11 Redisson分布式布隆過濾器+Redisson分布式鎖改造專輯詳情接口
11.1 緩存穿透解決方案&布隆過濾器
-
緩存穿透解決方案:
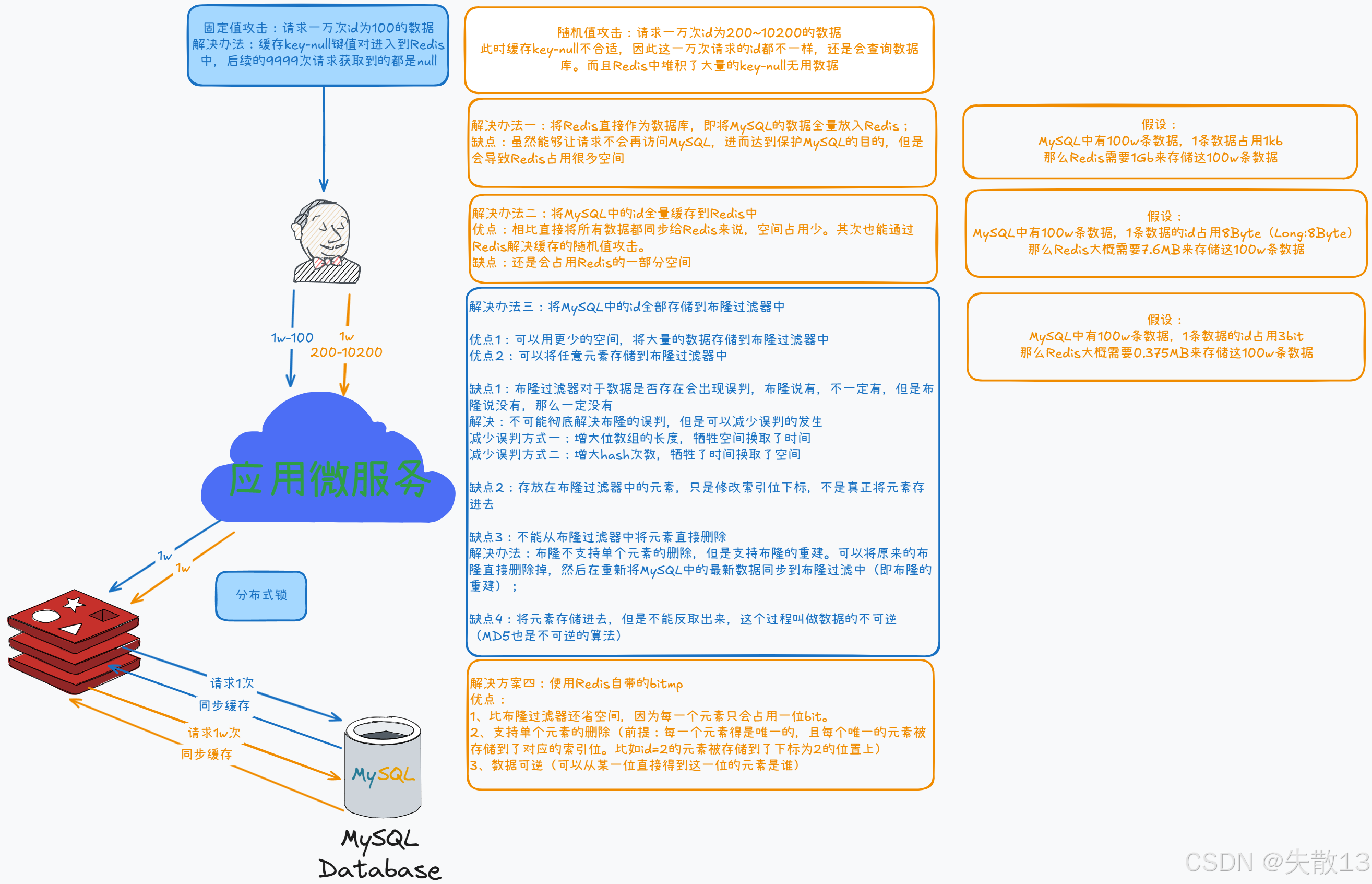
-
布隆過濾器:
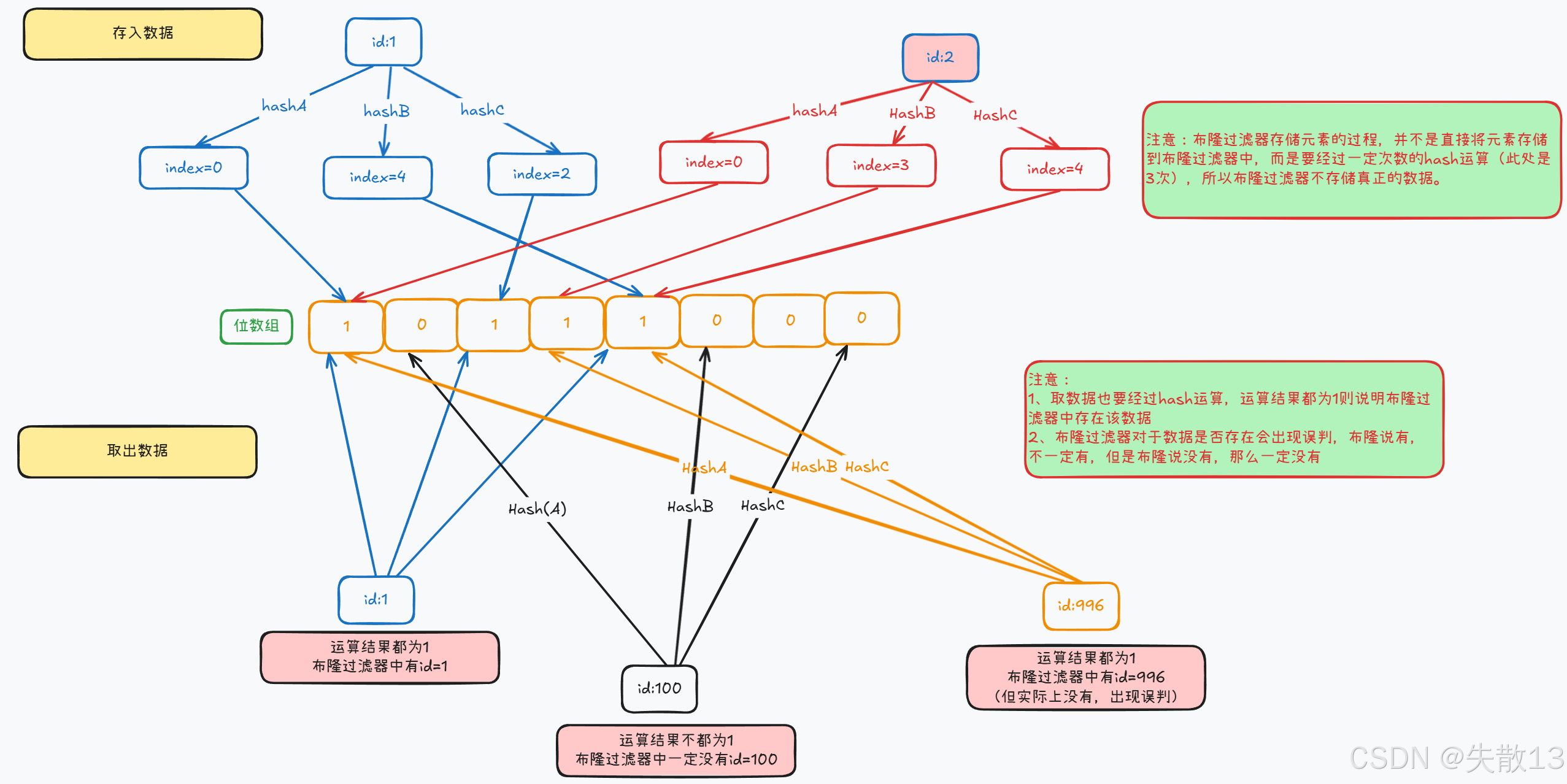
-
布隆過濾器的使用:
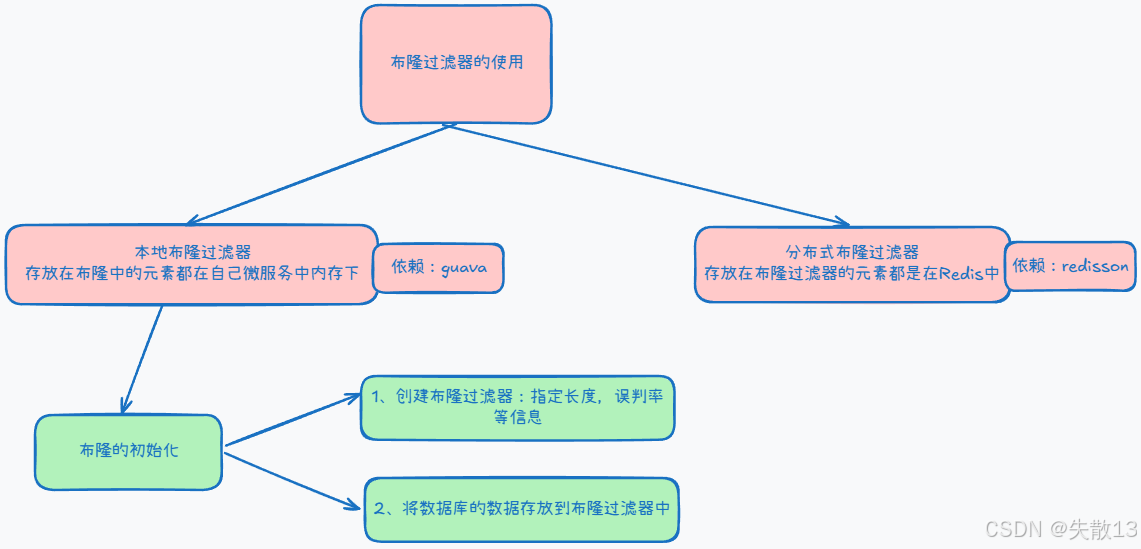
11.2 遠程調用查詢所有的專輯id集合
-
修改:
/*** 查詢所有的專輯id集合* @return*/ @GetMapping("/getAlbumInfoIdList") Result<List<Long>> getAlbumInfoIdList(); -
修改:
@Override public Result<List<Long>> getAlbumInfoIdList() {return Result.fail(); } -
修改:
/*** 查詢所有的專輯id集合* @return*/ @GetMapping("/getAlbumInfoIdList") Result<List<Long>> getAlbumInfoIdList() {List<Long> albumIdList = albumInfoService.getAlbumInfoIdList();return Result.ok(albumIdList); } -
修改:
/*** 查詢所有的專輯id集合* @return*/ Result<List<Long>> getAlbumInfoIdList() {List<Long> albumIdList = albumInfoService.getAlbumInfoIdList();return Result.ok(albumIdList); } -
修改:
/*** 查詢所有的專輯id集合* @return*/ @Transactional public void saveAlbumStat(Long albumId) {ArrayList<String> albumStatus = new ArrayList<>();albumStatus.add(SystemConstant.ALBUM_STAT_PLAY);albumStatus.add(SystemConstant.ALBUM_STAT_SUBSCRIBE);albumStatus.add(SystemConstant.ALBUM_STAT_BROWSE);albumStatus.add(SystemConstant.ALBUM_STAT_COMMENT);for (String status : albumStatus) {AlbumStat albumStat = new AlbumStat();albumStat.setAlbumId(albumId);albumStat.setStatType(status);albumStat.setStatNum(0);albumStatMapper.insert(albumStat);} } -
修改:在
ItemService中調用
/*** 查詢所有專輯的id集合* @return*/ List<Long> getAlbumInfoIdList(); -
修改:
/*** 查詢所有的專輯id集合* @return*/ @Override public List<Long> getAlbumInfoIdList() {Result<List<Long>> albumIds = albumInfoFeignClient.getAlbumInfoIdList();List<Long> albumIdsData = albumIds.getData();if (CollectionUtils.isEmpty(albumIdsData)) {throw new ShisanException(201, "應用中不存在專輯id集合");}return albumIdsData; }
11.3 本地布隆過濾器的使用
-
依賴:
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>23.0</version> </dependency> -
修改:
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnel; import com.google.common.hash.Funnels;@Slf4j @Service @SuppressWarnings({"unchecked", "rawtypes"}) public class ItemServiceImpl implements ItemService {// ……其它邏輯BloomFilter<Long> longBloomFilter = null;/*** 初始化本地布隆過濾器*/@PostConstruct // Spring在創建ItemServiceImpl Bean對象的時候,在其生命周期走到初始化前,會調用該方法public void initLocalBloomFilter() {// 創建化布隆過濾器// 創建漏斗(Funnel)// 漏斗(Funnel):是 Guava 庫中用于將對象轉換為字節流的接口,布隆過濾器通過它將元素哈希為位數組的位置// Funnels.longFunnel():是 Guava 提供的內置漏斗實現,專門用于處理 Long 類型,將長整型數值轉換為字節流Funnel<Long> longFunnel = Funnels.longFunnel();// BloomFilter.create():靜態工廠方法,用于創建布隆過濾器實例// longFunnel:指定元素類型(Long)的漏斗,用于元素的哈希轉換// 1000000:預期插入的元素數量(容量)。布隆過濾器會根據此值和誤判率計算所需的位數組大小// 0.01:期望的誤判率(假陽性概率),即當元素實際不存在時,布隆過濾器誤判為存在的概率。這里設置為 1%longBloomFilter = BloomFilter.create(longFunnel, 1000000, 0.01);// 將元素放入布隆過濾器器List<Long> albumInfoIdList = getAlbumInfoIdList();albumInfoIdList.stream().forEach(albumId -> {longBloomFilter.put(albumId);});log.info("本地布隆初始化完畢,布隆中的元素個數:{}", longBloomFilter.approximateElementCount());}/*** 根據專輯id查詢專輯詳情* @param albumId* @return*/@Overridepublic Map<String, Object> getAlbumInfo(Long albumId) {return getDistroCacheAndLockAndBloomFilter(albumId);}// ……其它邏輯/*** 最終版本+布隆過濾器* @param albumId* @return*/private Map getDistroCacheAndLockAndBloomFilter(Long albumId) {// ……其它邏輯// 查詢布隆過濾器(本地)。解決緩存穿透的隨機值攻擊boolean b = longBloomFilter.mightContain(albumId);if (!b) {log.info("本地布隆過濾器中不存在訪問的數據:{}", albumId);return null;}// ……其它邏輯if (acquireLockFlag) { // 若搶得到鎖(即加鎖成功)// ……其它邏輯try {long ttl = 0l; // 數據的過期時間// 回源查詢數據庫albumInfoFromDb = getAlbumInfoFromDb(albumId);// 設置數據的過期時間if (albumInfoFromDb != null && albumInfoFromDb.size() > 0) { // 如果數據庫查詢的數據不為空,則設置一個較長的過期時間ttl = 60 * 60 * 24 * 7l;} else { // 如果數據庫查詢的數據為空,則設置一個較短的過期時間ttl = 60 * 60 * 2;}// 將數據庫查詢的數據同步到Redis緩存,同時設置過期時間redisTemplate.opsForValue().set(cacheKey, JSONObject.toJSONString(albumInfoFromDb), ttl, TimeUnit.SECONDS);} finally {// ……其它邏輯}// 返回數據給前端return albumInfoFromDb;} else { // 若未搶到鎖(即加鎖失敗)// ……其它邏輯}}// ……其它邏輯 } -
測試:以 Debug 模型啟動
service-search微服務,打斷點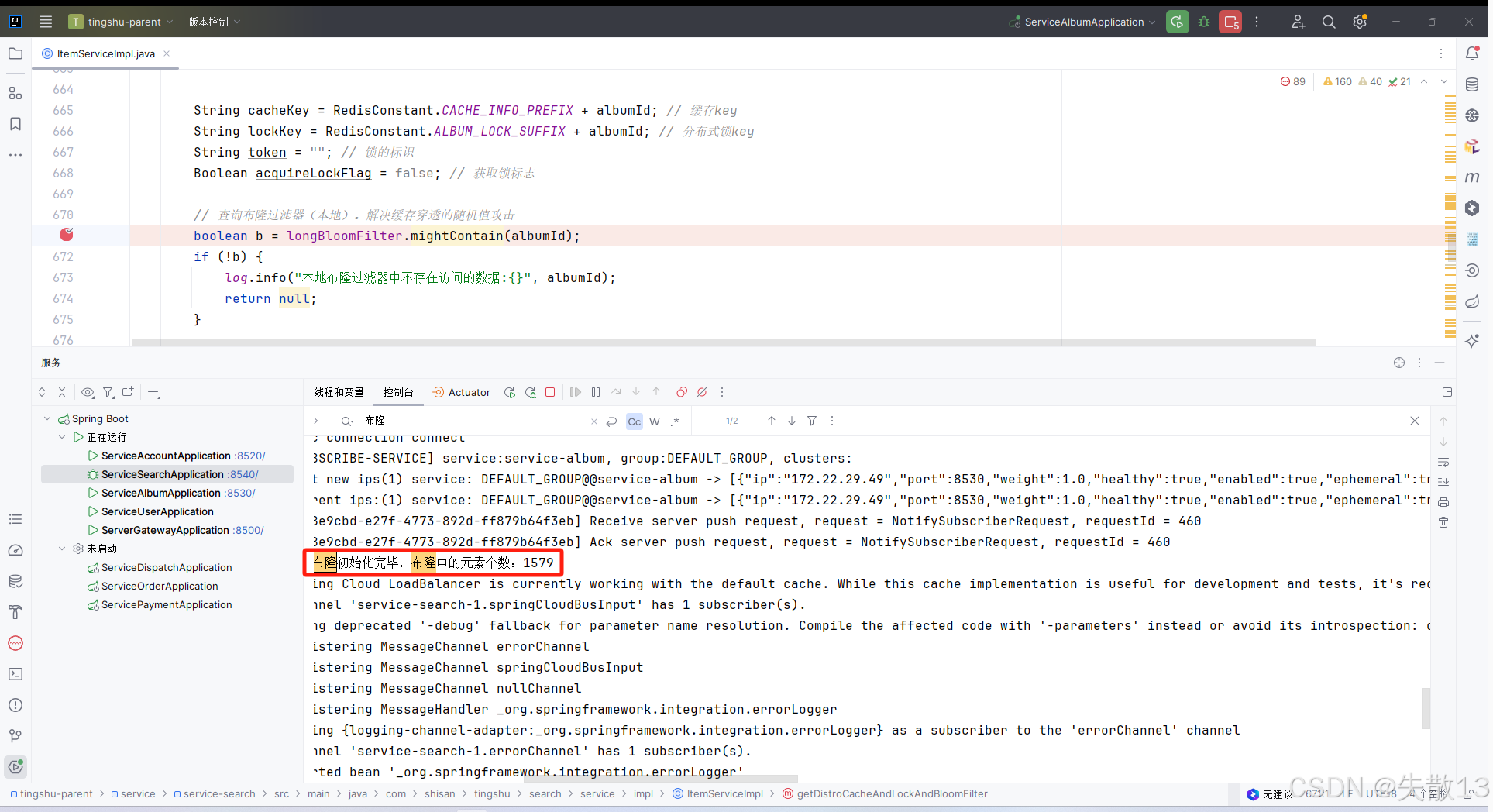
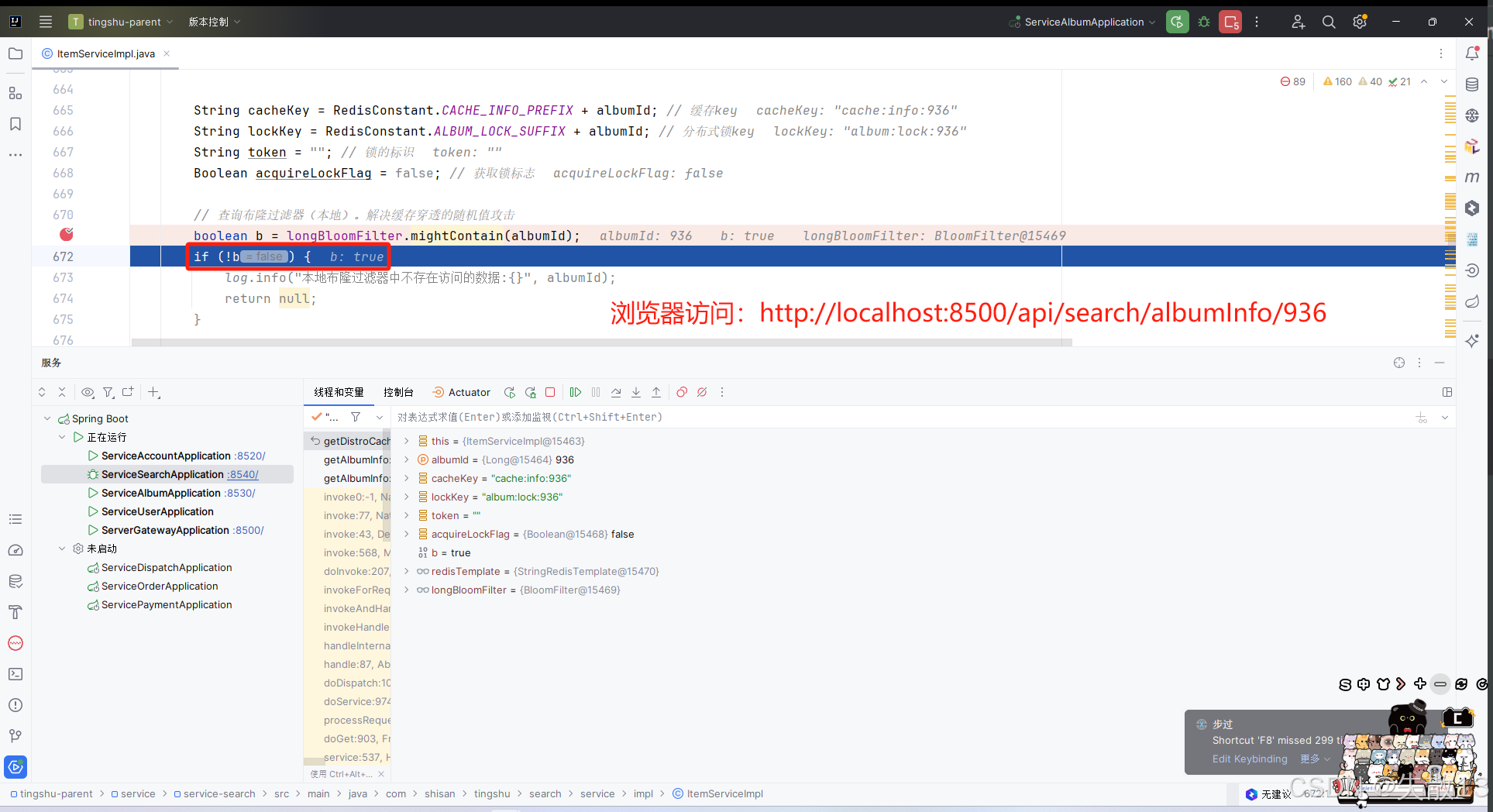

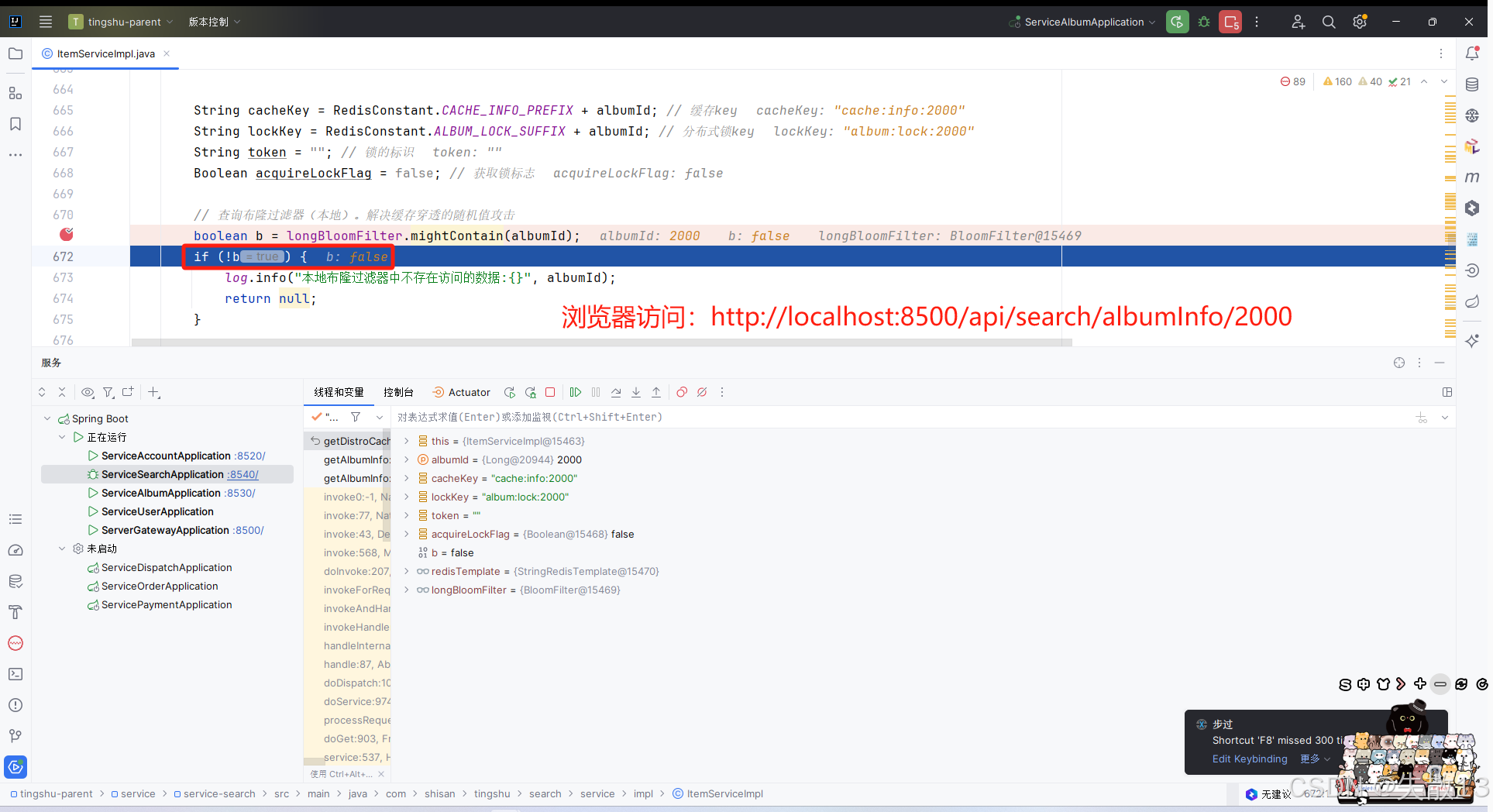
-
測試完,
initLocalBloomFilter()方法就可以注釋掉了。
11.4 Redisson分布式布隆過濾器初始化
-
分布式布隆過濾器依賴于 Redisson;
- GitHub:GitHub - redisson/redisson: Redisson - Valkey & Redis Java client. Real-Time Data Platform. Sync/Async/RxJava/Reactive API. Over 50 Valkey and Redis based Java objects and services: Set, Multimap, SortedSet, Map, List, Queue, Deque, Semaphore, Lock, AtomicLong, Map Reduce, Bloom filter, Spring, Tomcat, Scheduler, JCache API, Hibernate, RPC, local cache…;
- 文檔:Objects - Redisson Reference Guide;
-
引入依賴:
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.25.0</version> </dependency> -
新建:
package com.shisan.tingshu.search.config;import org.redisson.Redisson; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.redisson.config.Config; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.autoconfigure.data.redis.RedisProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.core.StringRedisTemplate;@Configuration public class RedissonAutoConfiguration {Logger logger = LoggerFactory.getLogger(this.getClass());@Autowiredprivate RedisProperties redisProperties;@Autowiredprivate StringRedisTemplate redisTemplate;/*** 定義Redisson客戶端的Bean對象*/@Beanpublic RedissonClient redissonClient() {// 給Redisson設置配置信息Config config = new Config();config.useSingleServer() // 使用單機模式.setPassword(redisProperties.getPassword()).setAddress("redis://" + redisProperties.getHost() + ":" + redisProperties.getPort());// 創建Redisson客戶端RedissonClient redissonClient = Redisson.create(config);return redissonClient;}/*** 定義一個BloomFilter的Bean對象*/@Beanpublic RBloomFilter rBloomFilter(RedissonClient redissonClient) {// 如果在Redis中沒有這個key,那么會自動創建,并返回這個key對應的布隆過濾器對象。反之 直接返回已經創建好的布隆過濾器// tryInit()方法返回true表示初始化成功(即之前不存在,現在新創建了),返回false表示已經存在(即之前已經初始化過)RBloomFilter<Object> albumIdBloomFilter = redissonClient.getBloomFilter("albumIdBloomFilter");// 初始化布隆過濾器boolean b = albumIdBloomFilter.tryInit(1000000l, 0.001);if (b) {logger.info("成功創建新的布隆過濾器,等待數據填充");} else {logger.info("布隆過濾器已存在,直接使用");}return albumIdBloomFilter;} }
11.5 讓Spring容器在啟動時就執行一些必要操作的四種實現方法
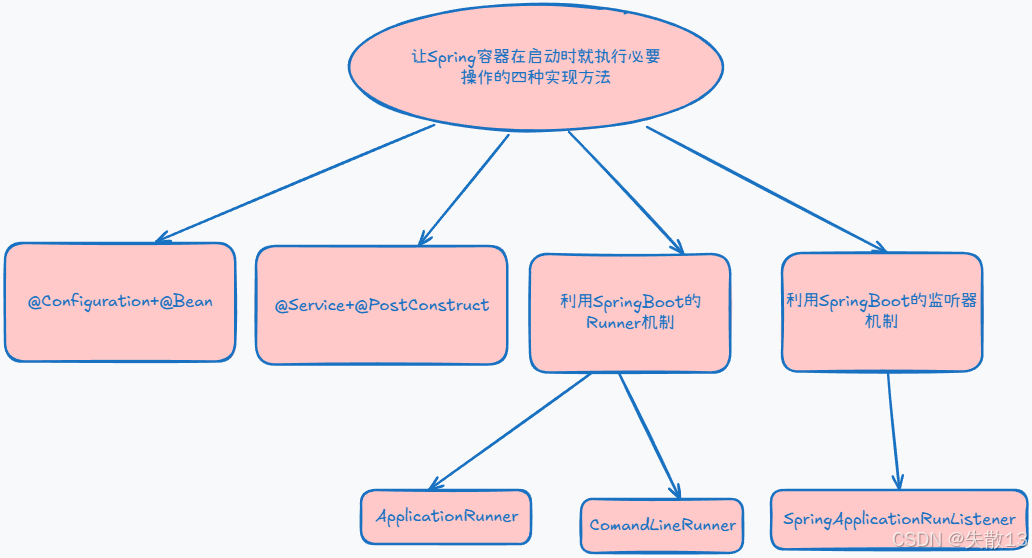
@Configuration + @Bean:- 在 Spring 中,
@Configuration注解用于標記一個類作為配置類,而@Bean注解用于在配置類中聲明一個 Bean; - 當 Spring 容器啟動時,會加載這些配置類,并初始化被
@Bean注解標記的方法所返回的對象,從而實現一些初始化操作; - 這種方式是 Spring 中比較基礎的配置方式,通過 Java 代碼的方式來替代傳統的 XML 配置,使得配置更加類型安全和靈活;
- 在 Spring 中,
@Service + @PostConstruct:@Service注解用于標記一個類作為服務層組件,當 Spring 容器啟動時,會掃描并初始化被@Service注解標記的類;- 而
@PostConstruct注解用于標記一個方法,該方法會在 Bean 初始化完成后被調用,通常用于在 Bean 初始化后執行一些初始化邏輯; - 這是 Spring 中常用的一種初始化 Bean 的方式,特別是在服務層組件中,經常需要在 Bean 初始化后進行一些資源初始化或數據加載等操作;
- 利用 SpringBoot 的 Runner 機制。SpringBoot 提供了兩種 Runner 接口來實現在容器啟動后執行特定的邏輯:
ApplicationRunner- 實現
ApplicationRunner接口的類會在 SpringBoot 應用啟動后被調用,run方法會接收一個ApplicationArguments對象,可以用來獲取應用啟動時的命令行參數等信息; - 這種方式通常用于在應用啟動后執行一些需要訪問應用參數的初始化操作;
- 實現
CommandLineRunner- 與
ApplicationRunner類似,實現CommandLineRunner接口的類也會在應用啟動后被調用,run方法接收的是原始的命令行參數數組; - 如果只需要簡單地處理命令行參數,而不需要
ApplicationArguments提供的高級功能,那么可以使用CommandLineRunner;
- 與
- 利用 SpringBoot 的監聽器機制(
SpringApplicationRunListener)SpringApplicationRunListener是 SpringBoot 提供的一個監聽器接口,用于監聽 SpringBoot 應用的啟動過程。通過實現這個接口,可以在應用啟動的不同階段執行自定義的邏輯,例如在應用上下文準備好后、應用啟動前等階段。- 這種方式提供了對 Spring Boot 應用啟動過程的更細粒度的控制,可以用于在應用啟動的不同階段執行一些自定義的初始化或監控操作。
11.6 利用SpringBoot的Runnner機制完成對分布式布隆過濾器的元素同步
-
接下來要將專輯id列表放入到分布式布隆過濾器中,此處采用
11.5 讓Spring容器在啟動時就執行一些必要操作的四種實現方法的方法三; -
新建:
package com.shisan.tingshu.runners;import com.shisan.tingshu.search.service.impl.ItemServiceImpl; import org.redisson.api.RBloomFilter; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.BeansException; import org.springframework.boot.ApplicationArguments; import org.springframework.boot.ApplicationRunner; import org.springframework.boot.CommandLineRunner; import org.springframework.context.ApplicationContext; import org.springframework.context.ApplicationContextAware; import org.springframework.stereotype.Component;import java.util.List;/*** 利用SpringBoot的Runnner機制完成對分布式布隆過濾器的元素同步* ApplicationRunner:* 實現ApplicationRunner接口的類會在SpringBoot應用啟動后被調用,run()方法會接收一個ApplicationArguments對象,可以用來獲取應用啟動時的命令行參數等信息;* 這種方式通常用于在應用啟動后執行一些需要訪問應用參數的初始化操作;* CommandLineRunner:* 與ApplicationRunner類似,實現CommandLineRunner接口的類也會在應用啟動后被調用,run()方法接收的是原始的命令行參數數組;* 如果只需要簡單地處理命令行參數,而不需要ApplicationArguments提供的高級功能,那么可以使用CommandLineRunner;*/ @Component public class BloomFilterRunners implements ApplicationRunner, CommandLineRunner, ApplicationContextAware {// 定義一個ApplicationContextAware接口的實現類,用于獲取spring容器中的Bean對象private ApplicationContext applicationContext;Logger logger = LoggerFactory.getLogger(this.getClass());/*** ApplicationRunner 接口的run()方法會在SpringBoot應用啟動后被調用,run()方法接收一個ApplicationArguments對象,可以用來獲取應用啟動時的命令行參數等信息* 這些參數中:--表示可選參數,沒有--的表示必選參數。比如:--spring.profiles.active=dev表示可選參數,spring.profiles.active=dev表示必選參數* 在該方法中,可以獲取到布隆過濾器的Bean對象,然后將數據同步到布隆過濾器中* @param args* @throws Exception*/@Overridepublic void run(ApplicationArguments args) throws Exception {// Set<String> optionNames = args.getOptionNames(); // for (String optionName : optionNames) { // 獲取可選參數 // System.out.println("命令行中輸入的可選參數名:" + optionName + "值:" + args.getOptionValues(optionName)); // } // for (String nonOptionArg : args.getNonOptionArgs()) { // 獲取必選參數 // System.out.println("命令行中輸入的必選參數名:" + nonOptionArg + "值:" + args.getOptionValues(nonOptionArg)); // }// 從Spring容器中獲取到布隆過濾器的Bean對象RBloomFilter rBloomFilter = applicationContext.getBean("rBloomFilter", RBloomFilter.class);// 從Spring容器中獲取應用的Bean對象ItemServiceImpl itemServiceImpl = applicationContext.getBean("itemServiceImpl", ItemServiceImpl.class);// 獲取數據List<Long> albumInfoIdList = itemServiceImpl.getAlbumInfoIdList();// 將數據放到布隆過濾器中for (Long albumId : albumInfoIdList) {rBloomFilter.add(albumId);}// 打印日志,判斷布隆過濾器元素是否同步進去logger.info("分布式布隆過濾器的元素個數:" + rBloomFilter.count());}/*** CommandLineRunner 接口的run()方法會在SpringBoot應用啟動后被調用,run()方法接收的是原始的命令行參數數組* @param args* @throws Exception*/@Overridepublic void run(String... args) throws Exception {}/*** 實現ApplicationContextAware接口,用于獲取spring容器中的Bean對象* @param applicationContext* @throws BeansException*/@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.applicationContext = applicationContext;} } -
測試:
11.7 利用SpringBoot的Listener機制完成對分布式布隆過濾器的元素同步
-
接下來要將專輯id列表放入到分布式布隆過濾器中,此處采用
11.5 讓Spring容器在啟動時就執行一些必要操作的四種實現方法的方法四;- 先將上一節講的
BloomFilterRunners的類上的@Component注解注釋掉;
- 先將上一節講的
-
新建:
package com.shisan.tingshu.search.listener;import com.shisan.tingshu.search.service.impl.ItemServiceImpl; import org.redisson.api.RBloomFilter; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.SpringApplicationRunListener; import org.springframework.context.ConfigurableApplicationContext; import org.springframework.stereotype.Component;import java.time.Duration; import java.util.Arrays; import java.util.List;//@Component 即使加了這個注解,SpringBoot也不會自動掃描到這個Listener類。只能通過 SPI 機制來加載這個Listener類 // SpringApplicationRunListener是SpringBoot提供的一個監聽器接口,用于監聽SpringBoot應用的啟動過程 // 通過實現這個接口,可以在應用啟動的不同階段執行自定義的邏輯,例如在應用上下文準備好后、應用啟動前等階段 public class BloomFilterListener implements SpringApplicationRunListener {Logger logger = LoggerFactory.getLogger(this.getClass());/*** started()方法在SpringBoot應用啟動的過程中被調用,用于監聽SpringBoot應用的啟動過程* 注意:started()方法在SpringBoot應用啟動的過程中會被調用兩次* 第一次是SpringCloud的組件調用的。方法參數ConfigurableApplicationContext,即Spring容器中是沒有應用中定義好的Bean對象* 第二次是SpringBoot組件調用的。方法參數ConfigurableApplicationContext,即Spring容器中才有應用中定義好的Bean對象* @param context Spring 容器* @param timeTaken 啟動時間*/@Overridepublic void started(ConfigurableApplicationContext context, Duration timeTaken) {logger.info("BloomFilterListener 被實例化!"); // 如果沒有這行日志,說明 SPI 加載失敗logger.info("當前所有 Bean: {}", Arrays.toString(context.getBeanDefinitionNames()));boolean containsBean = context.containsBean("rBloomFilter");if (containsBean) { // 當容器中存在布隆過濾器對象時,才進行布隆過濾器的元素同步(避免started()方法在第一次被調用的時候容器中沒有布隆過濾器對象而報錯)// 從Spring容器中獲取到布隆過濾器的Bean對象RBloomFilter rBloomFilter = context.getBean("rBloomFilter", RBloomFilter.class);// 從Spring容器中獲取應用的Bean對象ItemServiceImpl itemServiceImpl = context.getBean("itemServiceImpl", ItemServiceImpl.class);// 獲取數據List<Long> albumInfoIdList = itemServiceImpl.getAlbumInfoIdList();// 將數據放到布隆過濾器中for (Long albumId : albumInfoIdList) {rBloomFilter.add(albumId);}// 布隆過濾器元素是否同步進去logger.info("分布式布隆過濾器的元素個數:" + rBloomFilter.count());} else {logger.info("容器中不存在布隆過濾器對象");}} } -
新建:手動通過 SPI 機制將 Listener 注入容器
org.springframework.boot.SpringApplicationRunListener=com.shisan.tingshu.search.listener.BloomFilterListener -
測試:
-
最好先將Redis中關于
albumIdBloomFilter的數據刪掉 -
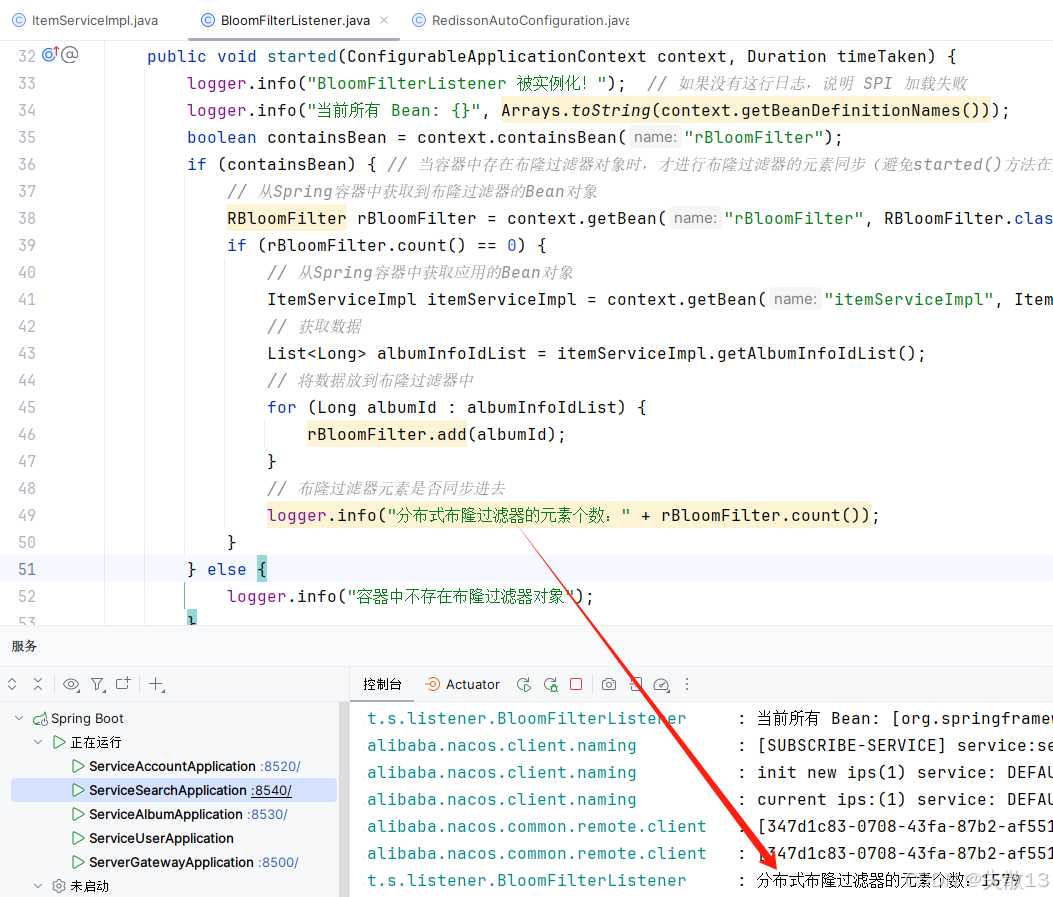
在日志中也可以看到下面兩行代碼執行了兩次
logger.info("BloomFilterListener 被實例化!"); // 如果沒有這行日志,說明 SPI 加載失敗 logger.info("當前所有 Bean: {}", Arrays.toString(context.getBeanDefinitionNames()));
-
-
修改
ItemServiceImpl:@Slf4j @Service @SuppressWarnings({"unchecked", "rawtypes"}) public class ItemServiceImpl implements ItemService {@Autowiredprivate RBloomFilter rBloomFilter;// ……其它邏輯/*** 最終版本+布隆過濾器* @param albumId* @return*/private Map getDistroCacheAndLockAndBloomFilter(Long albumId) {// ……其它邏輯// 查詢布隆過濾器(本地)。解決緩存穿透的隨機值攻擊 // boolean b = longBloomFilter.mightContain(albumId); // if (!b) { // log.info("本地布隆過濾器中不存在訪問的數據:{}", albumId); // return null; // }// 查詢布隆過濾器(分布式)boolean bloomContains = rBloomFilter.contains(albumId);if (!bloomContains) {return null;}// ……其它邏輯}// ……其它邏輯 } -
測試:同
11.3 本地布隆過濾器的使用。
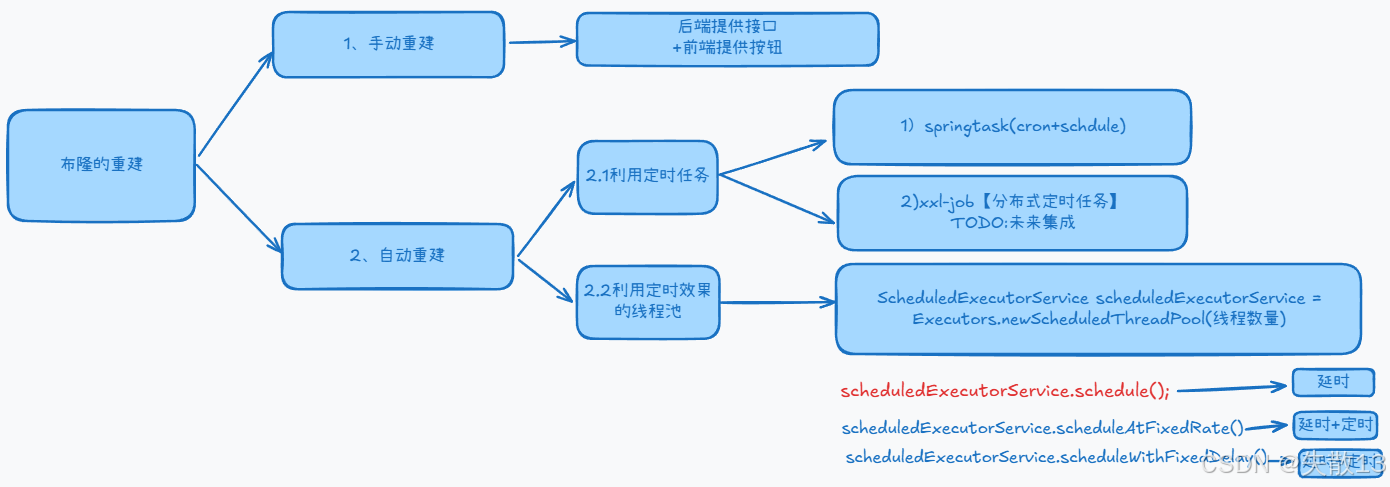
11.8 布隆重建的兩種方案(手動和自動)
11.9 分布式布隆重建方案之手動重建
-
新建:
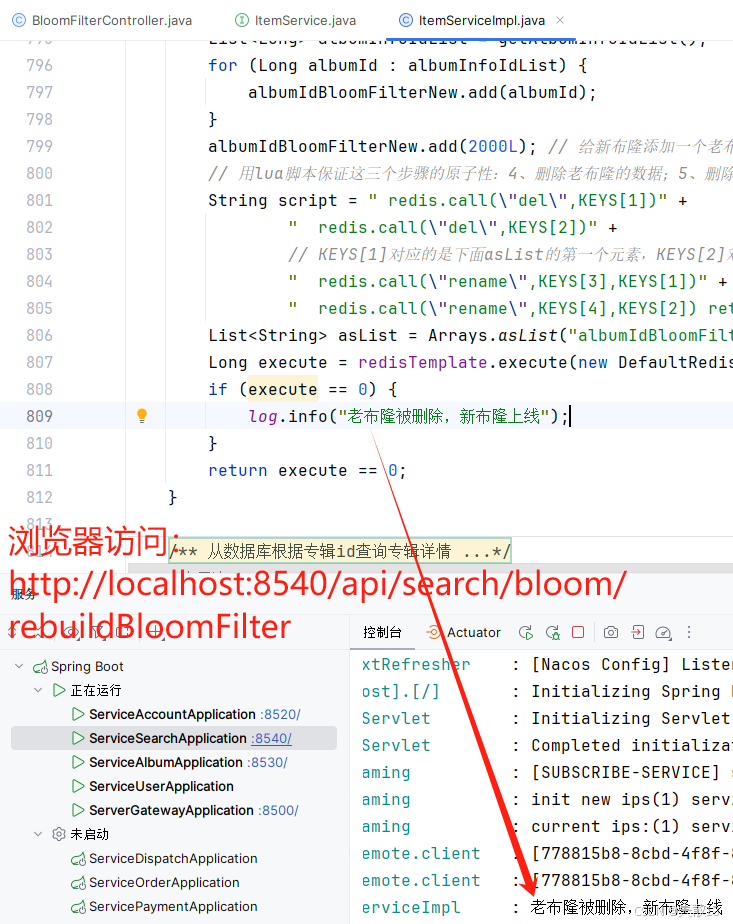
@GetMapping("/rebuildBloomFilter") @Operation(summary = "手動重建布隆") public Result rebuildBloomFilter() {Boolean isFlag = itemService.rebuildBloomFilter();return Result.ok(isFlag); } -
修改:
/*** 手動布隆重建* @return*/ Boolean rebuildBloomFilter(); -
修改:
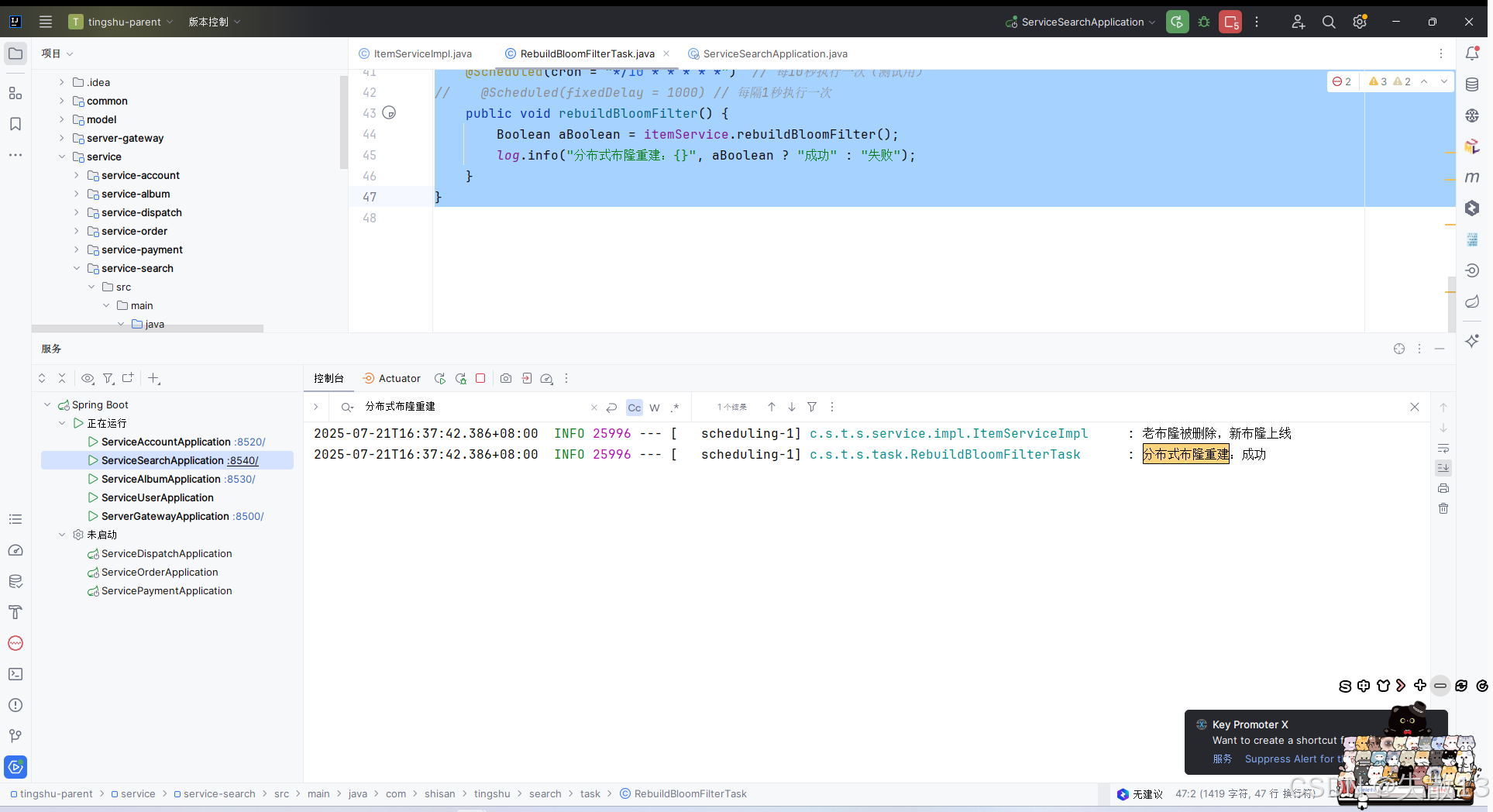
@Autowired private RedissonClient redissonClient;/*** 手動布隆重建* @return*/ @Override public Boolean rebuildBloomFilter() {// 步驟:刪除老布隆的數據 >> 刪除老布隆的配置 >> 創建新布隆 >> 初始化新布隆 >> 將數據放到新布隆// 但在高并發場景下,第一個線程刪除了老布隆的配置但是新布隆還沒有創建時,第二個線程進來仍然使用的是老布隆,此時就會報錯// 優化做法:創建新布隆 >> 初始化新布隆 >> 將數據放到新布隆 >> 刪除老布隆的數據 >> 刪除老布隆的配置 >> 將新布隆的名字重命名為老布隆的名字(第4、5、6步要做成一個原子操作)// 1、創建新布隆RBloomFilter<Object> albumIdBloomFilterNew = redissonClient.getBloomFilter("albumIdBloomFilterNew");// 2、初始化新布隆albumIdBloomFilterNew.tryInit(1000000l, 0.001);// 3、將數據放到新布隆List<Long> albumInfoIdList = getAlbumInfoIdList();for (Long albumId : albumInfoIdList) {albumIdBloomFilterNew.add(albumId);}albumIdBloomFilterNew.add(2000L); // 給新布隆添加一個老布隆不存在的數據,用于測試// 用lua腳本保證這三個步驟的原子性:4、刪除老布隆的數據;5、刪除老布隆的配置;6、將新布隆的名字重命名為老布隆的名字String script = " redis.call(\"del\",KEYS[1])" +" redis.call(\"del\",KEYS[2])" +// KEYS[1]對應的是下面asList的第一個元素,KEYS[2]對應的是下面asList的第二個元素,以此類推" redis.call(\"rename\",KEYS[3],KEYS[1])" + // 用后者替換前者" redis.call(\"rename\",KEYS[4],KEYS[2]) return 0";List<String> asList = Arrays.asList("albumIdBloomFilter", "{albumIdBloomFilter}:config", "albumIdBloomFilterNew", "{albumIdBloomFilterNew}:config");Long execute = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), asList);if (execute == 0) {log.info("老布隆被刪除,新布隆上線");}return execute == 0; } -
測試:
11.10 優化:分布式布隆過濾器只初始化一次&同步數據只做一次
-
每一次服務已啟動,就會初始化分布式布隆過濾器并同步數據,但是實際上 Redis 中已經存在布隆過濾器和同步數據了。所以此處就優化一下,讓分布式布隆過濾只初始化一次且同步數據只做一次;
-
修改:加個鎖,讓分布式布隆過濾器只初始化一次且同步數據只做一次
/*** 定義一個BloomFilter的Bean對象*/ @Bean public RBloomFilter rBloomFilter(RedissonClient redissonClient) {// 如果在Redis中沒有這個key,那么會自動創建,并返回這個key對應的布隆過濾器對象。反之 直接返回已經創建好的布隆過濾器// tryInit()方法返回true表示初始化成功(即之前不存在,現在新創建了),返回false表示已經存在(即之前已經初始化過)RBloomFilter<Object> albumIdBloomFilter = redissonClient.getBloomFilter("albumIdBloomFilter");// 加個鎖,讓分布式布隆過濾器只初始化一次且同步數據只做一次// 當鎖存在的時候,表示布隆過濾器已經初始化過了,直接返回布隆過濾器對象String bloomFilterLockKey = "albumIdBloomFilter:lock";Boolean aBoolean = redisTemplate.opsForValue().setIfAbsent(bloomFilterLockKey, "1");if (aBoolean) {// 初始化布隆過濾器boolean b = albumIdBloomFilter.tryInit(1000000l, 0.001); // 利用分布式鎖保證分布式布隆的初始化只做一次if (b) {logger.info("成功創建新的布隆過濾器,等待數據填充");} else {logger.info("布隆過濾器已存在,直接使用");}}return albumIdBloomFilter; } -
修改:如果布隆過濾器元素個數為0,說明布隆過濾器元素還沒有同步,需要同步布隆過濾器元素
@Override public void started(ConfigurableApplicationContext context, Duration timeTaken) {logger.info("BloomFilterListener 被實例化!"); // 如果沒有這行日志,說明 SPI 加載失敗logger.info("當前所有 Bean: {}", Arrays.toString(context.getBeanDefinitionNames()));boolean containsBean = context.containsBean("rBloomFilter");if (containsBean) { // 當容器中存在布隆過濾器對象時,才進行布隆過濾器的元素同步(避免started()方法在第一次被調用的時候容器中沒有布隆過濾器對象而報錯)// 從Spring容器中獲取到布隆過濾器的Bean對象RBloomFilter rBloomFilter = context.getBean("rBloomFilter", RBloomFilter.class);if (rBloomFilter.count() == 0) { // 如果布隆過濾器元素個數為0,說明布隆過濾器元素還沒有同步,需要同步布隆過濾器元素// 從Spring容器中獲取應用的Bean對象ItemServiceImpl itemServiceImpl = context.getBean("itemServiceImpl", ItemServiceImpl.class);// 獲取數據List<Long> albumInfoIdList = itemServiceImpl.getAlbumInfoIdList();// 將數據放到布隆過濾器中for (Long albumId : albumInfoIdList) {rBloomFilter.add(albumId);}// 布隆過濾器元素是否同步進去logger.info("分布式布隆過濾器的元素個數:" + rBloomFilter.count());} else {logger.info("布隆過濾器元素已經同步!");}} else {logger.info("容器中不存在布隆過濾器對象");} }
11.11 使用SpringTask的Schdule機制實現布隆定時重建
-
新建:
package com.shisan.tingshu.search.task;import com.shisan.tingshu.search.service.ItemService; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.scheduling.annotation.Scheduled; import org.springframework.stereotype.Component;@Component @Slf4j public class RebuildBloomFilterTask {@Autowiredprivate ItemService itemService;/*** cron表達式有7位,但實際使用的只有6位,即:秒 分 時 日 月 周 (年)* 注意:日和周不能同時出現,所以如果寫日,就不要寫周,用一個?占位即可** 書寫格式如下:* 字段 允許值 特殊字符* 秒 0-59 , - * /* 分 0-59 , - * /* 時 0-23 , - * /* 日 1-31 , - * / ?* 月 1-12 或 JAN-DEC , - * /* 周 0-7 或 SUN-SAT , - * / ?* 注意:0 和 7 均表示周日** 特殊字符說明:* 字符 含義 示例* * 所有值(任意時刻) 0 * * * * *:表示每分鐘執行* ? 忽略該字段(僅用于日或周) 0 0 0 ? * MON:表示每周一執行* - 范圍 0 0 9-17 * * *:表示9點到17點每小時執行* , 多個值 0 0 8,12,18 * * *:表示每天8點、12點、18點執行* / 步長 0 0/5 * * * *:表示每5分鐘執行一次*/// @Scheduled(cron = "0 0 2 */7 * ?") // 每周日凌晨2點執行@Scheduled(cron = "*/10 * * * * *") // 每10秒執行一次(測試用) // @Scheduled(fixedDelay = 1000) // 每隔1秒執行一次public void rebuildBloomFilter() {Boolean aBoolean = itemService.rebuildBloomFilter();log.info("分布式布隆重建:{}", aBoolean ? "成功" : "失敗");} } -
同時在
ServiceSearchApplication啟動類上加上@EnableScheduling注解; -
測試:
11.12 工廠類創建餓漢式單例定時任務線程池+一次性延遲任務+嵌套任務本身實現定時布隆重建
-
修改:開啟允許循環依賴
spring:main:allow-circular-references: true -
修改:
@Autowired private RedissonClient redissonClient;@Autowired private ItemServiceImpl itemServiceImpl; // 自己注入自己,記得在application.yaml中開啟允許循環依賴/*** ScheduleTaskThreadPoolFactory工廠類+一次性延遲任務+嵌套任務本身實現定時布隆重建*/ @PostConstruct public void initRebuildBloomFilter() {// // 創建一個定時任務線程池,核心線程數為2,用于執行定時或周期性任務 // ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(2); // // 安排一個周期性任務:RebuildBloomFilterRunnable,每隔7天執行一次 // scheduledExecutorService.scheduleWithFixedDelay( // new RebuildBloomFilterRunnable(redissonClient, redisTemplate, itemServiceImpl), // 要執行的周期性任務 // 0, // 首次立即執行 // 7, TimeUnit.DAYS // 在上一次任務執行完成后,固定間隔7天再次執行(FixedDelay策略) // ); // // 安排一個一次性延遲任務:RebuildBloomFilterRunnable,在10秒后執行。與上面的周期性任務不同,這個任務只執行一次 // // 那么怎么實現每10秒執行一次呢?在RebuildBloomFilterRunnable的run方法中,再調用一次scheduledExecutorService.schedule()方法,實現每10秒執行一次 // scheduledExecutorService.schedule( // new RebuildBloomFilterRunnable(redissonClient, redisTemplate, itemServiceImpl), // 10, TimeUnit.SECONDS // );// 從服務啟動開始,每隔7天的凌晨兩點執行一次// 使用ScheduleTaskThreadPoolFactory工廠類,實現定時任務的線程池對象創建ScheduleTaskThreadPoolFactory instance = ScheduleTaskThreadPoolFactory.getINSTANCE();Long taskFirstTime = instance.diffTime(System.currentTimeMillis()); // 傳入當前時間,計算出距離下次執行任務的時間差instance.execute(new RebuildBloomFilterRunnable(redissonClient, redisTemplate, itemServiceImpl),taskFirstTime,TimeUnit.MILLISECONDS); // instance.execute(new RebuildBloomFilterRunnable(redissonClient, redisTemplate, itemServiceImpl), 20L, TimeUnit.SECONDS); // 測試用 } -
新建:專門用于定時重建布隆過濾器的線程任務類
package com.shisan.tingshu.search.runnable;import com.shisan.tingshu.search.factory.ScheduleTaskThreadPoolFactory; import com.shisan.tingshu.search.service.impl.ItemServiceImpl; import lombok.extern.slf4j.Slf4j; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.data.redis.core.script.DefaultRedisScript;import java.util.Arrays; import java.util.List; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit;/*** 專門用于定時重建布隆過濾器的線程任務類*/ @Slf4j public class RebuildBloomFilterRunnable implements Runnable {Logger logger = LoggerFactory.getLogger(this.getClass());private RedissonClient redissonClient;private StringRedisTemplate redisTemplate;private ItemServiceImpl itemServiceImpl;public RebuildBloomFilterRunnable(RedissonClient redissonClient, StringRedisTemplate redisTemplate, ItemServiceImpl itemServiceImpl) {this.redissonClient = redissonClient;this.redisTemplate = redisTemplate;this.itemServiceImpl = itemServiceImpl;}@Overridepublic void run() {// 步驟:刪除老布隆的數據 >> 刪除老布隆的配置 >> 創建新布隆 >> 初始化新布隆 >> 將數據放到新布隆// 但在高并發場景下,第一個線程刪除了老布隆的配置但是新布隆還沒有創建時,第二個線程進來仍然使用的是老布隆,此時就會報錯// 優化做法:創建新布隆 >> 初始化新布隆 >> 將數據放到新布隆 >> 刪除老布隆的數據 >> 刪除老布隆的配置 >> 將新布隆的名字重命名為老布隆的名字(第4、5、6步要做成一個原子操作)// 1、創建新布隆RBloomFilter<Object> albumIdBloomFilterNew = redissonClient.getBloomFilter("albumIdBloomFilterNew");// 2、初始化新布隆albumIdBloomFilterNew.tryInit(1000000l, 0.001);// 3、將數據放到新布隆List<Long> albumInfoIdList = itemServiceImpl.getAlbumInfoIdList();for (Long albumId : albumInfoIdList) {albumIdBloomFilterNew.add(albumId);}albumIdBloomFilterNew.add(2000L); // 給新布隆添加一個老布隆不存在的數據,用于測試// 用lua腳本保證這三個步驟的原子性:4、刪除老布隆的數據;5、刪除老布隆的配置;6、將新布隆的名字重命名為老布隆的名字String script = " redis.call(\"del\",KEYS[1])" +" redis.call(\"del\",KEYS[2])" +// KEYS[1]對應的是下面asList的第一個元素,KEYS[2]對應的是下面asList的第二個元素,以此類推" redis.call(\"rename\",KEYS[3],KEYS[1])" + // 用后者替換前者" redis.call(\"rename\",KEYS[4],KEYS[2]) return 0";List<String> asList = Arrays.asList("albumIdBloomFilter", "{albumIdBloomFilter}:config", "albumIdBloomFilterNew", "{albumIdBloomFilterNew}:config");Long execute = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), asList);if (execute == 0) {log.info("老布隆被刪除,新布隆上線");}// 一次性延遲任務+嵌套任務本身,進而實現定時的效果(Nacos源碼就是這么做的) // ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(2); // scheduledExecutorService.schedule(this,10, TimeUnit.SECONDS);//但是定時任務線程池被創建了兩次(ItemServiceImpl的initRebuildBloomFilter()中一次,上面一次),所以可以使用工廠模式ScheduleTaskThreadPoolFactory instance = ScheduleTaskThreadPoolFactory.getINSTANCE();instance.execute(this, 7l, TimeUnit.DAYS); // instance.execute(this, 20l, TimeUnit.SECONDS); // 測試用} } -
新建:定時任務線程池工廠類
package com.shisan.tingshu.search.factory;import java.time.LocalDate; import java.time.LocalDateTime; import java.time.LocalTime; import java.time.ZoneId; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit;public class ScheduleTaskThreadPoolFactory {static ScheduledExecutorService scheduledExecutorService = null;// 在加載ScheduleTaskThreadPoolFactory類的時候,提前將定時任務的線程池對象創建出來static {scheduledExecutorService = Executors.newScheduledThreadPool(2);}/*** 使用單例設計模式定義一個工廠類的實例對象(餓漢式。在并發情況下,比懶漢式安全一點)* 餓漢式:類加載時就立即初始化單例實例,線程安全但可能造成資源浪費* 懶漢式:首次使用時才初始化單例實例,節省資源但需額外處理線程安全問題*/private static ScheduleTaskThreadPoolFactory INSTANCE = new ScheduleTaskThreadPoolFactory();/*** 獲取上面定義的實例對象*/public static ScheduleTaskThreadPoolFactory getINSTANCE() {return INSTANCE;}/*** 私有化構造器。讓外面無法通過new的方式創建該工廠類的實例對象*/private ScheduleTaskThreadPoolFactory() {}/*** 該方法使得工廠可以接收外部提交過來的任務* runnable:外部提交過來的任務* ttl:延遲時間* timeUnit:時間單位*/public void execute(Runnable runnable, Long ttl, TimeUnit timeUnit) {// 一次性延遲任務+嵌套任務本身,進而實現定時的效果(Nacos源碼就是這么做的)scheduledExecutorService.schedule(runnable, ttl, timeUnit);}/*** 計算時間差*/public Long diffTime(Long currentTime) {// 獲取當前時間的下一周的凌晨2點的時間戳LocalDate localDate = LocalDate.now().plusDays(7);LocalDateTime localDateTime = LocalDateTime.of(localDate, LocalTime.of(2, 0, 0));// 將LocalDateTime轉換為毫秒值。ZoneId.systemDefault()是獲取系統默認時區long time = localDateTime.atZone(ZoneId.systemDefault()).toInstant().toEpochMilli();// 當前時間減去下一周的凌晨2點的時間戳,得到時間差(小減大、大減小都行)Long diffTime = currentTime - time; // Long diffTime =time - currentTime;long absDiffTime = Math.abs(diffTime);return absDiffTime;} } -
測試:可能有延遲,正常現象
11.13 Redisson的lock鎖和tryLock鎖
-
Redisson 是一個基于 Redis 的 Java 客戶端,提供了分布式鎖的實現;
-
lock鎖,即
lock()方法,是阻塞式的獲取鎖方式-
特點:
- 如果鎖可用,則立即獲取鎖并返回
- 如果鎖不可用,則當前線程會被阻塞,直到鎖被釋放
- 支持可重入(同一個線程可以多次獲取同一把鎖)
- 默認情況下,鎖的租期是30秒,但會通過看門狗機制自動續期
-
例:
RLock lock = redisson.getLock("myLock"); try {lock.lock();// 執行業務邏輯 } finally {lock.unlock(); } -
注意:必須手動釋放鎖(在 finally 塊中調用
unlock())
-
-
tryLock鎖,即
tryLock()是非阻塞或帶超時的獲取鎖方式-
特點:
- 非阻塞版本:
tryLock()立即返回獲取結果 - 超時版本:
tryLock(long waitTime, TimeUnit unit)在指定時間內嘗試獲取鎖 - 同樣支持可重入
- 非阻塞版本:
-
方法重載:
boolean tryLock():嘗試獲取鎖,成功返回true,失敗立即返回falseboolean tryLock(long waitTime, long leaseTime, TimeUnit unit):在waitTime時間內嘗試獲取鎖,獲取成功后鎖的持有時間為leaseTimeboolean tryLock(long waitTime, TimeUnit unit):在waitTime時間內嘗試獲取鎖,獲取成功后鎖會通過看門狗自動續期
-
例:
RLock lock = redisson.getLock("myLock"); try {if (lock.tryLock(10, 30, TimeUnit.SECONDS)) {// 在10秒內獲取到鎖,且鎖的租期是30秒// 執行業務邏輯} else {// 獲取鎖失敗} } finally {if (lock.isHeldByCurrentThread()) {lock.unlock();} }
-
-
二者對比:
特性 lock() tryLock() 阻塞性 阻塞直到獲取鎖 非阻塞或帶超時的阻塞 返回值 無返回值 返回boolean表示是否獲取成功 適用場景 必須獲取鎖的場景 可以容忍獲取鎖失敗的場景 自動續期 默認支持(看門狗機制) 取決于參數設置
11.14 最最終版本:Redisson分布式布隆過濾器+Redisson分布式鎖
-
修改:
/*** 最最終版本:Redisson分布式布隆過濾器+Redisson分布式鎖* @param albumId* @return*/ @SneakyThrows private Map getDistroCacheAndLockFinallyRedissonVersion(Long albumId) {// 1.定義緩存keyString cacheKey = RedisConstant.CACHE_INFO_PREFIX + albumId; // 緩存keyString lockKey = RedisConstant.ALBUM_LOCK_SUFFIX + albumId; // 分布式鎖keylong ttl = 0l; // 數據的過期時間// 2.查詢分布式布隆過濾器boolean contains = rBloomFilter.contains(albumId);if (!contains) {return null;}// 3.查詢緩存String jsonStrFromRedis = redisTemplate.opsForValue().get(cacheKey);// 3.1 緩存命中if (!StringUtils.isEmpty(jsonStrFromRedis)) {return JSONObject.parseObject(jsonStrFromRedis, Map.class);}// 3.2 緩存未命中 查詢數據庫// 3.2.1 添加分布式鎖RLock lock = redissonClient.getLock(lockKey);boolean accquireLockFlag = lock.tryLock(); // tryLock:非阻塞、自動續期if (accquireLockFlag) { // 搶到鎖try {// 3.2.2 回源查詢數據Map<String, Object> albumInfoFromDb = getAlbumInfoFromDb(albumId);if (albumInfoFromDb != null) { // 如果根據albumId查詢到的數據不為空,則設置一個較長的過期時間ttl = 60 * 60 * 24 * 7l;} else { // 如果根據albumId查詢到的數據為空,則設置一個較短的過期時間ttl = 60 * 60 * 24l;}// 3.2.3 同步數據到緩存中去redisTemplate.opsForValue().set(cacheKey, JSONObject.toJSONString(albumInfoFromDb), ttl, TimeUnit.SECONDS); // 防止緩存穿透的固定值攻擊return albumInfoFromDb;} finally {lock.unlock();// 釋放鎖}} else { // 沒搶到鎖。等同步時間之后,查詢緩存即可Thread.sleep(200);String result = redisTemplate.opsForValue().get(cacheKey);if (!StringUtils.isEmpty(result)) {return JSONObject.parseObject(result, Map.class);}return getAlbumInfoFromDb(albumId);} } -
記得修改接口:
/*** 根據專輯id查詢專輯詳情* @param albumId* @return*/ @Override public Map<String, Object> getAlbumInfo(Long albumId) {return getDistroCacheAndLockFinallyRedissonVersion(albumId); } -
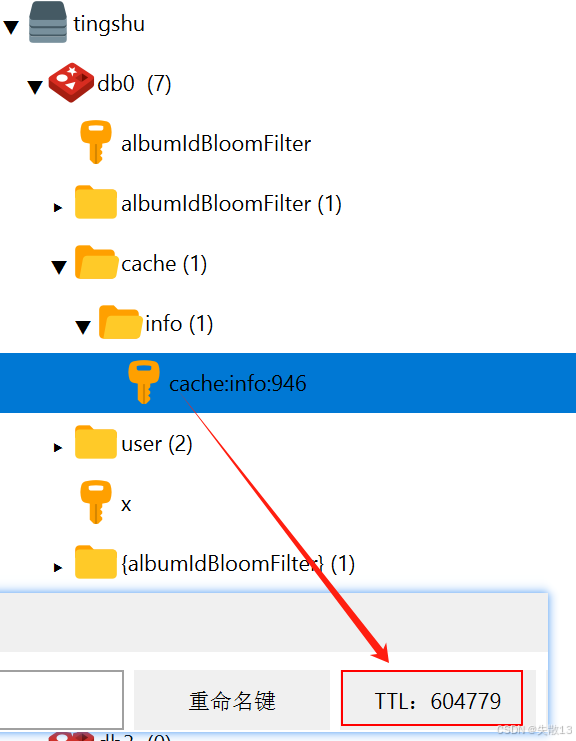
啟用前端測試Redis:
- 因為根據 albumId 從數據庫中查到是有數據的,所以 TTL 時間較長;
- 布隆過濾器則看后臺有沒有打印相關日志即可





)



)
)
)

)




從零搭建unity3d機械臂仿真-unity3d導入urdf模型)
