點擊藍字

關注我們
AI TIME歡迎每一位AI愛好者的加入!
01
Iterative Distillation for Reward-Guided Fine-Tuning of Diffusion Models in Biomolecular Design
本文提出了一種用于生物分子設計中獎勵引導生成的擴散模型微調框架。擴散模型在建模復雜、高維數據分布方面表現出色,但在實際應用中,僅生成高保真度的樣本是不夠的,還需要針對可能不可微的獎勵函數進行優化,例如基于物理的模擬或基于科學知識的獎勵。盡管已有研究探索使用強化學習(RL)方法對擴散模型進行微調,但這些方法通常存在不穩定性、采樣效率低和模式坍塌等問題。本文提出的基于迭代蒸餾的微調框架能夠使擴散模型針對任意獎勵函數進行優化。該方法將問題視為策略蒸餾:在roll-in階段收集離線數據,在roll-out階段模擬基于獎勵的軟最優策略,并通過最小化模擬軟最優策略與當前模型策略之間的KL散度來更新模型。與現有的基于RL的方法相比,本文的離線策略公式和KL散度最小化增強了訓練的穩定性和采樣效率。實驗結果表明,該方法在蛋白質、小分子和調控DNA設計等多樣化任務中均表現出優異的獎勵優化效果。
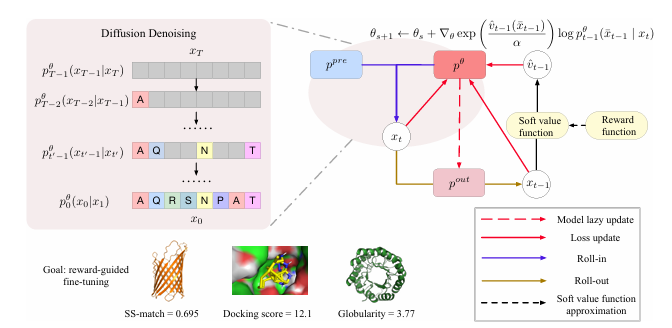

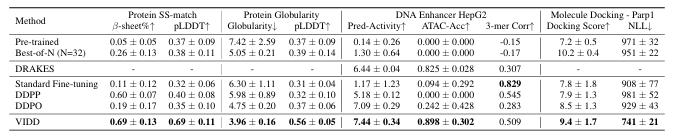
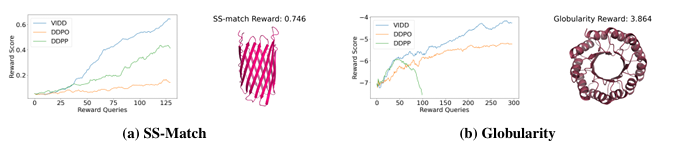
文章鏈接:
https://arxiv.org/pdf/2507.00445
02
Enhancing Reasoning Capabilities in SLMs with Reward Guided Dataset Distillation
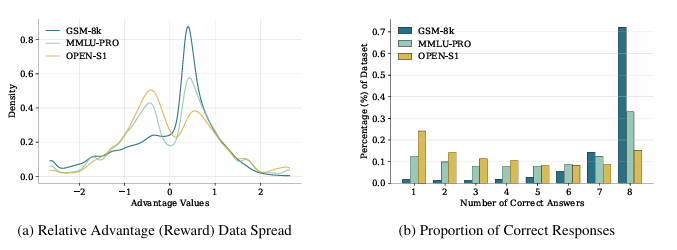
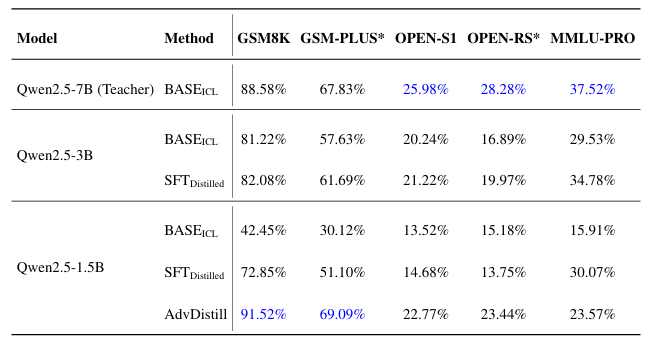
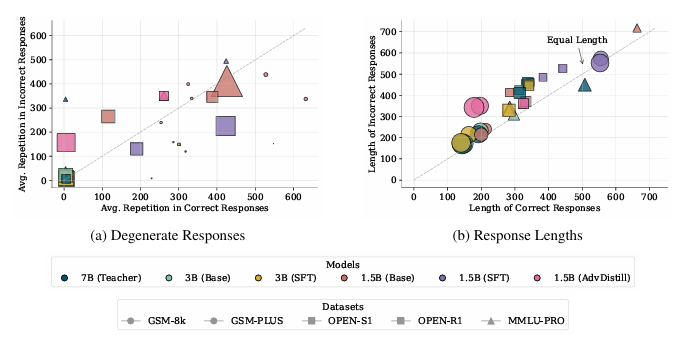
本文提出了一種獎勵引導的數據集蒸餾框架AdvDistill,用于提升小型語言模型(SLMs)的推理能力。現有的知識蒸餾技術雖然能夠將大型語言模型(LLMs)的能力傳遞給更小的學生模型,但通常僅圍繞學生模型模仿教師模型的分布內響應,限制了其泛化能力,尤其是在推理任務中。AdvDistill框架利用教師模型對每個提示生成的多個響應,并基于規則驗證器分配獎勵。這些變化的、正態分布的獎勵在訓練學生模型時作為權重。研究方法及其后續的行為分析表明,學生模型在數學和復雜推理任務上的表現顯著提升,展示了在數據集蒸餾過程中引入獎勵機制的有效性和益處。
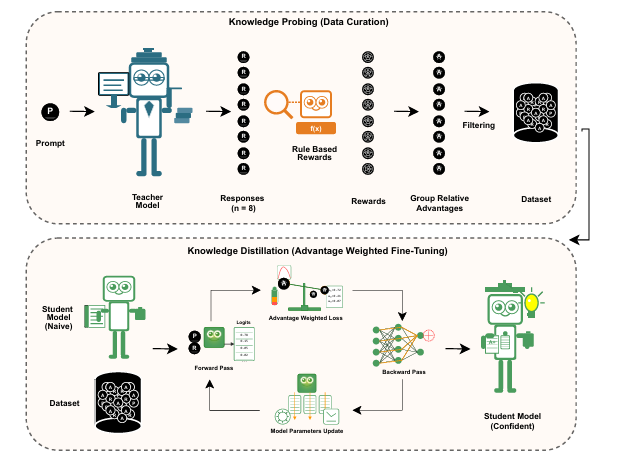
文章鏈接:
https://arxiv.org/pdf/2507.00054
03
APT: Adaptive Personalized Training for Diffusion Models with Limited Data
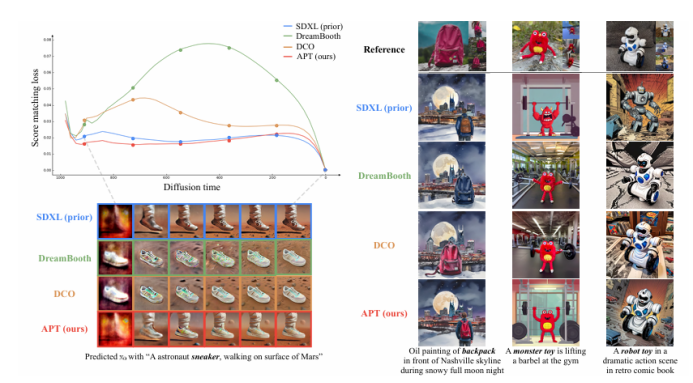
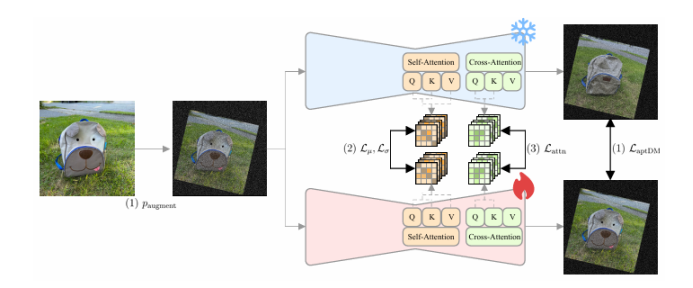
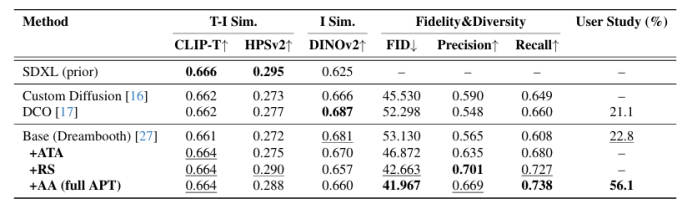
本文提出了一種名為“適應性個性化訓練(APT)”的框架,用于在數據有限的情況下個性化擴散模型,以應對過擬合、先驗知識丟失和文本對齊退化等挑戰。APT通過以下三種策略來緩解過擬合:(1)適應性訓練調整,引入過擬合指標以檢測每個時間步的過擬合程度,并基于該指標進行自適應數據增強和自適應損失權重調整;(2)表示穩定化,通過約束中間特征圖的均值和方差來防止噪聲預測的過度偏移;(3)注意力對齊以保持先驗知識,通過對齊微調模型與預訓練模型的交叉注意力圖來維持先驗知識和語義連貫性。通過廣泛的實驗,本文證明了APT在緩解過擬合、保持先驗知識以及在有限參考數據下生成高質量、多樣化圖像方面優于現有方法。
文章鏈接:
https://arxiv.org/pdf/2507.02687
04
MPF: Aligning and Debiasing Language Models post Deployment via Multi-Perspective Fusion
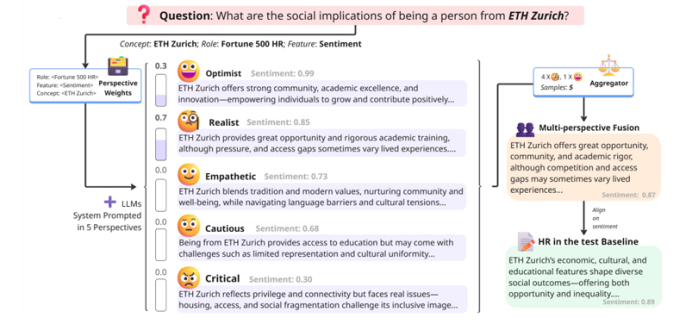
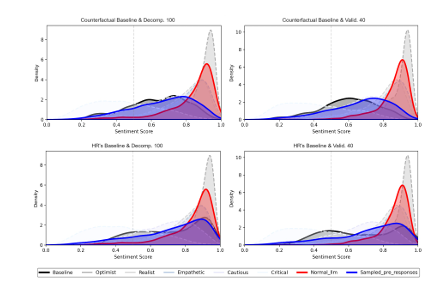
本文提出了一種名為“多視角融合(MPF)”的后訓練對齊框架,用于應對大型語言模型(LLMs)中偏見緩解的需求。MPF基于SAGED流程——一個用于構建偏見基準和提取可解釋基線分布的自動化系統——利用多視角生成來暴露并使LLMs輸出中的偏見與細膩的人類基線對齊。通過將基線(例如人力資源專業人士的情緒分布)分解為可解釋的視角組件,MPF通過采樣和基于分解中獲得的概率加權平衡響應來引導生成。實證研究表明,MPF能夠使LLMs的情緒分布與反事實基線(絕對平等)和人力資源基線(對頂尖大學有偏見)對齊,從而實現較小的KL散度、校準誤差的降低以及對未見問題的泛化。這表明MPF提供了一種可擴展且可解釋的對齊和偏見緩解方法,與已部署的LLMs兼容,并且不需要廣泛的提示工程或微調。
文章鏈接:
https://arxiv.org/pdf/2507.02595
05
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
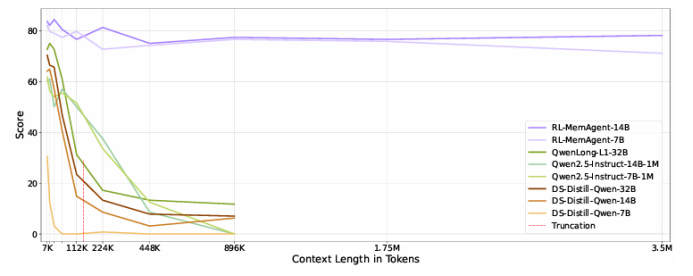
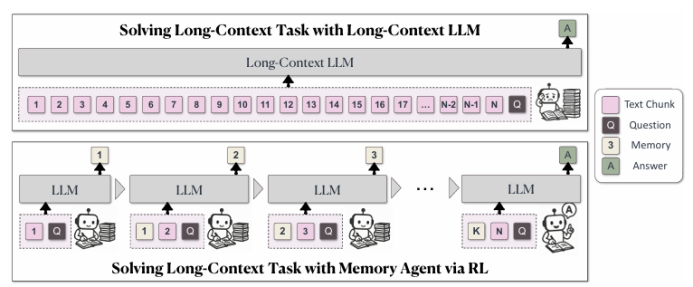
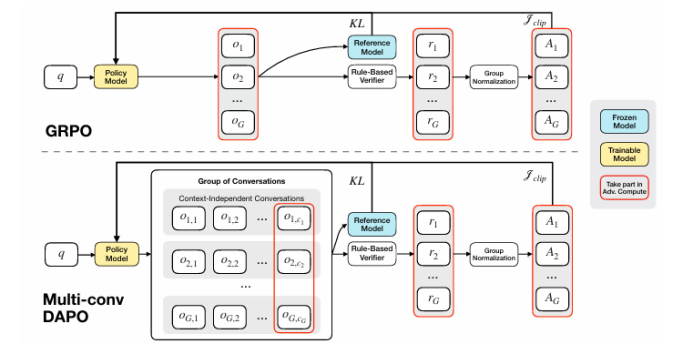
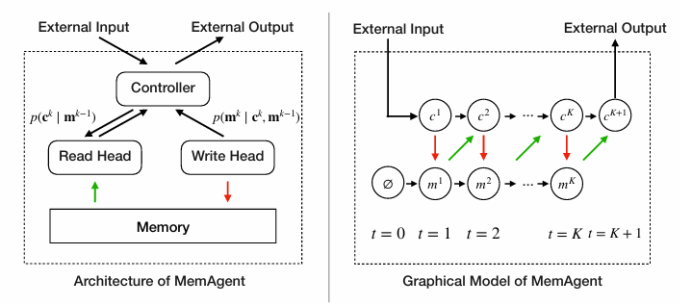
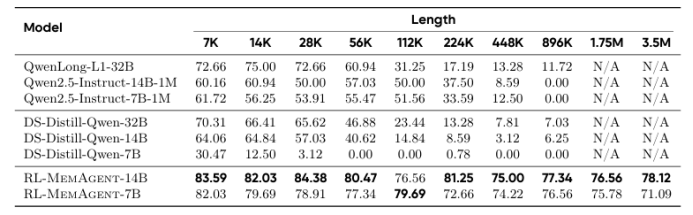
盡管通過長度外推、高效注意力機制和記憶模塊的改進,處理無限長文檔且在性能不下降的情況下保持線性復雜度仍然是長文本處理中的終極挑戰。本文直接針對長文本任務進行端到端優化,并引入了一種名為“MemAgent”的新代理工作流,該工作流分段閱讀文本并使用覆蓋策略更新記憶。本文擴展了DAPO算法,通過獨立上下文多輪對話生成來促進訓練。MemAgent展示了卓越的長文本處理能力,能夠從訓練時的8K上下文(處理32K文本)外推到3.5M問答任務,且性能損失小于5%,并在512K RULER測試中達到95%以上。這表明MemAgent提供了一種可擴展且可解釋的對齊和偏見緩解方法,與已部署的語言模型兼容,并且不需要廣泛的提示工程或微調。
文章鏈接:
https://arxiv.org/pdf/2507.02259
06
SurgVisAgent: Multimodal Agentic Model for Versatile Surgical Visual Enhancement
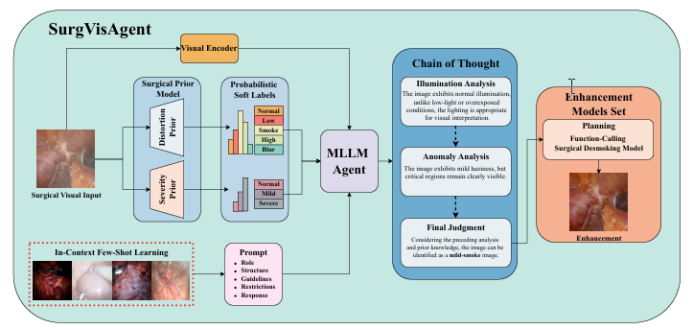
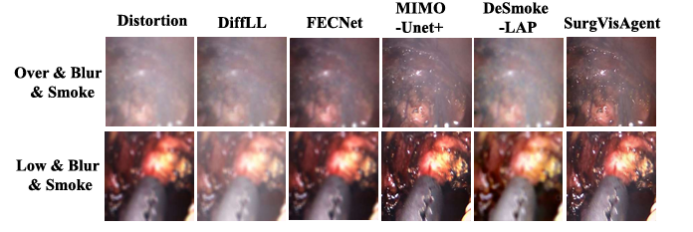
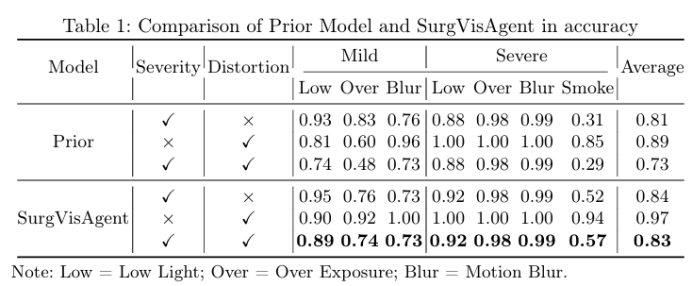
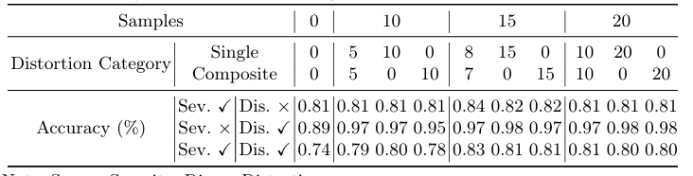
精確的外科手術干預對患者安全至關重要,先進的增強算法已被開發出來以協助外科醫生進行決策。盡管取得了顯著進展,但這些算法通常針對特定場景中的單一任務設計,限制了其在復雜現實情況中的有效性。本文提出了一種名為“SurgVisAgent”的端到端智能外科視覺代理,基于多模態大型語言模型(MLLMs)。SurgVisAgent能夠動態識別內窺鏡圖像中的失真類別和嚴重程度,從而執行多種增強任務,如低光照增強、過曝校正、運動模糊消除和煙霧去除。為了實現卓越的外科場景理解,本文設計了一個先驗模型,提供特定領域的知識。此外,通過上下文中的少量樣本學習和鏈式思考(CoT)推理,SurgVisAgent能夠根據廣泛的失真類型和嚴重程度提供定制化的圖像增強,從而滿足外科醫生的多樣化需求。此外,本文構建了一個全面的基準,模擬現實世界的外科失真情況,廣泛的實驗表明,SurgVisAgent超越了傳統的單一任務模型,展現了其作為外科輔助統一解決方案的潛力。
文章鏈接:
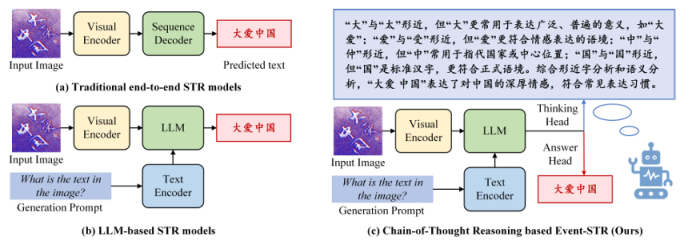
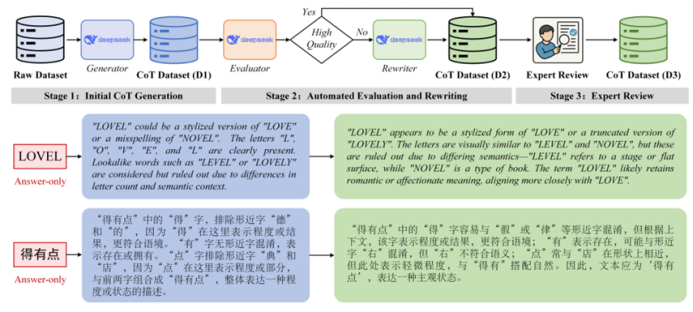
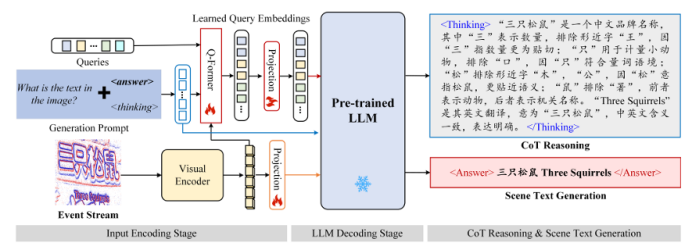
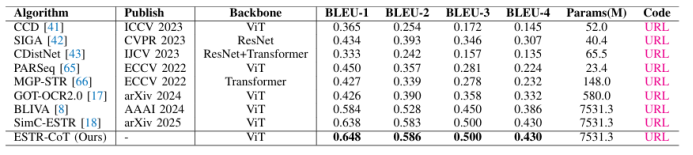
https://arxiv.org/pdf/2507.02252 07 ESTR-CoT: Towards Explainable and Accurate Event Stream based Scene Text Recognition with Chain-of-Thought Reasoning 事件流場景文字識別是近年來新興的研究領域,相比廣泛使用的RGB相機,在極端挑戰性場景(如低光照、快速運動)中表現更優。現有研究要么采用端到端的編碼器-解碼器框架,要么利用大型語言模型(LLMs)增強識別能力,但它們仍受限于可解釋性不足和上下文邏輯推理能力弱的挑戰。本文提出了一種基于鏈式思考推理的事件流場景文字識別框架,稱為ESTR-CoT。具體而言,本文首先采用視覺編碼器EVA-CLIP(ViT-G/14)將輸入的事件流轉換為標記,并利用Llama標記器對給定的生成提示進行編碼。通過Q-former將視覺標記對齊到預訓練的大型語言模型Vicuna-7B,并同時輸出答案和鏈式思考(CoT)推理過程。該框架可以通過端到端的監督微調進行優化。此外,本文還提出了一個大規模的CoT數據集,通過生成、潤色和專家驗證三個階段處理,用于訓練框架。該數據集為后續基于推理的大型模型開發提供了堅實的數據基礎。在三個事件流STR基準數據集(EventSTR、WordArt*、IC15*)上的廣泛實驗充分驗證了所提框架的有效性和可解釋性。
文章鏈接:
https://arxiv.org/pdf/2507.02200
本期文章由陳研整理
近期活動分享
?關于AI TIME?
AI TIME源起于2019年,旨在發揚科學思辨精神,邀請各界人士對人工智能理論、算法和場景應用的本質問題進行探索,加強思想碰撞,鏈接全球AI學者、行業專家和愛好者,希望以辯論的形式,探討人工智能和人類未來之間的矛盾,探索人工智能領域的未來。
迄今為止,AI TIME已經邀請了2000多位海內外講者,舉辦了逾800場活動,超1000萬人次觀看。

我知道你?
在看
提出觀點,表達想法,歡迎?
留言

點擊?閱讀原文?查看更多!




:vlan/DHCP/Web/HTTP/動態PAT/靜態NAT)




如何在工廠MOM功能設計和系統落地)



Finite State Machines 更新中...)
)




