《DeepSeek原生應用與智能體開發實踐》【摘要 書評 試讀】- 京東圖書
在人工智能與機器學習領域,模型的后訓練階段不僅是技術流程中的關鍵環節,更是提升模型性能,尤其是數學邏輯能力的“黃金時期”。這一階段,通過對已初步訓練好的模型進行精細化調優,能夠顯著增強其處理復雜數學邏輯任務的能力,使模型在諸如數學推理、數據分析、決策優化等場景中展現出更高的智能水平。
模型的后訓練,本質上是對模型參數進行二次優化,旨在消除初次訓練中的偏差與不足,提升模型的泛化能力和邏輯推斷精度。特別是在數學邏輯能力方面,后訓練通過引入更高級的數學概念、邏輯規則以及問題求解策略,引導模型學習并掌握更深層次的數學邏輯結構。這一過程不僅要求模型能夠準確理解數學符號與表達式的含義,更需具備運用邏輯規則進行復雜推理和解決問題的能力。大模型后訓練全景圖如圖15-1所示。
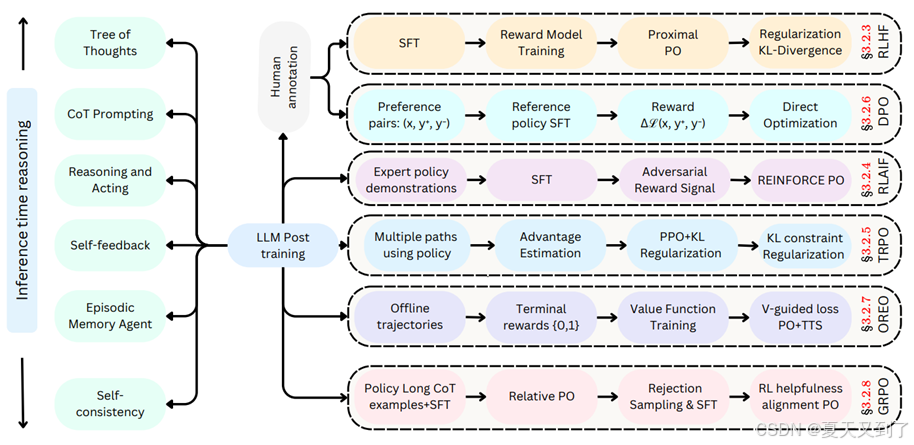
圖15-1? 大模型后訓練全景圖
為了有效提升模型的數學邏輯能力,后訓練階段可采用多種策略。一方面,可以設計專門的數學邏輯任務集,如數學證明題、邏輯推理題等,作為模型訓練的數據源,通過大量實踐讓模型在“做中學”,逐步積累數學邏輯經驗。另一方面,可借鑒人類解決數學問題的思維方式,如歸納推理、演繹推理等,將這些思維方法融入模型的后訓練過程中,使模型能夠模擬人類的邏輯思考過程,提高解題效率和準確性。
15.1.1 ?大模型的后訓練概念與核心目標
大模型的后訓練是在預訓練階段之后,對模型進行進一步調整與優化的關鍵過程。預訓練通常利用海量無標注數據,讓模型學習到語言的通用模式、結構以及豐富的語義信息,使模型具備基礎的“語言能力”。
然而,預訓練模型就像是一個擁有廣泛知識但缺乏特定專業技能的“通才”,它雖然對語言有普遍的理解,但無法直接精準地處理各種具體的任務。后訓練的目的就是把這個“通才”培養成在特定領域或任務上表現出色的“專才”。
例如,在科學領域,預訓練模型可能知道很多通用的詞匯和句子結構,但對于數學術語、物理定理等專業內容理解有限。通過后訓練,使用大量科學領域的數據對模型進行微調,模型就能更好地理解和處理與邏輯計算相關的文本,比如準確解讀論文等。后訓練的核心目標就是提升模型在特定任務上的性能,使其能夠更精準、高效地完成任務,滿足實際應用的需求。
大模型后訓練有多種方法和策略,其中監督微調(Supervised Fine-Tuning,SFT)和強化學習等微調手段是比較常用和有效的方法。微調就像是在已經建好的房子基礎上進行局部裝修。預訓練模型就好比是建好的房子主體結構,而微調則是根據具體需求,對房子的內部布局、裝飾等進行調整。微調的方法如圖15-2所示。
在微調過程中,使用有標注的任務特定數據,對預訓練模型的參數進行輕微調整。比如,要將一個預訓練的語言模型用于情感分析任務,就會收集大量帶有情感標簽(積極、消極、中立)的文本數據,然后讓模型在這些數據上進行訓練,調整模型的參數,使其能夠準確判斷文本的情感傾向。
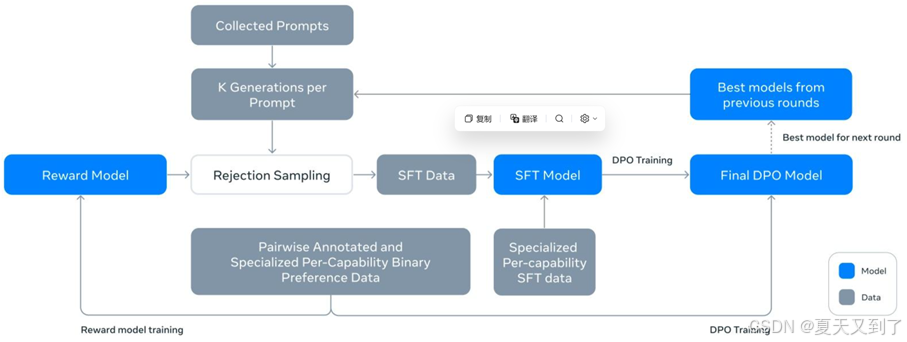
圖15-2? 微調的方法
除了微調,提示學習也是一種重要的后訓練方法。提示學習就像是給模型一個“提示語”,引導模型按照特定的方式生成輸出。例如,對于GLM系列模型,可以通過設計“請總結以下文章的主要內容”這樣的提示,讓模型對給定的文章進行摘要。這種方法不需要對模型進行大量的參數調整,只需要設計合適的提示,就能讓模型適應新的任務。此外,還有參數高效微調方法,它只微調模型中的部分參數,而不是全部參數,這樣可以在保證模型性能的同時,大大減少計算資源和時間成本。
大模型后訓練面臨著一些挑戰。數據稀缺是一個常見問題,特定任務的數據可能非常有限,這就像是要做一道美味的菜肴,但食材卻不夠。為了解決這個問題,研究人員會使用數據增強技術,比如對文本進行回譯、同義詞替換等,增加訓練數據的多樣性。計算資源限制也是一個挑戰,微調大型模型需要大量的計算資源,就像要建造一座大型建筑需要大量的人力和物力。
參數高效微調方法和模型壓縮技術可以在一定程度上緩解這個問題。
未來,大模型后訓練有著廣闊的發展前景。一方面,研究人員會不斷探索更高效的后訓練方法,進一步減少計算資源和時間成本,提高模型的訓練效率。另一方面,跨領域和跨任務學習將成為研究熱點,讓模型能夠更好地適應不同的領域和任務,實現更廣泛的應用。同時,提高模型的可解釋性和安全性也是未來的重要方向,讓模型不僅能夠做出準確的預測,還能讓用戶理解其決策過程,并且防止模型被惡意攻擊或濫用。
15.1.2 ?結果獎勵與過程獎勵:獎勵建模詳解
在上一節中,我們深入探討了大模型后訓練的多種方法與策略,其中最基礎的兩種便是監督微調(SFT)與強化學習。監督微調(SFT)我們已在前文(12.5節)有所闡述,它主要是通過標注好的數據對模型進行微調,使模型能夠初步適應特定的任務需求。而強化學習,尤其是以梯度正則化策略優化(GRPO)為代表的算法,則為大模型的后訓練提供了另一種高效的途徑。
在強化學習的框架下,獎勵建模扮演著至關重要的角色。獎勵建模的核心在于構建一個能夠準確反映人類偏好的獎勵函數,以此引導模型在訓練過程中不斷優化其行為策略。其中,結果獎勵與過程獎勵是獎勵建模中的兩個關鍵維度。結果獎勵關注的是模型最終輸出的質量,即模型生成的答案或決策是否符合人類的期望;而過程獎勵則側重于模型在生成過程中的行為表現,如是否遵循了合理的邏輯、是否展現了創造性等。
在訓練獎勵模型時,我們通常采用最小化負對數似然函數的方法,其目標函數可以表示為:
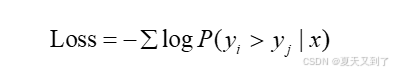
這個公式表明,我們希望獎勵模型給出的獎勵值能夠盡可能地接近真實(SFT),或者符合人類的偏好(GRPO)。例如,如果人類更喜歡yi 而不是yj ,那么我們希望模型的輸出盡可能地滿足R(x,yi) 輸出的概率大于(x,yj) 的輸出概率。
獎勵函數的設計在強化學習領域中占據著舉足輕重的地位。它就像一位精準的導航員,為模型在不同狀態下明確應得的獎勵,進而巧妙地引導模型逐步學習到我們所期望的行為模式。一個精心設計的獎勵函數,能夠如同明燈照亮模型前行的道路,使其在復雜多變的環境中迅速找到最優的行為策略。在強化學習的宏大框架里,獎勵函數的設計絕非可有可無的環節,而是決定模型訓練成敗與效果優劣的關鍵因素。
獎勵根據來源進行劃分,可以清晰地分為過程獎勵和結果獎勵兩大類別。
1. 過程獎勵(Process Reward)
過程獎勵,顧名思義,是在模型執行任務的每一個具體步驟中,依據其當下的行為表現所給予的獎勵。這種獎勵機制就像是一位時刻陪伴在模型身邊的嚴格導師,對模型每一步的操作都進行細致入微的評估與反饋。其顯著優勢在于能夠提供極為密集的反饋信號,模型無須等待漫長的任務結束,就能在每一個小步驟中及時知曉自己的行為是否正確、是否符合預期。這種即時反饋的特性,極大地加速了模型的學習進程,使其能夠更快地調整策略、優化行為。
下面我們用偽代碼模擬了一個過程獎勵,代碼如下所示:
def calculate_step_reward(response):# 1. 語法正確性檢查syntax = check_syntax(response)# 2. 邏輯連貫性評估coherence = model.predict_coherence(response)# 3. 事實一致性驗證fact_check = retrieve_evidence(response)return 0.3*syntax + 0.5*coherence + 0.2*fact_check在這個例子中,獎勵函數考慮了三個方面:
- 語法正確性檢查:檢查模型生成的文本是否符合語法規則。例如,可以使用語法分析器來判斷文本是否存在語法錯誤。
- 邏輯連貫性評估:評估模型生成的文本是否邏輯連貫。例如,可以使用語言模型來預測文本的連貫性。
- 事實一致性驗證:驗證模型生成的文本是否與事實相符。例如,可以使用知識庫來檢索相關信息,然后判斷模型生成的文本是否與知識庫中的信息一致。
對這三個方面進行加權求和,得到最終的獎勵值。權重的選擇需要根據實際情況進行調整。一般來說,更重要的方面應該分配更高的權重。
然而,過程獎勵并非完美無缺。其最大的挑戰在于設計難度極高,這要求設計者必須對任務有極為深入、透徹的理解。不同的任務具有獨特的規則、目標和約束條件,要設計出能夠精準反映模型在每個步驟中行為優劣的過程獎勵函數,需要綜合考慮諸多因素。例如,在一個復雜的機器人控制任務中,機器人的每一個動作都可能受到多種環境因素的影響,設計者需要精確衡量這些動作在不同情境下的合理性,才能制定出合適的過程獎勵規則。一旦過程獎勵設計不當,可能會誤導模型,使其學習到并非最優甚至錯誤的行為模式。
2. 結果獎勵(Outcome Reward)
與過程獎勵不同,結果獎勵關注的是模型在完成整個任務后所達成的最終成果。它更像是一位在終點等待的評判者,根據模型最終呈現的結果給予相應的獎勵或懲罰。結果獎勵的設計相對比較直觀,通常可以根據任務的明確目標來制定。比如,在一場棋類游戲中,贏得比賽即可獲得正獎勵,輸掉比賽則得到負獎勵。這種簡潔明了的獎勵方式,使得模型能夠清晰地了解最終需要追求的目標。
結果獎勵是指在任務完成后,根據模型的最終結果給出的獎勵。結果獎勵的設計比較簡單,只需要關注最終結果即可。但可能提供較稀疏的反饋信號,導致模型學習困難。典型應用場景包括:
- 數學問題:最終答案正確性。例如,如果模型生成的答案與正確答案一致,則給出正獎勵,否則給出負獎勵。
- 代碼生成:通過單元測試的比例。例如,如果模型生成的代碼能夠通過所有的單元測試,則給出正獎勵,否則給出負獎勵。
- 對話系統:用戶滿意度評分。例如,如果用戶對模型的回復感到滿意,則給出正獎勵,否則給出負獎勵。
在實際應用中,為了充分發揮強化學習的優勢,往往需要綜合考慮過程獎勵和結果獎勵,將它們巧妙地結合起來。通過合理設計兩者的權重和交互方式,使模型既能在每個步驟中得到及時的反饋和指導,又能明確最終的目標方向,從而實現更高效、更優質的學習效果。
但結果獎勵也存在一定的局限性。由于它僅關注最終結果,模型在訓練過程中可能會缺乏足夠的指導,就像在黑暗中摸索前行,只能憑借最終的結果反饋來調整方向。這可能導致模型在探索過程中走很多彎路,學習效率相對較低。而且,對于一些復雜任務,單一的結果獎勵可能無法全面反映模型在整個過程中的表現,容易忽略一些重要的中間環節和行為細節。
最后需要提醒大家,結果獎勵與過程獎勵并不是孤立的,而是相互關聯、相互影響的。一個優秀的模型不僅需要在最終結果上符合人類的期望,還需要在生成過程中展現出合理的邏輯和創造性。因此,在構建獎勵模型時,我們需要綜合考慮結果獎勵和過程獎勵,以實現模型性能的全面提升。




知識詳解)











完全指南)

_筆記)

