python網絡爬蟲小項目(爬取評論)超級簡單
學習python網絡爬蟲的完整路徑:
(第一章)
python網絡爬蟲(第一章/共三章:網絡爬蟲庫、robots.txt規則(防止犯法)、查看獲取網頁源代碼)-CSDN博客![]() https://blog.csdn.net/2302_78022640/article/details/149428719?sharetype=blogdetail&sharerId=149428719&sharerefer=PC&sharesource=2302_78022640&spm=1011.2480.3001.8118(第二章)
https://blog.csdn.net/2302_78022640/article/details/149428719?sharetype=blogdetail&sharerId=149428719&sharerefer=PC&sharesource=2302_78022640&spm=1011.2480.3001.8118(第二章)
python網絡爬蟲(第二章/共三章:安裝瀏覽器驅動,驅動瀏覽器加載網頁、批量下載資源)-CSDN博客![]() https://blog.csdn.net/2302_78022640/article/details/149431071?sharetype=blogdetail&sharerId=149431071&sharerefer=PC&sharesource=2302_78022640&spm=1011.2480.3001.8118
https://blog.csdn.net/2302_78022640/article/details/149431071?sharetype=blogdetail&sharerId=149431071&sharerefer=PC&sharesource=2302_78022640&spm=1011.2480.3001.8118
(第三章)
python網絡爬蟲(第三章/共三章:驅動瀏覽器窗口界面,網頁元素定位,模擬用戶交互(輸入操作、點擊操作、文件上傳),瀏覽器窗口切換,循環爬取存儲)-CSDN博客![]() https://blog.csdn.net/2302_78022640/article/details/149453182?spm=1011.2124.3001.6209(額外加一個小項目)
https://blog.csdn.net/2302_78022640/article/details/149453182?spm=1011.2124.3001.6209(額外加一個小項目)
即此篇文章
爬取商品好評
完整代碼
代碼如下:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
import time# 定義獲取頁面內容的函數
def get_content(driver):# 等待頁面加載完成,可以考慮用 WebDriverWait 來代替 time.sleeptime.sleep(3)# 以追加模式打開文件 '好評.txt',準備寫入內容file = open('好評.txt', 'a', encoding='utf-8')# 找到所有 class 為 'body-content' 的元素,這些元素包含評論的正文內容contents = driver.find_elements(By.CLASS_NAME, 'body-content')# 遍歷所有找到的評論內容for content in contents:# 給予寫入文件內容的時間time.sleep(3)# 將評論文本寫入文件file.write(content.text)file.write('\n')# 寫入完成后關閉文件file.close()# 配置 Edge 瀏覽器選項
edge_options = Options()
# 設置 Edge 瀏覽器的二進制路徑
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
# 初始化 Edge 瀏覽器驅動
driver = webdriver.Edge(options=edge_options)# 打開指定的 URL 網頁
driver.get("https://review.suning.com/cluster_cmmdty_review/cluster-38249278-000000012389328846-0000000000-1-good.htm?originalCmmdtyType=general&safp=d488778a.10004.loverRight.166")# 調用 get_content 函數獲取當前頁面的評論內容
get_content(driver)# 獲取“下一頁”按鈕
next_rv_maidian = driver.find_element(By.CSS_SELECTOR, '.next.rv-maidian')# 使用 while 循環來點擊“下一頁”按鈕并繼續抓取頁面評論
while next_rv_maidian != []:# 獲取“下一頁”按鈕元素next_rv_maidian = driver.find_element(By.CSS_SELECTOR, '.next.rv-maidian')# 點擊“下一頁”按鈕next_rv_maidian.click()# 獲取當前頁的評論內容get_content(driver)
如何尋找頁面元素:
網頁右鍵檢查,
點擊左上角按鍵:
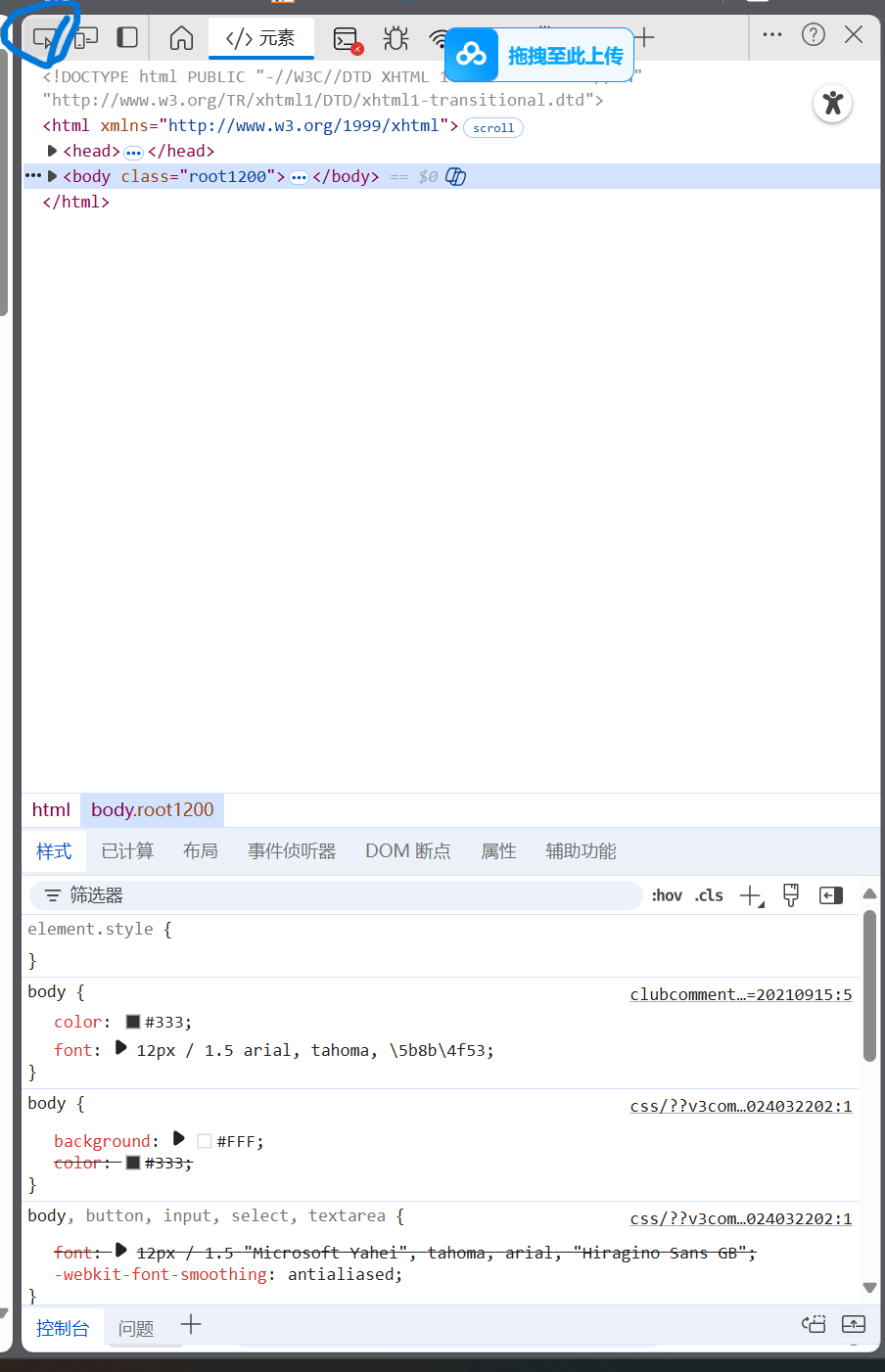
點擊左方要爬取的內容:
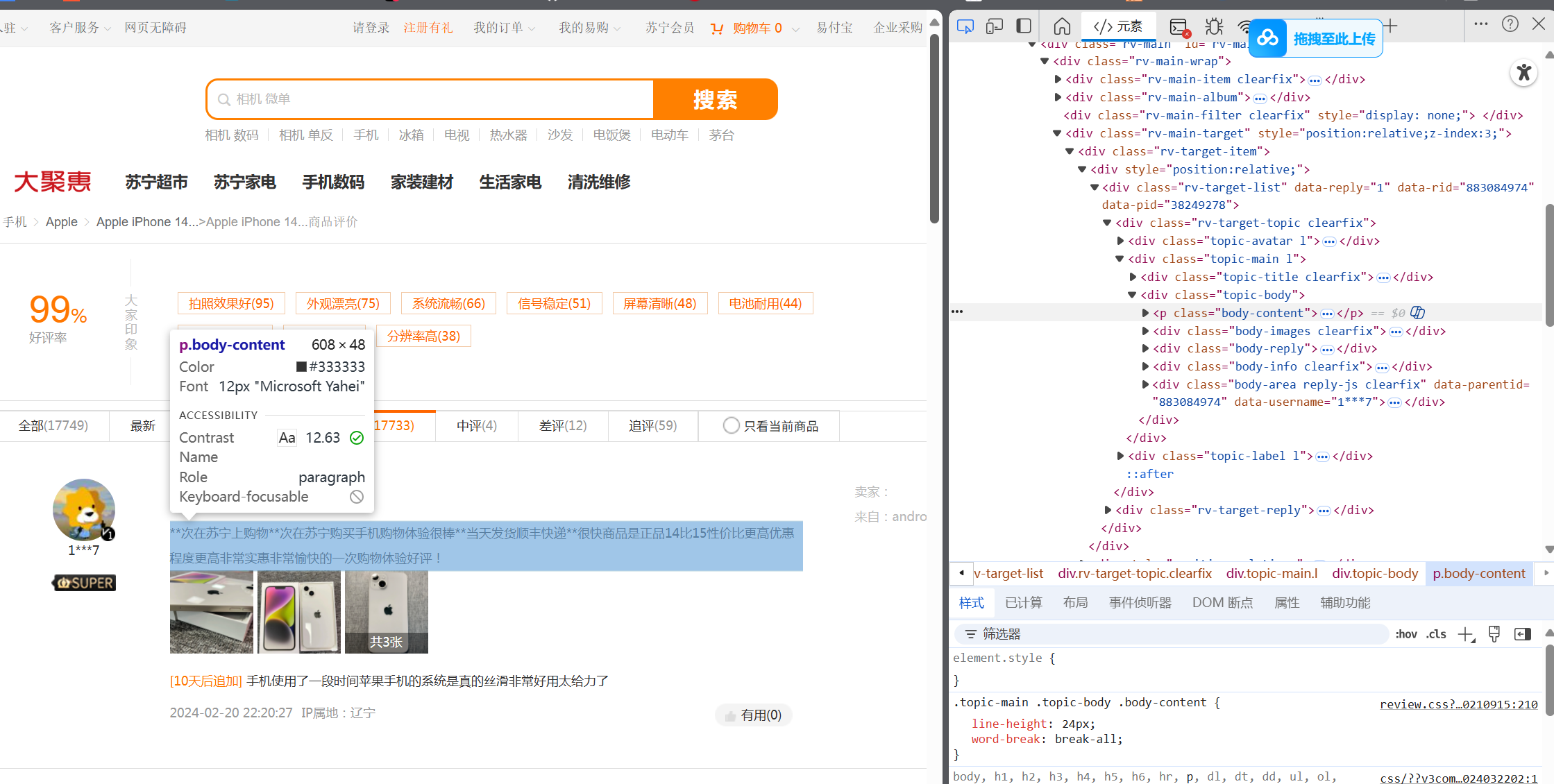
觀察到右邊:class="body-content"
此行代碼即可捕獲相應內容:
contents = driver.find_elements(By.CLASS_NAME, 'body-content')![]()





:vlan/DHCP/Web/HTTP/動態PAT/靜態NAT)




如何在工廠MOM功能設計和系統落地)



Finite State Machines 更新中...)
)



