我們常用的手機、消費類攝像頭等產品的麥克風所采集的原始聲音信號中往往包含了比較多的背景噪音,不僅影響用戶錄音和回放的使用體驗,而且這些噪聲數據還會降低音頻編碼的壓縮效率,因此有必要對音頻底噪進行抑制處理,這就是ANS(Auto Noise Suppression)功能的用武之地。
音頻3A中對于環境噪音的控制,除了以上的自動噪聲抑制ANS技術以外,還存在一個主動噪聲消除ANC(Active Noise Cancellation)的環節。ANS與ANC的區別主要在于,前者是采用被動降噪的方式,分析環境噪聲中頻率成分針對性的對其濾波處理,盡可能保留清晰的語音部分,并提高音質;而后者常見于目前市場上非常流行的主動降噪耳機,針對環境中存在的噪音,對噪聲聲波的頻率相位等分析,產生與噪聲相位相反的聲音信號來實現噪聲抵消的效果。因此兩者主要的區別就在于,ANS采用被動濾波的方式進行降噪,ANC則采用主動產生與噪聲波形相位相反的方式來實現與噪聲的相互抵消。一般而言,在消費類攝像頭領域中,對于攝像頭麥克風所采集聲音數據的處理只會用到ANS,因此本文僅關注ANS方式的被動降噪處理機制。
1. 音頻背景噪音的來源
一般來說,對于模擬系統來講,噪聲可產生于系統的各個環節之中,因此模擬系統更容易受到干擾而產生噪聲,而對于數字設備而言,抗干擾和噪聲的性能要好很多,噪聲串入的薄弱環節總是設備中的A/D、D/A轉換部分。在消費類電子領域,從成本等角度考慮,目前模擬音頻元件和處理電路仍然是應用中的主流,所以該類型產品中因為各種干擾所造成的背景噪聲等方面的聲音質量劣化往往是產品開發中的難點所在。
總的來講,消費類Camera產品的音頻噪聲主要來源于以下幾個方面:
- ? 設備電子元器件運行中的固有噪聲。例如,電子元器件(電容、電阻等)在高頻運行下本身就會產生細微的白噪聲,這些噪聲很容易被附近靈敏度高的麥克風拾取、放大后變得清晰可聞。
- ? 電磁干擾。電路在高頻開關切換的運行過程中,尤其設備內部空間中有無線通信電路功能運行時,所產生的高頻電磁波輻射干擾,通過音頻傳輸線路串入模擬音頻信號之中,從而產生電磁干擾噪聲。
- ? 電源干擾和接地回路噪聲。電源電路中的尖峰、脈沖、浪涌等,通過電源線路串入音頻線路,以及不同電路部分的地線接地電位差導致電流環路,這些電源和接地方面的噪聲會對音頻的小模擬信號產生顯著影響。
從以上音頻噪聲的來源總結可以看到,這些音頻噪聲大多數來源于硬件設備相關的設計和實現,其中部分噪聲來源是可以優化的,例如通過優化電源接地設計,以及調整布局改善音頻線路處理模塊的電磁干擾狀況,但是不可否認的是,消費類電子產品的結構和電子設計方面的局限性,會導致部分干擾因素無法從硬件層面完全解決。此時就要想辦法利用Audio Codec中的音頻增強功能甚至軟件層面上的音頻噪聲過濾算法來提升音頻采集的質量。
2. 噪聲的典型分類及其處理
從總體上,音頻背景噪聲可以分為兩類:平穩噪聲和瞬時噪聲。
平穩噪聲的最大特點就是其統計特性((如均值、方差、頻譜分布)不隨時間變化。
- ? 平穩噪聲在時域上,振幅波動較小,呈現出規律性分布(如高斯分布)。
- ? 在頻域方面,其頻譜連續且穩定,例如白噪聲會覆蓋全頻帶。
- ? 比較典型的平穩噪聲場景包括:高斯白噪聲、電子設備的熱噪聲、量化噪聲、持續的背景環境噪聲(如空調聲、風扇聲等)。
瞬時噪聲則是突發性強、持續時間短(毫秒至秒級)的噪聲,其統計特性一般會隨時間劇烈變化。
- ? 在時域方面,瞬時噪聲一般具有高幅值、短時間沖擊的特性。
- ? 在頻域方面,其能量一般集中在高頻或者特定的頻段。
- ? 典型的瞬時噪聲包括脈沖噪聲(敲擊鍵盤聲音、敲門聲、開關)、機械沖擊聲、不規則的電磁干擾(如靜電放電)等。
總的來講,對于平穩噪聲的處理,因為其統計特性及其頻譜分布相對比較穩定,容易識別,因此可以根據噪聲的頻譜特性和具體的信號特征進行針對性抑制,相對容易處理。但是瞬時噪聲在時域上突發性很強,而且頻譜基本上總是和正常語音的頻譜混疊在一起,很難進行抑制,因此技術上對于瞬時噪聲如何有效的抑制缺乏好的解決方案
3. 典型音頻降噪算法
下圖是典型的音頻降噪算法的處理流程圖。無論是傳統的信號處理算法,還是基于AI增強處理的思路,最終都是要對音頻噪聲的類型進行檢測,對噪聲模型進行建模,然后基于噪聲的模型針對性的進行處理。
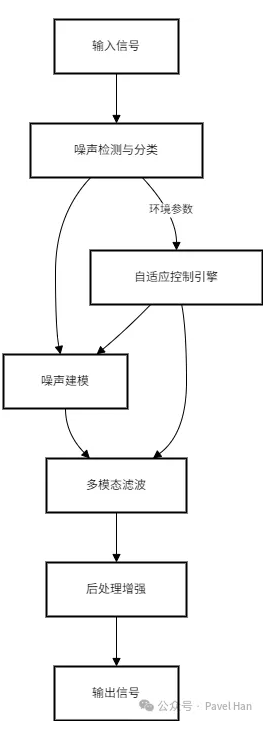
以下以兩個常用的傳統音頻數字信號處理模式的音頻降噪算法,即譜減法和自適應LMS濾波法對音頻降噪的流程進行解釋和說明。
3.1. 譜減法
譜減法是一種基于頻域的噪聲抑制技術,也就是通過對噪聲頻譜的估計和建模,在頻域中從包含噪音的混合信號中減去噪聲成分的處理方式。既然是基于頻域的處理方式,那么總體的處理流程中,就不可避免地要使用FFT把時域中采集的音頻采用數據序列轉換成頻域的頻譜序列 ,在頻域中進行處理后,再通過IFFT把處理后的信號轉換回時域。這樣的處理流程自然就涉及到加大的運算量。
譜減法的整體工作原理是,在語音靜默段(也就是僅含噪聲的時間里面)估計和建立噪聲功率譜模板,然后從包含噪聲信號在內的混合信號的功率譜中減去噪聲模板的功率譜,從而達到只保留語音成分的目的。
基于譜減法進行音頻噪聲消除的工作流程大致如下:
- ? 首先對音頻在時域中的采樣數據序列分片處理,分片的時長固定并與要計算FFT的點數相一致,例如在16KHz音頻采樣,進行512點FFT計算的情況下,以32ms為單位進行音頻數據的分片,一個音頻分片單位就是一個音頻幀。
- ? 對這個音頻幀進行FFT計算,得到其頻譜數據。
- ? 通過一個獨立的VAD檢測模塊,檢測當前是否處于語音靜默期。在當前處于語音靜默期的情況下,基于當前通過FFT計算得到的頻譜序列對噪聲功率譜模板進行動態的更新,使之與當前的噪聲頻譜狀態相一致。
- ? 針對當前音頻幀的頻譜數據序列,在頻域執行譜減運算:也就是把當前音頻幀的頻譜數據,與當前噪聲功率譜模塊的同頻數據進行相減,在當前音頻幀的頻譜上減去噪聲的功率譜,得到僅保留通話語音成分的頻域數據。
- ? 最后再通過IFFT把處理過的數據從頻域轉換回到時域,重新合并為音頻數據序列,恢復為時域的連續音頻采樣信號。
3.2. 自適應LMS濾波算法
不同于在頻域工作的譜減法,LMS濾波算法是一種在時域工作的自適應濾波器算法,通過動態比較音頻實時采樣的數據序列與濾波器的輸出,通過其計算誤差迭代調整濾波器系數,來實現最小化期望信號與濾波器輸出之間的均方誤差。
自適應LMS濾波器主要有兩個參數:
- ? 濾波器階數L:用于建模的噪聲長度,用于匹配噪聲的時間相關性。L越大,意味著對于每個音頻采樣的過濾會參考越多的歷史采樣數據,計算量也越大。典型值為64-256之間。
- ? 補償μ:主要用于控制噪聲變化跟蹤的收斂速度和穩定性,典型值為0.001-0.01之間。
自適應LMS濾波算法的執行流程:
- ? 首先把當前要進行過濾的音頻采樣數據input,以及該采樣之前的L-1個歷史音頻采樣數據放在緩沖區History中。
- ? 基于History歷史緩沖區數據以及LMS濾波器的當前參數W,計算LMS濾波器的輸出值Y:累加歷史采樣數據History[i]與濾波器參數W[i]的乘積。
- ? 計算當前音頻采樣數據input與以上計算出來的LMS濾波器輸出Y的差值E,這個差值E就是經過LMS自適應過濾的值。
- ? 基于以上差值E、歷史緩沖區中的采樣數據History[i]、LMS濾波器的μ對濾波器系統的運行參數W[i]進行更新。
- ? 返回以上計算出來的差值E。
以下是一段進行自適應LMS濾波算法處理的參考代碼,可以配合理解以上的執行流程:
#define L 128 //階數為128階
#define FRAME_SIZE 256
#define MU 0.002f //μ為0.002ffloat w[L]={0};// 濾波器系數
float x_history[L]={0};// 音頻采樣數據的歷史緩沖區voidprocess_frame(float*input,float*output){for(int n =0; n < FRAME_SIZE; n++){// 1. 更新輸入歷史(FIFO)// 每次計算都把當前最新的音頻采樣數據放在x_history緩沖區的開頭memmove(x_history +1, x_history,(L-1)*sizeof(float));x_history[0]= input[n];// 2. 計算濾波器輸出yfloat y =0.0f;for(int i =0; i < L; i++){y += w[i]* x_history[i];}// 3. 計算誤差e,實際上就是執行濾波處理float e = input[n]- y;// 4. 更新濾波器系數for(int i =0; i < L; i++){w[i]+= MU * e * x_history[i];}// 5. 輸出降噪結果output[n]= e;}
}LMS自適應濾波算法在應用中還經常會配合雙麥克風來實現更好的降噪效果。主麥克風靠近人的嘴部用于采集人說話的聲音,副麥克風遠離嘴部并放在噪聲源附近(如耳機外側)用于采集環境噪聲,工作的過程中用副麥克風采集的環境噪聲數據訓練和更新LMS濾波器的參數,然后對主麥克風的音頻采樣數據進行過濾。這種方式對對周期性噪聲(發動機聲、風扇聲)的抑制效果極佳。
- ? 當然,如果要使用主副麥克風的話,以上LMS過濾算法的執行流程和對應的代碼,就需要增加一個參考音頻信號(來自副麥克風)的采樣序列,History和LMS濾波器的輸出及其參數更新基于副麥克風的采樣數據進行計算,對于主麥克風采樣數據的過濾則使用主麥克風的采樣數據減去LMS濾波器的輸出即可。
從以上的譜減法和自適應LMS濾波算法的實現比較來看,譜減法要涉及到頻域和時域之間的兩次相互轉換,因此數據的計算量是比較大的,但是對于一幀音頻數據進行一次運算;而自適應LMS濾波算法是直接在時域中進行運算,但是針對每個采樣都需要執行兩次與濾波器階數相同的浮點數運算,分別用于計算濾波器輸出和更新濾波器的運行參數,所以如果濾波器階數比較高的話,計算量也會比較可觀。但是總的來說,后者對于計算資源的要求更低,更適合用于資源有限的嵌入式系統。
)


和組播(Multicast)對比)




】連續型隨機變量-連續均勻分布)



Spring IOC容器加載流程原理)






