之前做個幾個大模型的應用,都是使用Python語言,后來有一個項目使用了Java,并使用了Spring AI框架。隨著Spring AI不斷地完善,最近它發布了1.0正式版,意味著它已經能很好的作為企業級生產環境的使用。對于Java開發者來說真是一個福音,其功能已經能滿足基于大模型開發企業級應用。借著這次機會,給大家分享一下Spring AI框架。
注意:由于框架不同版本改造會有些使用的不同,因此本次系列中使用基本框架是 Spring AI-1.0.0,JDK版本使用的是19。
代碼參考: https://github.com/forever1986/springai-study
目錄
- 1 Embedding
- 1.1 什么是Embedding
- 1.2 嵌入模型(Embeddings Model)
- 2 Spring AI 中的Embeddings Model
- 2 示例演示
- 3 加載本地模型
前面幾乎將Spring AI的聊天模型的功能都講了一遍,接下來開始幾章將會講解其它類型的大模型。在聊天模型中Spring AI提供了ChatClient做了一層常用的功能性封裝,比如聊天記憶、RAG、MCP等應用場景。很遺憾其它類型的大模型并沒有提供再次封裝的上層API,不過通過前面對聊天模型ChatModel的使用,也知道可以直接使用類似ChatModel對模型的操作,在Spring AI中一樣對各類大模型進行了類似ChatModel的封裝。這一章先從嵌入模型(Embeddings Model)開始。
1 Embedding
使用嵌入模型(Embeddings Model)之前,需要了解Embedding是什么?為什么要使用Embedding?
1.1 什么是Embedding
首先在人類社會中使用的文字、圖片、音頻、視頻等數據,如何讓大模型識別。這里拿文字來說明這個過程:
1)編碼: 計算機只會識別0和1,那么這時候要讓計算機識別文字,就需要把所有文字進行編碼,以中文為例比如00001代表男,00002代表女,這樣每個字都有一個編碼。
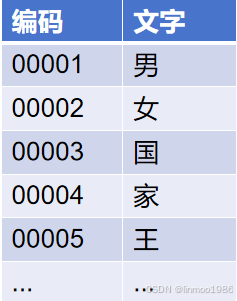
雖然編碼可以讓計算機識別,但是還是有缺點的。最大的缺點就是文字之間是有一定的關聯關系,也就是說每個字獨立編碼,那么機器是不理解文字之間的關系,為了解決這個問題,分詞就出現了。
2)Tokenizer : 為了解決文字之間的關系。這時候就有人想到使用Tokenizer 分詞器。在每個語言體系中,并不是所有的字都要獨立編碼,有些文字他們的語言體系中就是一直連在一起使用的,他們之間是有一定的含義,這樣可能只需要對子詞進行編碼即可。這樣就可以通過一定數據訓練得到合理的分詞表,這個過程就是Tokenizer做的事情。
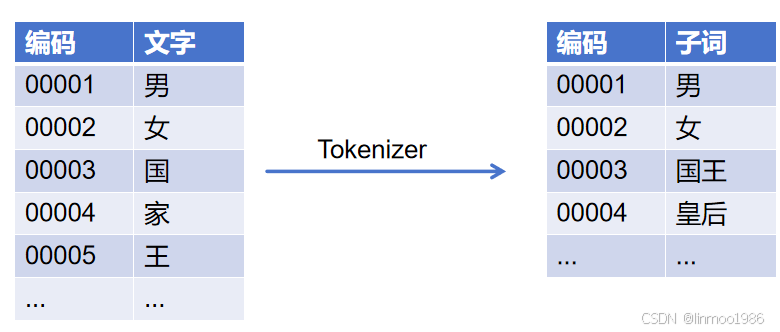
Tokenizer 雖然解決了一定的語義關系,但也造成一個問題,就是過于稀疏,占用過多資源。因為在底層都是2進制表示,那么10萬個子詞需要一個17維度(2的17次方)才能描述完,但是實際上很多位置上都是0。那么有沒有一種辦法使用更少的維度來表示更多的子詞,這時候就出現了Embedding。子詞之間的語義上關系,可能可以通過一個向量維度來表示,一個768維的就能表示768種語義關系可能就已經足夠描述所有關系。
3)Embedding: Embeding就是將每個子詞ID映射為n維向量,并與位置編碼、段落編碼相加。這個維度可以簡單理解就是相關性。比如其中一個維度表示性別,那么男人和國王在這個維度上面應該是相等的,而女人和皇后在這個維度應該也是相等的。這種通過多維度表示其實就是向量化,而且向量化之后的子詞還可以做運算,比如:國王-男=皇后-女 ,其結果在性別這個維度是相等的。
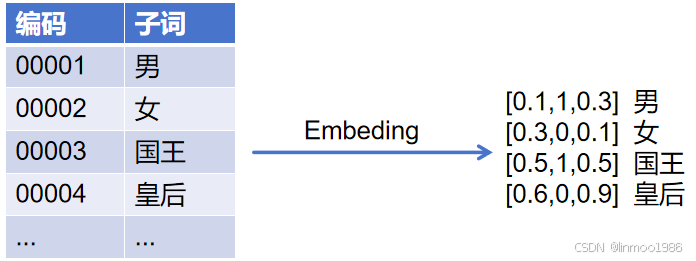
上圖示例中就是一個3維來表示,其中中間那個維度表示性別,那么國王-男和皇后-女的向量運算結果在這個性別維度上都是0。當然實際上可能會很多維,比如512、768、1024等,越多維度表示的語義更為準確,但是造成的效果就是需要更多計算量。
通過Embedding技術將文本、圖像和視頻轉換為一系列浮點數數組(即向量),能夠捕捉輸入之間的關系。這些向量旨在捕捉文本、圖像和視頻的含義。Embedding數組的長度被稱為向量的維度。通過計算兩段文本的向量表示之間的數值距離,應用程序能夠確定用于生成嵌入向量的兩個對象之間的相似度。這就是Embedding的意義。
1.2 嵌入模型(Embeddings Model)
Embeddings Model模型經過這些年的不斷改進,出現了各種各樣的Embeddings Model。這里需要注意的是Embeddings Model也是一個訓練好的模型,這里不詳細講述,大家有興趣可以去了解更深入。這個主要給大家講述幾個重要選擇Embeddings Model的實戰參考。在之前我寫的《RAG實踐系列》中的這一章《檢索增強生成RAG系列3–RAG優化之文檔處理》已經提到過。
對于我們如何選擇一個embedding,我根據一些實戰中的經驗總結如下:
- 排行榜:首先要知道有哪些embedding模型,一般可以去hugging face的排行版上找:https://huggingface.co/spaces/mteb/leaderboard
- 語言:在排行榜中,你可以根據你的業務選擇語言
- embedding維度:這個需要根據你的業務,如果你業務語義豐富,那么選擇維度更高更好,如果語義不豐富,其實選擇維度更低會更好。
- sequence length:不同embedding模型支持不同sequence length,因此需要根據你的業務選擇不同的模型
- 模型大小:這個會根據實際你有多少資源作為選擇標準
- 業務效果:以上幾個標準可能只是基本維度,最終還是需要看看業務效果,因此你可能需要選擇幾個比較合適的模型,然后再逐一的去測試一下其效果相對于你的業務結果如何
2 Spring AI 中的Embeddings Model
在Spring AI中,定義了一個EmbeddingModel接口,旨在便于與人工智能和機器學習中的嵌入模型進行集成。其主要功能是將文本轉換為數值向量,通常稱為“嵌入”。這些嵌入對于諸如語義分析和文本分類等任務至關重要。下面是其源代碼:
public interface EmbeddingModel extends Model<EmbeddingRequest, EmbeddingResponse> {/*** 需要各個模型廠家實現調用call方法 */@OverrideEmbeddingResponse call(EmbeddingRequest request);/*** 將一個text進行embedding,返回結果向量*/default float[] embed(String text) {Assert.notNull(text, "Text must not be null");List<float[]> response = this.embed(List.of(text));return response.iterator().next();}/*** 將一個文檔進行embedding,返回結果向量*/float[] embed(Document document);/*** 將多個text進行embedding,返回結果向量*/default List<float[]> embed(List<String> texts) {Assert.notNull(texts, "Texts must not be null");return this.call(new EmbeddingRequest(texts, EmbeddingOptionsBuilder.builder().build())).getResults().stream().map(Embedding::getOutput).toList();}/*** 將多個文檔進行embedding,返回結果向量*/default List<float[]> embed(List<Document> documents, EmbeddingOptions options, BatchingStrategy batchingStrategy) {Assert.notNull(documents, "Documents must not be null");List<float[]> embeddings = new ArrayList<>(documents.size());List<List<Document>> batch = batchingStrategy.batch(documents);for (List<Document> subBatch : batch) {List<String> texts = subBatch.stream().map(Document::getText).toList();EmbeddingRequest request = new EmbeddingRequest(texts, options);EmbeddingResponse response = this.call(request);for (int i = 0; i < subBatch.size(); i++) {embeddings.add(response.getResults().get(i).getOutput());}}Assert.isTrue(embeddings.size() == documents.size(),"Embeddings must have the same number as that of the documents");return embeddings;}/*** 將多個text進行embedding,但返回請求的結果Response */default EmbeddingResponse embedForResponse(List<String> texts) {Assert.notNull(texts, "Texts must not be null");return this.call(new EmbeddingRequest(texts, EmbeddingOptionsBuilder.builder().build()));}/*** 獲取嵌入向量的維度數量。請注意,通常情況下,此操作默認會執行。*/default int dimensions() {return embed("Test String").length;}}
EmbeddingModel接口設計圍繞著兩個主要目標展開:
- 可移植性:此接口確保了在各種嵌入式模型之間能夠輕松實現適應性。它使開發人員能夠通過最少的代碼更改來切換不同的嵌入技術或模型。這種設計符合 Spring 的模塊化和可互換性理念。
- 簡潔性:EmbeddingModel 簡化了將文本轉換為嵌入的流程。通過提供諸如 embed(String text) 和 embed(Document document) 這樣簡單的方法,它消除了處理原始文本數據和嵌入算法的復雜性。這一設計選擇使得開發人員,尤其是那些對人工智能不熟悉的人,能夠更輕松地在其應用程序中使用嵌入,而無需深入研究底層機制。
2 示例演示
代碼參考lesson17子模塊
示例說明:本示例使用智譜的線上embedding模型進行嵌入(由于智譜的embedding模式是付費的,請保證賬號有錢!)
1)新建lesson17子模塊,其pom引入如下:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-zhipuai</artifactId></dependency>
</dependencies>
2)配置application.properties文件
## API KEY
spring.ai.zhipuai.api-key=你的智譜模型的API KEY
3)創建演示類EmbeddingController:
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RestController
public class EmbeddingController {private final EmbeddingModel embeddingModel;public EmbeddingController(EmbeddingModel embeddingModel) {// 自動注入智譜的EmbeddingModel模型this.embeddingModel = embeddingModel;}@GetMapping("/ai/embeded")public float[] embeded(@RequestParam(value = "message", required = true, defaultValue = "測試進行嵌入") String message) {float[] embed = embeddingModel.embed(message);System.out.println("輸出的嵌入向量維度:"+embed.length);return embed;}
}
4)創建啟動類Lesson17Application:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class Lesson17Application {public static void main(String[] args) {SpringApplication.run(Lesson17Application.class, args);}}
5)演示效果
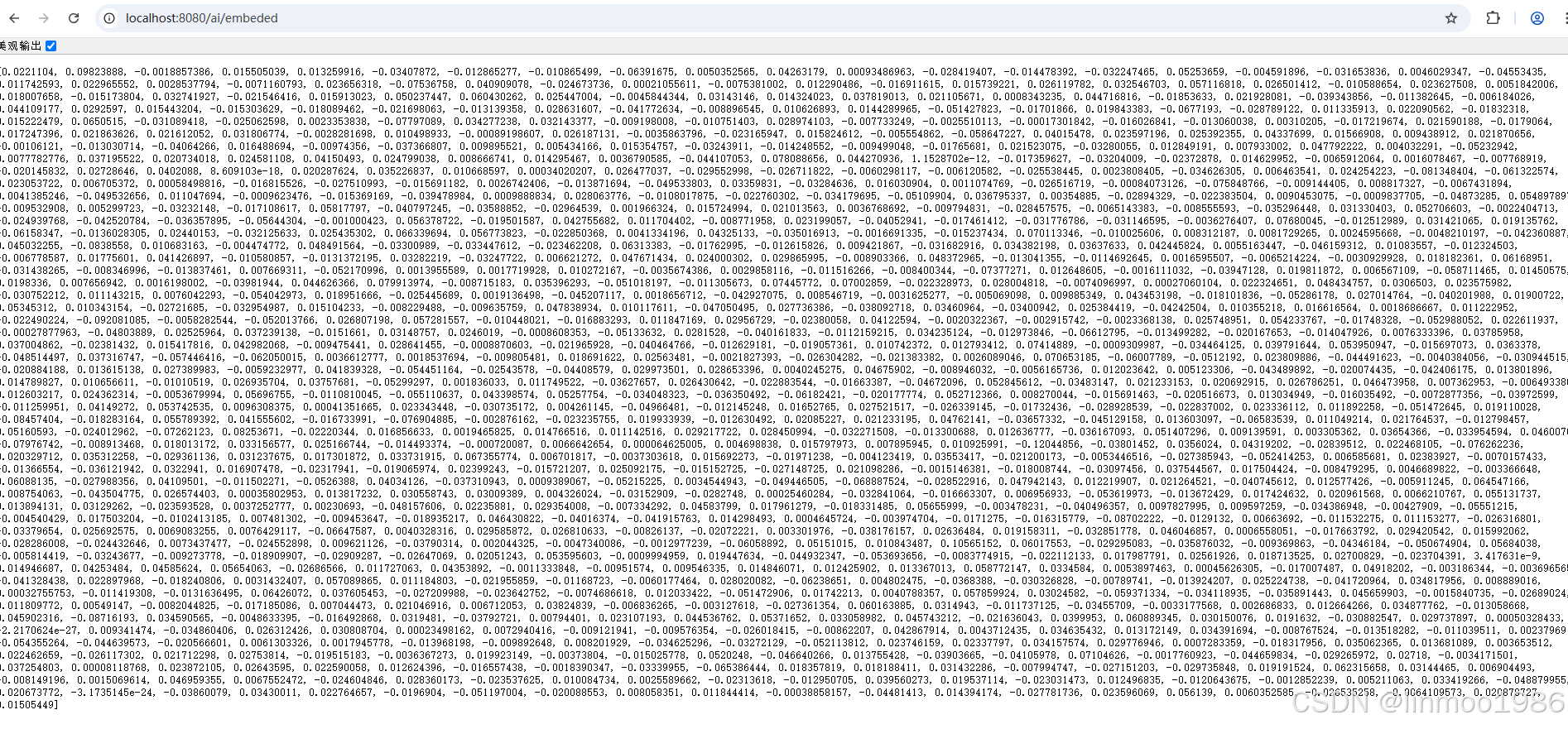
說明:可以看智譜默認的embedding模型的維度是1024維
3 加載本地模型
上面的示例是通過加載線上模型,其實有很多優秀的開源embedding模型,比如BGE-M3、M3E?等等,很多大廠的embedding也都開源,這個大家可以上網搜一下。但是有個問題,就是很多模型的權重都是基于pytorch或者tensorflow等python框架訓練出來的,那么Java中如何加載呢?這部分在前面的RAG中講過《系列之十 - RAG-加載本地嵌入模型》,大家可以回去看看該示例,這里就不在累述了。
結語:本章先簡單淺入的帶大家了解了什么是embedding,之后再講解的Spring AI中的EmbeddingModel,其提供了基礎的接口,由各大embedding模型廠商自行實現。最后舉例說明如何使用遠程和本地的EmbeddingModel。嵌入是大模型的一個基礎,它解決了人類社會的內容(文字、圖像、視頻等)與大模型直接的交互語言,因此了解embedding是非常有必要的。下一章將繼續講解非聊天模型之圖像大模型。
Spring AI系列上一章:《Spring AI 系列之二十 - Hugging Face 集成》
Spring AI系列下一章:《Spring AI 系列之二十二 - ImageModel》



)
——鏈接預測在社交網絡分析中的應用)



》免費中文翻譯 (第1章) --- Data visualization(2))

)
)







