繼上一篇的LRU算法的實現和講解,這一篇來講述LFU
最近使用頻率高的數據很大概率將會再次被使用,而最近使用頻率低的數據,將來大概率不會再使用。
做法:把使用頻率最小的數據置換出去。這種算法更多是從使用頻率的角度(但是當緩存滿時,如果最低訪問頻次的緩存數據有多個,就需要考慮哪個元素最近最久未被訪問)去考慮的。
基本算法描述
- LRU 是根據時間維度來選擇將要淘汰的元素,即刪除掉最長時間沒被訪問的元素。
- LFU 是根據頻數和時間維度來選擇將要淘汰的元素,即首選刪除訪問頻數最低的元素。如果兩個元素的訪問頻數相同,則淘汰最久沒被訪問的元素。
? ? ? ? 就是說LFU淘汰的時候會選擇兩個維度,先比較頻數,選擇訪問頻率最小的元素;如果頻率相同,則按時間維度淘汰掉最久遠的那個元素。LRU的實現是 1 個哈希表加上 1 個雙鏈表,與LRU類似,想要完成上述條件,LFU 仍需要結合哈希表和雙向鏈表這兩個結構進行操作,不過需要用 2 個哈希表再加上 N 個雙鏈表才能實現先按照頻數再按照時間兩個緯度的淘汰策略,具體 LFU 數據結構參考下圖。
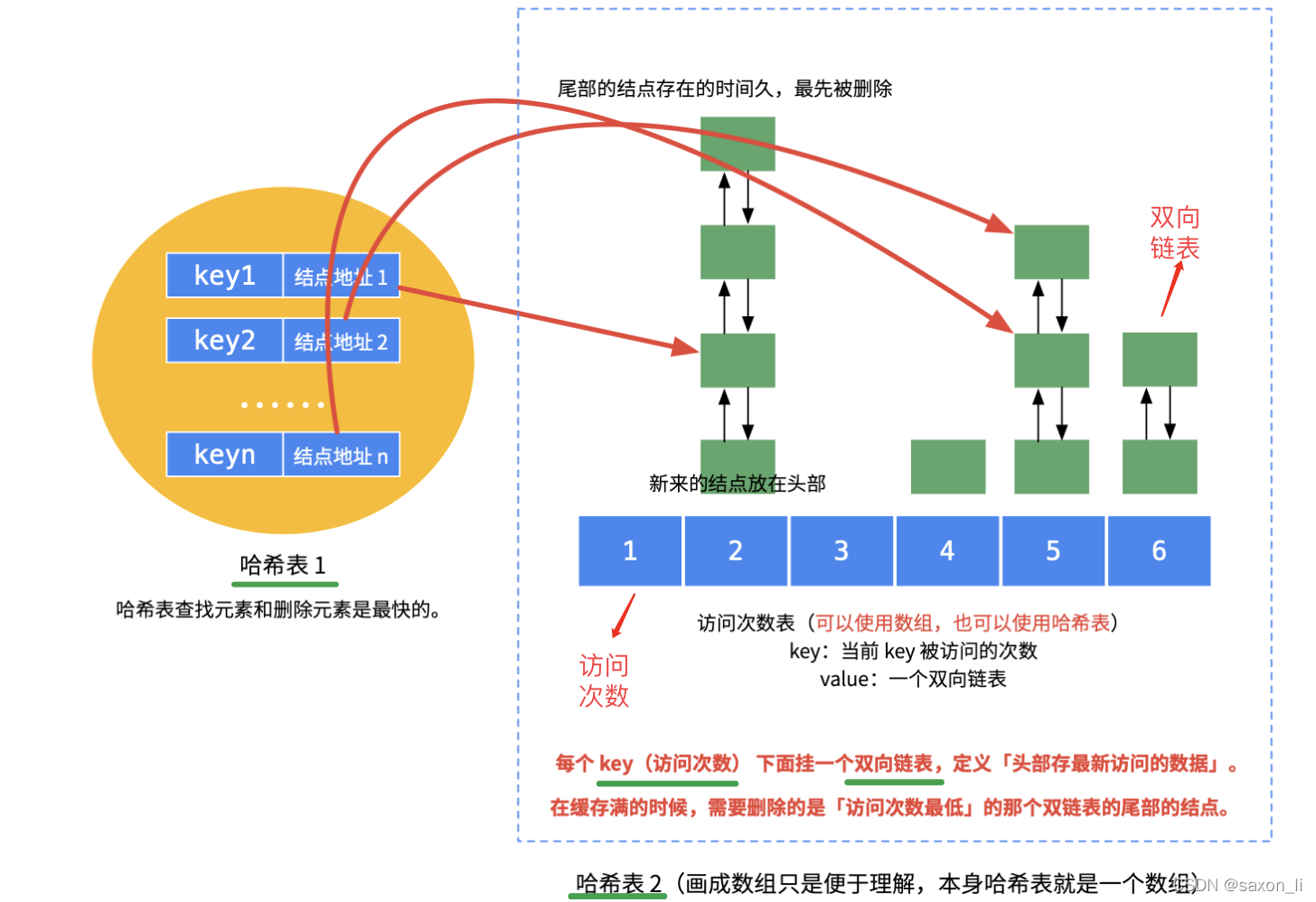
算法實現
基礎版
unordered_map<int,Node *> hashNode;unordered_map<int,FreqList *> hashFreq;- 哈希表 1:hashNode,節點哈希表,用于快速獲取數據中 key 對應的節點信息
- 哈希表 2:hashFreq,頻數雙向鏈表哈希表,為每個訪問頻數 freq 構造一個雙向鏈表 freqList,并且用哈希表聯系二者關系以快速定位
#include <unordered_map>
using namespace std;/*** LFU (Least Frequently Used) 緩存實現* 核心思想:當緩存滿時,優先淘汰訪問頻率最低的數據;* 若存在多個頻率相同的數據,則淘汰其中最久未使用的數據*/
class LFUCache {
private:// 雙向鏈表節點結構struct Node{int key; // 鍵值int value; // 存儲的值int freq; // 訪問頻率:記錄該節點被訪問的次數Node *pre; // 前驅指針:指向鏈表中的前一個節點Node *next; // 后繼指針:指向鏈表中的后一個節點// 節點構造函數Node(int key,int value,int freq){this->key = key;this->value = value;this->freq = freq;pre = nullptr; // 初始化為空指針next = nullptr; // 初始化為空指針}};// 頻率鏈表結構:每個頻率對應一個雙向鏈表,管理該頻率下的所有節點struct FreqList{int freq; // 該鏈表中所有節點的共同訪問頻率Node *L; // 頭哨兵節點:簡化鏈表操作,不存儲實際數據Node *R; // 尾哨兵節點:簡化鏈表操作,不存儲實際數據// 頻率鏈表構造函數FreqList(int freq){this->freq = freq;L = new Node(-1, -1, 1); // 創建頭哨兵R = new Node(-1, -1, 1); // 創建尾哨兵L->next = R; // 頭哨兵的后繼指向尾哨兵R->pre = L; // 尾哨兵的前驅指向頭哨兵}};int n; // 緩存的最大容量int minFreq; // 當前緩存中最小的訪問頻率,用于快速定位需要淘汰的節點/*** 節點哈希表:key -> Node** 作用:通過key快速定位對應的節點,實現O(1)時間復雜度的訪問*/unordered_map<int, Node*> hashNode;/*** 頻率鏈表哈希表:freq -> FreqList** 作用:通過頻率快速定位對應的鏈表,實現O(1)時間復雜度的鏈表操作*/unordered_map<int, FreqList*> hashFreq;/*** 從鏈表中刪除指定節點* @param node 要刪除的節點*/void deleteFromList(Node *node){Node *pre = node->pre; // 獲取前驅節點Node *next = node->next; // 獲取后繼節點pre->next = next; // 前驅節點的后繼指向后繼節點next->pre = pre; // 后繼節點的前驅指向前驅節點}/*** 將節點添加到對應頻率的鏈表尾部(尾部表示最近使用)* @param node 要添加的節點*/void append(Node *node){int freq = node->freq; // 獲取節點當前的頻率// 如果該頻率對應的鏈表不存在,則創建新的頻率鏈表if(hashFreq.find(freq) == hashFreq.end())hashFreq[freq] = new FreqList(freq);FreqList *curList = hashFreq[freq]; // 獲取當前頻率對應的鏈表// 將節點插入到尾哨兵的前面(即鏈表的尾部)Node *pre = curList->R->pre; // 尾哨兵的前驅節點Node *next = curList->R; // 尾哨兵節點pre->next = node; // 前驅節點的后繼指向當前節點node->next = next; // 當前節點的后繼指向尾哨兵next->pre = node; // 尾哨兵的前驅指向當前節點node->pre = pre; // 當前節點的前驅指向前驅節點}public:/*** LFU緩存構造函數* @param capacity 緩存的最大容量*/LFUCache(int capacity) {n = capacity; // 初始化緩存容量minFreq = 0; // 初始化最小訪問頻率為0}/*** 從緩存中獲取指定key的值* @param key 要訪問的鍵* @return key對應的value,如果key不存在則返回-1*/int get(int key) {// 緩存中存在該keyif(hashNode.find(key) != hashNode.end()){Node *node = hashNode[key]; // 通過哈希表快速定位節點// 從原頻率鏈表中刪除該節點(因為頻率即將增加)deleteFromList(node);// 訪問頻率加1node->freq++;/*** 檢查是否需要更新最小頻率:* 如果原來的最小頻率鏈表在刪除節點后變為空鏈表,* 說明當前節點是該頻率下的最后一個節點,最小頻率需要加1*/if(hashFreq[minFreq]->L->next == hashFreq[minFreq]->R) minFreq++;// 將節點添加到新頻率對應的鏈表中append(node);return node->value; // 返回key對應的value}else return -1; // 緩存中不存在該key,返回-1}/*** 向緩存中插入或更新鍵值對* @param key 要插入或更新的鍵* @param value 要插入或更新的值*/void put(int key, int value) {if(n == 0) return; // 緩存容量為0,無法存儲任何數據// 緩存中已存在該key,復用get操作更新頻率,再更新valueif(get(key) != -1)hashNode[key]->value = value;else // 緩存中不存在該key,需要插入新節點{// 緩存空間已滿,需要淘汰節點if(hashNode.size() == n){// 找到最小頻率對應的鏈表中最久未使用的節點(頭哨兵的下一個節點)Node *node = hashFreq[minFreq]->L->next;deleteFromList(node); // 從鏈表中刪除該節點hashNode.erase(node->key); // 從哈希表中刪除該節點}// 創建新節點,初始頻率為1Node *node = new Node(key, value, 1);hashNode[key] = node; // 將新節點加入哈希表minFreq = 1; // 新節點頻率為1,當前最小頻率更新為1append(node); // 將新節點添加到頻率為1的鏈表中}}
};
我們不難發現以上設計存在諸多問題:
- 頻率爆炸問題:對于長期駐留在緩存中的熱數據,頻率計數可能會無限增長,占用額外的存儲空間或導致計數溢出。
- 過時熱點數據占用緩存:一些數據可能已經不再是熱點數據,但因訪問頻率過高,難以被替換。
- 冷啟動問題:剛加入緩存的項可能因為頻率為1而很快被淘汰,即便這些項是近期訪問的熱門數據。
- 不適合短期熱點:LFU對長期熱點數據表現較好,但對短期熱點數據響應較慢,可能導致短期熱點數據無法及時緩存。
- 缺乏動態適應性:固定的LFU策略難以適應不同的應用場景或工作負載。
- 鎖的粒度大,多線程高并發訪問下鎖的同步等待時間過長。
針對上述問題,進行了以下幾點優化:
- 加上最大平均訪問次數限制
- HashLFUCache
最大平均訪問次數限制
在LFU算法之上,引入訪問次數平均值概念,當平均值大于最大平均值限制時將所有結點的訪問次數減去最大平均值限制的一半或者一個固定值。相當于熱點數據“老化”了,這樣可以避免頻次計數溢出,也可以緩解緩存污染。
template <typename Key, typename Value>
class LfuCache {
private:// 1. 緩存基礎屬性int capacity_; // 緩存最大容量(核心參數,決定何時觸發淘汰)int minFreq_; // 當前緩存中最小的訪問頻率(LFU核心,用于快速定位淘汰目標)// 2. 平均頻率控制(擴展功能,區別于標準LFU)int maxAverageNum_; // 允許的最大平均訪問頻率(防止頻率無限增長)int curAverageNum_; // 當前平均訪問頻率(總訪問次數 / 節點數)int curTotalNum_; // 所有節點的總訪問次數(用于計算平均頻率)// 3. 線程安全std::mutex mutex_; // 互斥鎖,保證多線程環境下put/get操作的原子性// 4. 核心映射表(數據結構核心)NodeMap nodeMap_; // key -> 節點指針(O(1)定位節點)std::unordered_map<int, FreqList<Key, Value>*> freqToFreqList_; // 頻率 -> 頻率鏈表(O(1)定位同頻率節點的鏈表)
};capacity_:緩存容量上限,決定何時觸發淘汰邏輯。minFreq_:LFU 的 “錨點”,直接指向最不常訪問的頻率,避免遍歷所有頻率找淘汰目標。- 兩個哈希表:
nodeMap_?解決 “找節點” 的效率問題,freqToFreqList_?解決 “找同頻率鏈表” 的效率問題,共同支撐 O (1) 操作。 - 平均頻率相關變量:解決標準 LFU 中 “頻率無限增長導致哈希表膨脹” 的問題,是該實現的核心擴展點。
1.?getInternal(訪問時更新頻率的核心邏輯)
/*** 【核心】處理緩存命中時的頻率更新(LFU核心邏輯)* 作用:將節點從原頻率鏈表遷移到新頻率鏈表,更新最小頻率和平均訪問次數*/
void getInternal(NodePtr node, Value& value) {value = node->value; // 返回節點值removeFromFreqList(node); // 從當前頻率鏈表中移除節點node->freq++; // 訪問頻率+1(核心:LFU的“頻率遞增”特性)addToFreqList(node); // 加入新頻率對應的鏈表// 若原頻率是最小頻率且鏈表已空,更新最小頻率(保證minFreq_有效性)if (node->freq - 1 == minFreq_ && freqToFreqList_[node->freq - 1]->isEmpty()) {minFreq_++;}addFreqNum(); // 更新總訪問次數和平均頻率(擴展功能)
}2.?putInternal(插入新節點的核心邏輯)
/*** 【核心】處理新節點插入(含緩存滿時的淘汰邏輯)* 作用:新增節點時,若緩存滿則淘汰最不常使用節點,否則直接插入*/
void putInternal(Key key, Value value) {if (nodeMap_.size() == capacity_) { // 緩存滿,觸發淘汰kickOut(); // 淘汰最不常使用的節點(LFU核心淘汰邏輯)}// 插入新節點(初始頻率為1)NodePtr node = std::make_shared<Node>(key, value);nodeMap_[key] = node; // 加入節點哈希表addToFreqList(node); // 加入頻率=1的鏈表addFreqNum(); // 更新總訪問次數和平均頻率minFreq_ = std::min(minFreq_, 1); // 新節點頻率為1,更新最小頻率
}3.?kickOut(淘汰節點的核心邏輯)? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
/*** 【核心】淘汰最不常使用的節點(LFU核心策略)* 邏輯:淘汰最小頻率鏈表中最久未使用的節點(鏈表頭部節點)*/
void kickOut() {// 找到最小頻率對應的鏈表中最久未使用的節點(頭節點的下一個,即鏈表第一個有效節點)NodePtr node = freqToFreqList_[minFreq_]->getFirstNode();removeFromFreqList(node); // 從頻率鏈表中移除nodeMap_.erase(node->key); // 從節點哈希表中移除decreaseFreqNum(node->freq); // 更新總訪問次數和平均頻率
}4.?handleOverMaxAverageNum(擴展功能核心)
/*** 【擴展核心】處理平均頻率超上限的情況(解決頻率無限增長問題)* 邏輯:當平均訪問頻率過高時,降低所有節點的頻率,控制頻率范圍*/
void handleOverMaxAverageNum() {if (nodeMap_.empty()) return;// 遍歷所有節點,降低頻率(核心:批量調整頻率,防止頻率無限增大)for (auto& it : nodeMap_) {NodePtr node = it.second;removeFromFreqList(node); // 從原頻率鏈表移除node->freq -= maxAverageNum_ / 2; // 頻率降低(至少保留1)if (node->freq < 1) node->freq = 1;addToFreqList(node); // 加入新頻率鏈表}updateMinFreq(); // 重新計算最小頻率
}設置最大平均訪問次數的值解決了什么問題?
- 防止某一個緩存的訪問頻次無限增加,而導致的計數溢出。
- 舊的熱點緩存,也就是該數據之前的訪問頻次很高,但是現在不再被訪問了,也能夠保證他在每次訪問緩存平均訪問次數大于最大平均訪問次數的時候減去一個固定的值,使這個過去的熱點緩存的訪問頻次逐步降到最低,然后從內存中淘汰出去
- 一定程度上是對新加入進來的緩存,也就是訪問頻次為1的數據緩存進行了保護,因為長時間沒被訪問的舊的數據不再會長期占據緩存空間,訪問頻率會逐步被降為小于1最終淘汰。
HashLfuCache
思路與HashLruCachea類似,參照上篇對應的內容
采用分片思想
template<typename Key, typename Value>
class HashLfuCache {
private:size_t capacity_; // 緩存總容量(所有分片容量之和)int sliceNum_; // 分片數量(核心參數,決定并發性能和分片大小)// 存儲所有LFU分片的容器(每個分片都是獨立的KLfuCache實例)std::vector<std::unique_ptr<KLfuCache<Key, Value>>> lfuSliceCaches_;
};

)
——鏈接預測在社交網絡分析中的應用)



》免費中文翻譯 (第1章) --- Data visualization(2))

)
)








