一、詞向量與詞嵌入
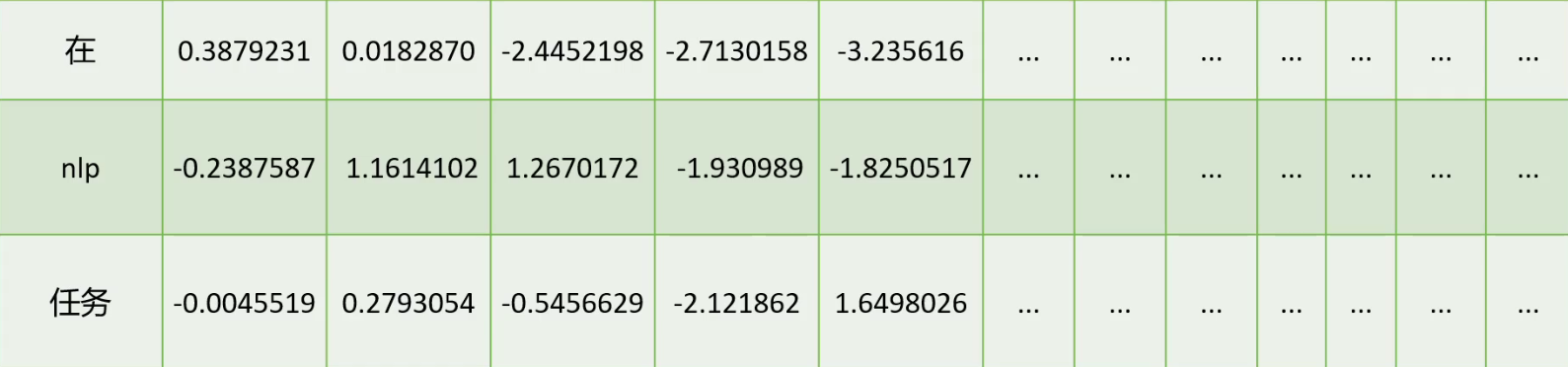
????????將文本語料分詞后,接下來就可以讓計算機學習這些詞,理解這些詞的含義。我們可以直接將文本數據輸入到計算機中讓計算機學習嗎?不可以,計算機只能看懂數字,看不懂文字。所以我們需要將詞語轉成一串數字讓計算機學習。
????????詞向量(Word Vector):指通過某種方式將每個單詞映射為一個固定維度的向量。每個向量的元素通常是浮點數,且這些元素通常不是獨立的,而是通過一定的訓練方式,使得相似的詞向量在向量空間中相對較近。
????????詞嵌入(Word Embedding):生成詞向量的技術或方法。
二、one_hot

????????這12個詞語用one hot的方法表示,我們只需要將對應單詞,在一個擁有所有詞語的詞庫中的對應位置標記1,其他位置標記0即可

????????所以說,one hot的維度是由詞庫的大小決定,詞庫有多少詞,詞向量就有多少維。
one hot的缺點:
- 維度災難:有多少個詞語,矩陣就需要擴大多少維,對于龐大的語料庫來說計算量和存儲量都是很大的問題。
- 無法度量詞語之間的相似性:我們用余弦相似度來計算任意兩個詞語之間的相似度,結果都會是0。
三、Word2Vec
3.1、Word2Vec
?????????由于one hot的種種問題,2013年科學家提出了Word2Vec的詞向量訓練算法。也就是將詞語表現為一串數字,這些數字它可以取任意實數。這樣一來,有限的維度的詞向量,就可以表示無數的詞語,16維的one hot只可以表示16個詞語,而16維的詞向量可以表示無數個詞。
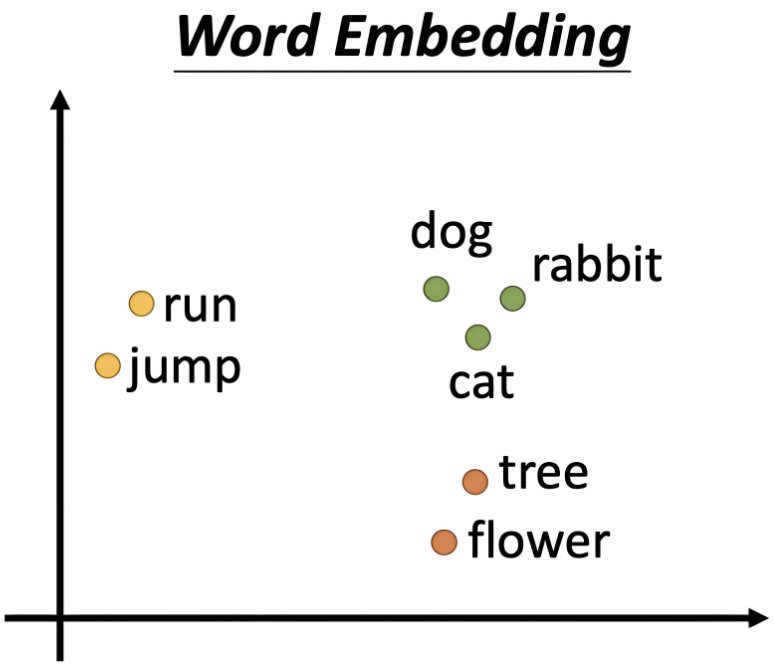
????????這就解決了one hot的維度災難問題,同時Word2Vec也可以度量詞語之間的相似性。我們以二維的Word2Vec模型舉例:
????????我們可以將二維的Word2Vec向量中的第一個值作為x軸的值,第二個值作為y軸的值,那此時一個詞就是二維空間中的一個點,意思越相近的詞,向量越相似。通過計算兩個向量夾角的余弦,余弦值越接近1,代表兩個向量的夾角越小,兩個向量越相似,代表這兩個詞的含義越相近;反之,余弦值越接近0,代表這兩個詞越無關。而在one hot表示法中,任何兩個詞向量的余弦值都是0。這就解決了one hot無法度量詞語之間的相似性的問題。
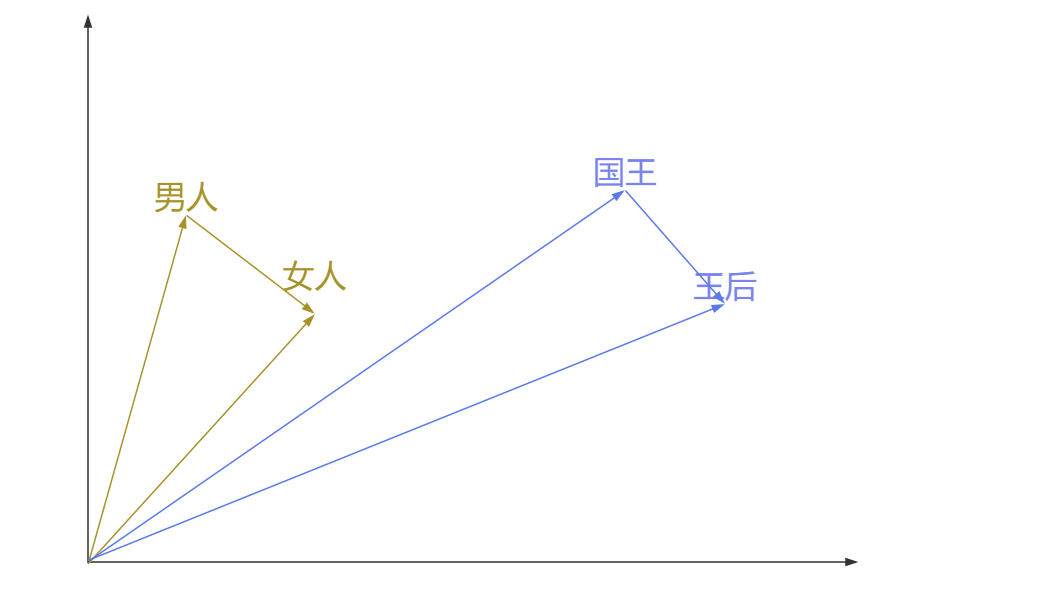
????????而使用Word2Vec向量還有這樣一個好處,就是可以用向量的差值表示兩個詞之間的對應關系,比如男人到女人的向量,和國王到王后的向量,這兩個向量非常相似。那么向量(男人-女人)就可以表示性別(男-->女),比如我們再想找到舅舅對應女性,我們只需要找到離(舅舅-(男人-女人))最近的詞向量即可,大概率這個詞是舅媽。所以對于Word2Vec的向量來說,維度越高,越能精確表示詞與詞之間的精確關系。
3.2、用途
| 應用領域 | 具體用途 | 技術實現 | 典型場景 |
|---|---|---|---|
| 語義相似度計算 | 量化詞語/句子間的語義相似性 | 計算詞向量的余弦相似度、歐氏距離 | 推薦系統、文檔去重、同義詞挖掘 |
| 文本分類 | 將文本表示為詞向量組合(如均值、加權)后分類 | 詞向量 + 分類模型(SVM、神經網絡) | 情感分析、垃圾郵件檢測、新聞分類 |
| 信息檢索與問答系統 | 改進查詢與文檔的語義匹配 | 查詢詞和文檔詞向量相似度加權評分 | 搜索引擎、智能客服 |
| 機器翻譯 | 增強源語言和目標語言的詞對齊 | 雙語詞向量映射(如跨語言 Word2Vec) | 神經機器翻譯(NMT) |
| 命名實體識別(NER) | 提升實體邊界和類別的識別準確性 | 詞向量作為 BiLSTM-CRF 等模型的輸入特征 | 抽取人名、地名、醫學術語 |
| 生成任務 | 為生成模型提供語義化的詞表示 | 詞向量作為 Seq2Seq、Transformer 的輸入 | 文本摘要、對話生成、AI 寫作 |
| 拼寫糾錯與自動補全 | 根據上下文推測正確詞或補全句子 | 結合詞向量和語言模型(如 n-gram、BERT) | 輸入法提示、搜索框補全 |
3.3、缺點
上下文無關
????????傳統的詞向量是靜態的,一個詞無論出現在什么上下文中,其向量都是固定的。比如bank在“河岸”和“銀行”中有不同的意義,但其詞向量是相同的。
對未登錄詞的處理不足
????????對于未在訓練數據中出現的詞,傳統詞向量模型無法生成向量。
詞間關系單一
????????詞向量捕捉的是線性關系,但無法直接表達復雜的語義關系(如因果關系、否定關系)。
????????窗口的長度有限,它只能考慮周圍的幾個詞語,沒有辦法考慮全局的文本信息,這個我們后面講Word2Vec的訓練就會提到
3.4、訓練流程
????????我們通過神經網絡模型可以對詞向量進行訓練,首先隨機初始化語料庫中所有詞語的向量值,并且隨機一個權重參數矩陣。比如說我們想訓練英文的詞向量,就需要準備所有的英文單詞,隨機初始化每一個單詞的詞向量。

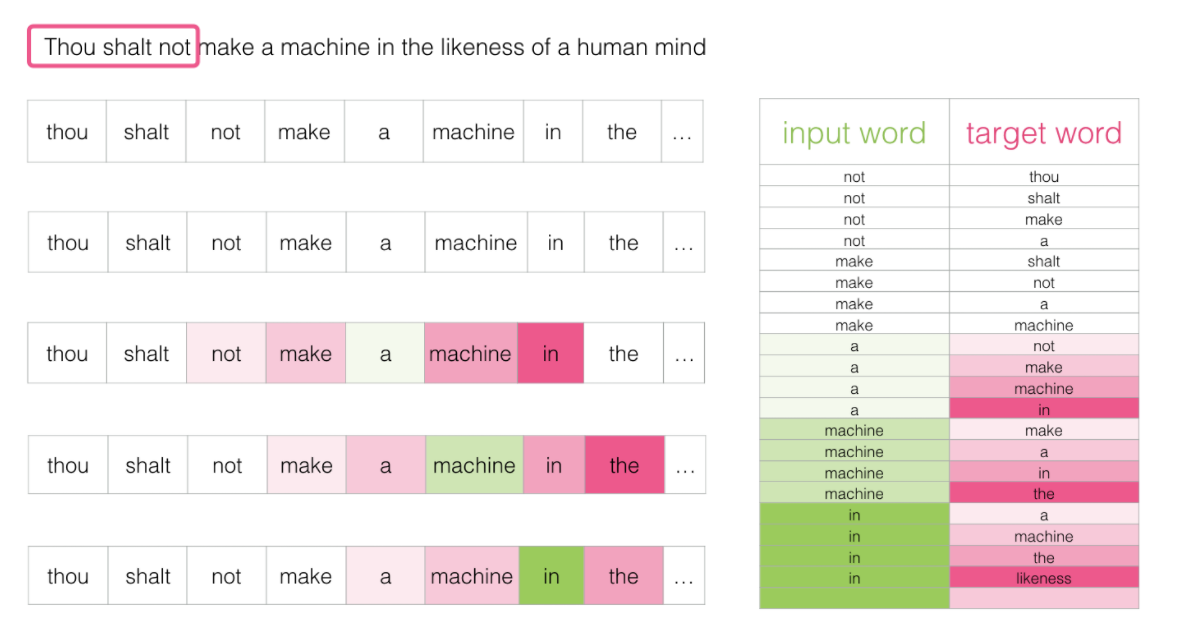
????????其次,設定好輸入值和輸出值,設置輸入和輸出值的方法有很多,后面我們會提到,基本都是輸入值的是文本中的某些詞,輸出值的是輸入值文本周圍的某些詞。例如學習這么一句話:

????????Word2Vec 的訓練過程本質上是通過神經網絡學習詞語之間的分布式表示。其核心思想基于一個重要的語言學假設:在文本中相鄰出現的詞語往往具有語義上的關聯性。具體來說,當我們在訓練時輸入一個中心詞(如"NLP"),模型會嘗試預測其周圍可能出現的上下文詞(如"任務"、"處理"、"語言"等)。這個預測過程通過神經網絡架構實現:輸入層接收詞語的one-hot編碼,經過隱藏層的線性變換后得到對應的詞向量表示,再通過輸出層的Softmax激活函數計算上下文詞的概率分布。
????????在訓練過程中,模型會不斷比較預測結果與真實上下文之間的差異,通過損失函數(通常是負對數似然)量化這種差異,并利用反向傳播算法同時更新兩個關鍵部分:一是隱藏層的權重矩陣(即詞向量查找表本身),二是輸出層的權重參數。這種雙重更新機制是Word2Vec的一個重要特性,它使得詞向量在訓練過程中能夠動態調整。隨著訓練的進行,語義相關或功能相似的詞語(如"任務"和"NLP")在向量空間中的距離會逐漸靠近,表現為它們的詞向量夾角減小、余弦相似度增高。
????????值得注意的是,這種學習過程完全是無監督的,僅依賴于文本中詞語的自然分布規律。最終訓練得到的詞向量能夠捕捉豐富的語義關系,不僅能使相關詞語在向量空間中聚集,還能保持諸如"國王-男性+女性≈女王"這樣的線性類比關系。這種特性使得Word2Vec成為許多NLP任務的基礎工具,從簡單的語義相似度計算到復雜的文本分類和生成任務都能發揮重要作用。詞向量的質量很大程度上取決于訓練語料的規模和質量,以及模型參數的合理設置,如向量維度、上下文窗口大小等。
3.5、訓練細節
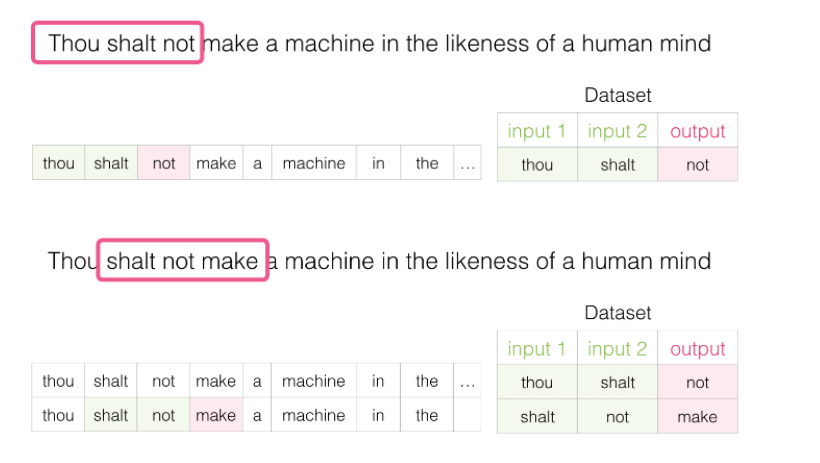
????????假如每次訓練讀取三個單詞,前兩個單詞是輸入,第3個單詞是輸出,這3個單詞要怎么選擇呢?我們通過窗體滑動的方式進行選擇,第一次選擇第123個單詞,讓這3個單詞產生關聯;第二次選擇第234個單詞,讓這3個單詞產生關聯;第三詞選擇第345個單詞,讓這3個單詞產生關聯...之后每次訓練向后滑動一個詞,直到學習完所有資料,這就是窗口滑動。
3.5.1、CBOW(連續詞袋模型)
????????通過上下文詞預測中心詞的模型。即輸入是上下文詞,輸出是中心詞,目標是讓其上下文詞的向量能夠準確中心詞。
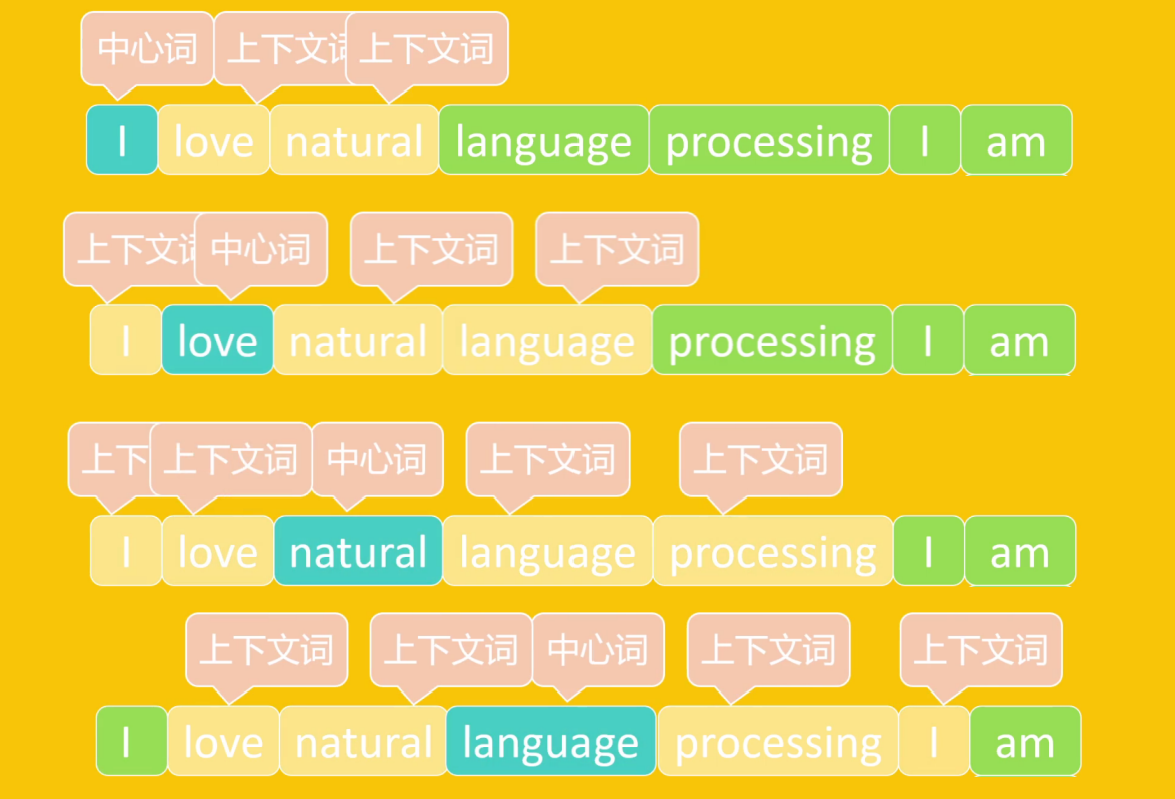
3.5.2、Skip-gram(跳字模型)
????????通過中心詞預測上下文詞的模型。輸入是中心詞,輸出是上下文詞,目標是讓目標詞的向量能夠準確預測其上下文。Skip-gram計算量要大于CBOW,但對稀有詞的訓練效果要好于CBOW。
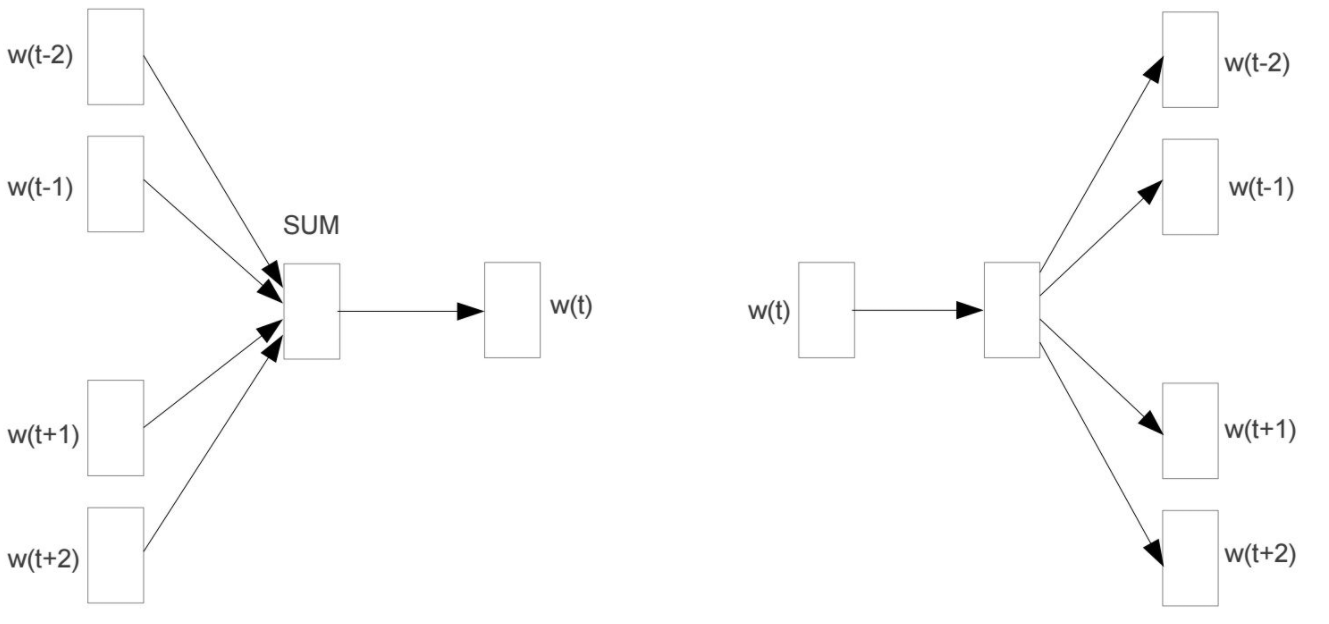
CBOW通過上下文預測中心詞,計算效率較高,適合常見詞的訓練
Skip-gram通過中心詞預測上下文,計算復雜度較高,但對稀有詞效果更好。
四、負采樣模型
????????負采樣(Negative Sampling)是Word2Vec模型中用于優化訓練效率的關鍵技術,它通過改進傳統Softmax的計算方式,使模型能夠高效地學習詞向量表示。該技術的核心思想是將復雜的多分類問題轉化為一系列二分類問題,從而大幅降低計算復雜度。

????????在具體實現上,負采樣采用了一種對比學習的策略。對于每個訓練樣本(中心詞和真實上下文詞組成的正樣本),模型會隨機采樣若干個非上下文詞作為負樣本。這種設計使得模型只需要區分正樣本和負樣本,而無需計算整個詞匯表的概率分布。例如,在處理"NLP-任務"這個正樣本時,模型可能會采樣"足球"、"電影"等無關詞匯作為負樣本,通過Sigmoid函數計算每個樣本的得分并優化損失函數。
????????負采樣的數學表達式采用了邏輯回歸的形式,其目標函數由兩部分組成:最大化正樣本的相似度得分,同時最小化負樣本的得分。這種設計不僅顯著提高了訓練速度(計算量從O(V)降低到O(k),其中V是詞匯表大小,k是負樣本數量),還能保
持較好的詞向量質量。實驗表明,當負樣本數量k=5-15時,模型效果與完整Softmax相當。
????????在實際應用中,負采樣通常采用頻率加權的采樣策略,即高頻詞被選為負樣本的概率更高,但會通過次采樣(subsampling)技術來平衡高頻詞的影響。這種技術上的改進使得Word2Vec能夠有效處理大規模語料庫,同時捕捉到詞語之間豐富的語義關系。負采樣的成功應用不僅限于Word2Vec,其思想也被廣泛應用于推薦系統、圖嵌入等其他表示學習領域。
?五、訓練模型效果
安裝工具包
pip install jieba=0.42.1
pip install gensim==4.3.1
代碼
import jieba # 中文分詞庫
import gensim # 自然語言處理庫
import re # 正則表達式庫
from gensim.models import Word2Vec # Word2Vec詞向量模型# 打開并讀取《三國演義》白話文文本文件
f = open('三國演義白話文.txt', 'r', encoding='utf-8')# 初始化一個空列表,用于存儲處理后的分詞結果
lines = []# 逐行處理文本
for line in f:# 使用jieba進行分詞temp = jieba.lcut(line)words = [] # 臨時存儲處理后的詞語# 對每個分詞結果進行清洗處理for word in temp:# 使用正則表達式去除標點符號和特殊字符i = re.sub("[\s+\.\!\/_,$%^*(+\"\'””《》]+|[+——!,。?、~@#¥%……&*():;‘]+", "", word)# 只保留非空詞語if len(i) > 0:words.append(i)# 只添加包含有效詞語的行if len(words) > 0:lines.append(words)# 使用處理后的語料訓練Word2Vec模型
# 參數說明:
# lines: 分詞后的語料庫(列表的列表)
# vector_size: 詞向量維度(20維)
# window: 上下文窗口大小(取中心詞前后各2個詞)
# min_count: 最低詞頻(出現次數少于3次的詞將被忽略)
# epochs: 訓練輪數(整個語料庫訓練10次)
# sg: 訓練算法(1表示使用skip-gram,0表示CBOW)
model = Word2Vec(lines, vector_size=20, window=2, min_count=3, epochs=10, sg=1)# 保存訓練好的模型(可選)
# model.save("word2vec.model")# 加載已保存的模型(可選)
# model = Word2Vec.load("word2vec.model")# 獲取"孔明"的詞向量并打印
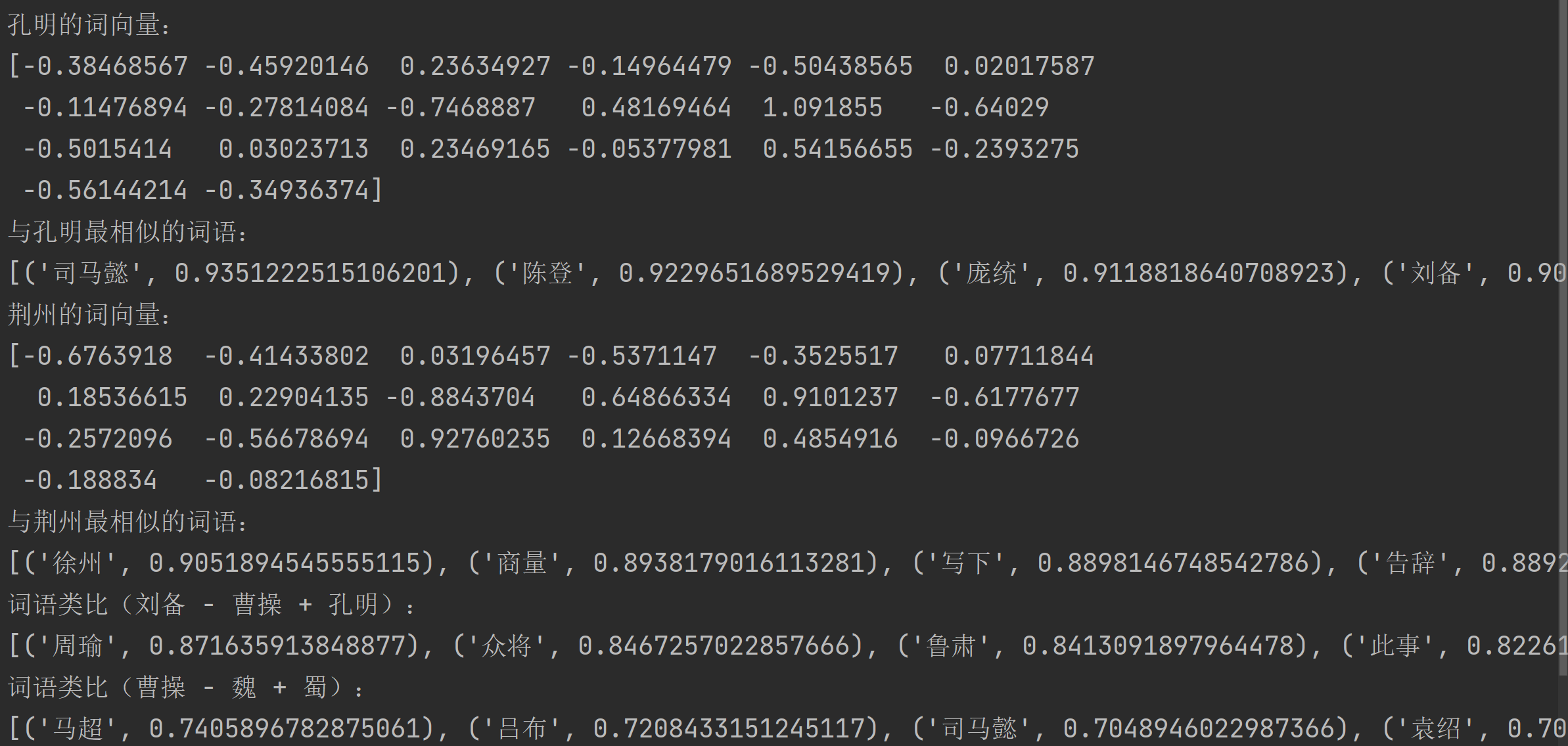
print("孔明的詞向量:")
print(model.wv.get_vector('孔明'))# 查找與"孔明"最相似的20個詞
print("\n與孔明最相似的詞語:")
print(model.wv.most_similar('孔明', topn=20))# 獲取"荊州"的詞向量并打印
print("\n荊州的詞向量:")
print(model.wv.get_vector('荊州'))# 查找與"荊州"最相似的20個詞
print("\n與荊州最相似的詞語:")
print(model.wv.most_similar('荊州', topn=20))# 詞語類比:劉備 - 曹操 + 孔明 ≈ ?
# 相當于"劉備"加上"孔明"減去"曹操"的結果
print("\n詞語類比(劉備 - 曹操 + 孔明):")
words = model.wv.most_similar(positive=['劉備', '孔明'], negative=['曹操'], topn=10)
print(words)# 詞語類比:曹操 - 魏 + 蜀 ≈ ?
# 相當于"曹操"加上"蜀"減去"魏"的結果
print("\n詞語類比(曹操 - 魏 + 蜀):")
words = model.wv.most_similar(positive=['曹操', '蜀'], negative=['魏'], topn=10)
print(words)







)
)

(騰訊地圖))
)







