前言
本系列文章承接C語言的學習,需要有C語言的基礎才能學會哦~
第3篇主要講的是有關于C++的引用類型、內聯inline和nullptr。
C++才起步,都很簡單呢!
目錄
前言
引用類型
基本語法
特性
應用
const引用
基本語法
引用與指針的關系
內聯inline
nullptr
引用類型
即對同一塊連續存儲空間,多取一個標識符(別名),語法上不開辟空間(但是匯編底層也是用指針實現的)
基本語法
int a = 0;
int& b = a;如上,引用類型的定義方式為:類型& 引用別名 = 引用對象(“類型”,要與引用對象相同)。
這里表示引用b為a的別名。
引用類型變量同原變量指向同一空間,即a,b都指向同一塊空間。
int a = 0;
int& b = a;
int& c = a;
//也可以給別名取別名
int& d = c;
//運行代碼,四次輸出的地址都相同,可知引用類型與原變量a指向同一個地址
cout << &a << endl;
cout << &b << endl;
cout << &c << endl;
cout << &d << endl;而且,可以給別名起別名(如上代碼)。
一個變量可以有多個別名。
特性
①引用在定義時必須初始化。
②一個變量可以有多個別名。
③引用不可以再改變指向。
應用
引用傳參和引用做返回值的時候減少拷貝,從而提高效率。而且改變引用類型對象同時會改變被引用對象。
struct A
{int arr[1000];//占用空間大
};
//不使用引用傳參和指針傳參
int Func(A aa)
{//此處需要拷貝一個占用較大的A類型,效率低return aa.arr[0];
}
int& Func2(A& aa)
{//此處返回值和傳參都無需拷貝return aa.arr[0];//數組首元素
}
//并且,若修改返回的值,數組的首元素同時也會被修改。
int main()
{struct A aa;for (int i = 0; i < 1000; i++){aa.arr[i] = i;}//首元素為0,輸出為1cout << ++Func2(aa) << endl;return 0;
}首先,將返回值傳回時,還會開辟一個臨時對象存儲返回值。這里使用了引用作返回值。
然后,將引用類型作為臨時對象返回,無需再進行拷貝,無需開辟空間,因為引用是被引用對象的別名,可以認為是同一個變量。
而且可以通過修改返回值,達到修改被引用對象的作用
調用Func2,可以Func2(aa)++,改變返回值,即可修改原數組的首元素
調用Func,Func(aa)++會報錯,因為返回的是個int類型數據,他不是一個左操作數。
注意,不可以出現野引用現象(類似野指針)!!
const引用
const引用,用于引用const對象,也可以引用普通對象。(const對象,不可被賦值,必須初始化)
基本語法
const int a = 0;
const int& b = a;引用const對象,要使用const引用。否則·······
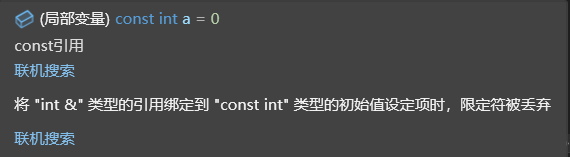
這是一個關于訪問權限的問題(指針和引用才有)。
訪問權限演示
//①
const int a = 0;
//!!錯誤演示!!
int &b = a;//int&引用指向的對象是可以修改的,這里放大了訪問權限
//!!正確演示!!
const int& ra = a;//②
int c = 10;
const int&rc = c;//該引用為訪問權限為const,縮小了權限,是允許的
//因此↓
c++;//c可以被修改
rc++;//不可以通過rc修改c//③
double d = 12.34;
const int& rd = d;//d先要進行類型轉換轉為int,中間產生臨時const對象,傳給rd時要求rd也是const引用
void func(const int& rx)
{int ret = rx;return ret;
}
int e = 10;
const int& re = e * 10;//e * 10的中間結果為臨時const對象,同上處理
func(e);//e的權限縮小為const
func(e * 3);//e * 3為臨時const對象,函數傳參要為const引用
//綜上,類型轉換、中間值、傳參等情況可能會出現訪問權限的問題?C++在類型轉換或者多次運算時,中間結果也為const對象。
引用與指針的關系
①指針和引用相輔相成,各有特點,不可替代。
②在語法上,引用不開辟空間存儲,指針變量要開辟空間存儲。
③引用必須初始化,指針可以不初始化(只是建議要初始化)。
④引用可以直接訪問對象,指針還需要解引用。
⑤在sizeof中,表達含義不同,引用,則為所引用的類型的大小;指針,則是指向地址空間的字節個數。
⑥指針容易出現空指針和野指針,引用很少會出現野引用,引用使用起來更安全。
⑦因為引用在初始化之后就不可以再賦值,因此不可以用在鏈表等數據結構中。
內聯inline
inline修飾的函數,叫作內聯函數。C++編譯器會在調用的地方直接展開內斂函數。它設計的目的就是要平替C語言的宏,避免宏的坑。
注:define宏函數的使用要點
①宏函數最后,不可加分號#define ADD(x, y) ((x)+(y)); cout << ADD(1,2) << endl;//會報錯,展開后多了個分號②宏函數需要加內部的括號
③宏函數需要加外部的括號
都是為了避免宏函數展開時,因運算符優先級的問題,導致運算順序沒有滿足實際需要,從而發生錯誤。
宏函數的好處:函數展開,不需要開辟棧幀,但是實現復雜,容易出錯,展開后代碼量大,不可以調試。
內聯既保留了不用開辟棧幀的優點,而且沒有宏的坑。
在vs編譯器的debug版本下,內聯默認不展開,inline修飾會忽略,這是為了能夠展開調試(展開了就和宏一樣無法調試了)。可以設置修改為不分內聯函數展開,即只展開短小函數,遞歸函數等復雜函數不展開。
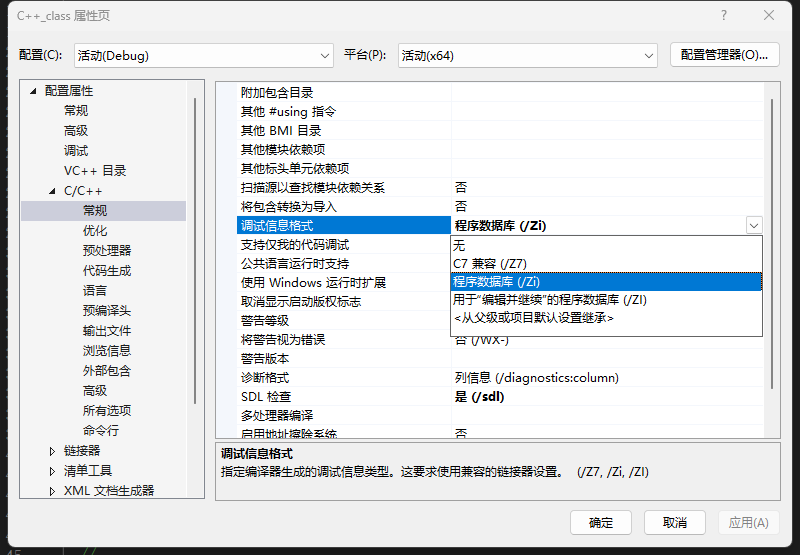
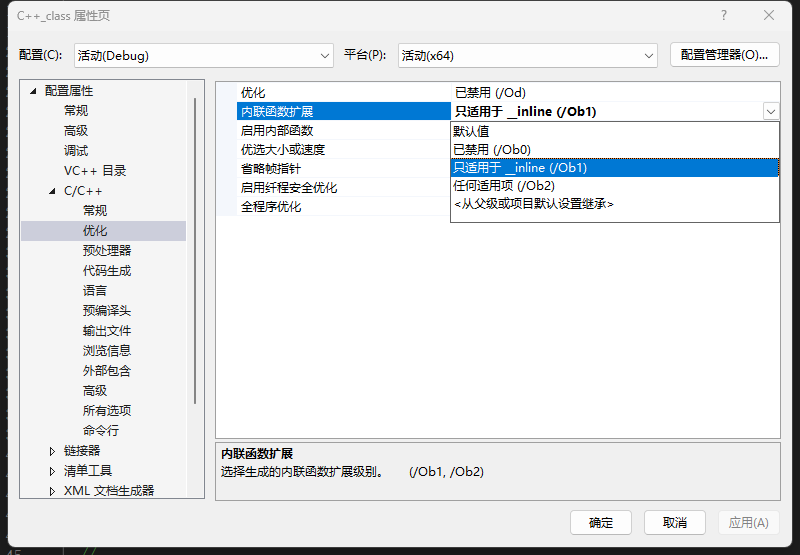
如圖,可設置為簡單inline函數展開。
究竟要多復雜的函數才會不展開呢?這取決于編譯器自身,不同的編譯器在這一點上就不同。在匯編層,不展開的內聯函數會有call指令出現。
假設Add函數在匯編層內有100條指令,在工程中調用了10000次
若不展開,匯編層一共只有10000條call指令;
若展開,匯編層一共有100 * 10000條指令。
因此,若展開復雜函數,會讓代碼量劇增,會導致指令占用內存變多。
且內聯函數不建議聲明和定義分離在兩個不同的文件上,可能會出現鏈接錯誤。因為內聯函數沒有地址。
nullptr
NULL在C++中為int類型的0,在C語言中為空指針,即void*類型。但在C++中void*不可以再轉類型,這就導致無法實現泛式函數。
nullptr為特殊關鍵字,可以轉換為任意類型的指針,在C++中要用nullptr來定義空指針。
?~~本文完結!!感謝觀看!!歡迎來我博客做客~~??





)





 視頻教程 - 用戶登錄實現)


: Word 基本操作)




