進入尾聲,一個完整的模型訓練 ,點亮的第一個led
#自己注釋版
import torch
import torchvision.datasets
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
# from model import *
from torch.utils.data import DataLoader#定義訓練的設備
device= torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#準備數據集
train_data = torchvision.datasets.CIFAR10(root='./data_CIF',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root='./data_CIF',train=False,transform=torchvision.transforms.ToTensor(),download=True)#獲得數據集長度
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f"訓練數據集的長度為 : {train_data_size}")
print(f"測試數據集的長度為 : {test_data_size}")#利用 Dataloader 來加載數據集
train_loader =DataLoader(dataset=train_data,batch_size=64)
test_loader =DataLoader(dataset=test_data,batch_size=64)#搭建神經網絡
class Tudui(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10),)def forward(self,x):x = self.model(x)return x#創建網絡模型
tudui = Tudui()
#GPU
tudui.to(device)#損失函數
loss_fn = nn.CrossEntropyLoss()
#GPU
loss_fn.to(device)#優化器
# learning_rate = 0.001
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate)#設置訓練網絡的一些參數
#記錄訓練的次數
total_train_step = 0
#記錄測試的次數
total_test_step = 0
#訓練的輪數
epoch = 10#添加tensorboard
writer = SummaryWriter("./logs_train")start_time = time.time()
for i in range(epoch):print(f"---------第{i+1}輪訓練開始---------")#訓練步驟開始tudui.train() #當網絡中有特定層的時候有用for data in train_loader:imgs, targets = data#GPUimgs.to(device)targets.to(device)output = tudui(imgs)loss = loss_fn(output,targets) #算出誤差# 優化器優化模型#梯度置零optimizer.zero_grad()#反向傳播loss.backward()#更新參數optimizer.step()#展示輸出total_train_step += 1if total_train_step % 100 == 0:end_time = time.time()print(f"訓練次數:{total_train_step} 花費時間:{end_time - start_time}")print(f"訓練次數:{total_train_step},Loss:{loss.item()}")writer.add_scalar("train_loss",loss.item(),total_train_step)#測試步驟開始tudui.eval() #當網絡中有特定層的時候有用total_test_loss = 0#整體的正確個數total_accuracy = 0#取消梯度with torch.no_grad():for data in test_loader:imgs, targets = data#GPUimgs.to(device)targets.to(device)output = tudui(imgs)loss = loss_fn(output,targets) #計算出誤差#構建一些指標total_accuracy += (output.argmax(1) == targets).sum().item() #統計每一批預測的結果和真實結果相等的個數total_test_loss += loss.item()print(f"整體測試集上的loss:{total_test_loss}")print(f"整體測試集上的正確率:{total_accuracy/test_data_size}")print(f"整體測試集上的正確數:{total_accuracy}")#寫入tensorboardwriter.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step += 1#保存模型torch.save(tudui.state_dict(),f"./tudui{i}.pth")print("模型已保存")writer.close()
#ai注釋版
import torch
import torchvision.datasets
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
from torch.utils.data import DataLoader# ----------------- 一、設備 -----------------
# 判斷是否有可用的GPU,沒有則用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# ----------------- 二、準備數據 -----------------
# 下載CIFAR10訓練集
train_data = torchvision.datasets.CIFAR10(root='./data_CIF', train=True, transform=torchvision.transforms.ToTensor(), download=True)
# 下載CIFAR10測試集
test_data = torchvision.datasets.CIFAR10(root='./data_CIF', train=False, transform=torchvision.transforms.ToTensor(), download=True)# 打印訓練集和測試集的長度
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f"訓練數據集的長度為 : {train_data_size}")
print(f"測試數據集的長度為 : {test_data_size}")# 使用Dataloader封裝數據,方便批量加載
train_loader = DataLoader(dataset=train_data, batch_size=64)
test_loader = DataLoader(dataset=test_data, batch_size=64)# ----------------- 三、搭建神經網絡 -----------------
class Tudui(nn.Module):def __init__(self):super().__init__()# 搭建一個簡單的卷積神經網絡self.model = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), # [b,3,32,32] -> [b,32,32,32]nn.MaxPool2d(2), # [b,32,32,32] -> [b,32,16,16]nn.Conv2d(32, 32, 5, 1, 2), # -> [b,32,16,16]nn.MaxPool2d(2), # -> [b,32,8,8]nn.Conv2d(32, 64, 5, 1, 2), # -> [b,64,8,8]nn.MaxPool2d(2), # -> [b,64,4,4]nn.Flatten(), # 拉平成一維 [b,64*4*4]nn.Linear(64*4*4, 64),nn.Linear(64, 10) # CIFAR10 一共10類)def forward(self, x):return self.model(x)# 創建模型對象
tudui = Tudui()
tudui.to(device) # 移動到GPU/CPU# ----------------- 四、定義損失函數和優化器 -----------------
# 交叉熵損失函數(多分類標準選擇)
loss_fn = nn.CrossEntropyLoss().to(device)# SGD隨機梯度下降優化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)# ----------------- 五、訓練準備 -----------------
total_train_step = 0 # 總訓練次數
total_test_step = 0 # 總測試次數
epoch = 10 # 訓練輪數# TensorBoard日志工具
writer = SummaryWriter("./logs_train")start_time = time.time() # 記錄起始時間# ----------------- 六、開始訓練 -----------------
for i in range(epoch):print(f"---------第{i+1}輪訓練開始---------")# 訓練模式(啟用BN、Dropout等)tudui.train()for data in train_loader:imgs, targets = dataimgs, targets = imgs.to(device), targets.to(device)# 前向傳播output = tudui(imgs)# 計算損失loss = loss_fn(output, targets)# 優化器梯度清零optimizer.zero_grad()# 反向傳播,自動求導loss.backward()# 更新參數optimizer.step()total_train_step += 1# 每100次打印一次訓練lossif total_train_step % 100 == 0:end_time = time.time()print(f"訓練次數:{total_train_step} 花費時間:{end_time - start_time}")print(f"訓練次數:{total_train_step}, Loss:{loss.item()}")# 寫入TensorBoardwriter.add_scalar("train_loss", loss.item(), total_train_step)# ----------------- 七、測試步驟 -----------------tudui.eval() # 切換到測試模式(停用BN、Dropout)total_test_loss = 0total_accuracy = 0# 不計算梯度,節省顯存,加快推理with torch.no_grad():for data in test_loader:imgs, targets = dataimgs, targets = imgs.to(device), targets.to(device)output = tudui(imgs)loss = loss_fn(output, targets)total_test_loss += loss.item()# 預測正確個數統計total_accuracy += (output.argmax(1) == targets).sum().item()print(f"整體測試集上的Loss: {total_test_loss}")print(f"整體測試集上的正確率: {total_accuracy / test_data_size}")print(f"整體測試集上的正確數: {total_accuracy}")# 寫入TensorBoard(測試loss和準確率)writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)total_test_step += 1# ----------------- 八、保存模型 -----------------torch.save(tudui.state_dict(), f"./tudui{i}.pth")print("模型已保存")# ----------------- 九、關閉TensorBoard -----------------
writer.close()
?結果圖
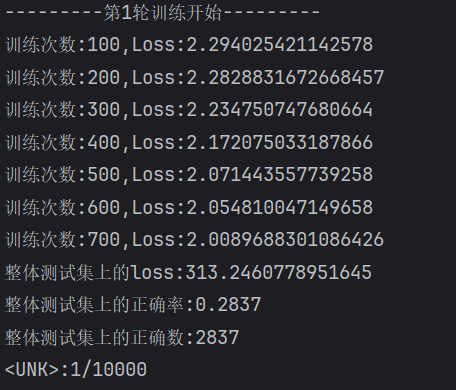
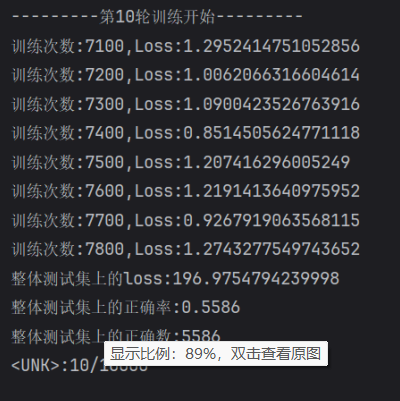
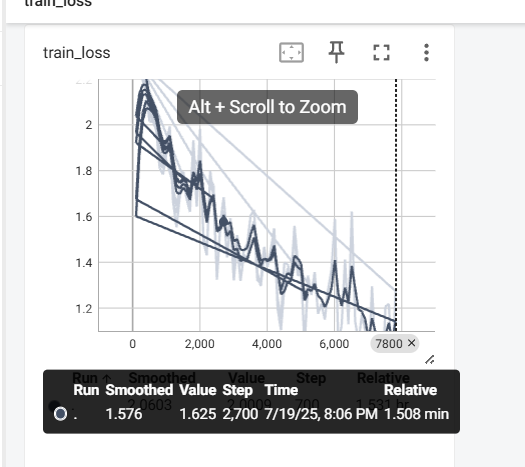
?忘記清除歷史數據了
?
?完整的模型驗證套路
import torch
import torchvision.transforms
from PIL import Image
from torch import nnimage_path = "./images/微信截圖_20250719220956.png"
image = Image.open(image_path).convert('RGB')
print(type(image))transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image = transform(image)
print(type(image))#搭建神經網絡
class Tudui(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10),)def forward(self,x):x = self.model(x)return xmodel = Tudui()
model.load_state_dict(torch.load("tudui9.pth"))
image = torch.reshape(image, (1,3,32,32))
model.eval()
with torch.no_grad():output = model(image)
print(output)
print(output.argmax(1))
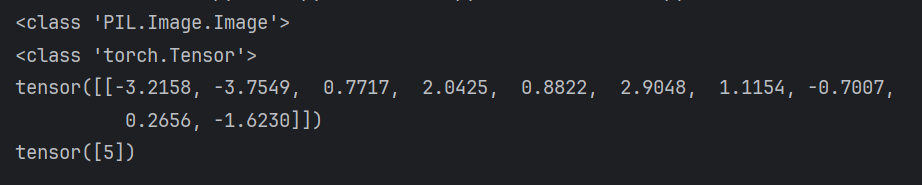
5確實是狗,驗證成功?



)
:多智能體系統的 “智能角色“ 核心實現——Role類)





詳解及案例)








