目錄
一、Transfusion
1、概述
2、方法
二、Show-o
1、概述
2、方法
3、訓練
三、Show-o2?
1、概述
2、模型架構
3、訓練方法
4、實驗
一、Transfusion
1、概述
? ? ? ? Transfusion模型應該是Show系列,Emu系列的前傳,首次將文本和圖像生成統一到單一Transformer架構中,并通過混合訓練目標實現多模態協同學習。
? ? ? ? 另外在Transfusion中提出了Omni-attention。
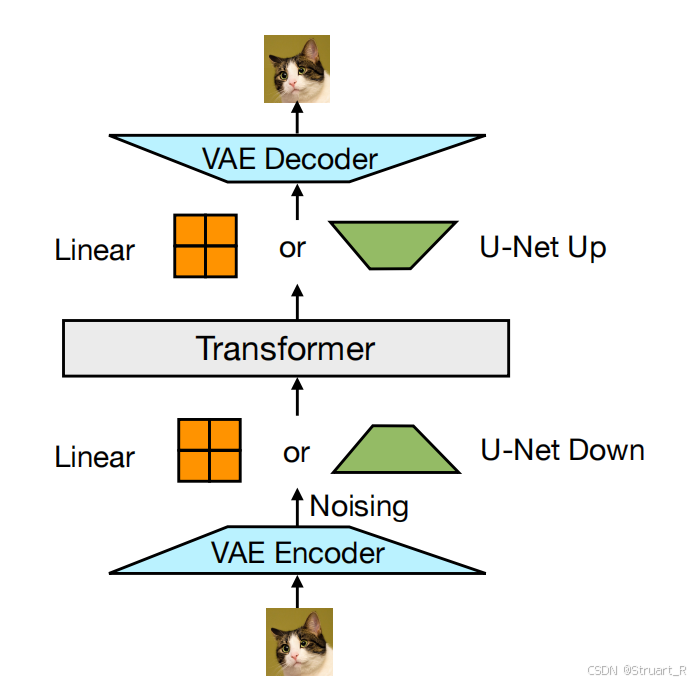
? ? ? ? 整體來說,就是把文字和圖片都轉換成Transformer能理解的token,并通過一個巨大的Transformer來學習多模態,而圖片其實中間先通過VAE轉換為連續的patch序列,再通過Transformer,最后通過VAE解碼。
2、方法
? ? ? ? 訓練目標:自回歸語言建模損失LM loss(NTP loss)和圖像的擴散模型損失DDPM loss。
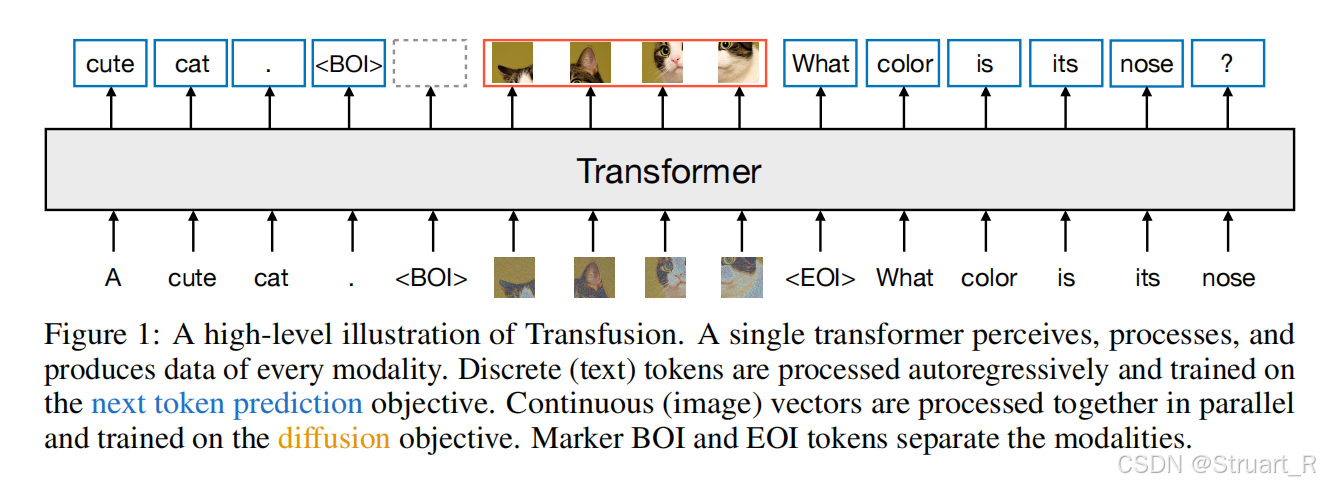
? ? ? ? 視覺部分的處理:
????????首先對256x256的原始圖像通過預訓練VAE壓縮為32x32x8的潛在張量。之后通過分塊,將潛在張量序列化為patch向量。
? ? ? ? 之后通過加噪,對潛在向量添加高斯噪聲,并經過一組U-Net下采樣塊,進一步壓縮,然后輸入到Transformer中。
? ? ? ? Transformer通過預測添加到圖像里的噪聲,注意力采用Omni-attention的方法。
? ? ? ? 之后反復去噪,更新向量信息,并通過U-Net上采樣還原維度信息,最終通過VAE解碼器重建像素圖像。
????????
二、Show-o
1、概述
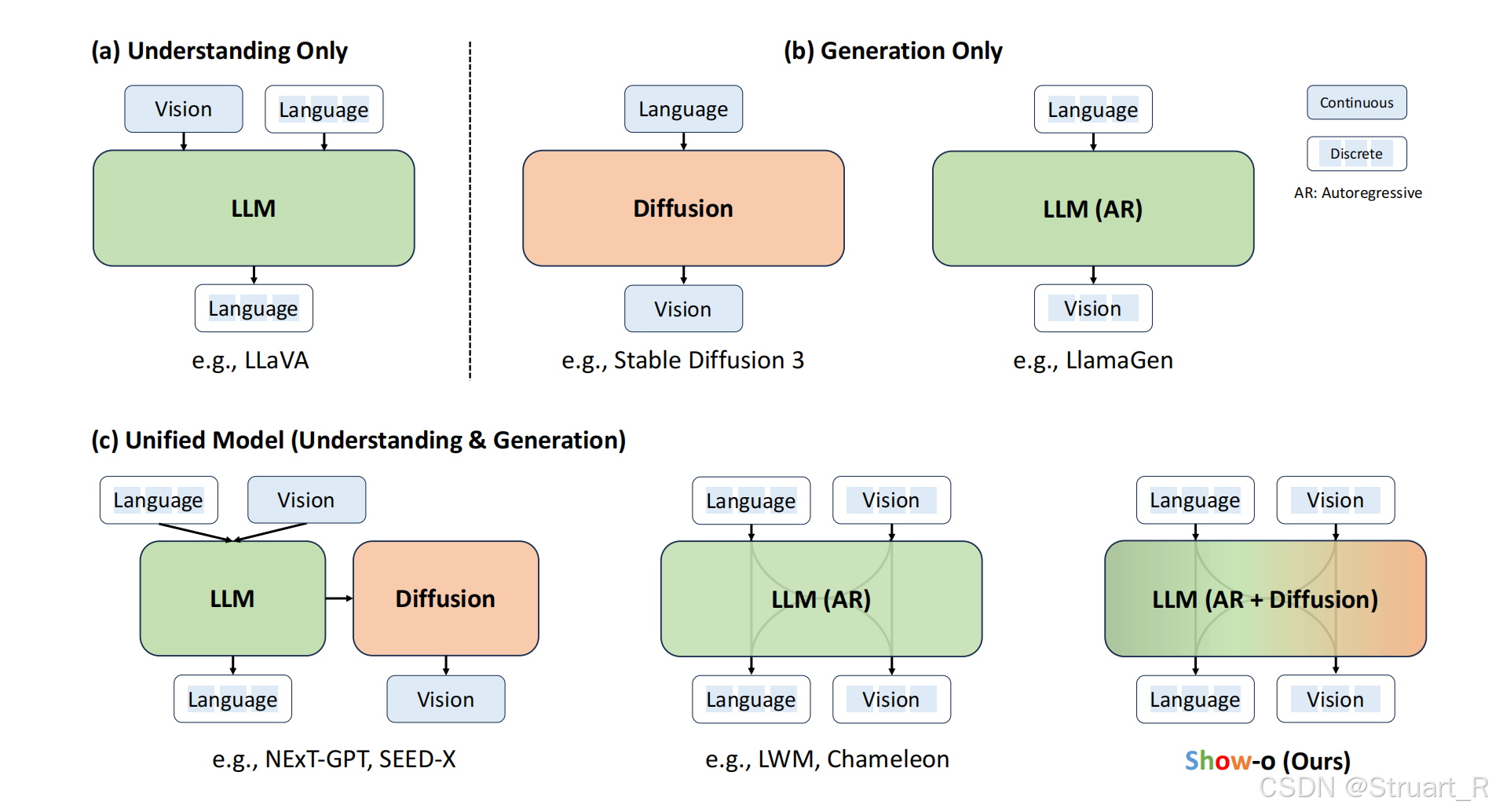
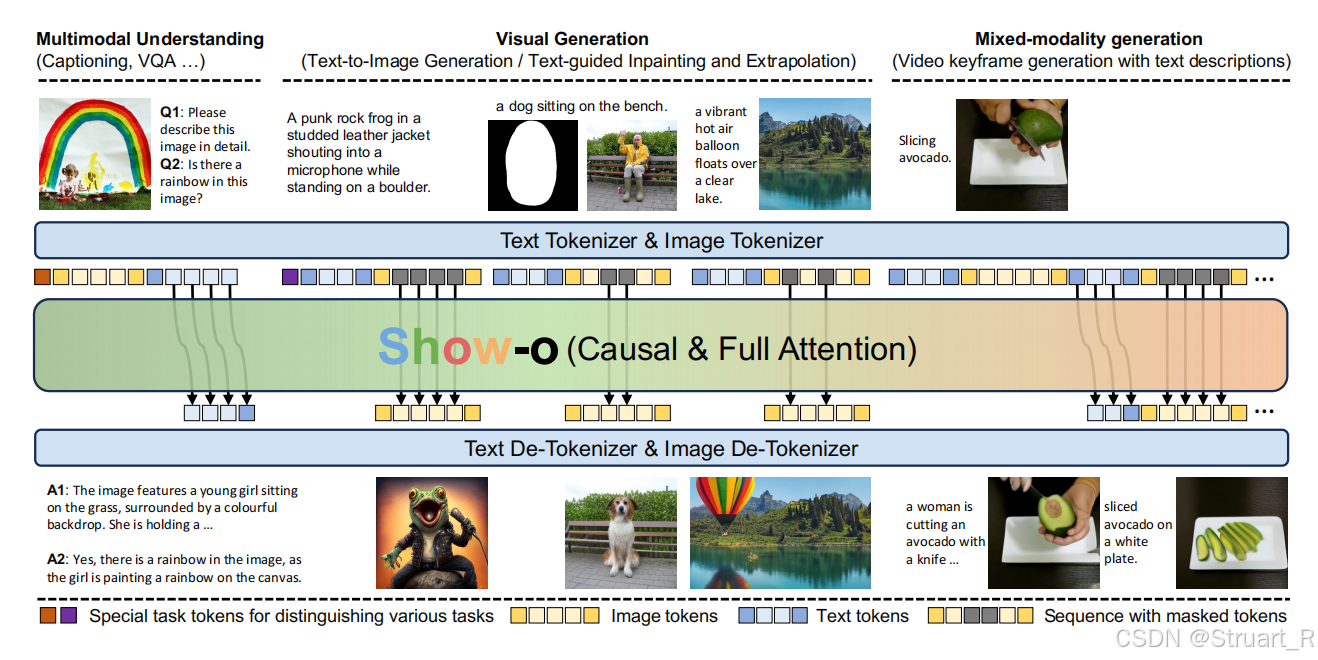
? ? ? ? 視覺理解模型的發展,從單一的視覺理解,單一的圖像生成,朝著視覺理解與生成統一的方向發展。但是以往的統一模型,要么是通過ViT+LLM,并將特征信息傳輸給diffusion用于生成圖像(NExT-GPT,SEED-X),要么是通過tokenizer+LLM+de-tokenizer的方式(Chameleon),歸根結底,都不是一個完整的Transformer架構。Show-o提出利用MAGVIT的分詞器(本質上就是MaskGIT),實現單個Transformer同時處理理解和圖像生成任務。
? ? ? ? 但隨之而來存在一個問題,文本是一個離散的tokens,圖像則是一個連續的tokens,二者本身存在明顯差異,也不容易集成到同一個網絡中。同樣以往的方法都是將文本利用text encoder后直接用LLM編碼,圖像則需要進入擴散模型中。
? ? ? ? Show-o為滿足同時處理理解和生成任務,使用AR+diffusion混合建模,文本部分完全建立在以往LLM分詞器上,保留文本推理的自回歸建模能力。圖像部分則采用MAGViT-v2,將圖像離散化為256個token,實現與文本token的符號空間對齊。
2、方法
? ? ? ? 受益于離散去噪擴散模型(D3PMs),區別于傳統擴散模型只能用于連續信息,離散去噪擴散模型可以處理離散數據(文本)間的信息,比如VQDiffusion,Copliot4D,而MaskGIT繼續簡化模型,并應用到圖像離散化數據中,Show-o則是建立在MAGVIT-v2上。
Image Tokenization
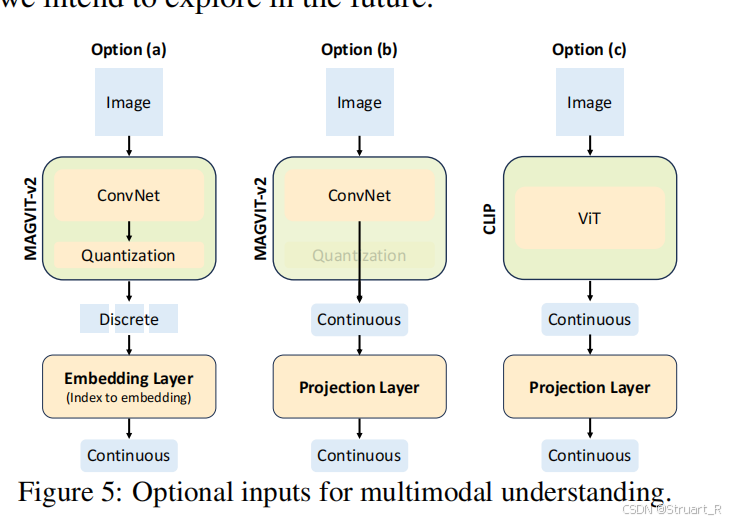
? ? ? ? 利用MAGVIT-v2作為基礎框架,訓練一個無查找量化器,避免傳統VQ-VAE的碼本查詢瓶頸。codebook size=8192,每張圖片256x256被編碼為16x16的離散tokens。由于MAGVIT-v2易于微調,所以未來將考慮衍生一個video tokenizer。(但是MAGVIT本身就是一個視頻編碼器啊,估計做了統一處理?),對于這個Image Tokenizer的架構,具體來說就是下圖a,而b,c則是后續實驗進行了對比。
Text tokenization
? ? ? ? Show-o基于預訓練LLaMA,使用相同的tokenizer進行文本數據標記,不做修改。
LLM整體架構
? ? ? ? 基于預訓練LLM LLaMA設計,保留原始的Transformer結構,但是在每一個注意力層都添加QK-Norm操作,并新增8192個可學習嵌入向量,表示離散圖像tokens。
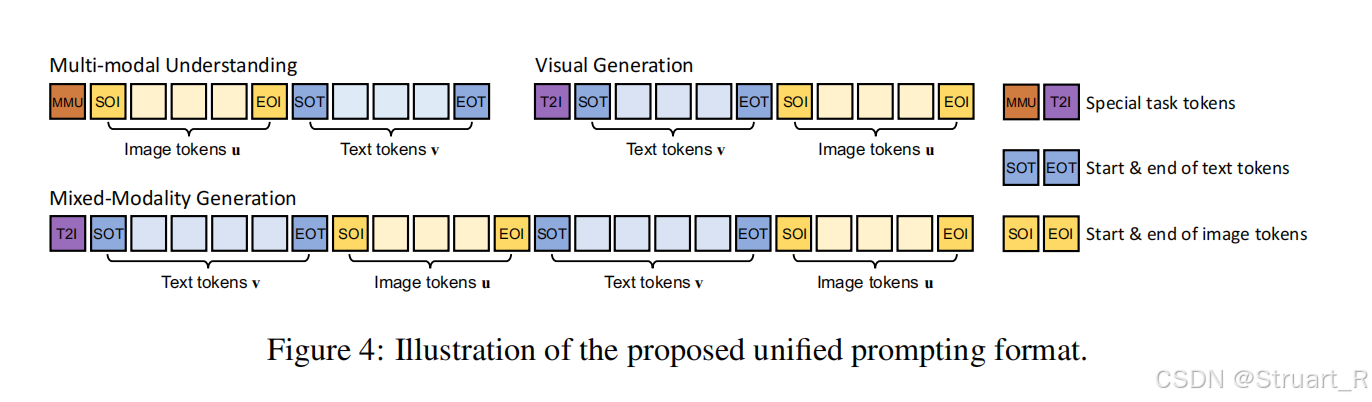
? ? ? ? 統一提示策略
? ? ? ? 為了統一訓練多模態理解和生成,設計了Unified Prompting 策略,對給定Image-text pair 通過tokenizer得到M個image tokens 和N個text tokens?
。
????????并且根據下圖的方法,設計為multi-modal understanding(多模態理解),visual generation(文生圖),mixed-modality generation(混合模態生成)三種任務,其中右側的 [MMU] 和 [T2I] 代表預定義的task token,表示執行什么具體的任務(生成文字or生成圖片), [SOT] 和 [EOT] 代表text token的開始和結束token,[SOI] 和 [EOI] 代表image?token的開始和結束token。
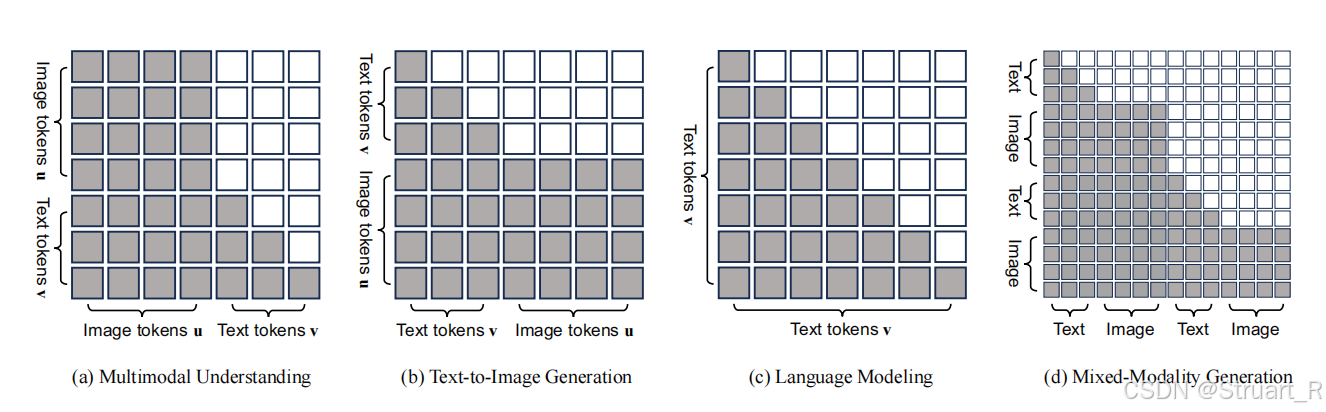
? ? ? ? Omni-Attention機制?
? ? ? ? 對于Show-o注意力機制并不是Casual attention,也不是Full attention,而是一種全新的綜合注意力機制,根據輸入序列的格式,自適應地混合和更改。可以理解為在不同Image和Text混合下,Casual attention和Full attention范圍內的一種自適應變換。
? ? ? ? 其中Show-o通過Casual attention對sequence中的text tokens進行建模,通過Full attention對image tokens進行建模。
? ? ? ? 所以鑒于上面的統一提示策略圖,提出了四種任務的注意力機制變換。
(a)多模態理解:文本關注先前所有圖像token,但是文本之間只關注以前的文本token
(b)文生圖:圖像token可以交互所有先前文本token,但是圖像間互相全交互
(c)文本建模中:退化會casual attention
(d)混合模態生成:綜合以上多種方法自適應調整。
3、訓練
? ? ? ? 訓練目標
? ? ? ? 訓練目標包含LLaMA本身的自回歸(Next-token-prediction)用于處理文本的語言建模損失,以及圖像離散擴散建模的擴散損失(Mask-token-prediction)。
? ? ? ? 對于給定M個image tokens 和N個text tokens?
? ? ? ? NTP:
? ? ? ? MTP:對于輸入的M個Image tokens?,首先以一定的比例(受 timestep控制)隨機將圖像token隨機替換為[MASK] token,得到
,然后目標以unmasked區域和text token,重建原始圖像的token。
????????????????????
? ? ? ? 基于classifier-free guidance做法,以一定的概率用空文本隨機替換conditioned text token。? ?
? ? ? ? 總損失為
 ? ? ? ? 訓練策略
? ? ? ? 訓練策略
? ? ? ? 訓練分為三個階段,由于缺乏了文本編碼器模塊,這對于文本與圖像對齊產生了很大挑戰,所以我們采用三階段的方法。
? ? ? ? 第一階段,訓練圖像token嵌入(8192個新增向量)和像素依賴學習,通過純文本RefinedWeb訓練語言建模能力,圖像分類庫ImageNet-1K訓練圖像生成能力,圖文對CC12M+SA1B訓練基礎圖文對齊。
? ? ? ? 第二階段:跨模態深度對齊,將ImageNet的分類名,轉為自然語言描述訓練文本對齊能力,文本描述能力。
? ? ? ? 第三階段:高質量數據微調。利用高質量圖文對LAION-aesthetics-12M,JourneyDB,訓練文生圖,另外通過LLaVA-Pretain-558K和LLaVA-v1.5-mix-665K訓練復雜推理指令和多任務混合指令。
? ? ? ? 推理策略
? ? ? ? 對于文本的預測,直接給定圖像或多模態問題,text token從具有更高置信度的預測token中自回歸采樣。
? ? ? ? 對于圖像的預測,通過輸入文本信息(N個token),和M個token [MASK]作為輸入,通過show-o為每一個[MASK] token預測一個logit?,其中t是時間步,每個[MASK]token的最終預測logit使用conditional logit?
和masked token的unconditional logit?
。
????????,其中w是guidance scale
? ? ? ? 下圖為去噪過程,包含T步,其中每一步保留置信度更高的image token,并替換以往的[MASK] token,隨后反饋到下一輪預測。

三、Show-o2?
1、概述
? ? ? ? Show-o2首次實現同一模型下原生統一地集成自回歸建模和Flow matching機制,實現了大規模下對文本、圖像和視頻多模態理解和生成。
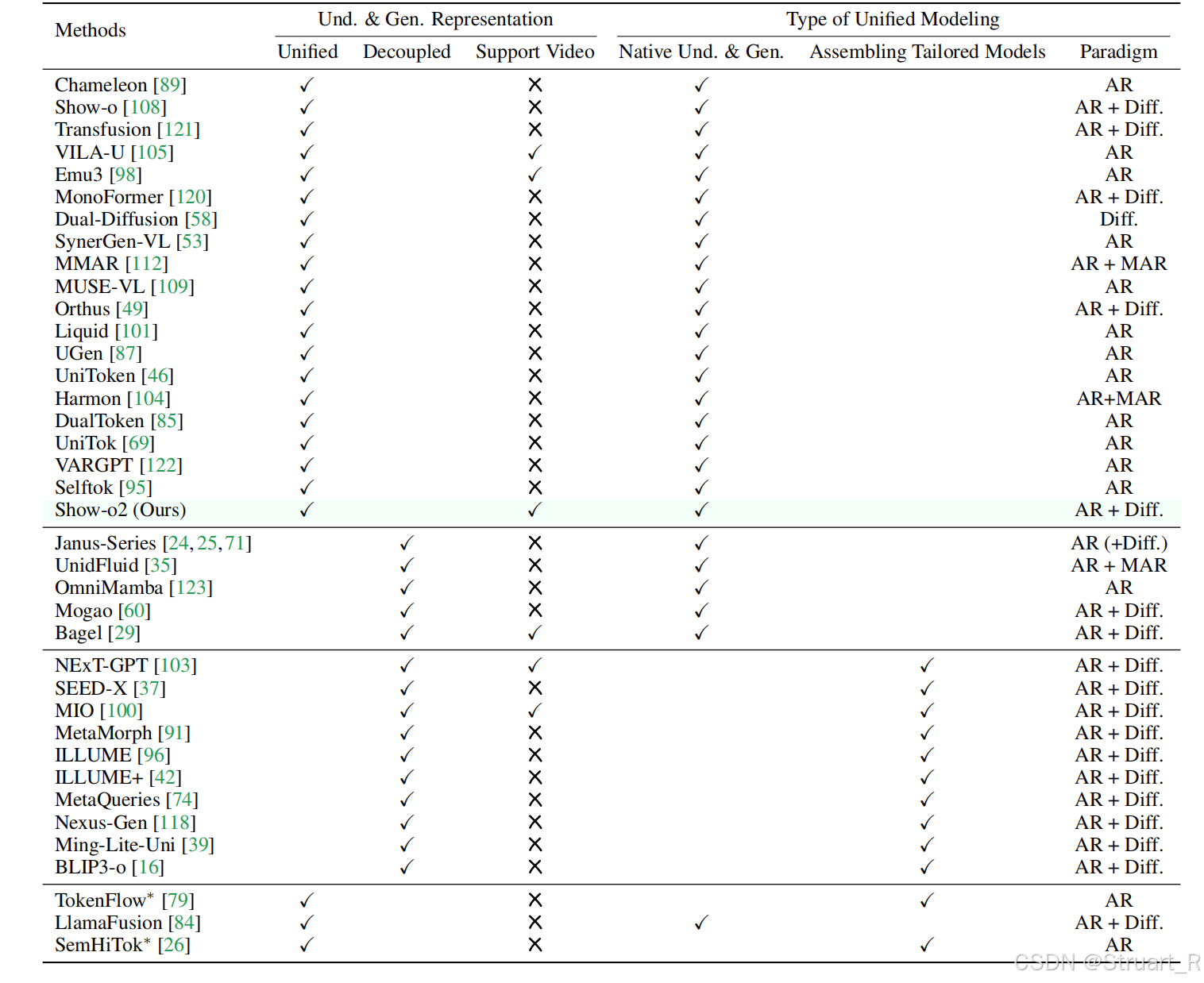
? ? ? ? 對于以往的統一多模態模型(UMM)從兩個方面進行分類,視覺表示類型和統一建模類型,對于視覺表示類型,要么是統一表示(Unified),要么是解耦模型(Und & Gen Representation)。對于統一建模類型,要么是原生統一的(Native Und & Gen),要么是組裝專家模型(Assembling Tailored Models)。下圖為所有相關模型的對比,Show-o2是第一個統一的原生多模態,支持視頻的,AR+Diff架構的模型。
? ? ? ? Show-o2引入了CogVideoX中的特色,使用3D Causal VAE對視頻進行編碼?。在訓練過程中同樣采用分層次訓練,先具備語言表達能力,在提升理解和圖、視頻生成能力。并且由于Show-o2訓練數據集的多樣性,也使得Show-o2可以理解中英文,同時可以在文檔中穿插文字,圖像,視頻序列。
2、模型架構
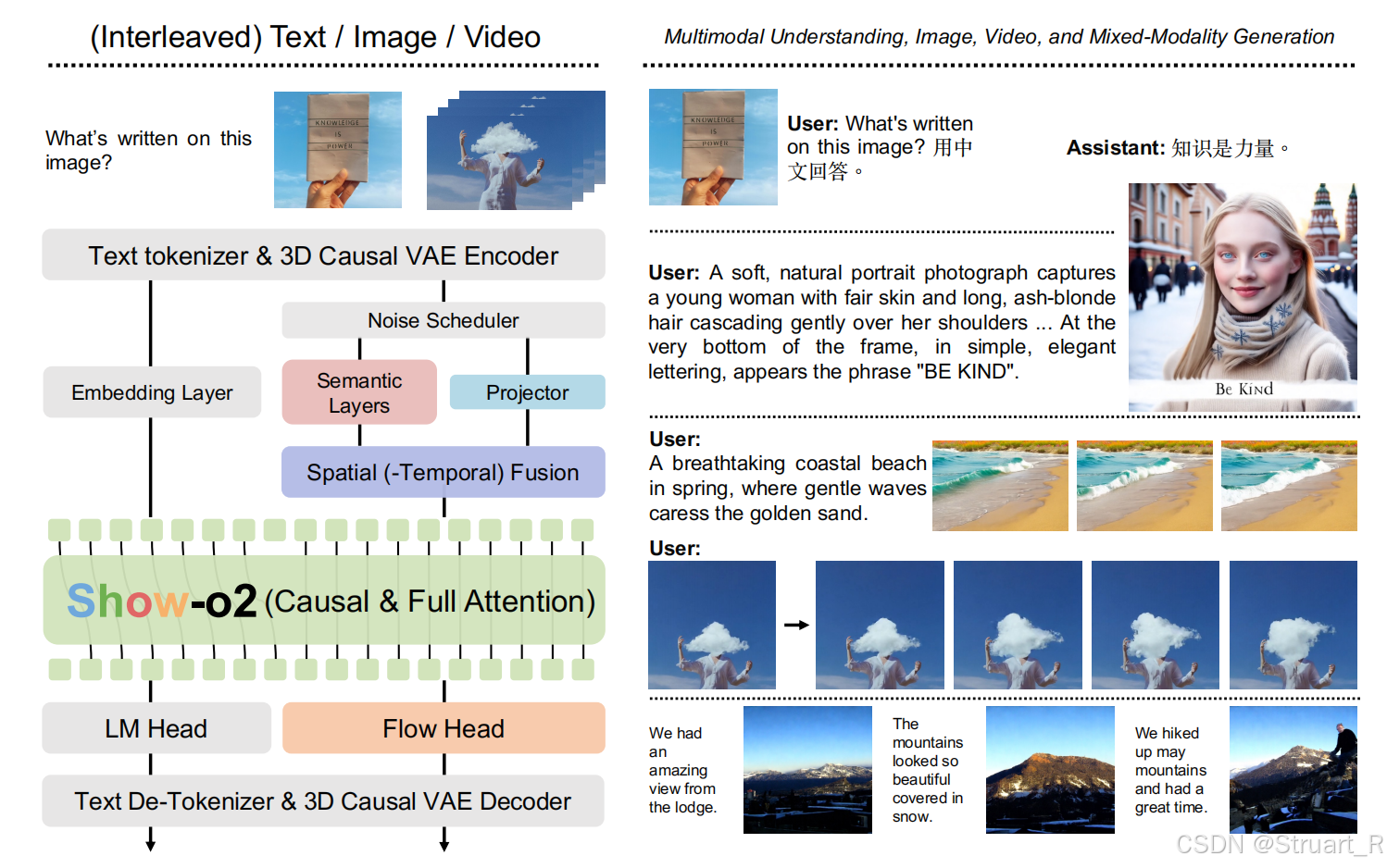
? ? ? ? Show-o2模型由文本編碼器+嵌入層、視覺編碼器(3D Causal VAE)、雙路徑融合、多模態建模器LLM、語言頭和流式頭。
? ? ? ? 文本編碼器和多模態建模器沒有具體說,基于Qwen2.5-1.5B-instruct和Qwen2.5-7B-instruct變體,并且LLM基于Show-o的Omni-Attention機制。
? ? ? ? 視覺編碼器:采用3D causal VAE編碼器,生成latents,架構與Wan2.1模型中相同,空間壓縮:432x432->27x27,支持8x空間壓縮和4x時間壓縮。
? ? ? ? 雙路徑視覺融合:潛在空間加噪,雙路徑提取深度特征,融合特征三部分。
????????潛在空間加噪:首先對潛在圖像特征空間加噪處理。為了后續流匹配生成高質量圖像、視頻提供優化路徑。(先對潛在空間添加可控噪聲,生成帶噪狀態
,之后進行語義層蒸餾和底層投影獲得特征,最后通過流匹配預測速度場
,從純噪聲
出發,沿梯度
方向,積分生成
)
? ? ? ? 雙路徑結構:語義路徑,利用基于SigLIP預先蒸餾的ViT塊,提取高層語義特征(如物體類別,場景全局信息),之后通過預蒸餾損失,確保特征對齊,公式如下,就是將semantic layers對齊到SigLIP上。
? ? ? ??????????????????
? ? ? ? 投影路徑,則是通過一個輕量投影器,留下色彩,邊界,細節等底層結構信息。
? ? ? ? 融合機制STF:拼接雙路徑特征->RMSNorm歸一化->兩層MLP融合->輸出統一表示
????????????????????????
? ? ? ? 多模態建模器:token序列格式,[BOS] {Text} [BOI / BOV] {Image / Video} [EOI / EOV] {Text} · · · [EOS]。可以同時適應任意模態組合
? ? ? ? 雙重輸出頭:語言頭,通過NTP loss,預測文本token。流式頭,通過流匹配預測速度場,并從噪聲中,沿著速度場方向,重構圖像/視頻。流式頭結構由DiT-style Transformer層+adaLN-zero時間步調制。
? ? ? ? 總損失函數為
3、訓練方法
? ? ? ? 現有的訓練策略,一般分為三類。
? ? ? ? 從頭訓練,Transfusion,無預訓練基礎,直接學習多模態對齊,并通過擴散建模實現視覺生成。但依賴大規模文本語料,語言知識容易退化。
? ? ? ? LLM或LMM微調,Show-o,EMU3,基于預訓練LLaMA或視覺語言模型CLIP初始化,并添加擴散建模或自回歸頭,實現理解與生成。計算成本高,收斂慢。
? ? ? ? 組裝專家模型,NExT-GPT,SEED-X,獨立訓練理解模型BLIP和生成模型SD,通過Adaptor拼接模塊,兼容性差,參數量冗余。
? ? ? ? 具體Show-o2訓練策略
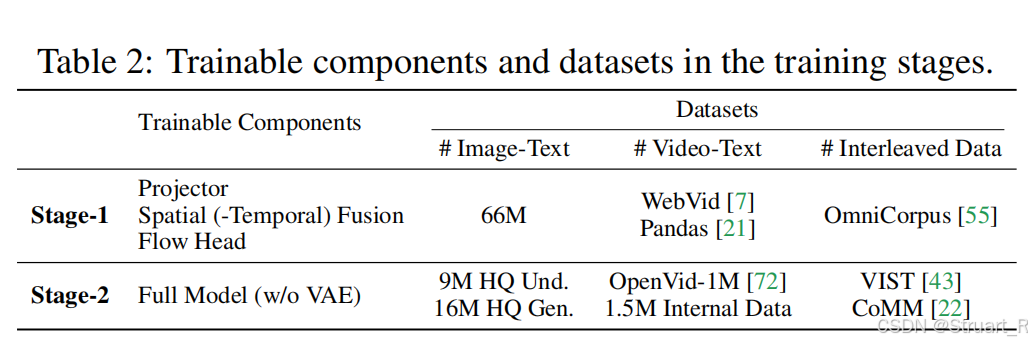
? ? ? ? Show-o2提出兩階段訓練,一階段凍結預訓練語言模型,訓練特征提取部分。二階段訓練除VAE以外的全模型。
? ? ? ? Stage1:凍結預訓練語言模型,Sematic layers通過SigLIP初始化,并且在帶噪潛變量xt上優化,僅訓練Projector,STF,Flow Head。數據采用66M圖文對(擴展到512x512,1024x1024分辨率,來自CC12M,COYO,LAION-Aesthetic-12M,AI合成數據集,并且除合成數據集外,其他均使用ShareGPT4v重標注,多模態理解指令為DenseFusion-1M和LLaVA-Onevision子集),視頻數據(Webvid,Pandas),交錯數據(OmniCorpus)。
? ? ? ? Stage2:多模態對齊,全模型訓練,聯合優化語言頭和Flow matching頭,α=1.0,平衡兩者。數據采用更高質量的文本對,視頻數據,以及交錯數據。并利用TextAtlas進行文本豐富圖像增強文本渲染。
? ? ? ? 相比于Show-o來說,Show-o采用隨機噪聲擴散,會導致高方差帶來的圖像生成隨機性,另外,Show-o三階段采樣,也會造成上千步的采樣時間。?
????????不同模型大小
? ? ? ? 訓練過程中,先訓練小模型1.5B,之后通過訓練輕量MLP變換擴展到7B大模型,并復用除LLM部分,再次經過兩階段訓練訓7B模型。
? ? ? ?
4、實驗
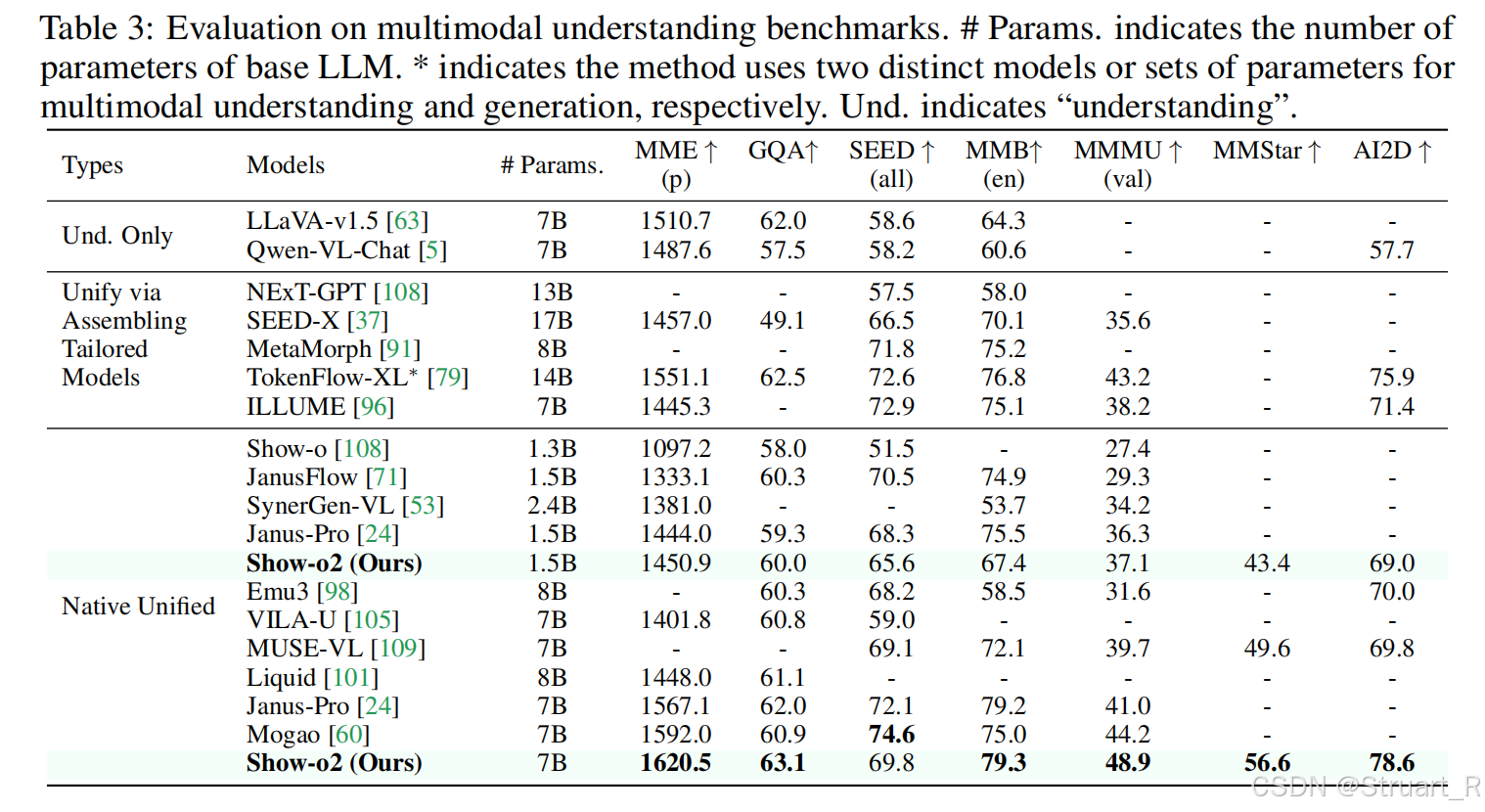
多模態理解
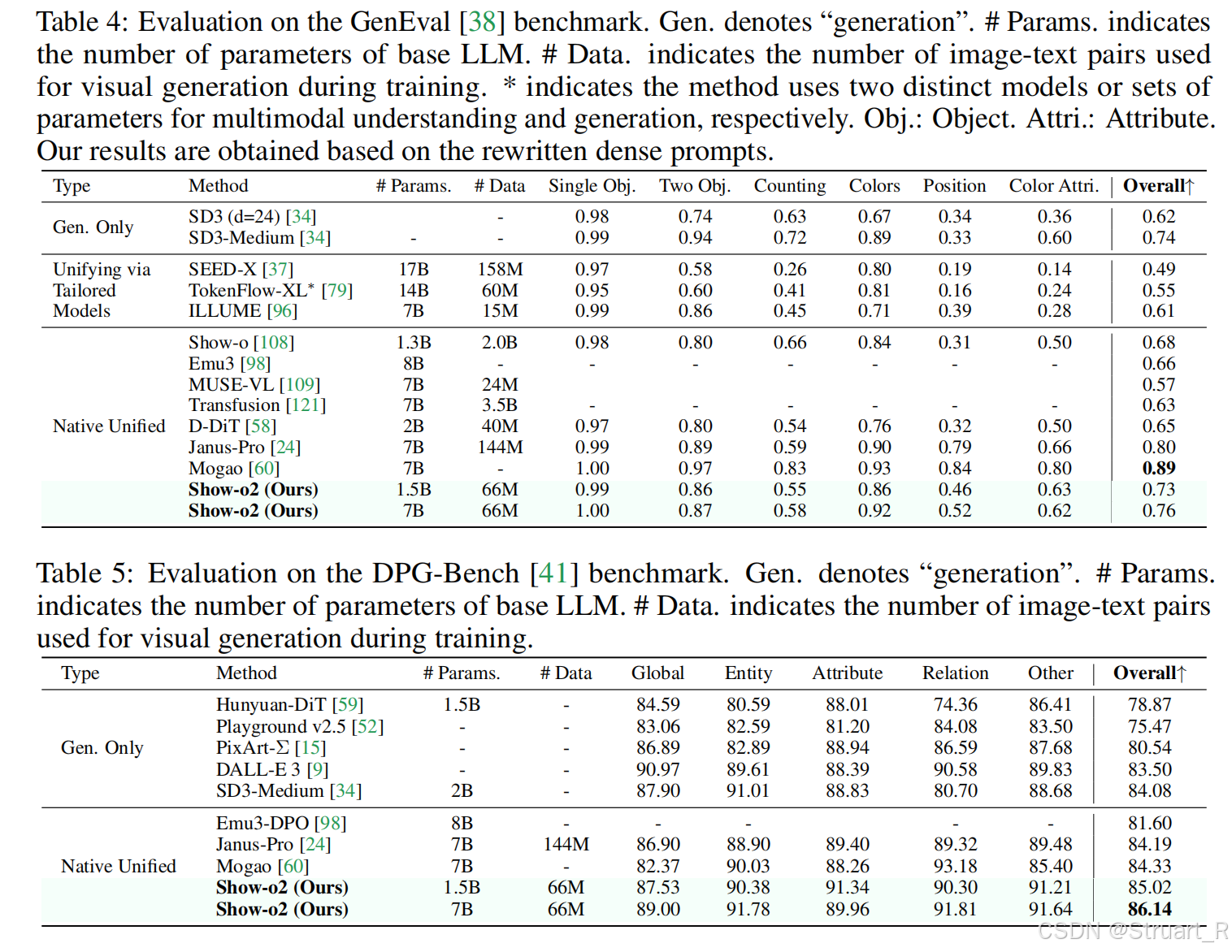
圖像生成
? ? ? ? 在GenEval和DPG-Bench上進行對比,在GenEval上甚至超過了SD3,但是最高的是Mogao。GenEval就是偏文生圖的指標,DPG-Bench類似于動態編輯,推理能力的組合。
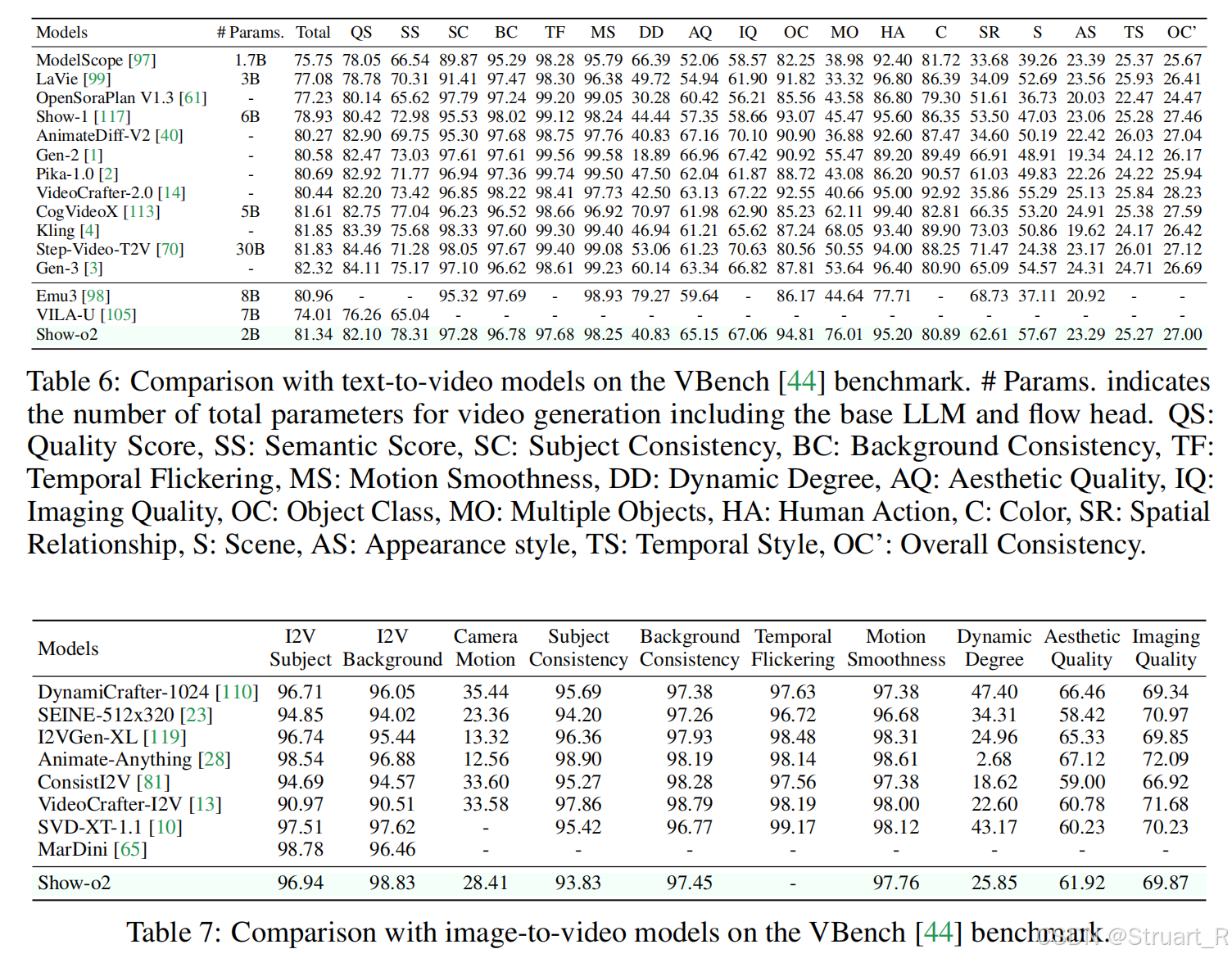
視頻生成
? ? ? ? 文生視頻和圖生視頻,由于沒有在運動上規范,所以運動上分數不高,但是描述能力很好。
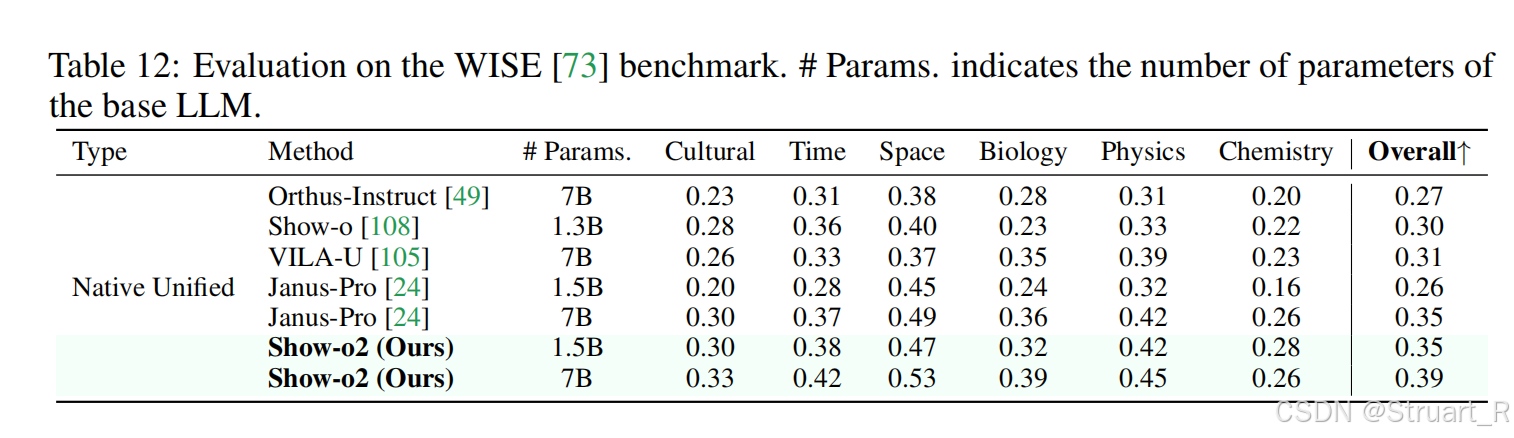
推理能力
論文參考:
https://arxiv.org/abs/2506.15564
[2408.12528] Show-o: One Single Transformer to Unify Multimodal Understanding and Generation

》免費中文翻譯 (第1章) --- Data visualization(2))

)
)














