.poll(); // "First"// 雙端操作
deque.addFirst("Front");
deque.addLast("End");
String first = deque.getFirst(); // "Front"
String last = deque.getLast();?? // "End"4.2.2 Map 接口體系詳解
1. 核心定義
public interface Map<K,V> {// 基本操作int size();boolean isEmpty();boolean containsKey(Object key);boolean containsValue(Object value);V get(Object key);V put(K key, V value);V remove(Object key);// 批量操作void putAll(Map<? extends K, ? extends V> m);void clear();// 集合視圖Set<K> keySet();Collection<V> values();Set<Map.Entry<K, V>> entrySet();// 內部Entry接口interface Entry<K,V> {K getKey();V getValue();V setValue(V value);// Java 8新增boolean equals(Object o);int hashCode();public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey()// ...}// Java 8新增方法default V getOrDefault(Object key, V defaultValue)default void forEach(BiConsumer<? super K, ? super V> action)default V putIfAbsent(K key, V value)default boolean remove(Object key, Object value)default boolean replace(K key, V oldValue, V newValue)default V replace(K key, V value)default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function)default V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)// ...
}這里是Java的源碼,可以看到Map實際上放的是一對K-V鍵值對。
2. 實現類對比
| 對比維度 | HashMap | LinkedHashMap | TreeMap |
|---|---|---|---|
| 繼承體系 | AbstractMap | 繼承HashMap | AbstractMap |
| 底層結構 | 數組+鏈表/紅黑樹 | 數組+鏈表/紅黑樹+雙向鏈表 | 紅黑樹 |
| 鍵值順序 | 無序 | 插入順序/訪問順序 | 鍵的自然順序/Comparator順序 |
| null鍵值支持 | 允許null鍵和null值 | 同HashMap | 不允許null鍵 |
| 初始容量 | 16 | 同HashMap | 無容量概念 |
| 擴容機制 | 2^n增長,負載因子0.75 | 同HashMap | 無需擴容 |
| 基本操作復雜度 | 平均O(1) | 平均O(1) | O(log n) |
| 線程安全性 | 非線程安全 | 非線程安全 | 非線程安全 |
| 迭代器類型 | fail-fast | fail-fast | fail-fast |
| 額外功能 | 無 | 可設置訪問順序(LRU實現) | 導航方法(如ceilingKey) |
| 哈希算法 | (h = key.hashCode()) ^ (h >>> 16) | 同HashMap | 不適用 |
| 樹化閾值 | 鏈表長度≥8且桶數量≥64 | 同HashMap | 不適用 |
| 序列化方式 | 自定義 | 同HashMap | 同HashMap |
| 推薦場景 | 大多數鍵值對存儲場景 | 需要保持插入/訪問順序 | 需要有序映射或范圍查詢 |
3. HashMap示例
// 創建HashMap
Map<String, Integer> hashMap = new HashMap<>();// 添加鍵值對
hashMap.put("Apple", 10);
hashMap.put("Banana", 20);
hashMap.put("Orange", 15);// 獲取值
int apples = hashMap.get("Apple"); // 10
int defaultValue = hashMap.getOrDefault("Pear", 0); // 0// 遍歷方式1:entrySet
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {System.out.println(entry.getKey() + ": " + entry.getValue());
}// 遍歷方式2:keySet
for (String key : hashMap.keySet()) {System.out.println(key);
}// 遍歷方式3:values
for (int value : hashMap.values()) {System.out.println(value);
}// Java 8操作
hashMap.forEach((k, v) -> System.out.println(k + " => " + v));
hashMap.computeIfAbsent("Pear", k -> 5); // 如果不存在則添加
hashMap.merge("Apple", 5, Integer::sum); // Apple數量增加54. LinkedHashMap示例
// 創建LinkedHashMap(保持插入順序)
Map<String, Integer> linkedHashMap = new LinkedHashMap<>();linkedHashMap.put("First", 1);
linkedHashMap.put("Second", 2);
linkedHashMap.put("Third", 3);// 遍歷順序與插入順序一致
linkedHashMap.forEach((k, v) -> System.out.println(k)); // First, Second, Third// 按訪問順序排序的LinkedHashMap(可用于LRU緩存)
Map<String, Integer> accessOrderMap = new LinkedHashMap<>(16, 0.75f, true);accessOrderMap.put("One", 1);
accessOrderMap.put("Two", 2);
accessOrderMap.put("Three", 3);accessOrderMap.get("Two"); // 訪問Two會使它移動到末尾// 現在順序:One, Three, Two5. TreeMap示例
// 創建TreeMap(按鍵自然排序)
Map<String, Integer> treeMap = new TreeMap<>();treeMap.put("Orange", 5);
treeMap.put("Apple", 10);
treeMap.put("Banana", 8);// 按鍵排序輸出
treeMap.forEach((k, v) -> System.out.println(k)); // Apple, Banana, Orange// 定制排序
Map<String, Integer> reverseMap = new TreeMap<>(Comparator.reverseOrder());
reverseMap.putAll(treeMap);// 輸出順序:Orange, Banana, Apple// 導航方法
TreeMap<Integer, String> employeeMap = new TreeMap<>();
employeeMap.put(1001, "Alice");
employeeMap.put(1002, "Bob");
employeeMap.put(1003, "Charlie");Map.Entry<Integer, String> entry = employeeMap.floorEntry(1002); // 1002=Bob
Integer higherKey = employeeMap.higherKey(1001); // 1002// 范圍視圖
Map<Integer, String> subMap = employeeMap.subMap(1001, true, 1003, false); // 1001-1002紅黑樹特性:
-
每個節點是紅色或黑色
-
根節點是黑色
-
所有葉子節點(NIL)是黑色
-
紅色節點的子節點必須是黑色
-
從任一節點到其每個葉子的路徑包含相同數目的黑色節點
主要是TreeMap的底層結構就是紅黑樹,這里建議惡補一下數據結構的知識——紅黑樹、鏈表、二叉堆和二叉樹等,方便理解。這里放兩個鏈接:
二叉樹和堆詳解(通俗易懂)_堆和二叉樹的區別-CSDN博客
【數據結構】紅黑樹超詳解 ---一篇通關紅黑樹原理(含源碼解析+動態構建紅黑樹)_紅黑樹的原理-CSDN博客
?
?4.3 集合類選擇
4.3.1 集合類選擇指南
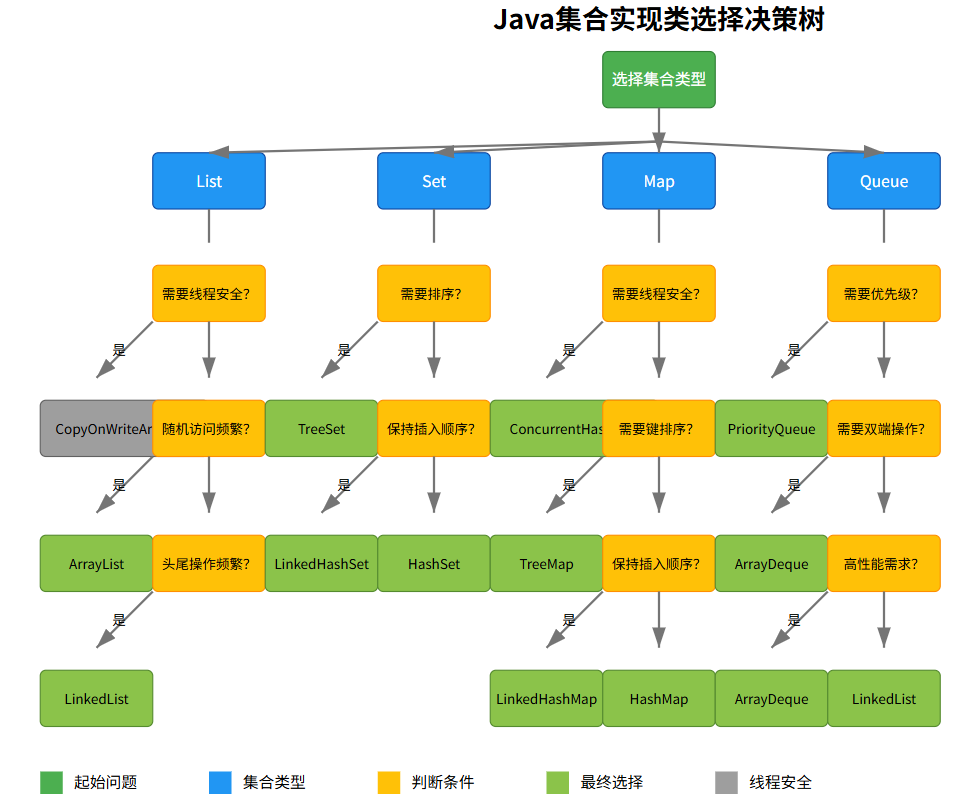
-
需要存儲鍵值對時:
-
不需要排序:HashMap
-
需要保持插入/訪問順序:LinkedHashMap
-
需要按鍵排序:TreeMap
-
需要線程安全:ConcurrentHashMap
-
-
只需要存儲元素時:
-
允許重復、需要索引:ArrayList/LinkedList
-
不允許重復、不關心順序:HashSet
-
不允許重復、需要保持插入順序:LinkedHashSet
-
不允許重復、需要排序:TreeSet
-
-
需要隊列功能時:
-
普通隊列:ArrayDeque
-
優先級隊列:PriorityQueue
-
線程安全隊列:LinkedBlockingQueue
-
-
需要線程安全時:
-
List:CopyOnWriteArrayList
-
Set:CopyOnWriteArraySet
-
Map:ConcurrentHashMap
-
Queue:LinkedBlockingQueue
-
4.3.2?集合類選擇決策樹
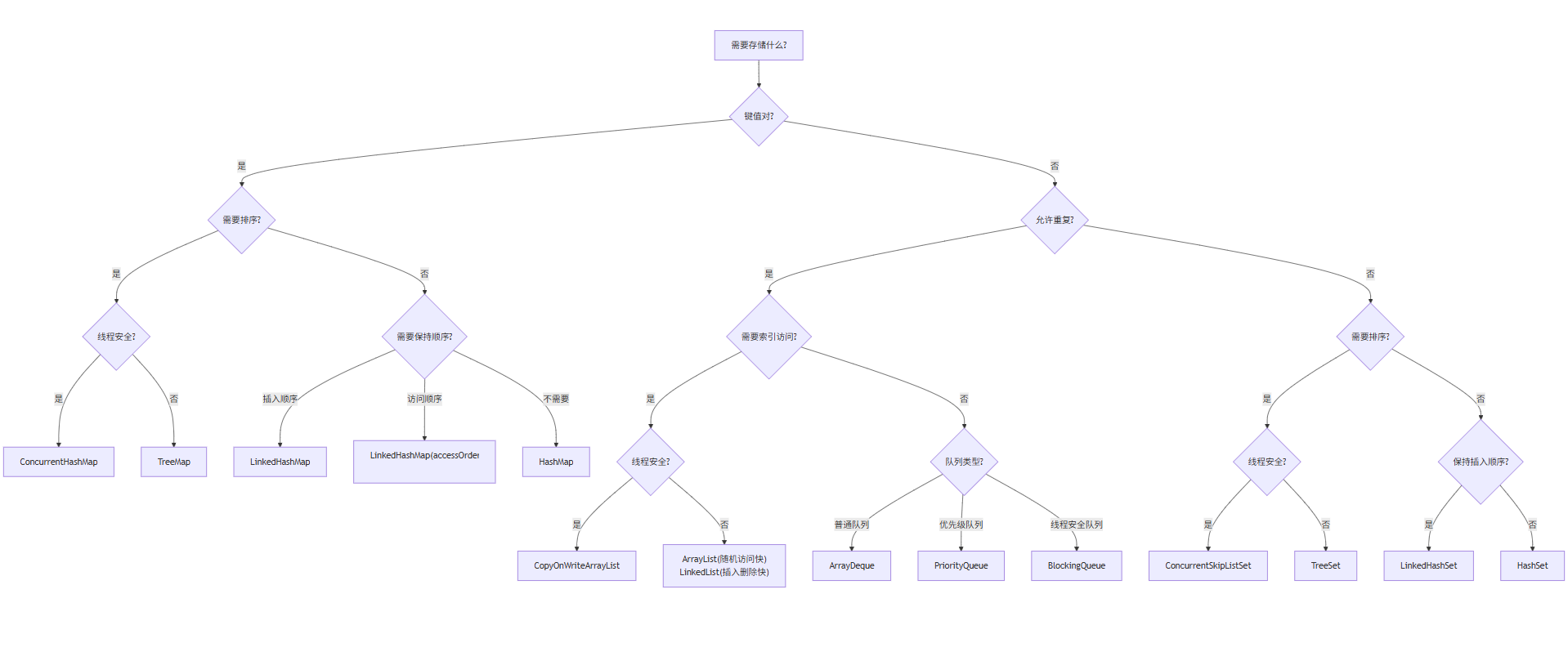
字有點小,建議點開了以后放大看 !!
決策樹文字說明:
-
第一層決策:存儲類型
-
鍵值對 → 進入Map分支
-
單元素 → 進入Collection分支
-
-
Map分支選擇邏輯:
-
需要排序?→?
TreeMap(自然排序)或ConcurrentSkipListMap(線程安全排序) -
不需要排序但需要順序?→?
LinkedHashMap(可配置插入順序或訪問順序) -
都不需要 →?
HashMap(最高性能)或ConcurrentHashMap(線程安全)
-
-
Collection分支選擇邏輯:
-
允許重復(List/Queue):
-
需要索引 →?
ArrayList(隨機訪問快)或LinkedList(插入刪除快) -
需要隊列 →?
ArrayDeque(標準隊列)或PriorityQueue(優先級隊列) -
線程安全 →?
CopyOnWriteArrayList或BlockingQueue實現類
-
-
不允許重復(Set):
-
需要排序 →?
TreeSet或ConcurrentSkipListSet -
需要插入順序 →?
LinkedHashSet -
只需要去重 →?
HashSet
-
-
4.4?性能優化建議
-
合理設置初始容量:對于ArrayList、HashMap等基于數組的集合,預先設置合理的初始容量可以減少擴容帶來的性能損耗。
-
選擇合適的負載因子:HashMap的負載因子(默認0.75)決定了哈希表在多少滿時擴容。更高的值節省內存但增加哈希沖突。
-
實現高質量的hashCode():對于作為HashMap鍵或HashSet元素的類,要確保hashCode()方法能產生均勻分布的哈希值。
-
考慮使用視圖:keySet()、values()等方法返回的是視圖而非新集合,可以節省內存。
-
注意自動裝箱開銷:對于大量基本類型數據,考慮使用專門的集合庫如Trove,避免自動裝箱帶來的性能損耗。
-
謹慎使用同步集合:只有在確實需要線程安全時才使用同步包裝器,否則會帶來不必要的性能損失。
-
利用不可變集合:對于不會修改的集合,使用Collections.unmodifiableXXX()創建不可變視圖,既安全又明確表達設計意圖。
4.5 總結
我在第一次接觸集合類的時候其實有點被搞得眼花繚亂的,因為實現類太多了我也不是特別能分得清各個核心類之間的區別;后來代碼量逐漸上來以后才能分辨請他們之間的差異。比較核心底層的東西還是得看源碼。
 等待事件(1)-概述)

)











)


)

