一、chunked prefills
1.1 chunked prefills核心思想
ORCA雖然很優秀,但是依然存在兩個問題:GPU利用率不高,流水線依然可能導致氣泡問題。
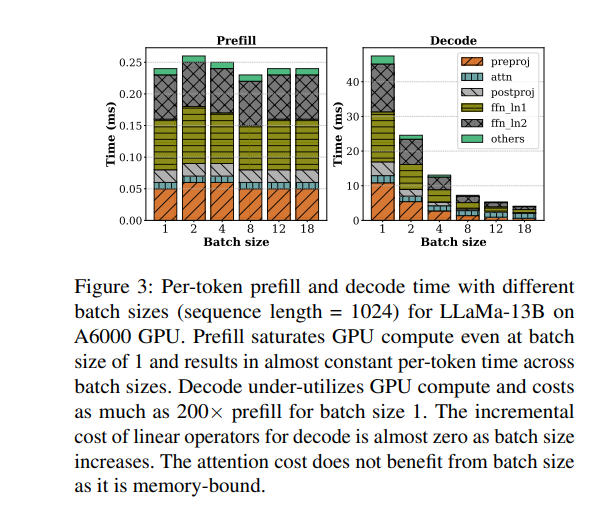
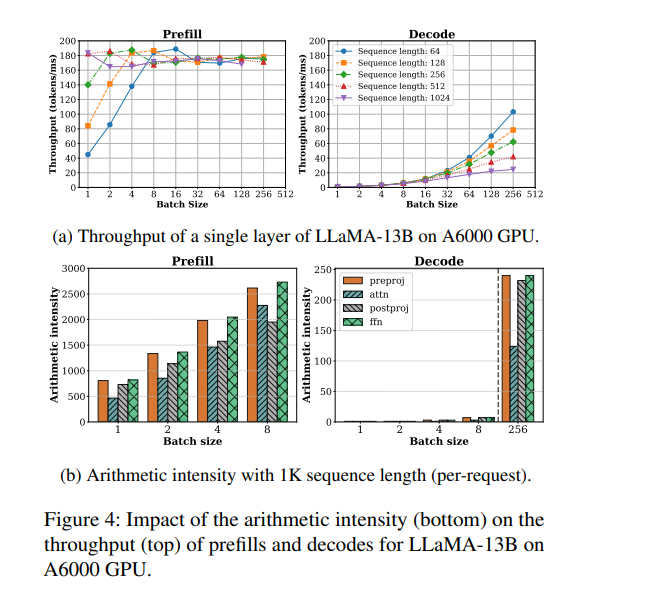
我們來看sarathi-serve做的一個實驗。左右兩圖分別刻畫了在不同的batch size下,prefill和decode階段的處理時間和計算強度。可以觀察到如下:
-
prefill 階段是計算密集型(compute-bound),主要時間花在大規模的線性變換和矩陣運算上,算力利用率高,但內存帶寬利用率不高。即使 batch size 很小,prefill 吞吐量也很快趨于飽和,增大 batch size 對提升吞吐幫助有限(比如 batch size 從 4 增加到 8),甚至可能因算力飽和而下降。
-
decode 階段是內存密集型(memory-bound),大部分時間消耗在讀取 KV cache 和模型權重上,算力利用率很低。此時增大 batch size 可以顯著提升吞吐,因為可以合并多次權重和 KV cache 的讀取,減少 IO 次數,讓空閑的算力得到利用。
混合批處理的優勢在于:
-
prefill 階段可以搭載(piggyback)在 decode 階段未被充分利用的算力上,提升整體算力利用率。
-
decode 階段可以和 prefill 階段共享一次權重讀取,減少內存帶寬壓力,提高帶寬利用率。
-
這樣,GPU 的計算單元和內存帶寬都能被更充分利用,整體吞吐和 QPS 明顯提升。
-
 ?
?
回顧 ORCA 的 Selective Batching 的策略就會發現,其行為具有一定的隨機性:一個 batch 中包含多少條 prefill 請求、多少條 decode 請求,并沒有明確控制,僅僅是按照“先到先服務”的策略動態拼裝而成。這就帶來一些問題:
-
若某個 batch 中包含大量 prefill 請求,或某些 prefill 請求本身 token 很長,就會導致 prefill tokens 占據大量計算資源,使整個 batch 變得 compute-bound;
-
相反,若 batch 中以 decode 請求為主,例如所有請求都處于推理階段,或沒有新的輸入序列可調度,則該 batch 很可能是 memory-bound 的,導致算力無法充分利用。
-
在流水線并行中同樣可能產生氣泡。
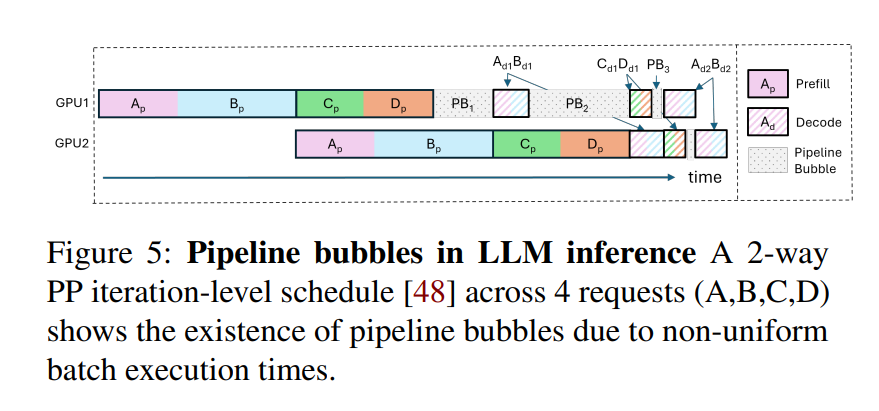
雖然流水線并行(Pipeline Parallelism)可以擴展大模型的并行能力,但也引入了一個典型問題:流水線氣泡(pipeline bubbles)。所謂“氣泡”,是指由于不同階段間計算不均衡或等待導致的 GPU 空閑時間,從而造成資源浪費和吞吐下降。
Orca 流水綫氣泡
?
Orca 系統嘗試通過 迭代級調度(iteration-level scheduling) 來緩解這一問題,但在實際推理中仍然可能出現氣泡,主要原因包括:
-
PB1:連續 micro-batch 的 prefill token 數量差異大。例如,若 AB 和 CD 分別是兩個 micro-batch,且 AB 的 token 總數顯著多于 CD。當 GPU1 完成 Cp 和 Dp 的 prefill 后,必須等待 GPU2 完成 AB 的 prefill,才能繼續執行 Ad1 和 Bd1 的 decode。GPU1 在此期間處于空轉狀態,形成 PB1 類型氣泡。
-
PB2:prefill 階段和 decode 階段計算負載差異大。PB2 類型氣泡出現在 prefill 和 decode 階段相繼執行時。以 Ad1 和 Bd1 為例,它們的 decode 階段每次僅處理一個 token,計算時間極短;而此時 GPU2 正在處理 Cp 和 Dp 的 prefill,涉及多個 token,耗時較長,導致 GPU1 無法及時執行后續任務,資源被浪費,形成 PB2 氣泡。
-
PB3:decode 階段上下文長度差異導致計算時間不均。decode 階段的計算開銷受上下文長度(即 KV cache 長度)影響較大。不同 micro-batch 中請求的上下文長度不一,導致 decode 階段耗時不同,從而在流水線上產生等待,形成 PB3 類型氣泡。
為了進一步解決上述問題,Sarathi-Serve 提出了一種兼顧吞吐量與延遲的調度機制,其中包括兩個核心設計思想:chunked-prefills(分塊預填充) 和 stall-free scheduling(無阻塞調度)。
-
chunked-prefills 將一個 prefill 請求拆分為計算量基本相等的多個塊(chunk),并在多輪調度迭代中逐步完成整個 prompt 的 prefill 過程(每次處理一部分 token)。
-
stall-free scheduling 則允許新請求在不阻塞 decode 的前提下,動態加入正在運行的 batch,通過將所有 decode 請求與新請求的一個或多個 prefill chunk 合并,構造出滿足預設大小(chunk size)的混合批次。
Sarathi-Serve 建立在 iteration-level batching 的基礎上,但有一個重要區別:它在接納新請求的同時,限制每輪迭代中 prefill token 的數量。這樣不僅限制了每輪迭代的延遲,還使其幾乎不受輸入 prompt 總長度的影響。通過這種方式,Sarathi-Serve 將新 prefill 的計算對正在進行的 decode 階段的 TBT 影響降到最低,從而同時實現了高吞吐量和較低的 TBT 延遲。
此外,Sarathi-Serve 構建的混合批次(包含 prefill 和 decode token)具有近似均衡的計算需求。結合流水線并行(pipeline-parallelism),這使我們能夠創建基于微批處理(micro-batching)的均衡調度,從而顯著減少流水線氣泡(pipeline bubbles),提升 GPU 利用率,實現高效且可擴展的部署。
chunked-prefills 流水綫氣泡示意圖:
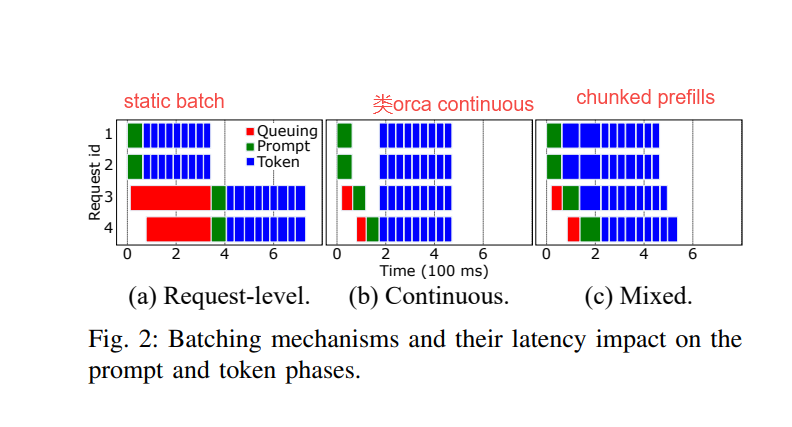 ?圖片來源:Splitwise: Efficient generative LLM inference using phase splitting
?圖片來源:Splitwise: Efficient generative LLM inference using phase splitting
1.2 實現
要使用預填充來附帶解碼,我們需要實現兩件事。
-
我們需要確定可以攜帶的解碼的最大可能批量大小,并確定構成預填充塊的預填充token的數量。
-
為了真正利用混合批的GPU飽和預填充計算來提高解碼效率,我們需要將預填充塊和批解碼的線性運算計算融合到一個操作中。動態分割的關鍵是將較長的預填充分成更小的塊(chunk),從而通過將預填充塊與多個解碼任務組合形成批處理,并充分調動 GPU,這個過程稱為捎帶確認(piggybacking)。
chunk的大小
該實現中很重要的一點就是如何確定chunk的大小,Sarathi提供了“固定”和“動態”兩種chunk size策略。
-
固定策略:該策略會依據硬件和profilling實驗計算出來一個可以最大限度把GPU利用起來的單batch中的tokens數量。這個是batch的token總配額(默認512),其在運行過程中會盡量保持不變,而prefill tokens數量會隨著decode tokens的增減而變化,但是因為decode tokens數量一般也不多,所以prefill tokens數量和整體batch tokens配額也不會相差很多。
-
動態策略:該策略希望對于一個請求,其prefill tokens的數量能隨著迭代次數的增加而減少。這是因為如果一個prompt特別長,它在每次迭代中都會占據很多計算資源,從而歷史累積的decode序列和新來的請求受到影響。因此對于這種新進入batch的長序列請求,Sarathi會在開始多配置一些prefill tokens額度,后續隨著迭代次數的增加,遞減這個配額,降低它對其它迭代的影響。
-
較小的 chunk size 有助于減少 TBT 延遲,因為每輪 iteration 涉及的 prefill token 更少,執行速度更快。
但如果 chunk size 過小,也會帶來一系列問題:
-
每個 chunk 的 Attention 操作都需重復讀取此前的 KV cache,增加內存訪問負擔;
-
算術強度下降,GPU 利用率降低;
-
kernel 啟動的固定開銷更頻繁,影響整體效率。
因此,在確定 chunk size 時,需要在 prefill 的計算開銷與 decode 的延遲之間做出合理權衡。可以通過一次性對不同 token 數量的 batch 進行 profiling,找出在不違反 TBT SLO 的前提下,單個 batch 可容納的最大 token 數,從而設定合適的 chunk size。論文中借助工具 Vidur 自動化完成這一過程,確保最終配置既能最大化吞吐量,又能有效控制延遲。
固定 chunk size 是包含 prefill + decode token 的總數。例如,512 token 的 batch 可能包含:2 個 decode 請求(各 1 token)+ prefill 請求 1(400 個 token)+ prefill 請求 2(110 個 token)= 512 個 token。
而動態 chunk size 對于不同階段的 prefill 請求是不一樣的,比如 chunk_sizes 列表是 [1024, 512, 256],一個 batch 可能包含 2 個 decode 請求(各 1 個 token)+ prefill 請求 1(250 個 token,階段 3)+ prefill 請求 2(772 個 token,階段 1,1024-2-250=772)= 1024 個 token。
-
在實際調度過程中,Sarathi-Serve 會優先調度正在進行的 decode 請求,因為每個 decode 僅消耗一個 token,且對延遲最為敏感,調度器會根據 KV cache 的容量判斷是否仍可繼續添加 decode 請求。隨后,系統會在剩余的 token 預算范圍內處理尚未完成的 prefill 請求,優先填滿一個 prefill 請求中的 token,再繼續處理下一個,在預算允許的情況下可連續處理多個 prefill 請求。若仍有剩余 token 預算,則進一步接納新的 prefill 請求加入當前批次。系統會確保當前調度輪次中 decode 和 prefill 的 token 總數不超過預設的 chunk size。
stall-free scheduling(無阻塞調度)
-
prefill 優先的調度策略(prefill-prioritized schedules):
-
vLLM 會優先調度盡可能多的 prefill 請求,只有在完成這些 prefill 后才恢復 decode,從而造成 decode 階段的阻塞,導致 TBT 延遲上升。
-
Orca 和 vLLM 都采用 FCFS(先來先服務)的 iteration-level batching 策略,并同樣優先處理 prefill 請求。但在 batch 組成策略上有所不同:vLLM 僅支持純 prefill 或純 decode 的 batch,而 Orca 支持 prefill 和 decode 的混合 batch。盡管如此,Orca 的混合 batch 在包含長 prompt 時執行時間依然較長,decode 階段依舊受到影響,無法避免 decode 阻塞。
-
decode 優先的調度策略(decode-prioritized schedules):
-
FasterTransformer 采用 request-level batching 策略,在當前請求的 decode 階段全部完成之前,不會調度任何新的請求。例如在下圖中,請求 C 和 D 的 prefill 將被阻塞,直到請求 A 和 B 完全退出系統。該策略雖然可以顯著降低 TBT 延遲,但也犧牲了系統整體吞吐量。
-
無阻塞(stall-free)的調度策略:
-
Sarathi-Serve 同樣支持 prefill 和 decode 的并行執行,但相比 Orca,它通過精細控制每個 batch 中 prefill token 的數量,確保 decode 幾乎不受影響。與 FasterTransformer 相比,Sarathi 的 decode 時間只略有延長(把 Sarathi-Serve 的綠色塊和 FasterTransformer 的紅色塊相比,可以發現綠色塊只長了一點),卻顯著提升了吞吐量,實現了低延遲與高吞吐的兼得。sarathi-serve允許decode和prefill一起做,但是它通過合理控制每個batch中prefill tokens的數量,使得decode階段幾乎沒有延遲。這樣即保了延遲,又保了吞吐。
-
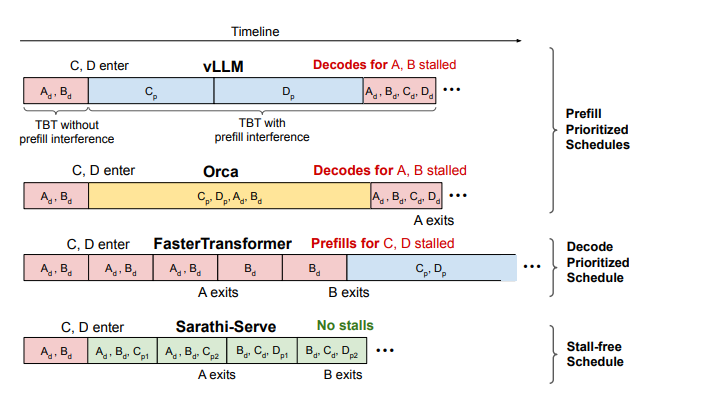
圖片來源:Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
避免 tile quantization 效應
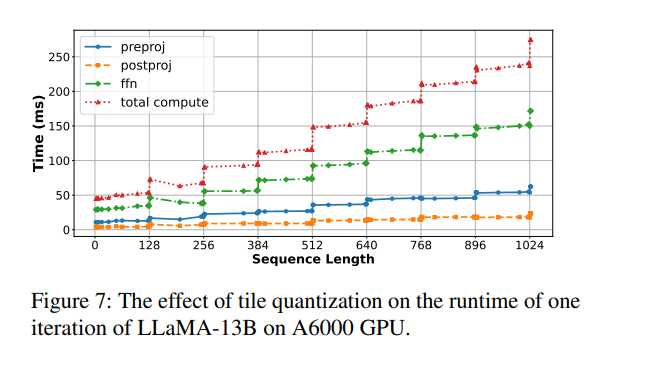
GPU 執行矩陣乘法時通常采用 tile 分塊機制(例如 tile size = 128),只有當矩陣維度是 tile 的整數倍時,資源利用率才最高。
如果 chunk size 剛好超過 tile size 的倍數(例如 257),就會導致 thread blocks 內部部分線程空閑或執行無效計算,即“空轉”,從而引發突發性的計算時間激增。下圖展示了這一現象:當序列長度從 256 增加到 257,僅增加 1 個 token,延遲卻從 69.8ms 飆升至 92.33ms,漲幅高達 32%。
當序列長度恰好是 tile size(128)的整數倍時,如 128、256、384 等,運行時間上升相對平穩;而一旦略微超過 tile 邊界(例如從 256 到 257),計算時間則會急劇增加。
這是因為 GPU 的矩陣乘法是按 tile 并行執行的,如果維度不是 tile 的整數倍,部分 tile 無法充分利用,導致計算資源浪費,這就是所謂的 tile quantization overhead。
為避免這種問題,推薦的做法是:選擇合適的 chunk size,并使其與搭載(piggyback) 的 decode token 數之和是 tile size 的整數倍,從而保持矩陣維度對齊,確保計算效率最優。
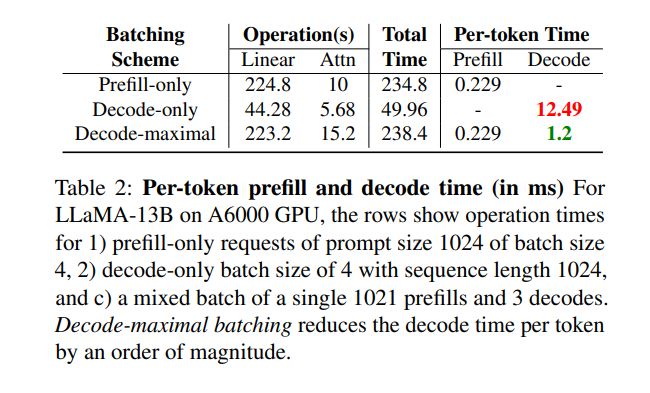
測試效果
-
僅包含 prompt 的請求(prompt 長度為 1024,batch 大小為 4);
-
僅包含 decode 的請求(batch 大小為 4,序列長度為 1024);
-
一個混合 batch,包括 1 個長度為 1021 的 prefill 請求和 3 個 decode 請求。
結果表明,混合 batch 能將每個 token 的解碼時間顯著降低一個數量級,大幅提升整體推理效率;同時,prefill 階段的耗時幾乎沒有變化。
二、引用文獻
[1] Orca: A distributed serving system for transformer-based generative models https://www.usenix.org/system/files/osdi22-yu.pdf
[2] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills https://arxiv.org/pdf/2308.16369
[3] DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference https://arxiv.org/pdf/2401.08671
[4] Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
https://arxiv.org/pdf/2403.02310
[5] Splitwise: Efficient generative LLM inference using phase splitting
https://arxiv.org/abs/2311.18677
[6] DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
https://arxiv.org/abs/2401.09670
[7] https://zhuanlan.zhihu.com/p/1928005367754884226
)




)

![[C++]string::substr](http://pic.xiahunao.cn/[C++]string::substr)










)
