一、創建一個Pod的工作流程
1. k8s架構解析
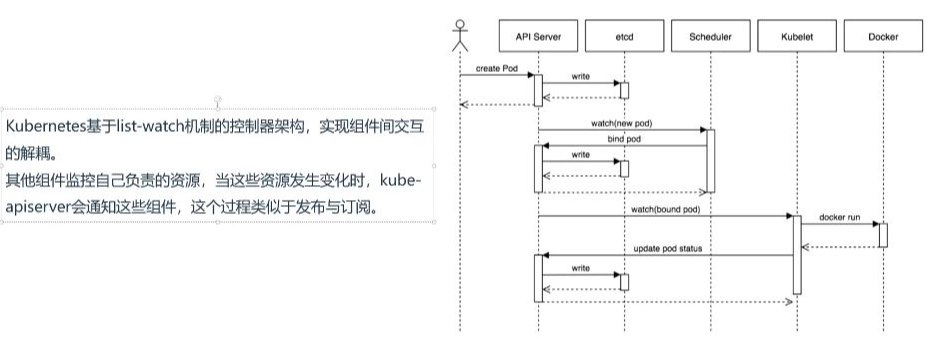
- 組件交互模式: Kubernetes采用list-watch機制的控制器架構,實現組件間交互的解耦。各組件通過監控自己負責的資源,當資源發生變化時由kube-apiserver通知相關組件。
- 類比說明: 類似小賣鋪場景,API Server相當于老板,其他組件(控制器、調度器、kubelet)相當于學生。當有新Pod需要處理時,API Server會主動通知對應組件,避免組件不斷輪詢檢查的低效行為。
- 架構特點:
- 各組件之間不直接通信,全部通過API Server進行協調
- 采用發布-訂閱模式實現事件通知
- 相比輪詢機制更高效,是現代事件通知系統的常見實現方式
二、Pod中影響調度的主要屬性
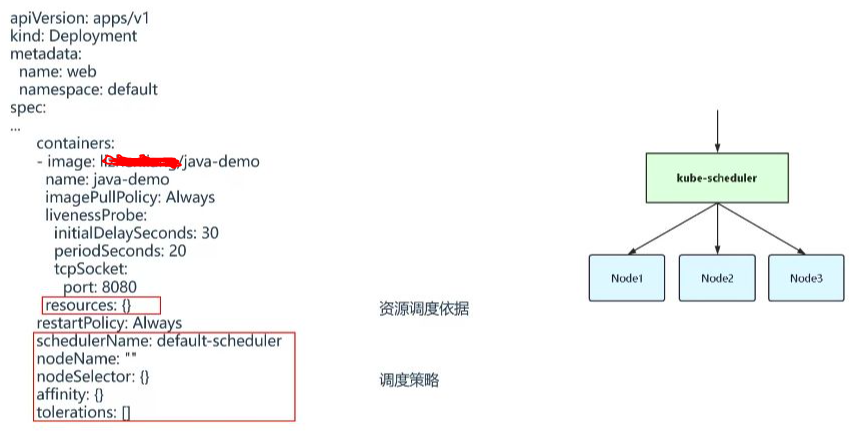
1. 資源配額與調度依據
- 資源配置: 通過resources字段設置容器的CPU和內存資源限制
- 示例配置:requests: memory: "64Mi" cpu: "250m" 和 limits: memory: "128Mi" cpu: "500m"
- CPU單位:可以寫m(毫核)或浮點數,如
0.5=500m0.5=500m0.5=500m,1=1000m1=1000m1=1000m
- 調度影響: 調度器會根據requests值判斷節點是否有足夠資源容納Pod
2. 調度器名稱與自定義調度器
- 默認調度器: 通過schedulerName: default-scheduler指定
- 自定義調度器: Kubernetes支持多個調度器并存,可通過指定不同調度器名稱使用自定義調度邏輯
3. 節點選擇器(nodeSelector)
- 匹配機制: 基于節點標簽進行調度匹配,Pod只會被調度到帶有指定標簽的節點上
- 使用場景: 簡單場景下的節點定向調度
4. 親和性(affinity)
- 功能: 可配置節點親和性和Pod親和性,通過約束條件控制Pod在集群中的分布
- 優勢: 比nodeSelector提供更靈活的調度控制能力
5. 污點與污點容忍(tolerations)
- 污點機制: 控制Pod不在哪些節點上運行
- 容忍機制: 允許Pod在特定條件下運行在污點節點上
6. 調度器篩選與打分機制
- 篩選階段: 調度器首先排除不滿足Pod配置要求的節點
- 打分階段: 對符合條件的節點進行評分,選擇最優節點
- 考慮因素:
- 節點空閑資源情況
- 服務質量要求
- 其他調度策略(如盡量打散Pod分布)
- 不會簡單追求各節點均勻分配Pod
三、資源限制對Pod調度的影響
1. 資源限制容器的創建
- 創建命令:使用kubectl run命令創建容器,示例創建名為part1的nginx容器
- 資源配置項:
- limits:定義容器最大使用的CPU和內存資源
- requests:定義容器請求的基礎資源量
- 配置方法:通過YAML文件中的resources字段進行定義,需結合應用程序實際需求設置
2. 資源請求對調度的影響
1)資源請求的理解
- 本質含義:request代表容器向集群請求的基礎資源量
- 調度影響:決定Pod能否被調度到某個節點的關鍵因素
- 配置示例:在YAML中通過requests.cpu和requests.memory字段定義
2)預留資源的概念
- 核心定義:request是K8s層面的資源預留機制
- 工作方式:節點分配Pod時,會預先扣除request指定的資源量
- 實際占用:預留資源未被實際占用,其他Pod無法使用這部分資源
3)預留資源與最小使用資源的區別
- JVM示例:
- 最小資源:像JVM配置的-Xms參數,物理內存立即被占用
- 預留資源:僅做邏輯預留,實際使用可能低于request值
- 關鍵區別:
- 最小資源:立即物理分配,不可回收
- 預留資源:邏輯預留,實際使用動態變化
4)預留資源在K8s調度中的作用
- 調度邏輯:
- 節點剩余資源 = 總資源 - 所有Pod的request總和
- 新Pod的request必須 ≤ 節點剩余資源才能調度
- 示例說明:2核4G節點上預留512M內存后,剩余3.5G可供其他Pod使用
5)預留資源的配置方法
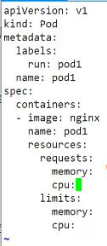
- 配置原則:
- 應設置為應用常規運行所需的基本資源量
- 需要結合應用實際資源使用特征進行調整
- 配置建議:
- 初始可設置較小值,根據監控逐步優化
- 典型場景:nginx等輕量應用可設置較低request值
四、知識小結
知識點 | 核心內容 | 考試重點/易混淆點 | 難度系數 |
API Server角色 | 類比小賣鋪老板,作為核心協調組件,所有組件(學生)都需通過API Server交互 | 組件間無直接通信,必須通過API Server中轉 | ?? |
List-Watch機制 | 事件通知架構,避免組件輪詢查詢(學生不用來回跑),通過監聽API Server事件觸發動作 | 與輪詢機制對比理解,事件驅動更高效 | ??? |
調度器工作原理 | 1. 篩選符合基本配置的節點 2. 對候選節點打分評級 3. 分配Pod到最優節點 | 不會均勻分配,考慮節點空閑率/配置差異/服務質量等多維度 | ???? |
影響調度的6大因素 | 1. 資源配額(resources) 2. 指定調度器(schedulerName) 3. 節點名稱(nodeName) 4. 節點標簽選擇器(nodeSelector) 5. 親和性(affinity) 6. 污點容忍(tolerations) | resource.requests≠limits:requests是預留資源,limits是硬限制 | ???? |
資源限制配置 | - limits:容器資源使用上限 - requests:調度預留資源(非實際占用) | OOM風險:內存超限會被Kill,CPU超限會被限流 | ??? |
資源耗盡影響 | 節點資源利用率>90%時會導致: - 服務響應延遲 - SSH操作卡頓 - 整體服務不可用 | 需配置合理limits防止單Pod拖垮節點 | ??? |
多調度器機制 | 可通過schedulerName字段指定自定義調度器,支持多調度器共存 | 默認調度器名稱:default-scheduler | ?? |
控制器協作模式 | 各控制器(Deployment/StatefulSet等)通過API Server獲知資源變更,獨立完成閉環控制 | 控制器之間無直接交互 | ??? |



)

——方法交換)
)





)






