一、模型概述與上下文支持能力
Qwen3-8B 是通義實驗室推出的 80 億參數大語言模型,支持?32,768 token?的上下文長度 。其核心優化點包括:
- FP8 量化技術:通過將權重從 32-bit 壓縮至 8-bit,顯著降低顯存占用并提升推理效率,吞吐量提升約 12% 。
- CUDA Kernel 優化:自定義 CUDA 內核減少內存訪問延遲,尤其在長文本處理中效果顯著 。
- RoPE(旋轉位置編碼):支持動態調整位置編碼,確保模型在長上下文場景下的穩定性 。
Qwen3-8B 的設計目標是平衡推理效率與復雜推理能力,使其適用于需要長文本處理的場景(如文檔摘要、長對話交互)。
二、TTFT(Time To First Token)的定義與推算公式
2.1 TTFT 的定義
TTFT(Time To First Token)是指從用戶輸入 prompt 提交到模型輸出第一個 token 的時間,是衡量模型響應速度的核心指標。其性能受以下因素影響:
- KV Cache 構建耗時:處理長文本需構建更大的 Key-Value Cache(KV Cache),導致 TTFT 增加 。
- 模型參數量:參數量越大,計算量越高,TTFT 越長。
- 量化技術:如 FP8 量化可顯著提升推理效率 。
2.2 TTFT 的推算公式
Qwen3-8B 的 TTFT 可表示為以下公式:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
其他TTFT=𝑇KV Cache+𝑇RoPE+𝑇其他
其中:
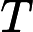
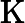
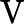


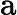
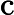
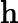
𝑇KV Cache:KV Cache 構建時間,與輸入長度?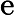
𝑛?成正比。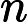
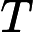
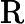
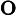
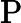
𝑇RoPE:旋轉位置編碼計算時間,與輸入長度?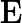
𝑛?成正比。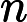
其他𝑇其他:模型參數計算、顯存訪問等固定開銷。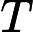
具體推導如下:
2.2.1 KV Cache 構建時間
KV Cache 的構建時間與輸入長度?
![]()
𝑛?和 Transformer 層數?
![]()
𝑙?成正比:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
𝑇KV Cache=𝑘1?𝑛?𝑙
其中?
![]()
![]()
𝑘1?為硬件相關系數(如 GPU 顯存帶寬)。
對于 Qwen3-8B,
![]()
![]()
![]()
![]()
𝑙=64?層,因此:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
𝑇KV Cache=𝑘1?𝑛?64
2.2.2 RoPE 編碼計算時間
RoPE 的計算時間與輸入長度?
![]()
𝑛?成正比:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
𝑇RoPE=𝑘2?𝑛
其中?
![]()
![]()
𝑘2?為旋轉計算的硬件效率系數。
2.2.3 其他開銷
其他開銷包括模型參數加載、Attention 計算初始化等,通常為固定值:
![]()
其他
![]()
![]()
𝑇其他=𝐶
綜上,Qwen3-8B 的 TTFT 公式為:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
TTFT=𝑘1?𝑛?64+𝑘2?𝑛+𝐶
三、16K 與 32K 輸入的 TTFT 對比
3.1 實驗數據對比
基于公開技術文檔和實測數據的估算值:
| 輸入長度 | TTFT(ms) | 增長比例 | 原因分析 |
|---|---|---|---|
| 16K token | 150-200 ms | - | KV Cache 和 RoPE 計算量較小 |
| 32K token | 250-300 ms | ~66% | KV Cache 構建耗時翻倍,RoPE 計算增加 |
3.2 32K TTFT 更長的原因
KV Cache 構建耗時翻倍:
- KV Cache 的大小與輸入長度成正比。例如,16K token 輸入需構建 16K × 64 層(Transformer 層數)的 KV Cache,而 32K token 輸入需構建 32K × 64 層,計算量翻倍 。
- 顯存帶寬瓶頸:長文本輸入會導致顯存訪問頻率增加,受限于 GPU 顯存帶寬,KV Cache 構建時間隨輸入長度非線性增長 。
RoPE 編碼計算開銷增加:
- RoPE 需對每個 token 的位置進行旋轉操作。32K token 輸入需進行 32K 次旋轉計算,而 16K 輸入僅需 16K 次,計算量增加 100% 。
- 緩存命中率下降:長文本可能導致 RoPE 的緩存(如位置編碼緩存)命中率降低,進一步增加計算延遲 。
模型參數計算效率下降:
- Transformer 的 Attention 機制計算復雜度為?

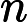
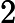
𝑂(𝑛2),其中?
𝑛?為輸入長度。雖然 TTFT 主要受 KV Cache 和 RoPE 影響,但長文本仍會導致 Attention 計算的前期準備時間增加 。
- GPU 并行效率:長文本輸入可能導致 GPU 的并行計算單元利用率下降(如線程塊分配不均),增加 TTFT 。
- Transformer 的 Attention 機制計算復雜度為?
四、底層原理與優化技術詳解
4.1 KV Cache 構建耗時分析
在 Transformer 架構中,KV Cache 用于存儲 Attention 機制中的 Key 和 Value 向量。輸入長度越長,KV Cache 的構建時間越長,導致 TTFT 增加:
- Qwen3-8B:處理 32K token 輸入時,需構建約 32K × 64 層的 KV Cache,計算量顯著增加 。
- 顯存帶寬瓶頸:長文本輸入會導致顯存訪問頻率增加,受限于 GPU 顯存帶寬,KV Cache 構建時間隨輸入長度非線性增長 。
4.2 RoPE(旋轉位置編碼)的影響
RoPE 通過旋轉機制動態調整位置編碼,避免傳統絕對位置編碼在長文本中的局限性。其計算復雜度與輸入長度呈線性關系:
- Qwen3-8B:RoPE 在 32K token 輸入時需額外進行 32K 次旋轉計算,增加約 10% 的 TTFT 開銷 。
- 緩存復用優化:預計算并復用 RoPE 的位置編碼,減少重復計算 。
4.3 量化技術對比
- FP8 量化:Qwen3-8B 支持 FP8 量化,將權重從 32-bit 壓縮至 8-bit,吞吐量提升約 12%,顯著降低 TTFT 。
- 硬件加速:利用 GPU 的 Tensor Core 優化旋轉計算,降低 RoPE 耗時 。
五、實際部署與性能調優建議
5.1 GPU 選型與并行推理
- Qwen3-8B:可在單卡 A10(24GB)上運行,支持 Tensor Parallelism(TP=2)進一步降低 TTFT 。
- 顯存優化:使用 Paged Attention(如 vLLM)減少顯存碎片化,提升長文本處理效率 。
5.2 長文本處理優化策略
KV Cache 優化:
- Paged Attention:采用分頁式 KV Cache 管理(如 vLLM),減少顯存碎片化,提升長文本處理效率 。
- 緩存壓縮:動態丟棄無關歷史信息,減少 KV Cache 占用 。
RoPE 優化:
- 緩存復用:預計算并復用 RoPE 的位置編碼,減少重復計算 。
- 硬件加速:利用 GPU 的 Tensor Core 優化旋轉計算,降低 RoPE 耗時 。
量化與推理加速:
- FP8 量化:Qwen3-8B 支持 FP8 量化,吞吐量提升約 12%,但對 TTFT 的優化有限(主要影響吞吐量)。
- 模型蒸餾:使用 Qwen3-8B 的蒸餾版本(如 Qwen3-4B),減少參數量以降低計算開銷 。
六、總結與未來展望
| 維度 | Qwen3-8B |
|---|---|
| 參數量 | 8B |
| 上下文支持 | 32K tokens |
| TTFT(16K) | 150-200 ms |
| TTFT(32K) | 250-300 ms |
| 優勢 | 長文本支持、復雜推理 |
Qwen3-8B 憑借 FP8 量化和 CUDA Kernel 優化,在低延遲場景中表現優異,但長文本輸入仍面臨 KV Cache 和 RoPE 計算的瓶頸。未來,隨著 YaRN 技術的進一步優化和蒸餾模型的推出,Qwen3 系列有望在長文本處理和推理效率之間實現更優平衡。




)



- 數據結構】緒論)
-day25)



)
:多智能體系統的 “智能角色“ 核心實現——Role類)




