文章目錄
- 1. MAE與MSE的本質區別
- 2. 高斯噪聲下的統計特性
- 3. MAE導致稀疏解的內在機制
- 4. 對比總結
1. MAE與MSE的本質區別
MAE(Mean Absolute Error)和MSE(Mean Squared Error)是兩種常用的損失函數,它們的數學形式決定了對誤差的不同敏感程度:
- MAE: MAE=1n∑i=1n∣yi?y^i∣\text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|MAE=n1?∑i=1n?∣yi??y^?i?∣
- MSE: MSE=1n∑i=1n(yi?y^i)2\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2MSE=n1?∑i=1n?(yi??y^?i?)2
從幾何角度看,MSE等價于歐氏距離的平方,而MAE等價于曼哈頓距離。這導致MSE對離群點更加敏感,而MAE更具魯棒性。
2. 高斯噪聲下的統計特性
在噪聲服從高斯分布 ?~N(0,σ2)\epsilon \sim \mathcal{N}(0, \sigma^2)?~N(0,σ2) 的假設下:
-
MSE是最優損失函數
MSE對應于高斯噪聲下的最大似然估計(MLE)。此時,最小化MSE等價于最大化對數似然函數:
arg?min?θ∑i=1n(yi?f(xi;θ))2?arg?max?θ∏i=1n12πσ2exp?(?(yi?f(xi;θ))22σ2)\arg\min_{\theta} \sum_{i=1}^{n} (y_i - f(x_i; \theta))^2 \quad \Leftrightarrow \quad \arg\max_{\theta} \prod_{i=1}^{n} \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i - f(x_i; \theta))^2}{2\sigma^2}\right) argθmin?i=1∑n?(yi??f(xi?;θ))2?argθmax?i=1∏n?2πσ2?1?exp(?2σ2(yi??f(xi?;θ))2?)
高斯分布的二次指數形式直接對應平方誤差。 -
MAE的統計假設
MAE對應于噪聲服從拉普拉斯分布時的MLE。拉普拉斯分布的概率密度函數為:
p(?)=12bexp?(?∣?∣b)p(\epsilon) = \frac{1}{2b} \exp\left(-\frac{|\epsilon|}{b}\right) p(?)=2b1?exp(?b∣?∣?)arg?min?θ∑i=1n∣yi?f(xi;θ)∣?arg?max?θ∏i=1n12bexp?(?∣yi?f(xi;θ)∣b)\arg\min_{\theta} \sum_{i=1}^{n} |y_i - f(x_i; \theta)| \quad \Leftrightarrow \quad \arg\max_{\theta} \prod_{i=1}^{n} \frac{1}{2b} \exp\left(-\frac{|y_i - f(x_i; \theta)|}{b}\right) argθmin?i=1∑n?∣yi??f(xi?;θ)∣?argθmax?i=1∏n?2b1?exp(?b∣yi??f(xi?;θ)∣?)
此時,最小化MAE等價于最大化拉普拉斯分布下的對數似然。
3. MAE導致稀疏解的內在機制
MAE容易產生稀疏解的根本原因在于其梯度特性:
-
MAE的梯度恒定
MAE的梯度為:
?MAE?θ={+1,if?yi?f(xi;θ)>0?1,if?yi?f(xi;θ)<0undefined,if?yi?f(xi;θ)=0\frac{\partial \text{MAE}}{\partial \theta} = \begin{cases} +1, & \text{if } y_i - f(x_i; \theta) > 0 \\ -1, & \text{if } y_i - f(x_i; \theta) < 0 \\ \text{undefined}, & \text{if } y_i - f(x_i; \theta) = 0 \end{cases} ?θ?MAE?=????+1,?1,undefined,?if?yi??f(xi?;θ)>0if?yi??f(xi?;θ)<0if?yi??f(xi?;θ)=0?
當參數接近零時,梯度仍保持恒定(±1),促使參數快速收斂到零。 -
MSE的梯度衰減
MSE的梯度為:
?MSE?θ=?2(yi?f(xi;θ))??f(xi;θ)?θ\frac{\partial \text{MSE}}{\partial \theta} = -2(y_i - f(x_i; \theta)) \cdot \frac{\partial f(x_i; \theta)}{\partial \theta} ?θ?MSE?=?2(yi??f(xi?;θ))??θ?f(xi?;θ)?
當誤差接近零時,梯度趨近于零,導致參數更新變得非常緩慢,難以徹底消除小參數。 -
幾何解釋
從優化角度看,MAE的等高線是菱形(在二維空間中),其頂點位于坐標軸上;而MSE的等高線是圓形。當損失函數的最小值靠近坐標軸時,MAE的等高線更容易與坐標軸相交,從而使某些參數被置零。更多可見 損失函數的等高線與參數置零的關系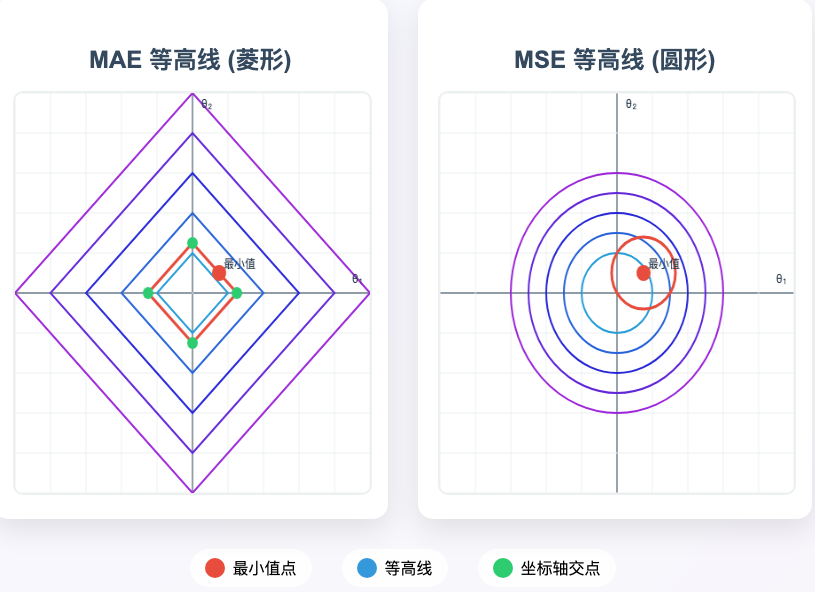
4. 對比總結
| 特性 | MSE | MAE |
|---|---|---|
| 對離群點敏感度 | 高(平方放大誤差) | 低(線性處理誤差) |
| 噪聲分布假設 | 高斯分布 | 拉普拉斯分布 |
| 梯度特性 | 梯度隨誤差減小而衰減 | 梯度恒定(除零點外) |
| 稀疏性 | 不易產生稀疏解 | 易產生稀疏解 |
| 優化穩定性 | 平滑優化,數值穩定性好 | 非光滑優化,可能需要特殊處理 |
在實際應用中,如果數據包含較多離群點或需要進行特征選擇,MAE是更合適的選擇;如果追求預測精度且噪聲近似高斯分布,MSE通常表現更好。


詳解)
詳解)











詳解)

)

