????????MySQL 的?ORDER BY?子句實現排序是一個涉及查詢優化、內存管理和磁盤 I/O 的復雜過程。其核心目標是高效地將結果集按照指定列和順序排列。
一、確定排序模式 (Sort Mode)
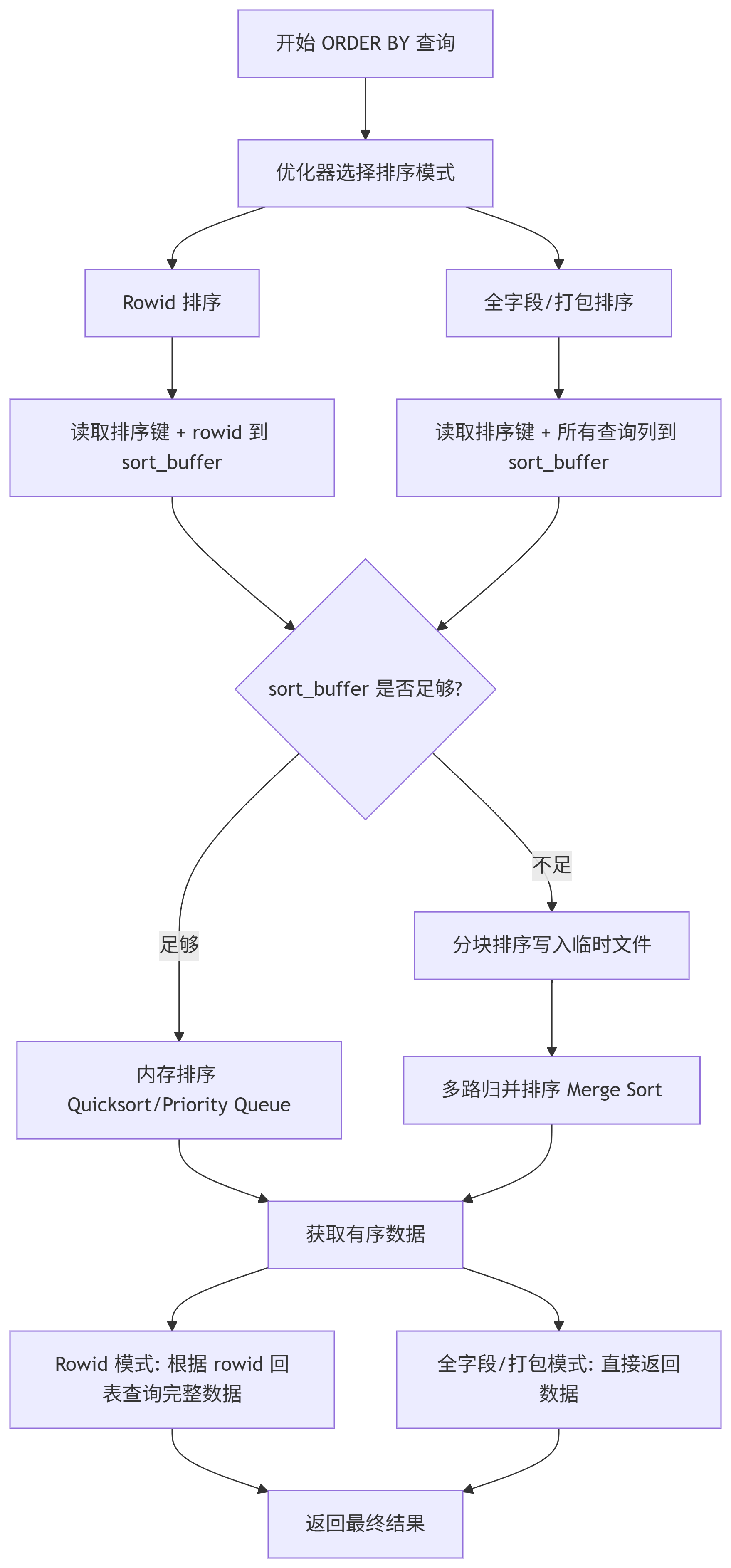
MySQL 根據查詢特性和系統變量決定采用哪種排序策略:
1.1?Rowid 排序
<sort_key, rowid>?模式 (Rowid 排序):僅將排序鍵 (ORDER BY 的列)?和?行指針 (通常是主鍵或行 ID)?放入?
sort_buffer?內存緩沖區。在內存中對這些?
<sort_key, rowid>?元組進行排序。排序完成后,根據行指針回表查詢完整的數據行。
優點:?
sort_buffer?能容納更多元組,減少內存不足時落磁盤的次數。缺點:?排序后需要額外的回表操作,可能增加隨機 I/O。
觸發條件:?
max_length_for_sort_data?系統變量設置較小,或者?SELECT?的列總長度較大時,優化器傾向于選擇此模式。
1.2?全字段排序
<sort_key, additional_fields>?模式 (全字段排序):將?排序鍵 (ORDER BY 的列)?和?查詢需要返回的所有列?放入?
sort_buffer。在內存中直接對包含完整數據的元組進行排序。
排序完成后,直接從?
sort_buffer?返回結果,無需回表。優點:?避免排序后的回表操作,減少隨機 I/O。
缺點:?如果查詢返回的列很多或很寬,
sort_buffer?能容納的元組數量會顯著減少,更容易觸發磁盤臨時文件。觸發條件:?
max_length_for_sort_data?設置較大,或者查詢返回的列總長度較小時,優化器傾向于選擇此模式。
1.3?打包排序
<sort_key, packed_additional_fields>?模式 (打包排序 - MySQL 8.0+ 優化):MySQL 8.0.20 引入的進一步優化。
類似于全字段排序,但對?
sort_buffer?中存儲的額外字段進行了更緊湊的打包處理。優點:?比傳統全字段排序更節省?
sort_buffer?空間,容納更多數據,減少落盤。觸發條件:?MySQL 8.0.20 及以后版本默認啟用,替代傳統的全字段排序。
二、利用?sort_buffer?內存排序
MySQL 分配一塊稱為?
sort_buffer?的內存區域專門用于排序。服務器線程將需要排序的行(根據選擇的模式,可能是部分列或全列)放入?
sort_buffer。如果?
sort_buffer?足夠容納所有需要排序的行:MySQL 直接在內存中對數據進行排序。通常使用高效的快速排序 (Quicksort)?算法。
對于?
ORDER BY ... LIMIT N?這類只需要前 N 條結果的查詢,MySQL 優化器可能使用優先級隊列 (Priority Queue Heap Sort)?算法。它在內存中維護一個大小為 N 的堆,只保留最終需要的 N 條有序結果,避免對所有數據進行完全排序,極大提升效率。
三、處理大數據集:外部排序 (External Sort)
如果?
sort_buffer?無法容納所有需要排序的行:分塊排序:?MySQL 會將數據分成若干塊 (chunks)。對每一塊數據在?
sort_buffer?中進行快速排序,然后將排好序的塊寫入磁盤上的臨時文件。這個過程稱為 "run generation"。多路歸并 (Multi-way Merge):?當所有塊都排序并寫入臨時文件后,MySQL 使用歸并排序 (Merge Sort)?算法將這些已排序的塊合并成一個完整有序的結果集。它使用一個緩沖區同時讀取多個臨時文件的開頭部分,找出當前最小的元素輸出,然后從相應文件補充新元素,直到所有文件處理完畢。
歸并路數:?同時合并的文件數由?
merge_buffer_size?控制。MySQL 會盡量多路歸并以減少磁盤 I/O 輪次。
四、返回結果
無論排序是在內存中完成還是經過外部排序,最終都會得到一個完全按照?
ORDER BY?要求排序的結果集。服務器按順序讀取這個有序的結果集并返回給客戶端。
五、關鍵影響因素和優化點:
sort_buffer_size:?控制分配給每個排序操作的內存緩沖區大小。增大它可以減少甚至避免磁盤臨時文件的使用,提升排序速度。但設置過大可能導致系統內存資源緊張(尤其是在高并發排序時)。max_length_for_sort_data:?決定優化器選擇 Rowid 排序還是全字段/打包排序的閾值。增大它可能促使優化器選擇全字段/打包排序(避免回表),但可能導致?sort_buffer?容納行數減少(更容易落盤)。需要根據實際情況權衡。tmpdir:?指定磁盤臨時文件的存儲目錄。使用更快的存儲設備(如 SSD)可以顯著提升外部排序階段的速度。ORDER BY ... LIMIT N:?優化器會優先嘗試使用優先級隊列算法,性能通常很好。使用覆蓋索引:?如果?
ORDER BY?的列和?SELECT?的列都包含在一個索引中(覆蓋索引),MySQL 可以直接按索引順序讀取數據,完全避免排序操作?(Using index)。這是性能最優的方式。innodb_disable_sort_file_cache:?(InnoDB 相關) 控制是否對臨時文件使用操作系統文件緩存。在某些場景下禁用可能有輕微性能提升。監控指標:
Sort_merge_passes: 歸并排序的次數。次數多表明外部排序發生頻繁,可能需要增大?sort_buffer_size。Sort_range?/?Sort_scan: 分別表示通過范圍掃描和全表掃描執行的排序次數。Sort_rows: 排序的總行數。Created_tmp_disk_tables?/?Created_tmp_files: 創建的磁盤臨時表和臨時文件數,反映內存排序不足的情況。
六、總結流程:
合理設計索引(尤其是覆蓋索引)來避免排序。
根據查詢特征和服務器配置調整?
sort_buffer_size?和?max_length_for_sort_data。解讀執行計劃 (
EXPLAIN) 中的?Using filesort(表示發生了排序)并判斷其成本。監控服務器狀態以識別潛在的排序性能瓶頸。
編寫更高效的 SQL 查詢(例如,利用?
LIMIT?優化)。









完全指南)

_筆記)



)

——方法交換)
)
