大家好,我是java1234_小鋒老師,最近寫了一套【NLP輿情分析】基于python微博輿情分析可視化系統(flask+pandas+echarts)視頻教程,持續更新中,計劃月底更新完,感謝支持。今天講解?jieba庫分詞簡介及使用
視頻在線地址:
2026版【NLP輿情分析】基于python微博輿情分析可視化系統(flask+pandas+echarts+爬蟲) 視頻教程 (火爆連載更新中..)_嗶哩嗶哩_bilibili
課程簡介:
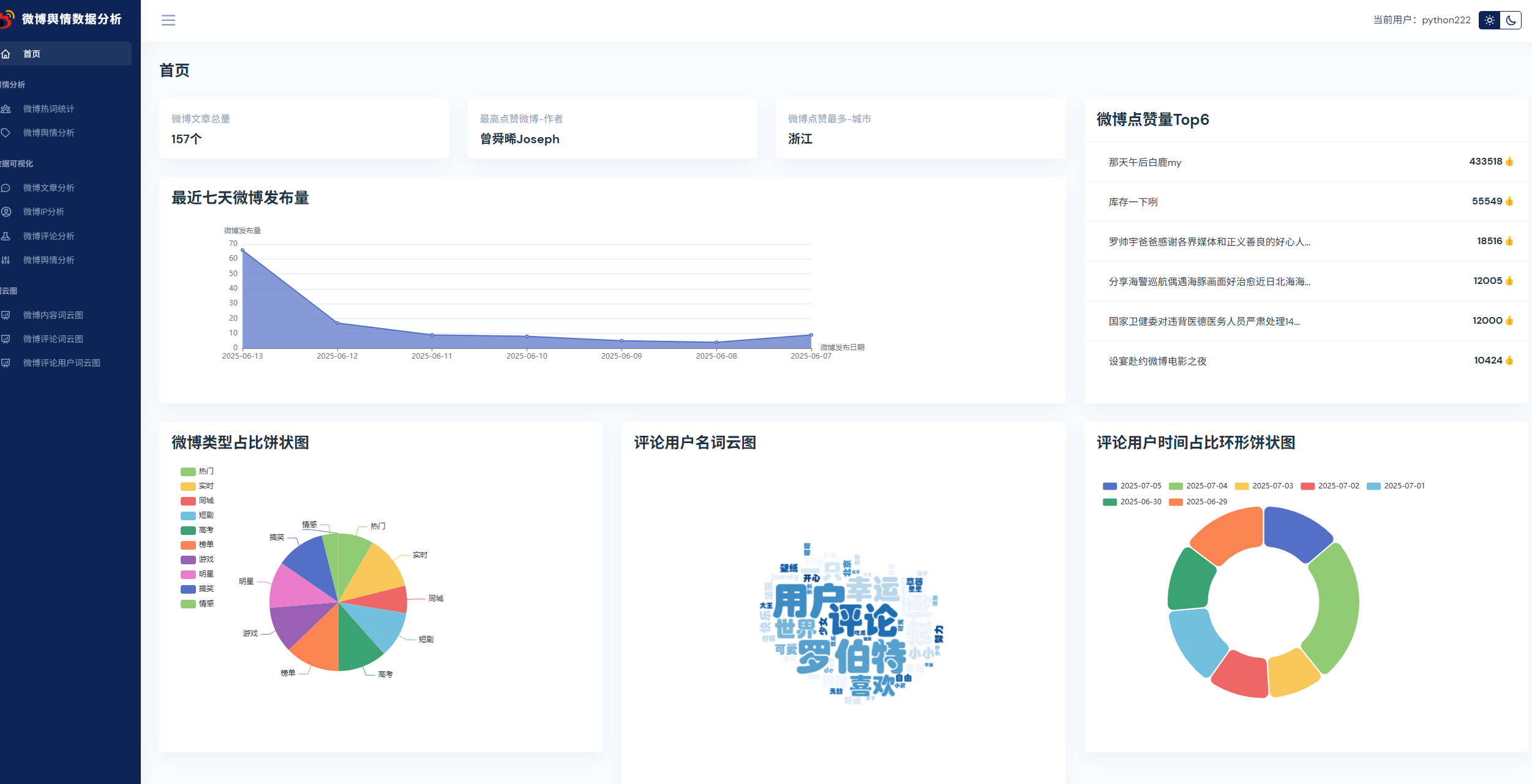
本課程采用主流的Python技術棧實現,Mysql8數據庫,Flask后端,Pandas數據分析,前端可視化圖表采用echarts,以及requests庫,snowNLP進行情感分析,詞頻統計,包括大量的數據統計及分析技巧。
實現了,用戶登錄,注冊,爬取微博帖子和評論信息,進行了熱詞統計以及輿情分析,以及基于echarts實現了數據可視化,包括微博文章分析,微博IP分析,微博評論分析,微博輿情分析。最后也基于wordcloud庫實現了詞云圖,包括微博內容詞云圖,微博評論詞云圖,微博評論用戶詞云圖等功能。
jieba庫分詞簡介及使用
我們后面業務功能實現有一些詞頻統計功能需求,也就是把微博或者評論信息進行分詞,然后統計出出現頻率最高的一些詞語,算作是輿情分析的關鍵要素需求功能。
我們使用jieba庫進行分詞。
jieba 是 Python 中一個功能強大的中文分詞工具,具有高性能、易用性和擴展性等特點。它支持多種分詞模式,是目前最流行的中文分詞庫之一。
安裝jieba庫:
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple三種分詞模式
-
精確模式:最常用的模式,適合文本分析
-
全模式:所有可能的詞語組合
-
搜索引擎模式:對長詞再次切分,適合搜索引擎
分詞示例:
import jieba
?
text = "自然語言處理是人工智能領域的重要方向"
?
# 精確模式(默認)
seg_list = jieba.cut(text)
print("精確模式: " + "/".join(seg_list))
?
# 全模式
seg_list_full = jieba.cut(text, cut_all=True)
print("全模式: " + "/".join(seg_list_full))
?
# 搜索引擎模式
seg_list_search = jieba.cut_for_search(text)
print("搜索引擎模式: " + "/".join(seg_list_search))運行結果:
精確模式: 自然語言/處理/是/人工智能/領域/的/重要/方向
全模式: 自然/自然語言/語言/處理/是/人工/人工智能/智能/領域/的/重要/方向
搜索引擎模式: 自然/語言/自然語言/處理/是/人工/智能/人工智能/領域/的/重要/方向



知識詳解)











完全指南)

_筆記)
