??代碼質量其實在需求高壓,業務快速迭代的場景下往往容易被人忽視的問題,大家的編碼習慣和規范也經常會各有喜好,短期之內獲取看不出來什么問題,但長此以往就會發現,屎山逐步成型了,而線上代碼跑著往往就不想改也不敢改了,所以團隊成員有一個良好的開發習慣,統一的編碼規范和一定的代碼潔癖是很重要的。
??但是項目代碼量一上來,其實再想逐行分析代碼的問題就很麻煩了,由此便有了本文的亡羊補牢的方案。(最好還是防患于未然,不要亡羊補牢,至于預防方案后續再更)。
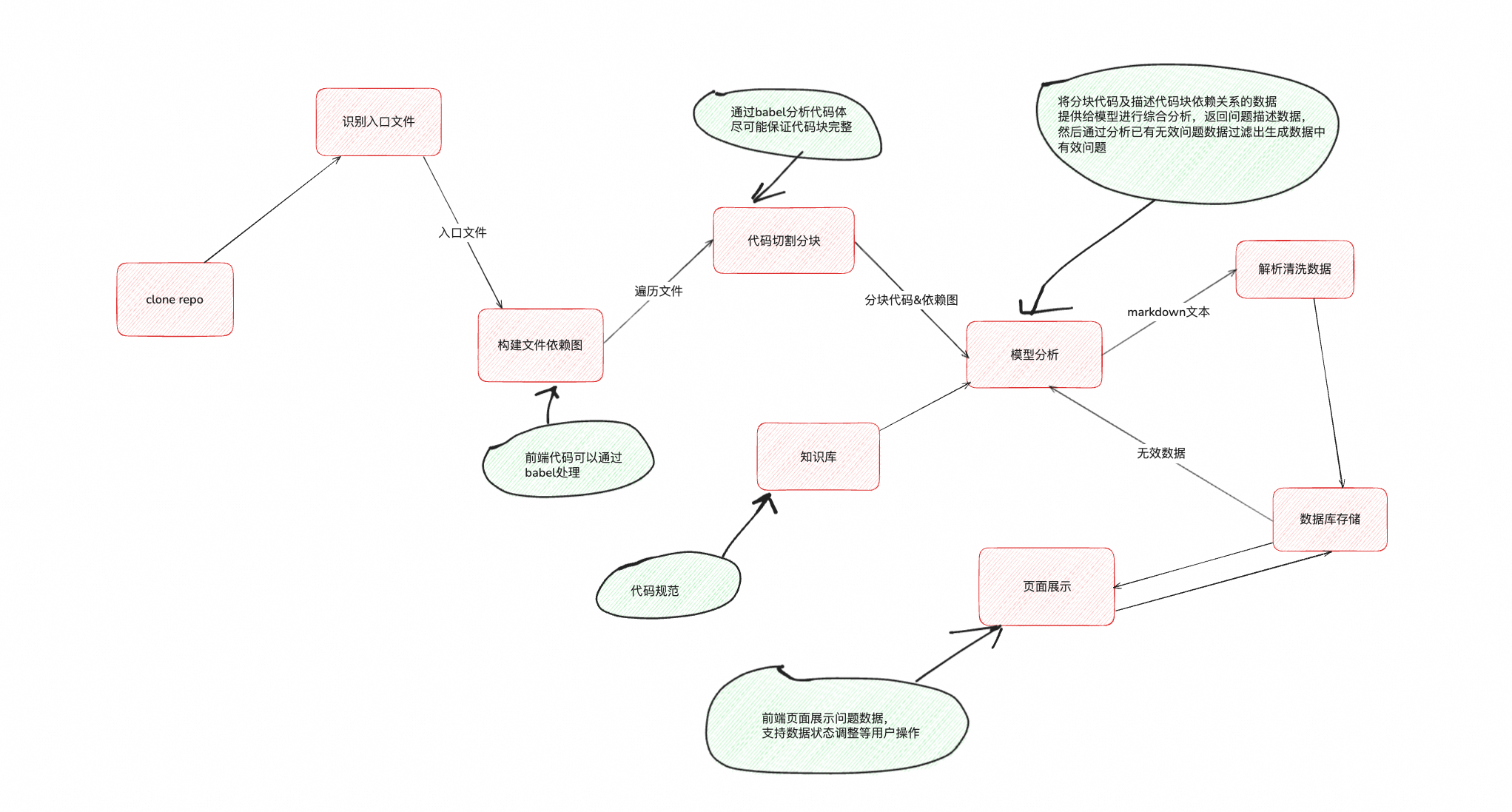
設計圖
clone代碼
賬號準備
??公共賬號1個,使用公共賬號作為clone倉庫的賬號,避免使用個人賬號受權限和人員變動影響
clone工具
??可以通過simple-git或者直接執行shell命令的方式來操作git倉庫代碼,機器硬盤存儲空間充足的情況下可以考慮保存clone后的代碼目錄,clone前檢查是否存在,存在就pull更新避免每次clone提高效率
入口文件分析
??一般而言倉庫代碼入口文件是可知的,拿前端代碼舉例,一般為路由對應的頁面入口文件或者npm包的入口文件。尤其在團隊規范統一的情況下,入口文件的邏輯應該是一個相對標準的,更加易于識別。
構建依賴圖
??“依賴”和“圖”是兩個點,前端代碼我們可以像項目構建一樣,通過@babel/parser中的parse來從入口文件開始解析成ast,然后通過@babel/traverse來遍歷ast解析其代碼依賴文件,遞歸處理獲取依賴關系,其他語言的項目也會有類似的工具可以處理。因為代碼依賴不會是一個簡單的“樹”形結構,往往樹“圖”結構的,而“圖”的結構數據體積也會相對小一些。
代碼分塊
??模型在一次對話的輸入數據的大小往往是有限制的,也就是常見的長文本處理問題。我們在通過@babel/parser獲取ast后可以通過遍歷ast.program.body來獲取完整的代碼區塊。
const ast = parse(code, {sourceType: 'module',plugins: ['typescript'],errorRecovery: true,attachComment: false,});
for (const node of ast.program.body) {const codeSnippet = code.slice(node.start, node.end);// TODO: 自行拼接代碼區塊}
然后按照模型單次對話接收文本長度閾值的限制來拼接代碼塊,分多次對話提供給模型,利用模型記憶多輪歷史對話的能力即可全部提供給模型。
模型分析
??模型在接收完全部代碼區塊和依賴圖數據后,對內容進行整體分析即可檢查出代碼存在的問題,此外我們可以通過在知識庫中補充團隊的代碼規范、優秀代碼demo示例等信息利用RAG的能力來提高輸出結果的質量。因為模型會存在幻覺的問題,所以我們在模型輸出一波問題以后讓其參考人工標注過的無效問題數據來進行二次過濾,篩選出真正有效的問題,自此便可以拿到我們需要的結果
備注
提示詞書寫可以參考之前的文章:如何寫高效的Prompt?
)
--Cartographer在Gazebo仿真環境下的建圖以及建圖與定位階段問題(實車也可參考))



)








)
)


)
