
前言:在這個數據爆炸的時代,PostgreSQL數據庫集群就像是我們的"數據寶庫"。但是,再好的寶庫也需要有專業的"保安"來守護。今天我們就來聊聊如何給PostgreSQL集群配備一套智能的"保安系統"——自動化性能監測。
📋 文章目錄
- 一、為什么需要自動化監測?
- 二、核心監測指標解析
- 三、監測工具選型指南
- 四、監測架構設計
- 五、實施方案詳解
- 六、告警策略配置
- 七、最佳實踐總結
- 八、常見問題解答
一、為什么需要自動化監測?
1.1 傳統監測的痛點
想象一下,你的PostgreSQL集群就像一個24小時營業的超市,客流量時高時低,商品進出頻繁。如果只靠人工檢查,就像讓店員每隔幾分鐘跑一圈,既累人又容易遺漏問題。
傳統監測面臨的挑戰:
- 反應滯后:問題發生后才能發現,往往為時已晚
- 人力成本高:需要專人24小時值守
- 監測盲區:復雜的集群環境容易有監測死角
- 數據分散:各種指標散落在不同地方,難以形成全局視圖
1.2 自動化監測的價值
自動化監測就像給數據庫裝上了"智能大腦",能夠:
- 實時感知:毫秒級別發現異常
- 預警機制:在問題惡化前提前告警
- 趨勢分析:通過歷史數據預測未來風險
- 智能決策:自動執行一些簡單的修復操作
二、核心監測指標解析
2.1 性能關鍵指標
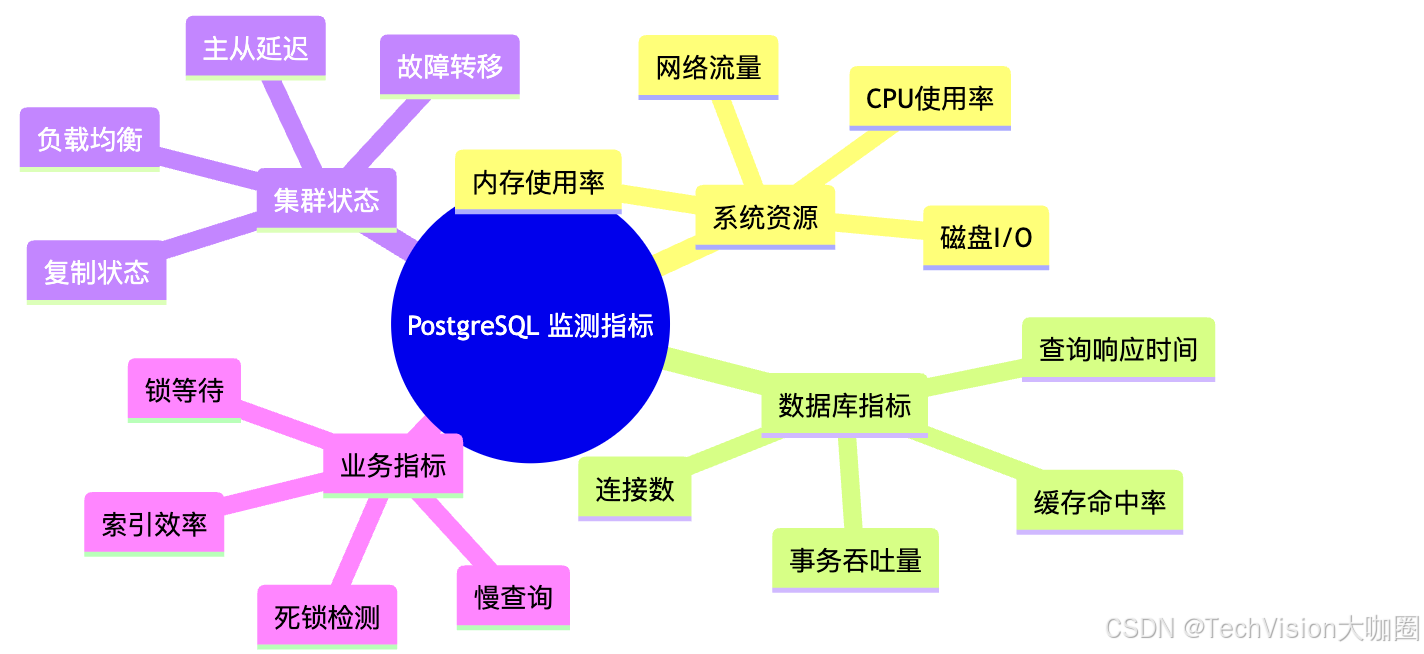
2.2 指標詳細說明
🔥 CPU使用率
- 正常范圍:60-80%
- 告警閾值:>85%持續5分鐘
- 關注點:突發性高CPU可能表示復雜查詢或全表掃描
💾 內存使用情況
- shared_buffers使用率:建議80-90%
- 工作內存:監測是否頻繁使用臨時文件
- 連接內存:每個連接的內存占用
💿 磁盤I/O性能
- IOPS:每秒讀寫操作次數
- 響應時間:單次I/O操作延遲
- 隊列深度:等待處理的I/O請求數量
三、監測工具選型指南
3.1 主流監測方案對比
| 工具組合 | 優勢 | 適用場景 | 部署復雜度 |
|---|---|---|---|
| Prometheus + Grafana | 開源免費、生態豐富、高度可定制 | 中大型企業、技術團隊較強 | ??? |
| Zabbix | 功能全面、中文支持好、學習成本低 | 傳統企業、運維團隊主導 | ?? |
| 云廠商方案 | 開箱即用、與云服務深度集成 | 云原生環境、快速上線 | ? |
| 商業產品 | 專業支持、功能強大 | 大型企業、預算充足 | ???? |
3.2 推薦組合:Prometheus生態
為什么選擇Prometheus?
- 原生支持:PostgreSQL有成熟的exporter
- 云原生:天然適配Kubernetes環境
- 社區活躍:問題解決方案豐富
- 擴展性強:可以輕松添加自定義指標
四、監測架構設計
4.1 整體架構圖
4.2 數據流向說明
Step 1:數據采集
- postgres_exporter從PostgreSQL實例中提取指標
- node_exporter收集系統層面的指標
- 自定義腳本采集業務相關指標
Step 2:數據存儲
- Prometheus定時拉取所有exporter的數據
- 數據按時間序列存儲,支持高效查詢
Step 3:數據分析
- Grafana從Prometheus查詢數據并可視化
- AlertManager根據規則進行告警判斷
Step 4:告警通知
- 多渠道告警確保及時響應
- 告警分級避免信息過載
五、實施方案詳解
5.1 環境準備
服務器配置建議:
# 監測服務器最低配置
CPU: 4核心
內存: 8GB
磁盤: 100GB SSD(用于存儲監測數據)
網絡: 千兆網卡
5.2 部署postgres_exporter
# 1. 下載并安裝
wget https://github.com/prometheus-community/postgres_exporter/releases/download/v0.15.0/postgres_exporter-0.15.0.linux-amd64.tar.gz
tar xzf postgres_exporter-0.15.0.linux-amd64.tar.gz
sudo mv postgres_exporter /usr/local/bin/# 2. 創建監測用戶
sudo -u postgres psql -c "CREATE USER postgres_exporter WITH PASSWORD 'your_password';"
sudo -u postgres psql -c "GRANT pg_monitor TO postgres_exporter;"# 3. 配置環境變量
export DATA_SOURCE_NAME="postgresql://postgres_exporter:your_password@localhost:5432/postgres?sslmode=disable"# 4. 啟動服務
postgres_exporter --web.listen-address=:9187
5.3 Prometheus配置
# prometheus.yml
global:scrape_interval: 15sevaluation_interval: 15srule_files:- "postgresql_rules.yml"scrape_configs:- job_name: 'postgresql'static_configs:- targets: - 'pg-master:9187'- 'pg-slave1:9187'- 'pg-slave2:9187'scrape_interval: 30smetrics_path: /metrics- job_name: 'node'static_configs:- targets:- 'pg-master:9100'- 'pg-slave1:9100'- 'pg-slave2:9100'alerting:alertmanagers:- static_configs:- targets:- alertmanager:9093
5.4 監測流程圖
六、告警策略配置
6.1 告警規則設計
# postgresql_rules.yml
groups:- name: postgresql.rulesrules:# 數據庫連接數告警- alert: PostgreSQLTooManyConnectionsexpr: pg_stat_database_numbackends / pg_settings_max_connections * 100 > 80for: 5mlabels:severity: warningannotations:summary: "PostgreSQL連接數過高"description: "實例 {{ $labels.instance }} 連接數使用率超過80%,當前值:{{ $value }}%"# 復制延遲告警 - alert: PostgreSQLReplicationLagexpr: pg_stat_replication_lag > 30for: 2mlabels:severity: criticalannotations:summary: "PostgreSQL主從復制延遲"description: "從庫 {{ $labels.instance }} 復制延遲超過30秒,當前延遲:{{ $value }}秒"# 慢查詢告警- alert: PostgreSQLSlowQueriesexpr: rate(pg_stat_database_tup_returned[5m]) / rate(pg_stat_database_tup_fetched[5m]) < 0.1for: 10mlabels:severity: warningannotations:summary: "PostgreSQL存在大量慢查詢"description: "數據庫 {{ $labels.datname }} 查詢效率低,命中率:{{ $value }}"
6.2 告警分級策略
🟢 信息級 (Info)
- 定期健康檢查報告
- 性能趨勢分析報告
🟡 警告級 (Warning)
- 資源使用率達到75%
- 慢查詢增多
- 連接數接近上限
🟠 嚴重級 (Critical)
- 資源使用率超過90%
- 主從復制延遲
- 數據庫響應緩慢
🔴 緊急級 (Emergency)
- 數據庫無法連接
- 主庫宕機
- 數據損壞風險
七、最佳實踐總結
7.1 監測策略建議
📊 監測頻率設置
系統指標:每30秒采集一次
數據庫指標:每1分鐘采集一次
業務指標:每5分鐘采集一次
📈 數據保留策略
原始數據:保留30天
小時級聚合:保留90天
日級聚合:保留1年
7.2 性能優化技巧
避免監測成為負擔
- 合理設置采集頻率,避免過于頻繁
- 選擇性采集指標,不是越多越好
- 定期清理歷史數據,防止存儲爆炸
提高監測準確性
- 設置合理的告警閾值,避免誤報
- 建立告警收斂機制,防止告警風暴
- 定期校驗監測數據的準確性
7.3 故障處理流程
八、常見問題解答
Q1:監測會不會影響數據庫性能?
A: 合理配置的監測系統影響微乎其微(通常<1%)。關鍵是:
- 使用只讀用戶進行監測
- 避免執行復雜的監測查詢
- 合理設置采集頻率
Q2:如何處理監測數據存儲空間問題?
A: 采用分層存儲策略:
- 近期數據保持高精度
- 歷史數據進行聚合壓縮
- 超長期數據可以備份到對象存儲
Q3:告警太多怎么辦?
A: 優化告警策略:
- 調整告警閾值,減少誤報
- 實施告警分組和抑制
- 建立告警升級機制
Q4:如何監測集群的整體健康狀態?
A: 建立綜合健康評分:
- 各個指標加權計算
- 設置健康狀態等級
- 提供一目了然的整體視圖
🎯 總結
PostgreSQL數據庫集群的自動化性能監測,就像給我們的"數據寶庫"配備了一套智能安防系統。通過合理的架構設計、工具選型和策略配置,我們可以做到:
🔍 全面監控:從系統資源到業務指標,360度無死角
? 快速響應:秒級發現問題,分鐘級處理異常
📊 數據驅動:基于歷史數據進行趨勢分析和容量規劃
🤖 智能化:自動化處理常見問題,減少人工干預
記住,好的監測系統不是讓你收到更多告警,而是讓你睡得更安穩。當你的PostgreSQL集群在深夜安靜運行時,監測系統就像一個盡職的守夜人,默默守護著你的數據安全。
最后,監測系統也需要持續優化。定期回顧告警記錄,調整監測策略,讓這套"智能保安系統"越來越聰明,越來越貼合你的實際需求。



![[MRCTF2020]PYWebsite](http://pic.xiahunao.cn/[MRCTF2020]PYWebsite)

![[AI-video] Web UI | Streamlit(py to web) | 應用配置config.toml](http://pic.xiahunao.cn/[AI-video] Web UI | Streamlit(py to web) | 應用配置config.toml)





詳解)
詳解)






