目錄
一、為什么你的數據集成總失敗?
1.數據沒有統一標準
2.數據 “斷點多”,打通成本高
3.數據 “用不起來”,價值難落地
二、數據集成的正確做法是什么?
第一步:明確 “集成為了誰”— 用業務目標倒推數據需求
第二步:盤點 “數據資產”—— 搞清楚 “有什么”“缺什么”
第三步:清楚”數據質量“——用 “四性” 來判斷
三、數據集成路徑怎么選?
方案 1:輕量級 ETL(適合中小企業 / 離散制造)
方案 2:實時流集成(適合大型制造 / 流程制造)
方案 3:數據中臺(適合集團化 / 多基地制造)
結語
數據集成,聽著高大上,但制造業做過的都知道——坑多、失敗率高!
- 設備數據在PLC里,
- 生產數據在MES里,
- 質量數據在另一臺機器上...
想搞個分析?東拼西湊、手動核對,折騰半天數據不準,效率還低!
為什么花了錢、費了勁,數據集成還是做不成?
問題往往不在技術本身,而是你根本沒搞清楚這三個根本性問題。
今天就跟大家好好聊聊這三個問題:
- 為啥你的數據集成總失敗?
- 想成功,到底該避開哪些坑,抓住哪些關鍵?
- 數據集成的路徑到底該怎么選?
一、為什么你的數據集成總失敗?
在說 “怎么做” 之前,得先說說 “為啥難”。
國內制造企業搞數據集成費勁,根本上是:
- 業務太復雜
- 技術又跟不上
具體來說,有三個常見的讓人頭疼的地方:
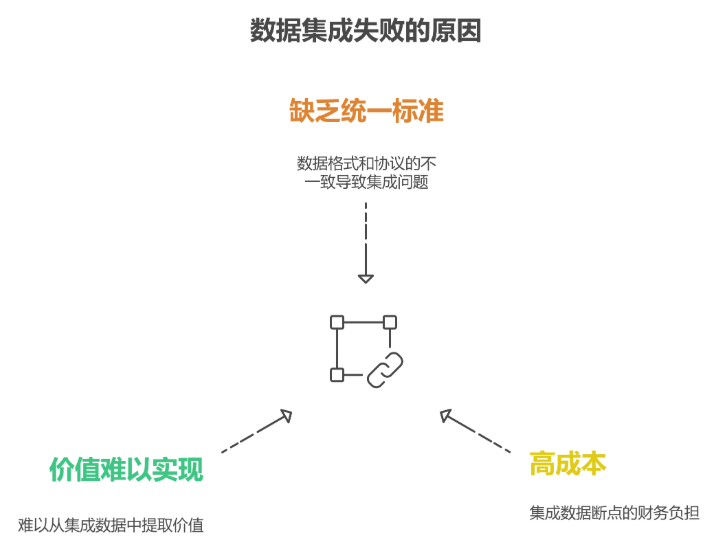
1.數據沒有統一標準
制造業涉及工藝、設備、質量、供應鏈等好多環節,每個環節的數據說法都不一樣。
比如:
- 設備部門用 “OEE(設備綜合效率)” 看產能,但不同產線對 “停機” 的說法就可能不一樣;
- 質量部門用 “CPK(過程能力指數)” 看良率,可供應商給的原材料數據可能用 “批次合格率”;
- 老設備的傳感器數據是按分鐘采的,新上的智能設備是按秒采的,時間記錄的精度不一樣。
簡單來說,就是數據標準不統一,整合起來處處是阻礙。
2.數據 “斷點多”,打通成本高
制造業的數據鏈很容易斷,具體來說就是:
(1)縱向斷:
從研發(PLM)→生產(MES)→售后(CRM),數據基本不怎么互通。
比如:
研發的設計 BOM(物料清單)和生產的制造 BOM,版本經常亂套,排產的時候材料用錯是常事兒。
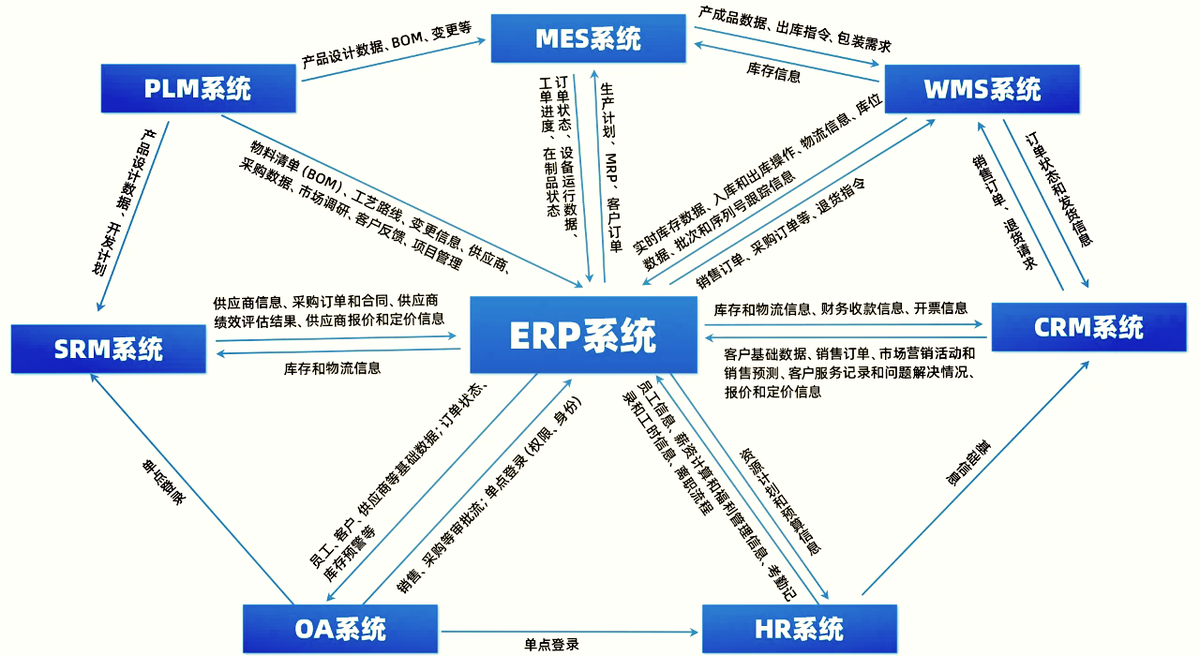
(2)橫向斷:
同一個工廠的不同產線,用的 ERP 模塊可能都不一樣:
- 有的用 SAP,
- 有的用金蝶,
- 甚至還有用 Excel 手寫記錄的。
(3)內外斷:
供應商的交貨數據、客戶的訂單變更,想實時傳到企業內部系統里,難著呢。
這些斷點,每打通一個都得花不少錢,你說難不難?
3.數據 “用不起來”,價值難落地
很多企業覺得把數據放一塊兒就是集成了。
結果呢?
- 數據不少,但能用到的維度太少:只采了設備運行的數據,沒把工藝參數和質量結果關聯起來,想分析啥參數組合容易出不良品,根本沒法弄;
- 分析就停在看個表面:能看到實時產量、設備狀態,可要說根據歷史停機數據,預測下一周設備可能出啥故障,做不到;
- 業務部門不認可:生產工人覺得多了一堆填表的活兒,管理層覺得這些數據跟做決策沒啥關系,你說這集成了有啥用?
說到底,就是數據沒真正用起來,價值根本落不了地。
二、數據集成的正確做法是什么?
解決數據集成的難題,關鍵是別光想著技術,得盯著業務價值來做。
結合行業里做得好的例子,我總結了 “四步走” 的法子,從需求到落地,一步一步來,準沒錯。
第一步:明確 “集成為了誰”— 用業務目標倒推數據需求
數據集成說到底是為了解決業務問題,不是為了炫技術。
開始之前,這三個問題必須想清楚:
首先是業務場景:
- 是想提高生產效率,比如減少停機時間;
- 還是想提升產品質量,少出點不良品;
- 或者是想讓決策快點,排產能靈活調整。
其次是用戶角色:
集成完了,誰用這些數據?
- 一線工人可能需要實時知道咋操作;
- 車間主任得盯著生產過程;
- 管理層要能看到全局情況。
不同的人需求不一樣,工人要操作方便,管理層要看得全面,你說對嗎?
這時就可以:
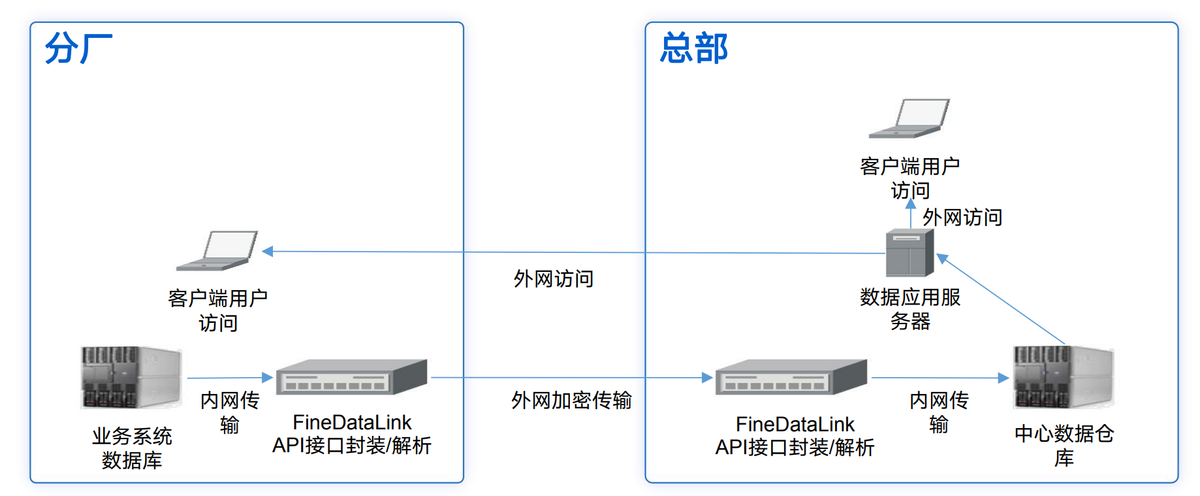
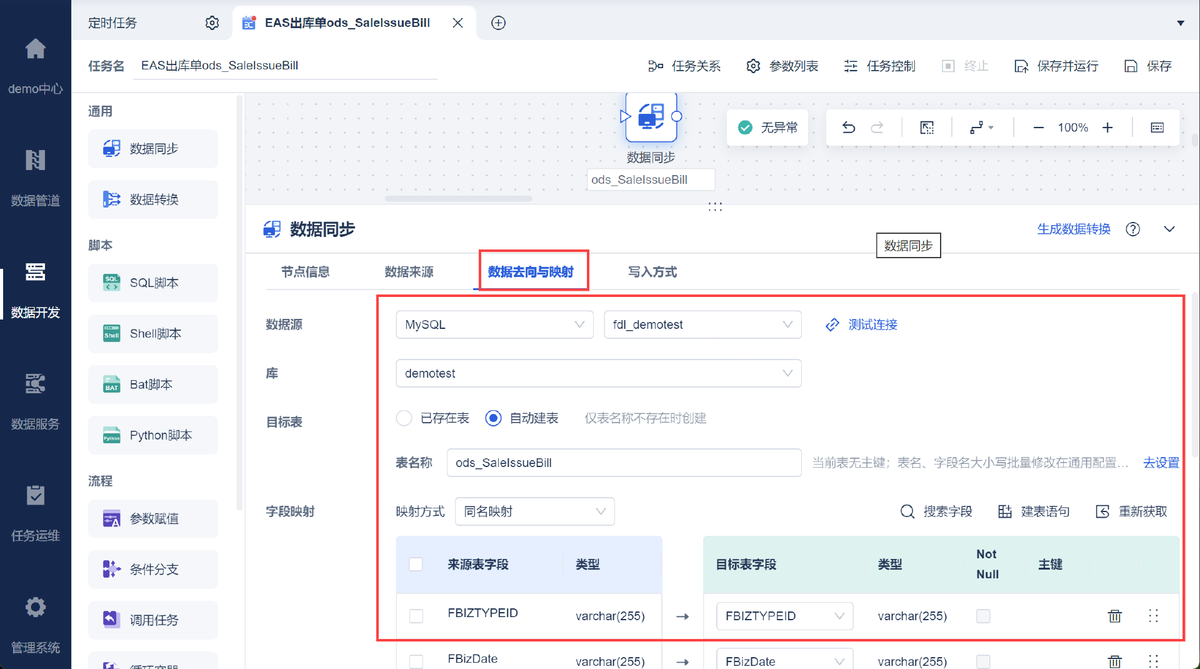
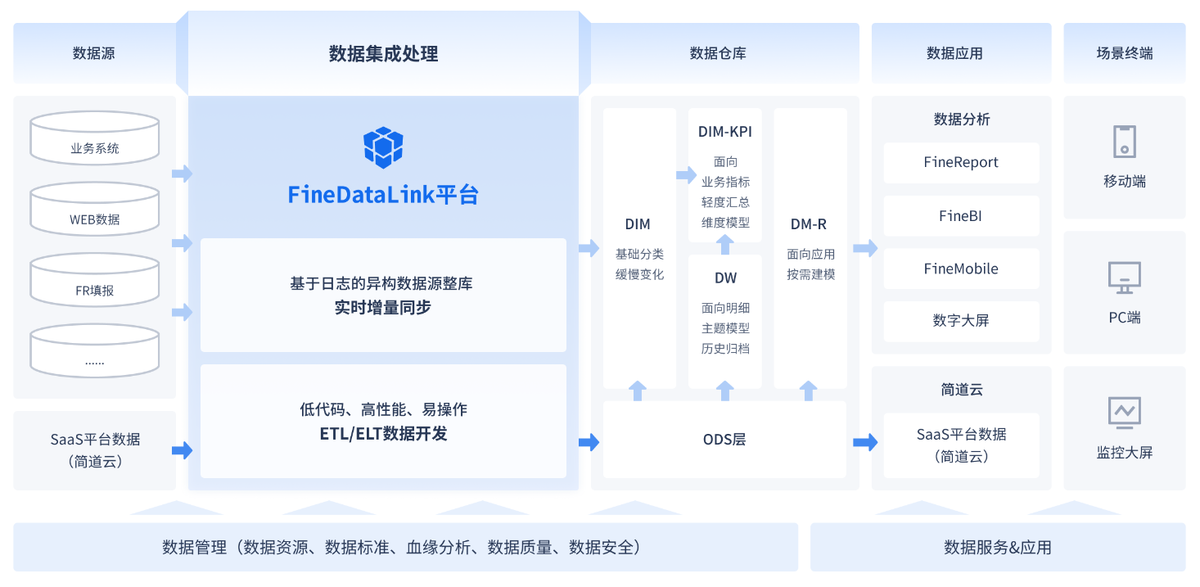
借助數據集成平臺FineDataLink,將 EAS 系統和OA 系統存儲的數據,通過數據開發-定時任務將數據同步至同一數據庫,形成數據分析架構線上化,實現數據口徑的統一。還能實時監控生產數據,提供及時的決策支持。FineDataLink體驗地址→免費FDL激活(復制到瀏覽器打開)
最后看價值指標:
怎么才算集成成功了?
- 是設備綜合效率(OEE)提高 5%,
- 還是不良品追溯時間從 3 天縮到 30 分鐘,
- 或者訂單交付準時率漲了 10%。
沒有這些能衡量的指標,很容易瞎忙活。
一句話總結:明確誰用、解決啥問題、怎么算成功,集成才有方向。
第二步:盤點 “數據資產”—— 搞清楚 “有什么”“缺什么”
數據集成不是簡單挪數據,得先把手里的數據好好查查。
具體來說,要清楚數據在哪兒?
制造業的數據存的地方五花八門,得分類理清楚:
- 結構化數據:就是存在數據庫里的,像 MES 里的生產訂單、ERP 里的采購記錄;
- 半結構化數據:有固定格式,但不是正經數據庫里的,比如設備傳感器的 JSON 日志、質檢照片的元數據;
- 非結構化數據:沒固定格式的,像工人的操作日志 Word 文檔、會議紀要 PDF。
這些地方都得查到,漏一個都可能影響后續分析。
第三步:清楚”數據質量“——用 “四性” 來判斷
“四性”簡單來說就是:
- 完整性:關鍵的字段有沒有漏的;
- 準確性:數據符不符合實際情況;
- 一致性:同一個指標在不同系統里的說法是不是一樣;
- 及時性:數據采集和傳輸有沒有耽誤。
數據質量不行,集成了也白搭。
還要看缺啥數據:
比如想分析 “供應商來料質量對生產線效率的影響”,得有:
- 供應商交貨批次
- 來料檢驗結果(IQC 數據)
- 生產線因為來料問題停機的時間(MES 數據)。
要是其中某類數據沒記錄,比如 IQC 的詳細情況沒記,那得先補上,不然分析沒法做。
三、數據集成路徑怎么選?
數據集成的技術方法不少,關鍵是要為業務場景服務,所以要選適合自己的,別盲目追新。
根據數據要不要實時用、系統復不復雜,我總結了三種常用方案:
方案 1:輕量級 ETL(適合中小企業 / 離散制造)
如果企業:
- 數據量不大,一天下來不到 1GB,
- 系統也比較穩定,就只有 ERP 和 MES,
那用 ETL 工具,定時把數據抽出來、洗洗干凈、轉成能用的格式就行。
具體操作方法:
- 先把 “主數據” 定下來,像物料編碼、設備編號,讓各系統說法一致;
- 記清楚數據從哪兒來、經過啥處理,方便以后找問題;
- 定期檢查數據質量,比如用 Python 寫個小程序,看看關鍵指標有沒有大的波動。
優勢很多:
- 花錢少,工具要么免費,要么不貴;
- 容易學,技術團隊學一兩周就能上手。
但局限也很明顯:
實時性差,一般按小時或者按天同步數據。
比如像:
設備要提前預測故障這種需要秒級響應的情況,就不適合。
簡單說,就是小投入解決大問題,適合中小企業起步用。
方案 2:實時流集成(適合大型制造 / 流程制造)
像汽車、化工這些行業,需要實時盯著生產線,比如 OEE 隨時算、設備一停機就報警,那必須用流處理技術。

可以進行技術組合:
- 用 Kafka 做消息隊列,接收設備、傳感器、PLC 的實時數據;
- 用 Flink 或者 Spark Streaming 實時計算;
- 用 ClickHouse 或者 HBase 存數據,能做到毫秒級查詢。
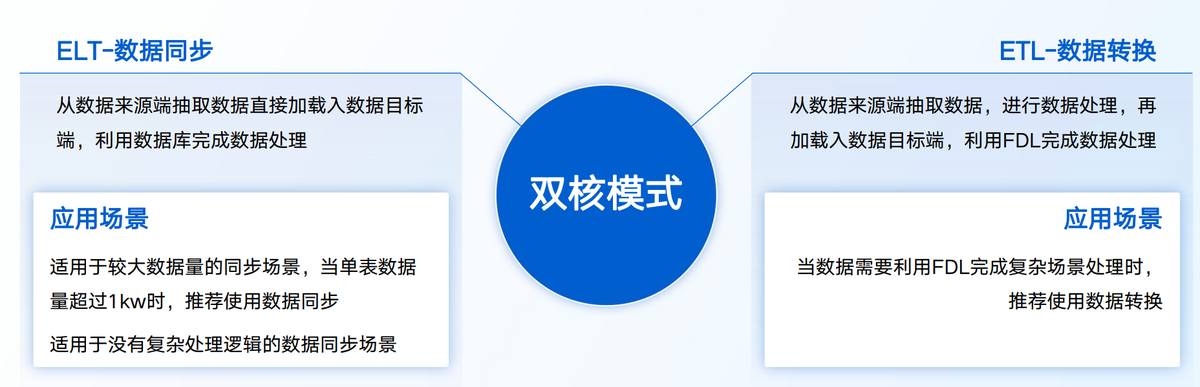
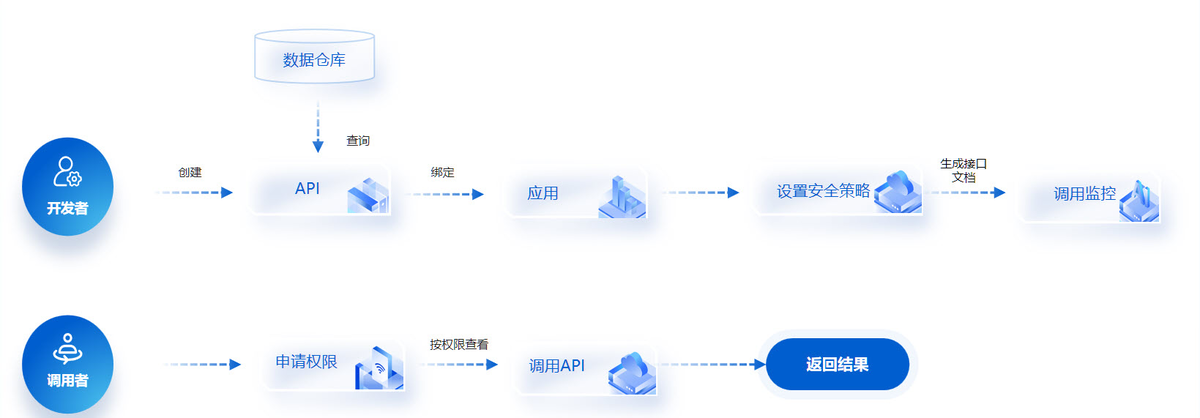
- 用FineDataLink一鍵發布 API 接口,解決數據傳輸最后一公里問題。
具體操作方法:
- 先做 “數據降維”,比如設備傳感器的原始數據是每秒 1 條,而分析只需要每分鐘的平均值,可先進行聚合處理;
- 設置 “流控機制”,防止數據突發洪峰壓垮系統;
- 做好 “斷點續傳”,在網絡中斷時能從上次位置繼續采集數據。
優勢是:
實時性強,延遲能控制在幾秒內,能馬上做決策。
局限性也很明顯:
- 技術比較復雜,運維團隊得熟悉這些流處理工具;
- 花錢也多,服務器和人工成本都不低。
所以說:
這種方案,適合對實時性要求高的大企業。
方案 3:數據中臺(適合集團化 / 多基地制造)
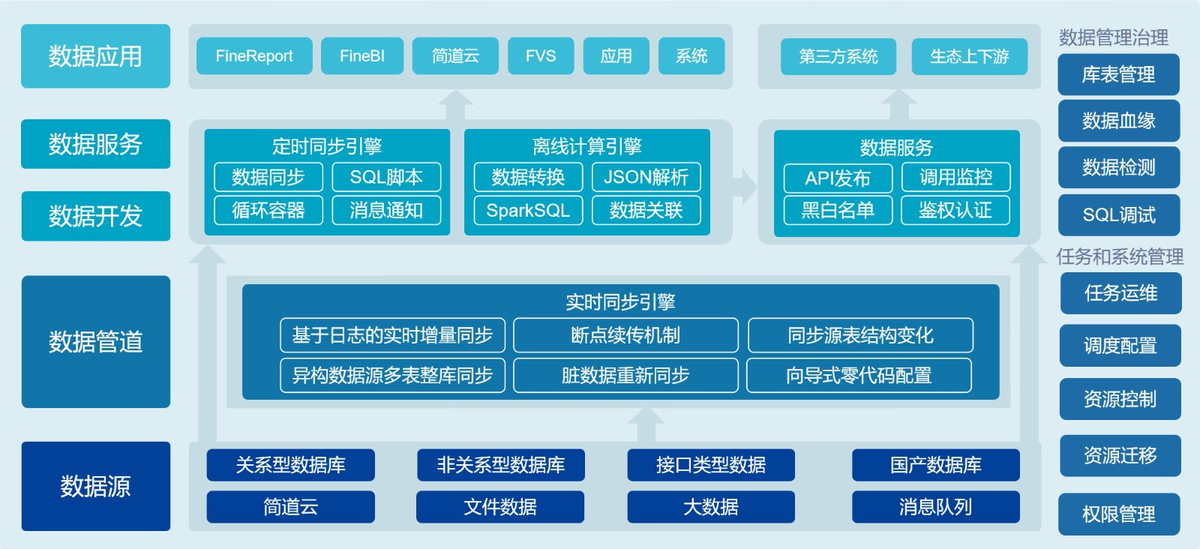
如果企業有好幾個工廠,還不在一個地方,像家電、鋼鐵行業,要把不同基地、不同系統的數據連起來,建議建個數據中臺。
這樣就能:
- 統一數據標準,通過 MDM 主數據管理,讓物料、設備、供應商的編碼在全集團都一樣;
- 把 ERP、MES、PLM、SCADA 等系統的數據都接到中臺里;
- 業務部門想用數據,通過 API 調用就行,不用直接去碰底層系統;
- 業務人員自己用低代碼工具,拖拖拽拽就能生成報表,很方便。
但要注意:
中臺不是大倉庫,別什么數據都往里塞,只整合生產、質量、供應鏈這些核心業務的數據就行。
還要:
成立個 “數據治理委員會”,IT、生產、質量部門的負責人都參與進來,別弄成 IT 自己建,業務部門不用的情況。
一句話總結:
這種方案,適合跨地域、多工廠的大企業統一管理數據。
結語
國內制造業現在正從 “拼規模” 轉向 “拼效率”“拼質量”,數據集成就是這場轉型的基礎。說到底,制造業數據集成能不能成,關鍵就看你有沒有搞定這三件事:
- 讓數據“說同一種話” (統一標準),
- 把斷掉的“數據鏈”接起來 (打通斷點),
- 讓數據真正“發揮價值” (提升業務)。
它不是簡單地挪數據,成功的集成,是讓對的數據,在對的時間,順暢地流到需要它的人手里。 做到這些,制造業的數字化轉型才算真正開始。



)

)









:單調棧)
)


