一、模型介紹
論文為《TabNet: Attentive Interpretable Tabular Learning》發表于2021年,屬于Google Cloud AI。該研究針對表格數據提出了一種新的深度神經網絡(DNN)架構TabNet,旨在解決傳統深度學習在表格數據上表現不如決策樹模型的問題,同時提升性能和可解釋性。
TabNet模型融合了多種先進思想:它將Transformer的注意力機制(賦予模型動態、稀疏地“聚焦”于最重要特征的能力)、Boosting的序列化決策思想(分步、迭代地做出決策)以及自監督學習的表示學習能力(在正式訓練前,讓模型預先學習特征間的內在關系,為后續的智能決策提供“先驗知識)巧妙地結合在了一起,用于解決表格數據問題。
保留DNN的end-to-end和representation learning特點的基礎上,還擁有了樹模型的可解釋性和稀疏特征選擇的優點
TabNet 的工作方式(通俗的方式理解模型)
Boosting的序列化決策思想(比如GBDT 通過擬合上一步的預測殘差不斷訓練迭代模型)
-
使用一部分特征(通過自監督學習+注意力選擇),做出一個初步的預測貢獻。
-
TabNet不像Boosting那樣顯式地計算一個 y_true - y_pred 的殘差,它通過特征選擇機制達到了類似的效果。當第二步的注意力模塊被告知“這些特征已經被用過了”時,它實際上是在被引導去關注那些在第一步中未能充分解釋目標變量方差的特征。這可以被看作是在特征空間中的“殘差學習”。
-
基于新選出的特征,產生一個新的“預測貢獻”。這個貢獻的作用就是修正或細化第一步的判斷。
-
這個過程在多個步驟中重復,每一步都試圖利用新的特征組合來進一步完善整體的預測。
TabNet架構設計
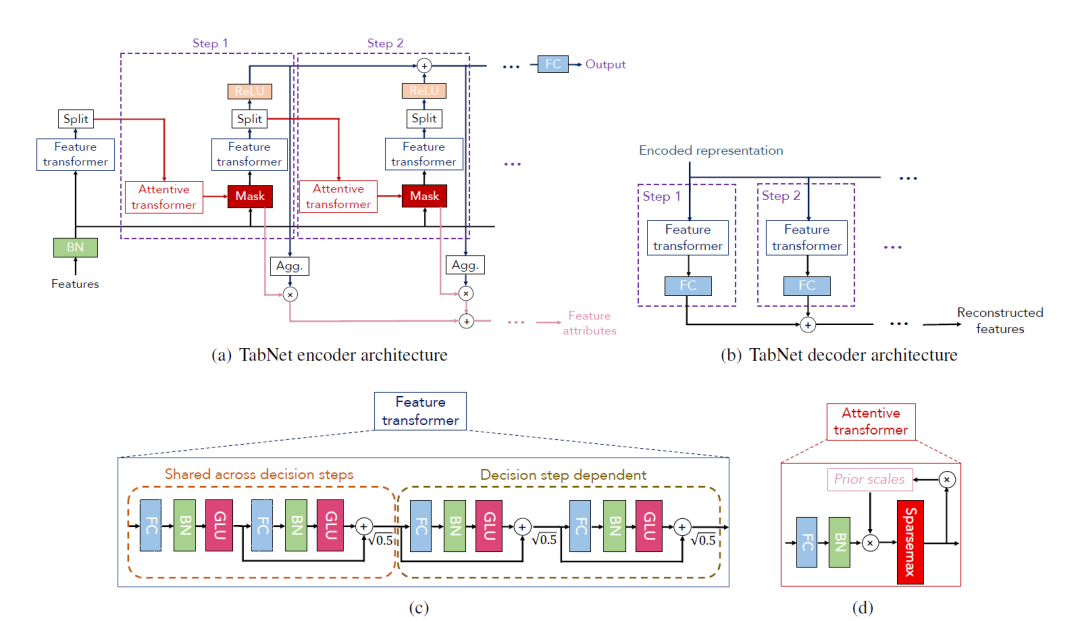
TabNet 將預測分解為多個步驟。在每一步,它都用一個注意力模塊(Attentive Transformer)來智能地、稀疏地挑選出一組當前最相關的特征,然后用另一個模塊(Feature Transformer)來處理這些特征并得出初步結論。這個過程是序列化的,因為后一步的選擇會受到前一步的影響,從而使模型能夠全面而高效地利用所有特征信息,最終做出高質量的預測。
自監督學習
在整個有監督的決策流程開始之前,TabNet可以通過一個自監督的預訓練任務來“熱身”。模型通過隨機遮蔽(Mask)一部分特征,然后嘗試用剩余的特征來預測被遮蔽的內容。
-
賦予模型關于“特征關系圖譜”的先驗知識:模型被迫學習到特征之間復雜的相關、互補或冗余關系。
-
提升決策效率:當進入正式的序列化決策流程時,Attentive Transformer不再是盲目選擇特征,而是基于已經學到的“常識”,做出更明智、更高效的特征選擇。
Attentive Transformer (注意力轉換器)
Attentive Transformer是決策的起點,它的核心使命是回答:“在當前步驟,我應該關注哪些特征?”
它接收上一步處理過的信息,利用注意力機制為所有特征計算出一個“特征權重”。特征權重基于sparsemax的激活函數和正則化,使得注意力模塊每次只選擇少數幾個最關鍵的特征,將其權重設為非零,而其他大量無關特征的權重則為零,從而完成動態選擇最重要特征的目的。
序列化更新:它有一個“記憶機制”。在生成新的Mask時,它會參考一個“先驗尺度”(Prior Scale),該尺度記錄了每個特征在之前所有步驟中被使用的總程度。如果一個特征已被頻繁使用,模型會被激勵去降低對它的關注,轉而探索新的、未被充分利用的特征。
Feature Transformer (特征轉換器)
一旦Attentive Transformer選定了特征,Feature Transformer就接手處理,它的使命是:“利用這些選中的特征,我能得出什么結論?”
該模塊接收 Attention Mask M_i 篩選和加權后的特征,通過幾層神經網絡對被選中的特征進行復雜的非線性變換,提取出有用的信息,并為最終預測貢獻一部分結果。
多步驟決策
所有決策步驟(比如N步)都完成后,模型會將每個步驟產生的“預測貢獻”加權求和,得到最終的預測結果。
其中,加權系數與每個步驟探索“新特征”的程度有關,具體來說,與(1 - Prior_i)有關(Prior_i是到第i步為止的特征累積使用度)。這種機制確保了最終的預測結果是建立在一系列互補、多樣化的特征視角之上,從而更加魯棒和準確。
二、代碼實現
Pytorch-tabnet可以實現以下任務:
- TabNetClassifier:二元分類和多類分類問題
- TabNetRegressor:簡單和多任務回歸問題
- TabNetMultiTaskClassifier:多任務多分類問題
整個模型可分為自監督預訓練 (Self-supervised Pre-training)+有監督微調 (Supervised Fine-tuning),官方展示的二分類或多分類示例中僅僅展示了有監督微調部分。下面代碼展示頁只包括模型訓練部分:
Step1:包和數據載入預處理
from pytorch_tabnet.tab_model import TabNetClassifierimport torch
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import roc_auc_scoreimport pandas as pd
import numpy as np
np.random.seed(0)import scipyimport wget
from pathlib import Pathfrom matplotlib import pyplot as plt
# %matplotlib inlineimport os
os.environ['CUDA_VISIBLE_DEVICES'] = f"0"
import torch
torch.__version__
import optuna
import scipy.sparse# filein_name = filein.replace(".csv","")
filein_name ="tmp"
save_path = './Result_' + filein_name + '_s73_try1/' # raw_datasetpaths = [save_path + "/input/", save_path + "/result/", save_path + "/models/"]
for path in paths:if not os.path.exists(path):os.makedirs(path)
# 數據加載
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
dataset_name = 'census-income'
out = Path(os.getcwd()+'/data/'+dataset_name+'.csv')
out.parent.mkdir(parents=True, exist_ok=True)
if out.exists():print("File already exists.")
else:print("Downloading file...")wget.download(url, out.as_posix())
train = pd.read_csv(out)
target = ' <=50K'
# 數據預處理,比如標簽編碼
nunique = train.nunique()
types = train.dtypescategorical_columns = []
categorical_dims = {}
for col in train.columns:if types[col] == 'object' or nunique[col] < 200:print(col, train[col].nunique())l_enc = LabelEncoder()train[col] = train[col].fillna("Unknown")train[col] = l_enc.fit_transform(train[col].values)categorical_columns.append(col)categorical_dims[col] = len(l_enc.classes_)
# else:
# train.fillna(train.loc[train_indices, col].mean(), inplace=True)
# 劃分數據集
if "Set" not in train.columns:train["Set"] = np.random.choice(["train", "valid", "test"], p =[.8, .1, .1], size=(train.shape[0],))
print(train["Set"].value_counts())train_indices = train[train.Set=="train"].index
valid_indices = train[train.Set=="valid"].index
test_indices = train[train.Set=="test"].index
# 生成cat_idxs,cat_dims等參數
unused_feat = ['Set']features = [ col for col in train.columns if col not in unused_feat+[target]] cat_idxs = [ i for i, f in enumerate(features) if f in categorical_columns]cat_dims = [ categorical_dims[f] for i, f in enumerate(features) if f in categorical_columns]grouped_features = [[0, 1, 2], [8, 9, 10]]
X_train = train[features].values[train_indices]
y_train = train[target].values[train_indices]X_valid = train[features].values[valid_indices]
y_valid = train[target].values[valid_indices]X_test = train[features].values[test_indices]
y_test = train[target].values[test_indices]
Step2: 模型訓練
Step 2.0:參數解釋
數據處理方面
- cat_idxs: 所有類別特征在輸入特征矩陣 X 中的列索引
- cat_dims:含了每個類別特征的基數(cardinality),也就是該特征有多少個不同的取值。
- cat_emb_dim:將類別變量中的每一個類別表示成一個長度為多長的特征。
- grouped_features:比如獨熱編碼后的特征,比如身高體重與BMI
模型訓練參數:
- n_d, n_a:代表決策流(decision stream)和注意力流(attention stream)的輸出維度。它們共同決定了模型每一步的“寬度”。通常將它們設置為相等的值,例如 8, 16, 32, 64。從較小的值開始(如 n_d=8, n_a=8),如果模型欠擬合(訓練集和驗證集表現都不好),則逐步增大。如果模型過擬合(訓練集表現遠好于驗證集),可以嘗試減小它們或增加正則化。
- n_steps:模型中決策步驟的數量。每個步驟都會選擇一部分特征進行處理。值越大,模型越復雜,理論上能學習更復雜的模式。通常取值在 3 到 10 之間。更多的步驟會增加訓練時間,也可能導致過擬合。
- gamma:特征重用系數。值越大(接近2.0),每個特征在所有決策步驟中被使用的可能性就越小,鼓勵模型在不同步驟關注不同特征。值越小(接近1.0),特征可以被更頻繁地重用。如果感覺模型在不同步驟總是關注相同的特征,可以適當增大 gamma。
- lambda_sparse:稀疏性正則化系數。這是TabNet的一個關鍵特性,它鼓勵模型在每一步只選擇最重要的少數特征,從而實現可解釋性并防止過擬合。值越大,特征選擇越稀疏。如果模型嚴重過擬合,可以嘗試增大此值。如果模型欠擬合,或者你發現重要特征沒有被選入,可以減小此值。搜索范圍建議: [1e-4, 1e-3, 1e-2, 0.1] (通常在對數尺度上搜索)
處理數據類別不平衡(SMOTE和weights通常只用一種)
- weights: 設置類別權重,也是處理不平衡數據的方法。weights=1 表示所有類別權重相同。如果你有類別不平衡問題,可以設置為 0(自動計算權重,使得少數類有更高權重)
優化器與學習率調度器調優
- optimizer_fn: Adam 通常是個不錯的選擇。AdamW 是 Adam 的改進版,可以嘗試替換。在對數尺度上搜索,通常 1e-3 到 2e-2 是一個比較常見的范圍。
- scheduler_fn 和 scheduler_params: ReduceLROnPlateau 通常是更好的選擇。它會監測驗證集上的指標(如 valid_auc),當指標在一定 patience 內不再提升時,自動降低學習率。
Step 2.1: 基于optuna自動搜索超參數
import optuna
import torch
import scipy.sparse
max_epochs = 50 if not os.getenv("CI", False) else 2# 數據增強
from pytorch_tabnet.augmentations import ClassificationSMOTE
#aug = ClassificationSMOTE(p=0.2)# 此時X_train, y_train, X_valid, y_valid, cat_idxs, cat_dims, grouped_features 已定義def objective(trial):# 定義要搜索的超參數空間n_d = trial.suggest_int("n_d", 8, 32, step=8) n_steps = trial.suggest_int("n_steps", 3, 7) # 決策步驟數gamma = trial.suggest_float("gamma", 1.0, 2.0)# 特征重用系數,值越大,特征重用可能性越小lambda_sparse = trial.suggest_float("lambda_sparse", 1e-4, 1e-2, log=True) # 值越大,特征選擇越稀疏;過擬合,增大此值,使模型更專注,減少對噪音的學習lr = trial.suggest_float("lr", 1e-3, 3e-2, log=True)virtual_batch_size = trial.suggest_categorical("virtual_batch_size", [128, 256])weight_decay = trial.suggest_float("weight_decay", 1e-6, 1e-3, log=True)mask_type = trial.suggest_categorical("mask_type", ["entmax", "sparsemax"])aug_p = trial.suggest_float("aug_p", 0.1, 0.4, step=0.1)aug = ClassificationSMOTE(p=aug_p)# 設置模型參數tabnet_params = {"cat_idxs": cat_idxs,"cat_dims": cat_dims,"cat_emb_dim": 2,"grouped_features": grouped_features,"n_d": n_d,"n_a": n_d, # 保持 n_a 和 n_d 一致"n_steps": n_steps,"gamma": gamma,"lambda_sparse": lambda_sparse,"mask_type": mask_type, # sparsemax,entmax"optimizer_fn": torch.optim.AdamW, "optimizer_params": dict(lr=lr, weight_decay=weight_decay),"scheduler_fn": torch.optim.lr_scheduler.ReduceLROnPlateau,"scheduler_params":dict(mode="max",patience=5, min_lr=1e-5,factor=0.5)}clf = TabNetClassifier(**tabnet_params)# 訓練模型:在超參數搜索時,可以適當減少 max_epochs 和 patience 來加速max_epochs = 50patience = 10clf.fit(X_train=X_train, y_train=y_train,eval_set=[(X_valid, y_valid)],eval_name=['valid'],eval_metric=['auc'],max_epochs=max_epochs,patience=patience,batch_size=2048, # 增大 batch_sizevirtual_batch_size=virtual_batch_size,num_workers=0,drop_last=False, # 在搜索時可以先關掉augmentations=aug, # 暫時關閉增強,專注于模型結構)# 返回要優化的目標# clf.best_cost 是驗證集上最好的損失,我們希望最大化AUC# clf.history['valid_auc'] 是一個列表,取最后一個值或最大值valid_auc = max(clf.history['valid_auc'])return valid_auc# 開始優化
study = optuna.create_study(direction="maximize", study_name='TabNet optimization') # direction="maximize" 因為我們要最大化 AUC
study.pruners = optuna.pruners.MedianPruner() # 增加剪枝,提前終止不好的試驗
study.optimize(objective, n_trials=2, timeout=6*60) # n_trials 是你想要嘗試的超參數組合數量# 輸出最佳參數
print("Best trial:")
trial = study.best_trial
print(" Params: ")
for key, value in trial.params.items():print(f" {key}: {value}")best_params = trial.params
Step 2.2: 基于最優超參數訓練模型
tabnet_params = dict(cat_idxs=cat_idxs,cat_dims=cat_dims,cat_emb_dim=2,grouped_features=grouped_features,n_d=best_params['n_d'], n_a=best_params['n_d'], n_steps=best_params['n_steps'], gamma=best_params['gamma'],lambda_sparse=best_params['lambda_sparse'],mask_type=best_params['mask_type'],optimizer_fn=torch.optim.Adam,optimizer_params=dict(lr=best_params["lr"], weight_decay=best_params["weight_decay"]),scheduler_fn=torch.optim.lr_scheduler.ReduceLROnPlateau,scheduler_params=dict(mode="max",patience=5,min_lr=1e-5,factor=0.5),verbose=0)clf = TabNetClassifier(**tabnet_params)
# This illustrates the behaviour of the model's fit method using Compressed Sparse Row matrices
sparse_X_train = scipy.sparse.csr_matrix(X_train) # Create a CSR matrix from X_train 優化內存使用和加速模型訓練。
sparse_X_valid = scipy.sparse.csr_matrix(X_valid) # Fitting the model
max_epochs = 50
aug = ClassificationSMOTE(p=best_params["aug_p"])
clf.fit(X_train=sparse_X_train, y_train=y_train,eval_set=[(sparse_X_train, y_train), (sparse_X_valid, y_valid)],eval_name=['train', 'valid'],eval_metric=['auc'],max_epochs=max_epochs, patience=20,batch_size=1024, virtual_batch_size=128,num_workers=0,drop_last=True, #丟棄最后一個批次# 類別不平衡weights=0,augmentations=aug, compute_importance=True
)
# plot losses
plt.figure(figsize=(3,2))
plt.plot(clf.history['loss'])
plt.show()# plot learning rates
plt.figure(figsize=(3,2))
plt.plot(clf.history['lr'])
plt.show()
# plot auc
plt.figure(figsize=(3,2))
plt.plot(clf.history['train_auc'], label='Train AUC')
plt.plot(clf.history['valid_auc'], label='Valid AUC')
plt.legend()
plt.show()
Step 2.3: 預測及結果保存
# save tabnet model
savefile = save_path + "/models/tabnet_model"
saved_filepath = clf.save_model(savefile)# load tabnet model
loaded_model = TabNetClassifier()
loaded_model.load_model(saved_filepath)
loaded_model
Step 3:特征可解釋性-tabnet固有
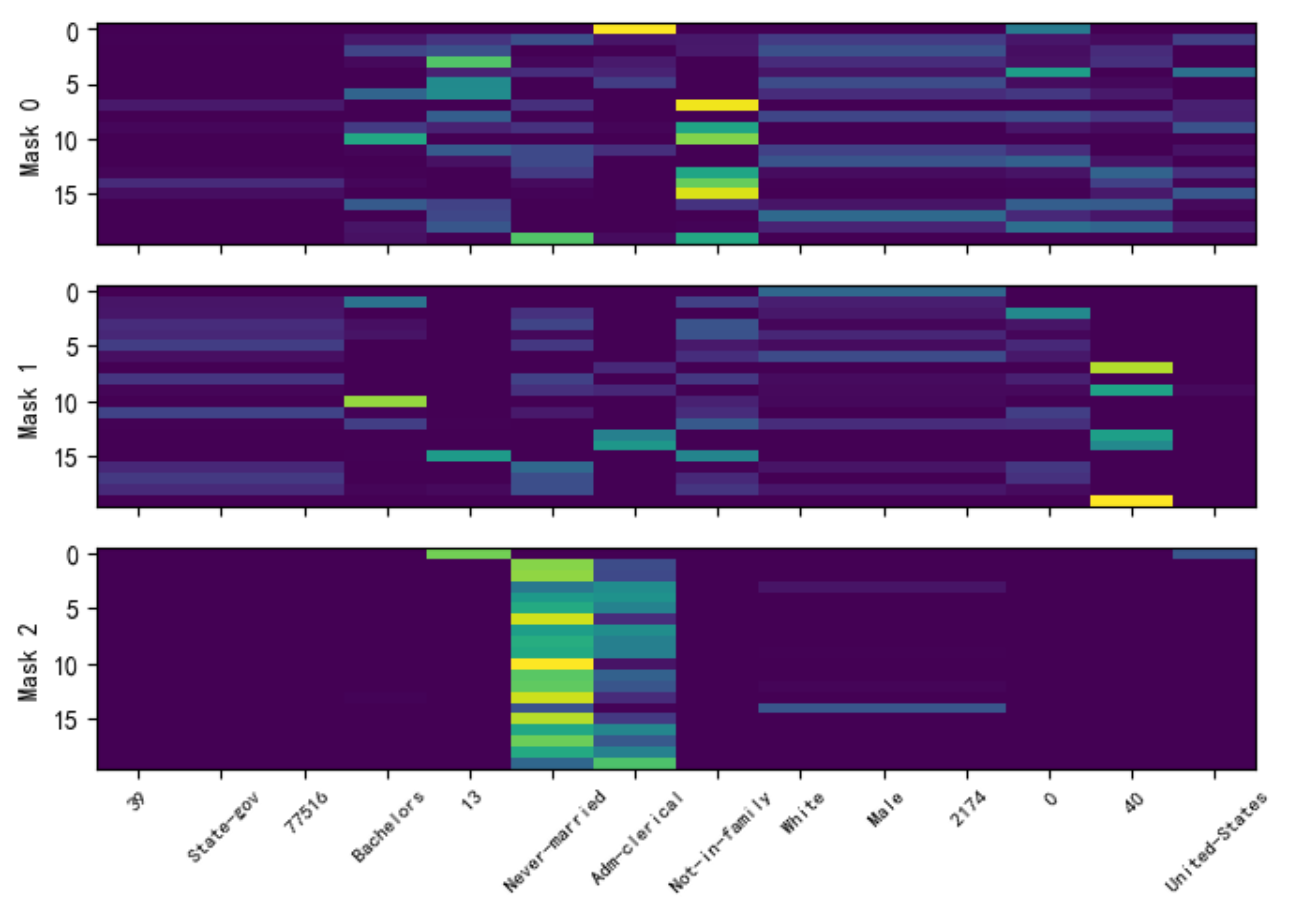
explain_matrix, masks = clf.explain(X_test)
# explain_matrix 是對所有決策步驟 (steps) 的掩碼 (masks) 進行聚合后的結果,它代表了模型對輸入 X_test 中每個樣本的最終或整體的特征重要性。
# masks 提供了更深層次、更細粒度的解釋。它是一個列表,其中包含了模型在每個決策步驟中生成的原始掩碼。這讓你能夠窺探模型的“思考過程”。列表長度等于決策步驟數 (n_steps)。每個數組展示了在該步驟中,模型對每個特征的關注度。行為樣本,列為特征,亮度為重要性
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# 獲取特征重要性
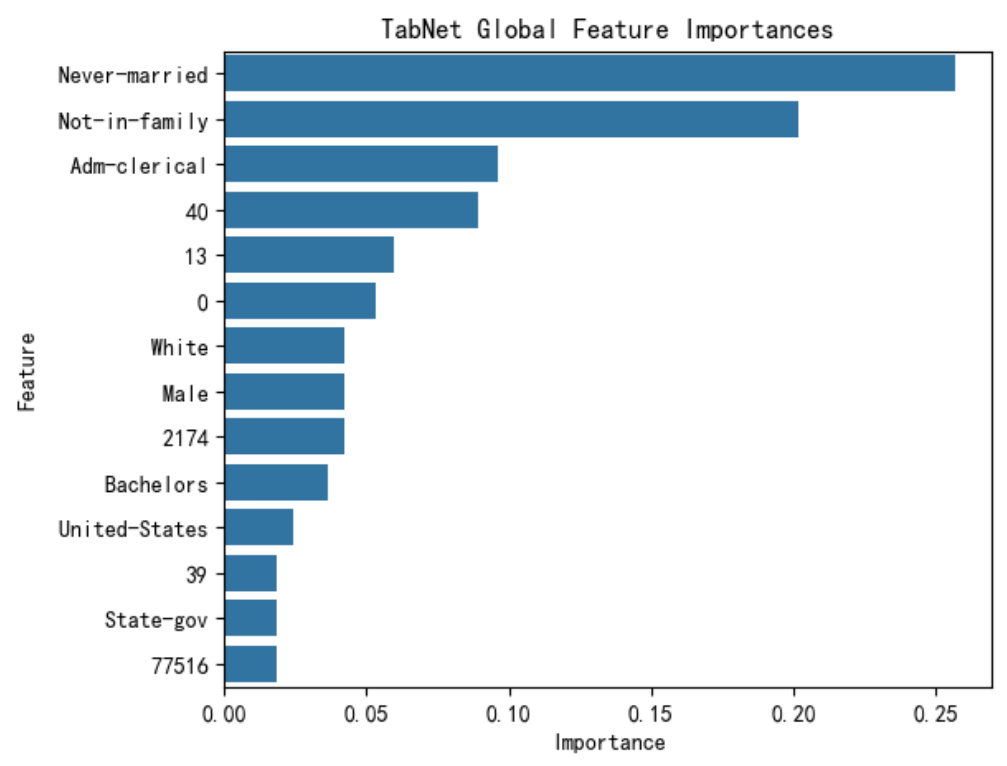
importances = clf.feature_importances_feature_importance_df = pd.DataFrame({'Feature': features,'Importance': importances}).sort_values('Importance', ascending=False)# 可視化
plt.figure(figsize=(6, 5))
sns.barplot(x='Importance', y='Feature', data=feature_importance_df)
plt.title('TabNet Global Feature Importances')
plt.show()print(feature_importance_df)
# 選擇前20個樣本在每一步中特征選擇與應用頻率
split_num = len(masks.keys())
num_features = masks[0].shape[1]fig, axs = plt.subplots(split_num, 1, figsize=(7,5))
for i in range(split_num):axs[i].imshow(masks[i][:20], aspect='auto')axs[i].set_ylabel(f"Mask {i}")axs[i].set_xticks(list(np.arange(num_features)))axs[i].set_xticklabels(labels = [], rotation=45,fontsize=7)
axs[i].set_xticklabels(labels = features, rotation=45,fontsize=8)
plt.tight_layout( )
plt.show()
Step3:特征可解釋性-SHAP
# pip show shap
import shap
shap.initjs()
explainer = shap.KernelExplainer(clf.predict, X_train)X_test_ = X_test[1:100,:]
shap_values = explainer.shap_values(X_test_, nsamples=20)
print(shap_values)
X_test_ = pd.DataFrame(X_test_,columns=features)
shap.summary_plot(shap_values, X_test_, plot_type = 'violin', max_display=10) # dot violin
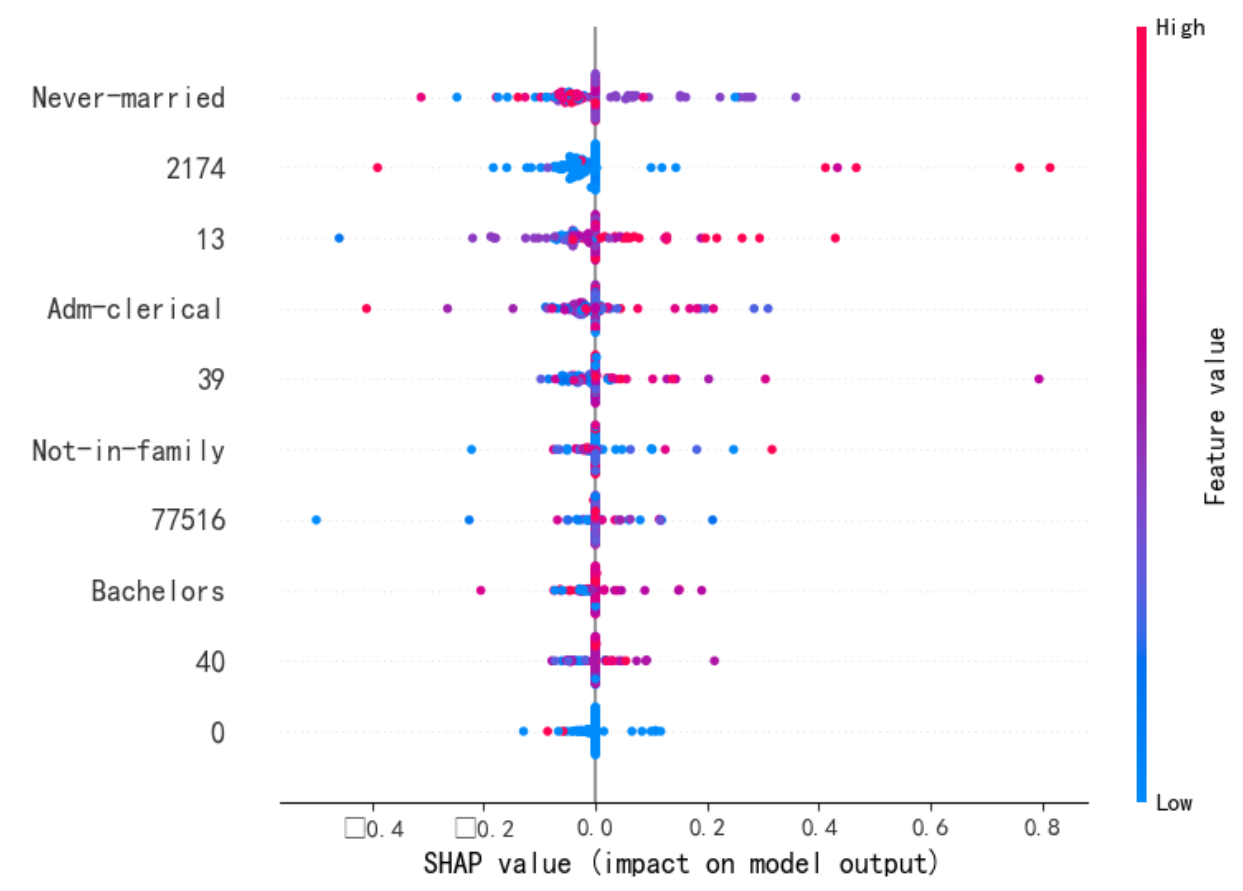
shap.summary_plot(shap_values, X_test_, plot_type="bar") #[class_index]
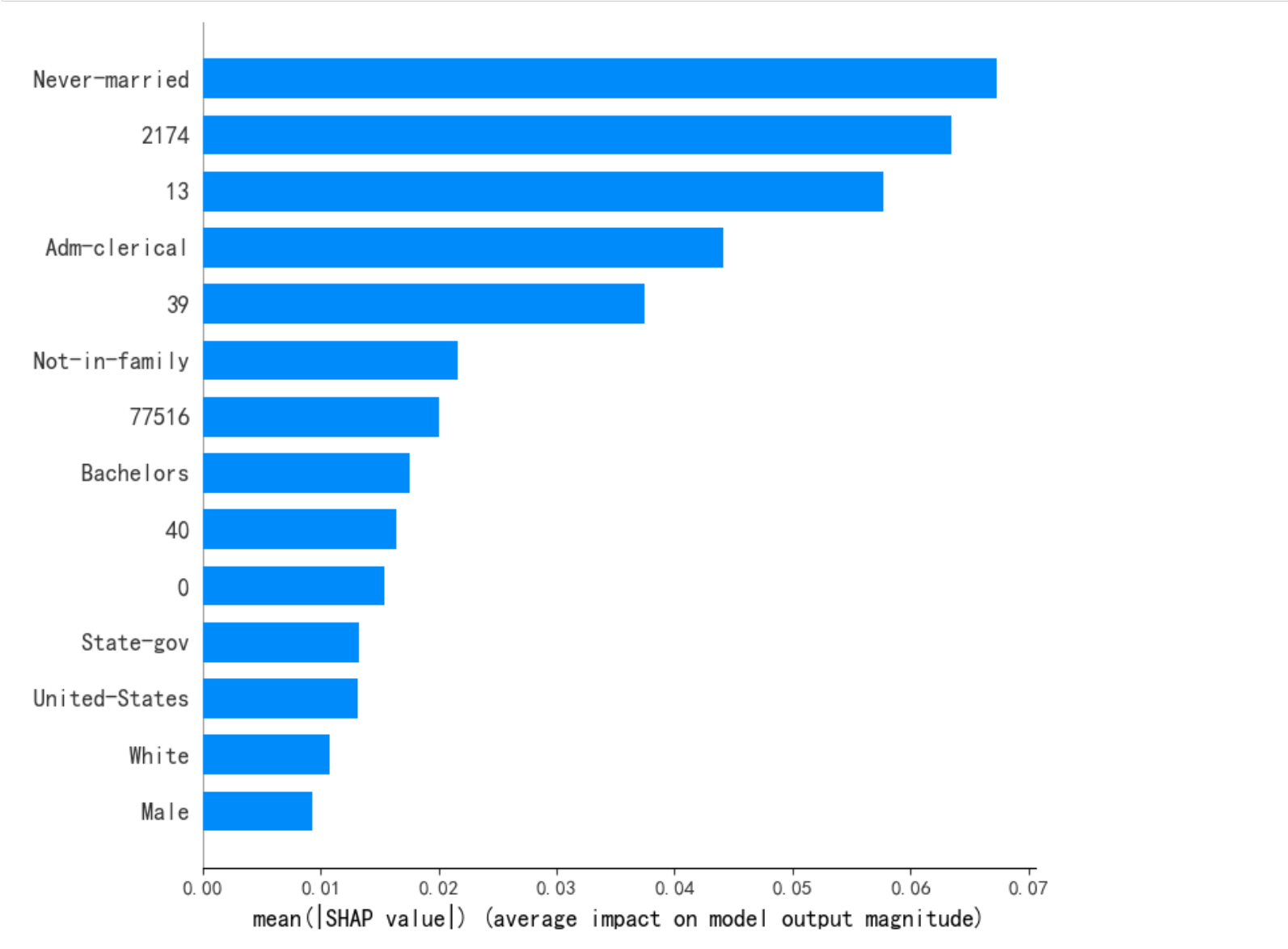
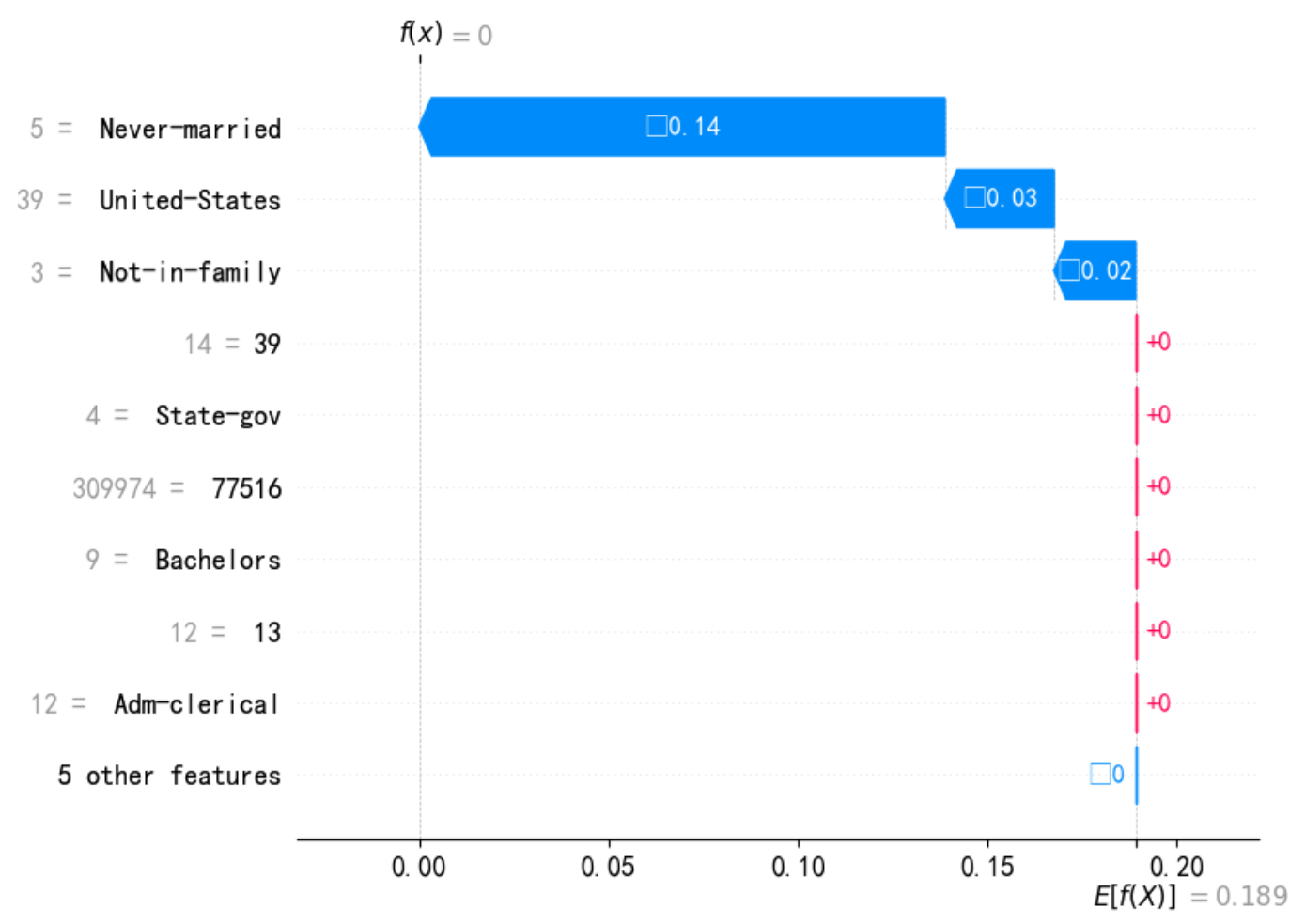
print(f"--- 解釋樣本 {idx} 的瀑布圖 ---")shap.waterfall_plot(shap.Explanation(values=shap_values[idx,:], # shap_values[class_index][idx,:],base_values=explainer.expected_value, # explainer.expected_value[class_index]data=X_test_.iloc[idx,:],feature_names=X_test_.columns.tolist())
)
三、參考
github: https://github.com/dreamquark-ai/tabnet
https://mp.weixin.qq.com/s/6tdSoOOc7I7v-LSyGZ96rA
https://7568.github.io/2021/11/26/tabnet.html
https://zhuanlan.zhihu.com/p/152211918
shap:https://colab.research.google.com/drive/1bAXxurZEWfkCTyPeJn0YbHMrSKbneOKL?usp=sharing#scrollTo=C9qTb-lhNzVH
調優:https://www.kaggle.com/code/neilgibbons/tuning-tabnet-with-optuna/notebook(ReduceLROnPlateau);https://www.kaggle.com/code/optimo/the-beauty-of-tabnet-a-simple-baseline(OneCycleLR)




)

)









:單調棧)
)

