目錄
- 1.摘要
- 2.蜣螂優化算法DBO原理
- 3.改進策略
- 4.結果展示
- 5.參考文獻
- 6.代碼獲取
- 7.算法輔導·應用定制·讀者交流

1.摘要
傳統DBO存在探索與開發能力失衡、求解精度低以及易陷入局部最優等問題。因此,本文提出了帶有縮減因子分數階蜣螂優化算法(FORDBO),其通過縮減因子實現探索與開發能力的動態平衡。分數階微積分策略用于調整搜索區域邊界,使算法能更有效地聚焦于潛在的優質解空間。此外,重復更新機制進一步增強了跳出局部最優的能力。
2.蜣螂優化算法DBO原理
【智能算法】蜣螂優化算法(DBO)原理及實現
3.改進策略
縮減因子
DBO在探索與開發能力的平衡上存在不足,容易出現全局探索不充分或局部開發不精確的問題,參數的隨機選取也會導致優化過程不穩定。為解決這些問題,本文引入了自適應縮減因子www,實現了縮減因子的動態調整。
w=e?bkatTmax?w=\mathrm{e}^{-\frac{b}{k^a}\frac{t}{T_{\max}}} w=e?kab?Tmax?t?
在滾球蜣螂階段,個體更新:
xi(t+1)=wxi(t)+αkxi(t?1)+bΔx\boldsymbol{x}_i(t+1)=w\boldsymbol{x}_i(t)+\alpha k\boldsymbol{x}_i(t-1)+b\Delta\boldsymbol{x} xi?(t+1)=wxi?(t)+αkxi?(t?1)+bΔx
xi(t+1)=wxi(t)+tan?θ∣xi(t)?xi(t?1)∣\boldsymbol{x}_i(t+1)=w\boldsymbol{x}_i(t)+\tan\theta\left|\boldsymbol{x}_i(t)-\boldsymbol{x}_i(t-1)\right| xi?(t+1)=wxi?(t)+tanθ∣xi?(t)?xi?(t?1)∣
動態邊界的分數階調整
DBO上下邊界會隨著迭代動態收縮,從而提升搜索的精度。但隨著邊界的不斷收窄,種群個體容易集中甚至重疊,導致多樣性下降,影響全局優化能力。此外,當前邊界的調整僅依賴于當前迭代次數以及局部和全局最優解的位置,缺乏對歷史邊界信息的繼承和利用,進一步限制了優化效果。采用G-L定義:
Dv[f(x)]=lim?ω→0ω?v∑k=0β(?1)kΓ(v+1)Γ(k+1)Γ(v?k+1)f(x?kω)D^v[f(x)]=\lim_{\omega\to0}\omega^{-v}\sum_{k=0}^\beta(-1)^k\frac{\Gamma(v+1)}{\Gamma(k+1)\Gamma(v-k+1)}f(x-k\omega) Dv[f(x)]=ω→0lim?ω?vk=0∑β?(?1)kΓ(k+1)Γ(v?k+1)Γ(v+1)?f(x?kω)
化簡可得:
Dν[Lb?(t+1)]=(1Tmax)X?D^{\nu}\left[ Lb^*(t+1) \right] = \left( \frac{1}{T_{\text{max}}} \right) \mathbf{X}^* Dν[Lb?(t+1)]=(Tmax?1?)X?
Dν[Ub?(t+1)]=?(1Tmax)X?D^{\nu}\left[ Ub^*(t+1) \right] = -\left( \frac{1}{T_{\text{max}}} \right) \mathbf{X}^* Dν[Ub?(t+1)]=?(Tmax?1?)X?
重復更新機制
重復更新機制通過對全局最優個體的位置進行多次迭代更新,結合局部最優和群體平均信息,并引入概率性多樣化操作,有效提升了算法跳出局部最優的能力。

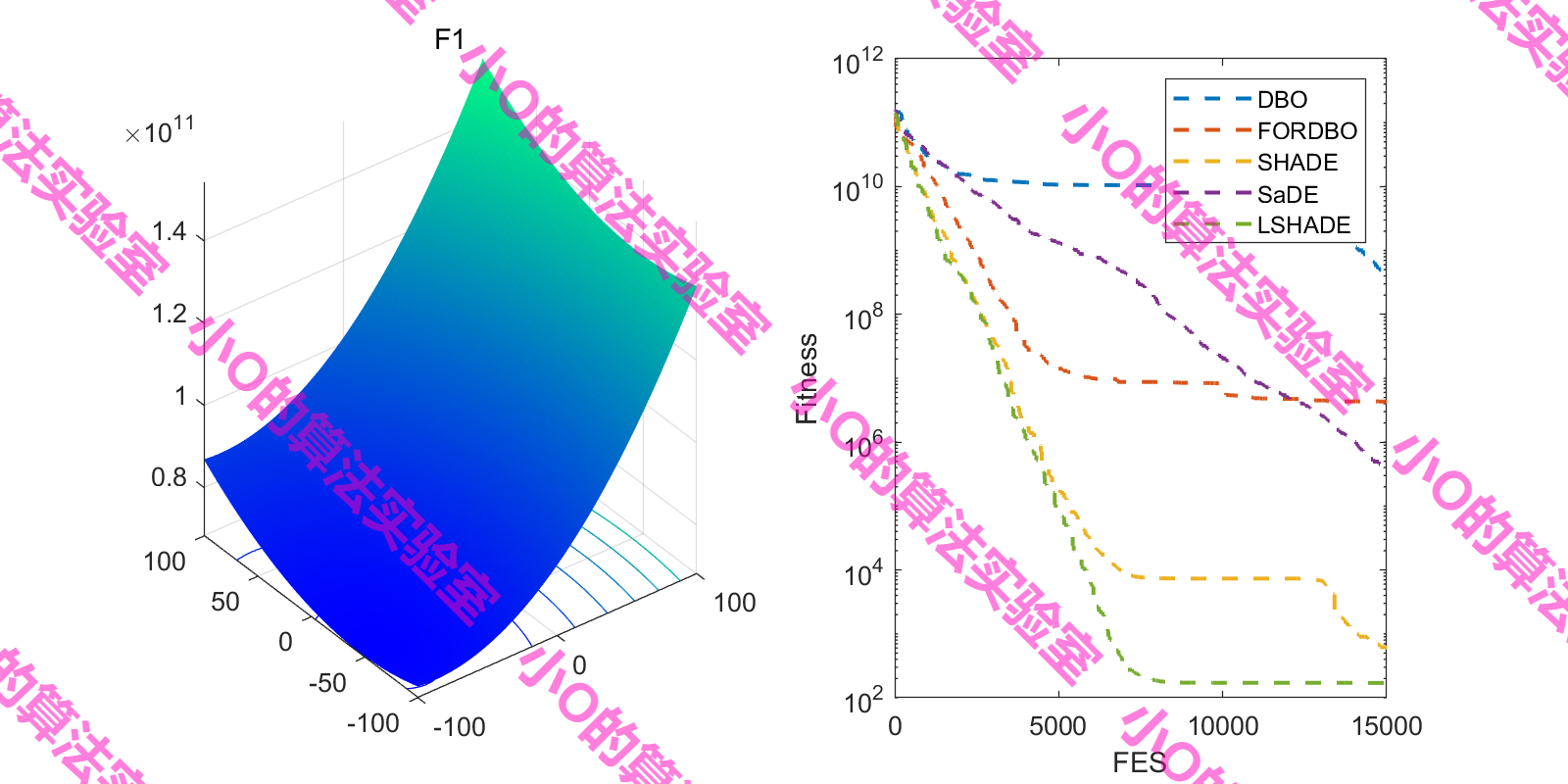
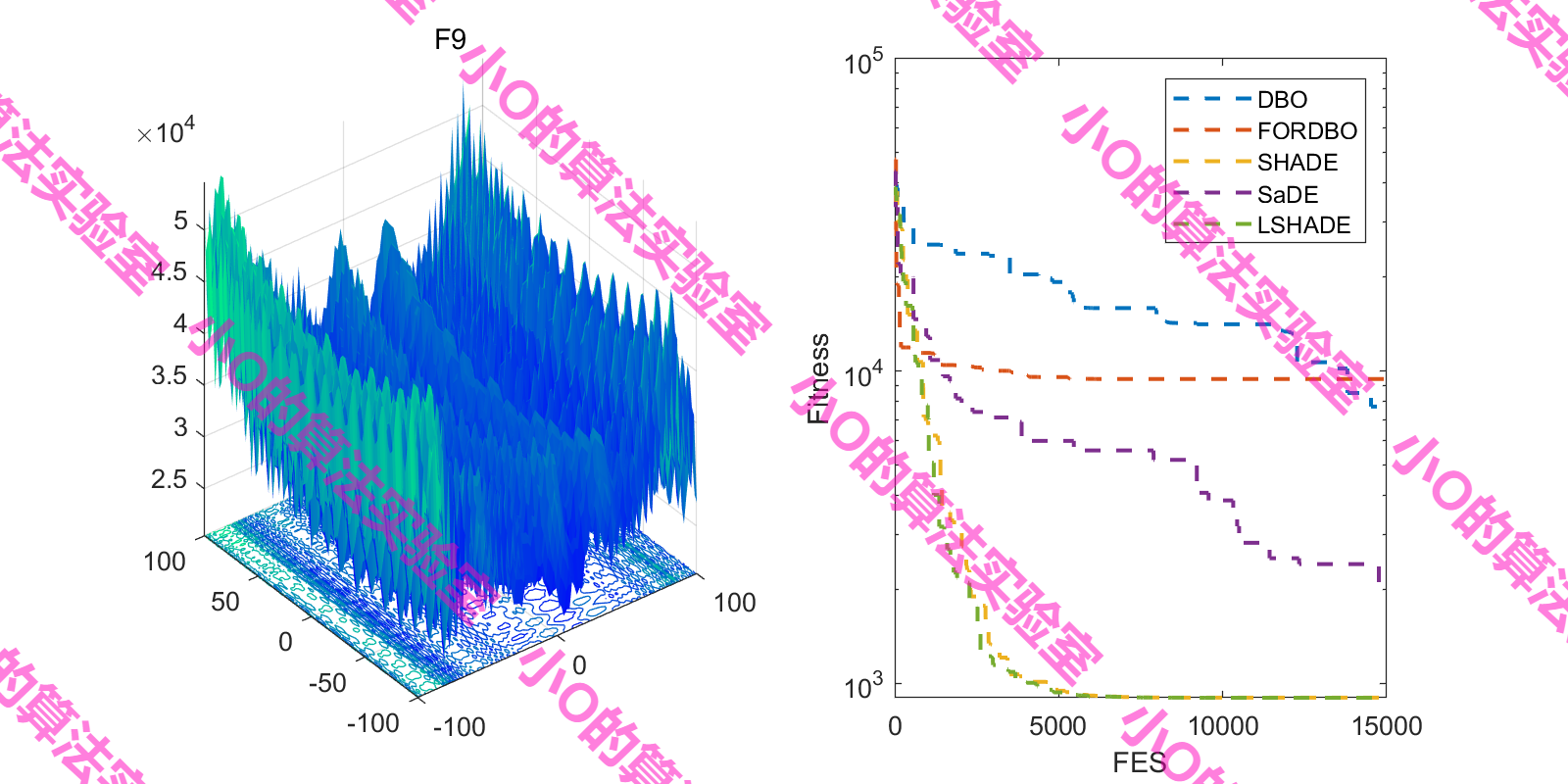
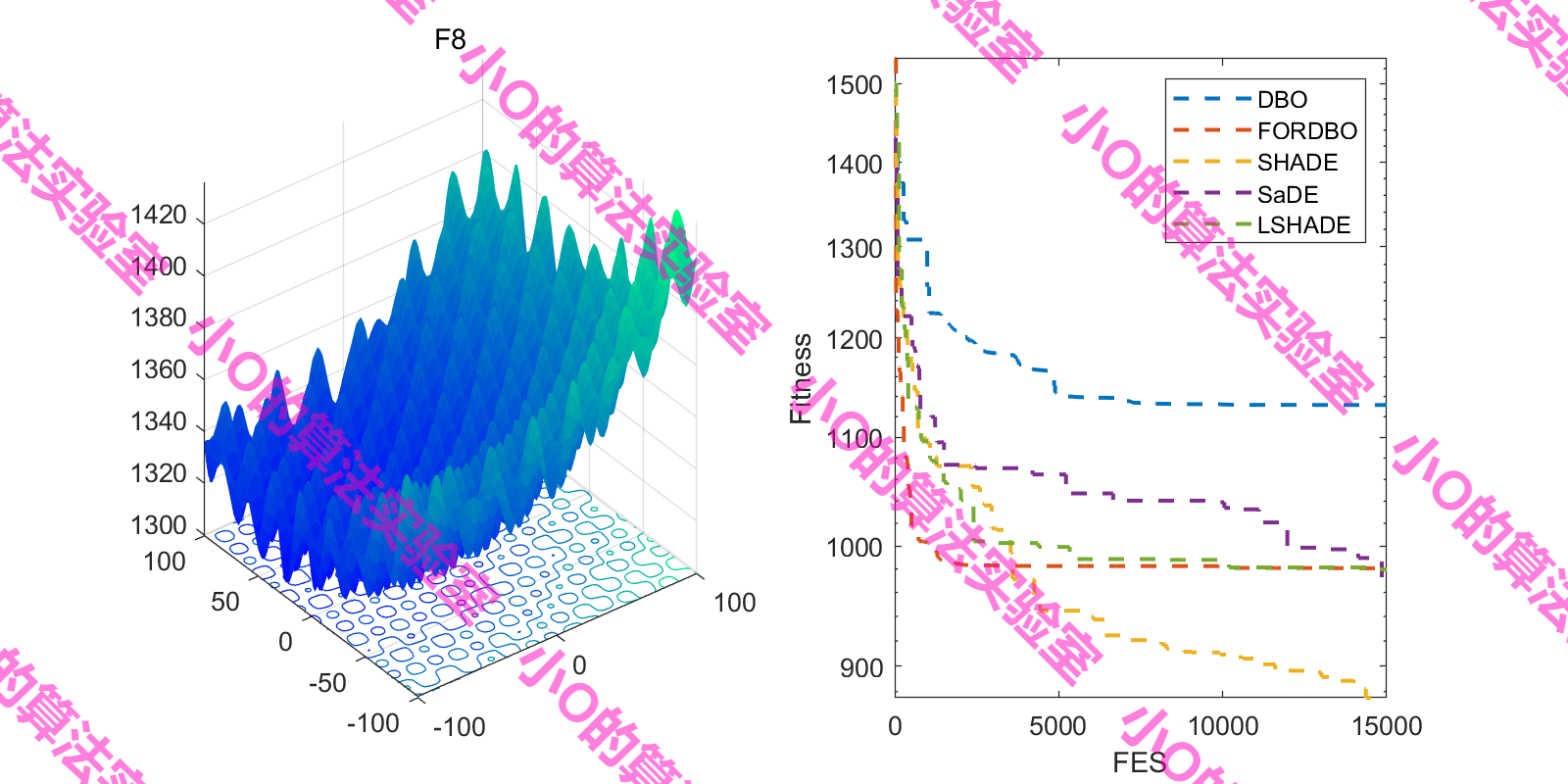
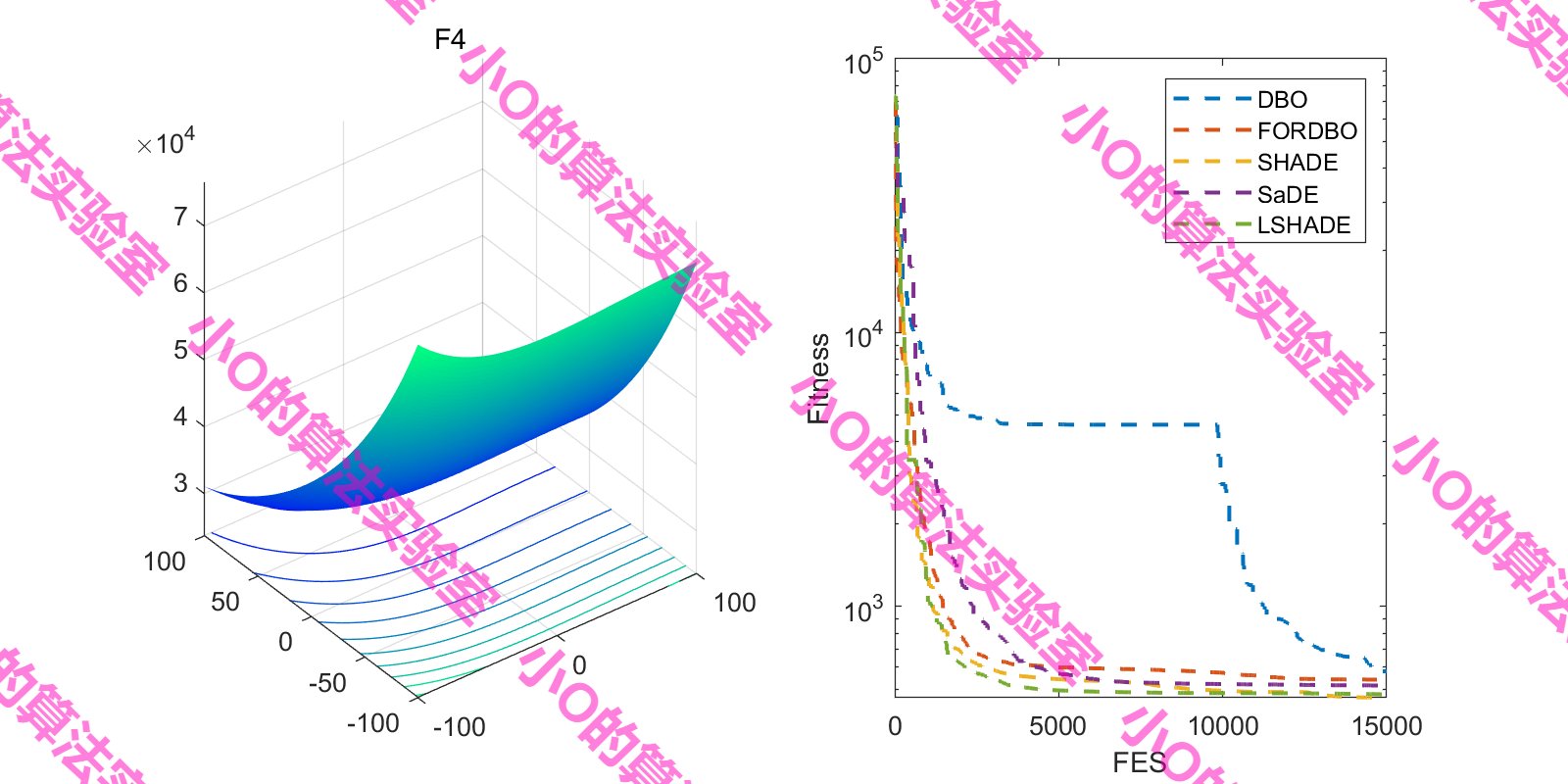
4.結果展示
這里采用fes對FORDBO測試(原文iter,增加DE冠軍算法)
5.參考文獻
[1] Xia H, Ke Y, Liao R, et al. Fractional order dung beetle optimizer with reduction factor for global optimization and industrial engineering optimization problems[J]. Artificial Intelligence Review, 2025, 58(10): 308.
6.代碼獲取
xx
)


中最常用的命令匯總和實戰示例)
)






)


)

)

)
