解釋器模式
解釋器模式介紹
解釋器模式使用頻率不算高,通常用來描述如何構建一個簡單“語言”的語法解釋器。它只在一些非常特定的領域被用到,比如編譯器、規則引擎、正則表達式、SQL 解析等。不過,了解它的實現原理同樣很重要,能幫助你思考如何通過更簡潔的規則來表示復雜的邏輯。
解釋器模式(Interpreter pattern)原始定義:用于定義語言的語法規則表示,并提供解釋器來處理句子中的語法。
我們通過一個例子給大家解釋一下解釋器模式。
- 假設我們設計一個軟件用來進行加減計算。我們第一想法就是使用工具類,提供對應的加法和減法的工具方法。
//用于兩個整數相加的方法
public static int add(int a , int b){return a + b;
}//用于三個整數相加的方法
public static int add(int a , int b,int c){return a + b + c;
}public static int add(Integer ... arr){int sum = 0;for(Integer num : arr){sum += num;}return sum;
}+ -
上面的形式比較單一、有限,然而現實生活中情況就比較復雜,形式變化非常多,這就不符合要求,因為加法和減法運算,兩個運算符與數值可以有無限種組合方式。比如: 5-3+2-1, 10-5+20…
文法規則和抽象語法樹
解釋器模式描述了如何為簡單的語言定義一個文法,如何在該語言中表示一個句子,以及如何解釋這些句子。
在上面提到的加法/減法解釋器中,每一個輸入表達式(比如:2+3+4-5) 都包含了3個語言單位,可以使用下面的文法規則定義:
文法是用于描述語言的語法結構的形式規則。
expression ::= value | plus | minus
plus ::= expression ‘+’ expression
minus ::= expression ‘-’ expression
value ::= integer
注意: 這里的符號“::=”表示“定義為”的意思,豎線 | 表示或,左右的其中一個,引號內為字符本身,引號外為語法。
上面規則描述為 :表達式可以是一個值,也可以是 plus 或者 minus 運算,而 plus 和 minus 又是由表達式結合運算符構成,值的類型為整型數。
抽象語法樹:
在解釋器模式中還可以通過一種稱為抽象語法樹的圖形方式來直觀的表示語言的構成,每一棵抽象語法樹對應一個語言實例,例如加法/減法表達式語言中的語句 " 1+ 2 + 3 - 4 + 1" 可以通過下面的抽象語法樹表示
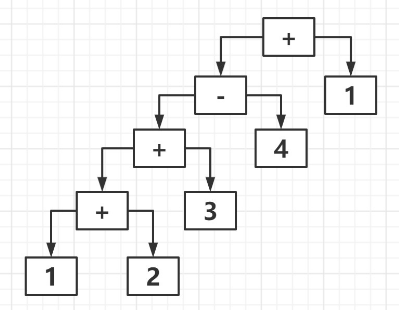
解釋器模式原理
接下來我們畫個UML類圖,通過該類圖來了解下該模式的原理。
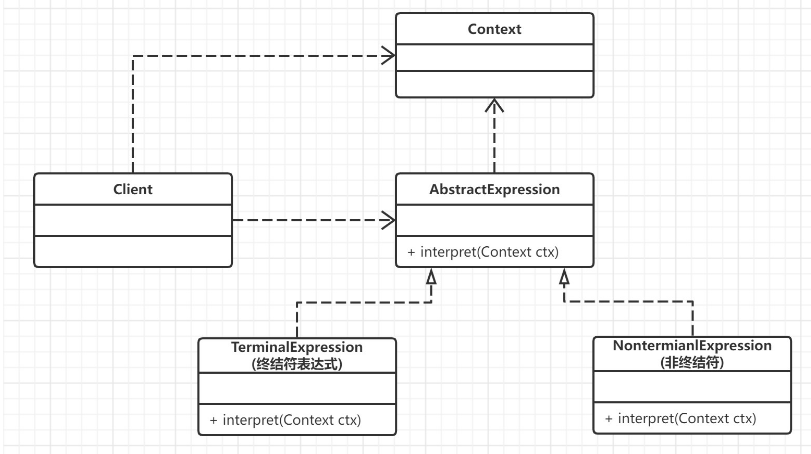
從上述UML類圖中,看到解釋器模式包含以下幾種主要角色。
- 抽象表達式(Abstract Expression)角色:定義解釋器的接口,約定解釋器的解釋操作,主要包含解釋方法 interpret()。
- 終結符表達式(Terminal Expression)角色:抽象表達式的子類,用來實現文法中與終結符相關的操作,文法中的每一個終結符都有一個具體終結表達式與之相對應。上例中的value 是終結符表達式.
- 非終結符表達式(Nonterminal Expression)角色:也是抽象表達式的子類,用來實現文法中與非終結符相關的操作,文法中的每條規則都對應于一個非終結符表達式。上例中的 plus , minus 都是非終結符表達式
- 環境(Context)角色:通常包含各個解釋器需要的數據或是公共的功能,一般用來傳遞被所有解釋器共享的數據,后面的解釋器可以從這里獲取這些值。
- 客戶端(Client):主要任務是將需要分析的句子或表達式轉換成使用解釋器對象描述的抽象語法樹,然后調用解釋器的解釋方法,當然也可以通過環境角色間接訪問解釋器的解釋方法。
解釋器模式實現
為了更好的給大家解釋一下解釋器模式,我們來定義了一個進行加減乘除計算的“語言”,語法規則如下:
- 運算符只包含加、減、乘、除,并且沒有優先級的概念;
- 表達式中,先書寫數字,后書寫運算符,空格隔開;
我們舉個例子來解釋一下上面的語法規則:
- 比如
“ 9 5 7 3 - + * ”這樣一個表達式,我們按照上面的語法規則來處理,取出數字“9、5”和“-”運算符,計算得到 4,于是表達式就變成了“ 4 7 3 + * ”。然后,我們再取出“4 7”和“ + ”運算符,計算得到 11,表達式就變成了“ 11 3 * ”。最后,我們取出“ 11 3”和“ * ”運算符,最終得到的結果就是 33。
代碼示例:
- 用戶按照上面的規則書寫表達式,傳遞給 interpret() 函數,就可以得到最終的計算結果。
/*** 表達式解釋器類**/
public class ExpressionInterpreter {//Deque雙向隊列,可以從隊列的兩端增加或者刪除元素private Deque<Long> numbers = new LinkedList<>();//接收表達式進行解析public long interpret(String expression){String[] elements = expression.split(" ");int length = elements.length;//獲取表達式中的數字for (int i = 0; i < (length+1)/2; ++i) {//在 Deque的尾部添加元素numbers.addLast(Long.parseLong(elements[i]));}//獲取表達式中的符號for (int i = (length+1)/2; i < length; ++i) {String operator = elements[i];//符號必須是 + - * / 否則拋出異常boolean isValid = "+".equals(operator) || "-".equals(operator)|| "*".equals(operator) || "/".equals(operator);if (!isValid) {throw new RuntimeException("Expression is invalid: " + expression);}//pollFirst()方法, 移除Deque中的第一個元素,并返回被移除的值long number1 = numbers.pollFirst(); //數字long number2 = numbers.pollFirst();long result = 0; //運算結果//對number1和number2進行運算if (operator.equals("+")) {result = number1 + number2;} else if (operator.equals("-")) {result = number1 - number2;} else if (operator.equals("*")) {result = number1 * number2;} else if (operator.equals("/")) {result = number1 / number2;}//將運算結果添加到集合頭部numbers.addFirst(result);}//運算完成numbers中應該保存著運算結果,否則是無效表達式if (numbers.size() != 1) {throw new RuntimeException("Expression is invalid: " + expression);}//移除Deque的第一個元素,并返回return numbers.pop();}
}
代碼重構
上面代碼的所有的解析邏輯都耦合在一個函數中,這樣顯然是不合適的。這時候,我們就要考慮拆分代碼進行優化了,將解析邏輯拆分到獨立的小類中, 前面定義的語法規則有兩類表達式,一類是數字,一類是運算符,運算符又包括加減乘除。 利用解釋器模式,我們把解析的工作拆分到以下五個類:num、plu、sub、mul和div
- NumExpression
- PluExpression
- SubExpression
- MulExpression
- DivExpression
/*** 表達式接口**/
public interface Expression {long interpret();
}/*** 數字表達式**/
public class NumExpression implements Expression {private long number;public NumExpression(long number) {this.number = number;}public NumExpression(String number) {this.number = Long.parseLong(number);}@Overridepublic long interpret() {return this.number;}
}/*** 加法運算**/
public class PluExpression implements Expression{private Expression exp1;private Expression exp2;public PluExpression(Expression exp1, Expression exp2) {this.exp1 = exp1;this.exp2 = exp2;}@Overridepublic long interpret() {return exp1.interpret() + exp2.interpret();}
}/*** 減法運算**/
public class SubExpression implements Expression {private Expression exp1;private Expression exp2;public SubExpression(Expression exp1, Expression exp2) {this.exp1 = exp1;this.exp2 = exp2;}@Overridepublic long interpret() {return exp1.interpret() - exp2.interpret();}
}/*** 乘法運算**/
public class MulExpression implements Expression {private Expression exp1;private Expression exp2;public MulExpression(Expression exp1, Expression exp2) {this.exp1 = exp1;this.exp2 = exp2;}@Overridepublic long interpret() {return exp1.interpret() * exp2.interpret();}
}/*** 除法**/
public class DivExpression implements Expression {private Expression exp1;private Expression exp2;public DivExpression(Expression exp1, Expression exp2) {this.exp1 = exp1;this.exp2 = exp2;}@Overridepublic long interpret() {return exp1.interpret() / exp2.interpret();}
}//測試
public class Test01 {public static void main(String[] args) {ExpressionInterpreter e = new ExpressionInterpreter();long result = e.interpret("6 2 3 2 4 / - + *");System.out.println(result);}
}
上面的代碼看起來是不是清晰多了,有空的家人也去動手試試吧!
解釋器模式總結
1) 解釋器優點
-
易于改變和擴展文法
因為在解釋器模式中使用類來表示語言的文法規則的,因此就可以通過繼承等機制改變或者擴展文法。每一個文法規則都可以表示為一個類,因此我們可以快速的實現一個迷你的語言
-
實現文法比較容易
在抽象語法樹中每一個表達式節點類的實現方式都是相似的,這些類的代碼編寫都不會特別復雜
-
增加新的解釋表達式比較方便
如果用戶需要增加新的解釋表達式,只需要對應增加一個新的表達式類就可以了。原有的表達式類不需要修改,符合開閉原則
2) 解釋器缺點
-
對于復雜文法難以維護
在解釋器中一條規則至少要定義一個類,因此一個語言中如果有太多的文法規則,就會使類的個數急劇增加,當值系統的維護難以管理.
-
執行效率低
在解釋器模式中大量的使用了循環和遞歸調用,所有復雜的句子執行起來,整個過程也是非常的繁瑣
3) 使用場景
- 當語言的文法比較簡單,并且執行效率不是關鍵問題.
- 當問題重復出現,且可以用一種簡單的語言來進行表達
- 當一個語言需要解釋執行,并且語言中的句子可以表示為一個抽象的語法樹的時候





![Nordic打印RTT[屏蔽打印中的<info> app]](http://pic.xiahunao.cn/Nordic打印RTT[屏蔽打印中的<info> app])

:開發規范、組件開發方法介紹,快速上手組件開發,創造各種有趣的UI組件!)

與filter()對比)
 概述與分類)



)


中最常用的命令匯總和實戰示例)
)
