如何快速批量地獲取海量公共資源數據決定了科研的效率。Python網絡爬蟲是快速批量獲取網絡數據的重要手段,它按照發送請求、獲得頁面、解析頁面、下載內容、儲存內容等流程?
一:Python軟件的安裝及入門
1 Python軟件安裝及入門
1)Anaconda軟件安裝
2)Python庫的安裝與基本語法
3)Python的字符操作與正則表達式
4)Python的數據清洗與存儲
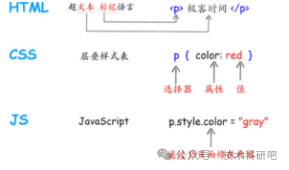
5)HTML和XML基礎

二:Python爬蟲基礎
2 Python爬蟲基礎
1)爬蟲的工作流程
2)發送請求及獲得頁面
Requests庫的使用
獲取代理、設置代理ip池及反爬蟲
3)解析頁面技術:
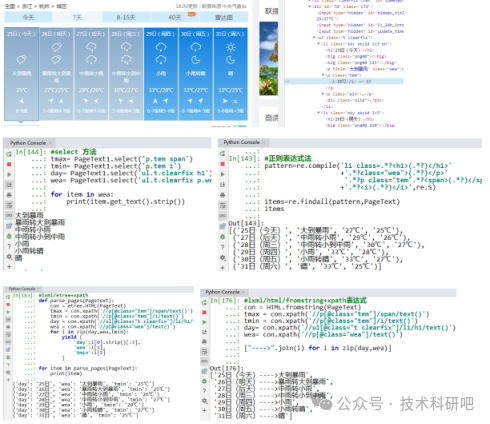
正則表達式使用
BeautifulSoup庫的使用
CSS選擇器使用
Xpath、lxml、entree語法講解
PyQuery庫使用
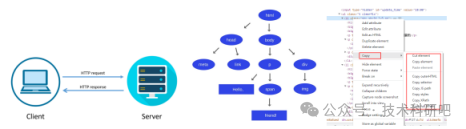
三:Python爬蟲全流程
3 Python爬蟲全流程
1)抓取的數據形式:文本、圖片、鏈接
2)保存和清洗獲取的數據
3)如何使用多線程提高爬蟲的效率
4)案例:使用五種不同解析技術爬取經濟、天氣、土壤、品種大數據

四:Python爬蟲模擬器
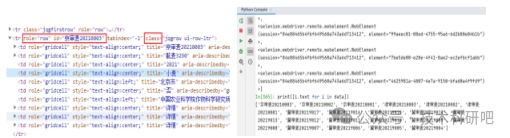
4 模擬瀏覽器Selenium使用
1)Selenium庫
2)Selenium定位元素(id/name/class/tag/text/xpath/css定位)
3)Selenium操作網頁(點擊、保存、刷新等)
4)Selenium顯式等待和隱式等待
5)案例:使用Selenium爬取農業大數據
五:Python 爬取異步加載網頁及數據集網站
5 Python 爬取異步加載網頁及數據集網站
1)Ajax請求和JS渲染
2)json解析、XHR
3)案例:使用Ajax爬取和下載動態圖片庫
4)案例:使用json解析爬取數據類網站
5)案例:使用一些特定庫爬取大型數據集網
6)案例:如何爬取pdf中的表格數據



)





(筆記)(面試考試必備知識點))









——引用類型、內聯inline和nullptr)