各位大佬好,我是落羽!一個堅持不斷學習進步的大學生。
如果您覺得我的文章有所幫助,歡迎多多互三分享交流,一起學習進步!
也歡迎關注我的blog主頁: 落羽的落羽

文章目錄
- 一、set和map是什么
- 二、set系列
- 1. set
- 2. multiset
- 三、map系列
- 1. map
- 2. multimap
一、set和map是什么
我們之前已經學習過了STL庫中的部分容器,如string、vector、list、deque,這些容器統稱之為序列式容器,因為它們的邏輯結構都是線性的,存儲元素之間一般沒有緊密的聯系關系,即使交換元素位置,數據結構仍是線性的。這些序列式容器的元素是按照他們在容器中存儲的位置來順序保存和訪問的。
關聯式容器的邏輯結構則是非線性的結構,元素位置之間有緊密的關聯關系,交換位置則存儲結構會破壞。關聯式容器有map/set系列和unordered_map/unorderer_set系列。
今天我們學習的set和map,底層是紅黑樹,紅黑樹是一棵平衡二叉搜索樹。set是key搜索場景的結構,而map是key/value搜索場景的結構。
二、set系列
使用set系列的set、multiset,都需要#include <set>
1. set
set是不允許key值重復出現的平衡二叉搜索樹。

- set的模板參數T,就是key的類型。
- set默認要求key值是小于比較,也就是這棵樹中左子樹key < 結點key < 右子樹key,因為第二個模板參數默認傳的是
less<T>。我們也可以自己傳greater<T>使之變成大于比較,即這棵樹中左子樹key > 結點key > 右子樹key。 - 由于set底層是紅黑樹,增刪查效率是O(logN),效率很高,中序遍歷默認是升序的。
set的幾種構造方式:
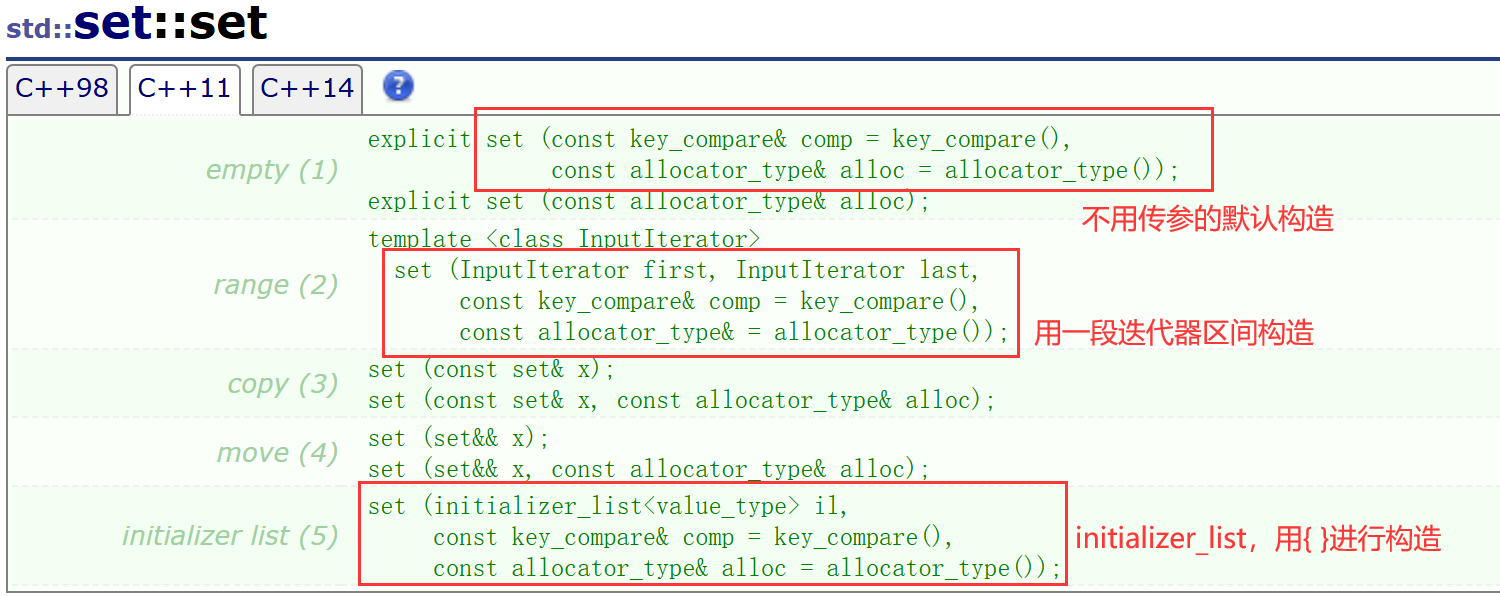
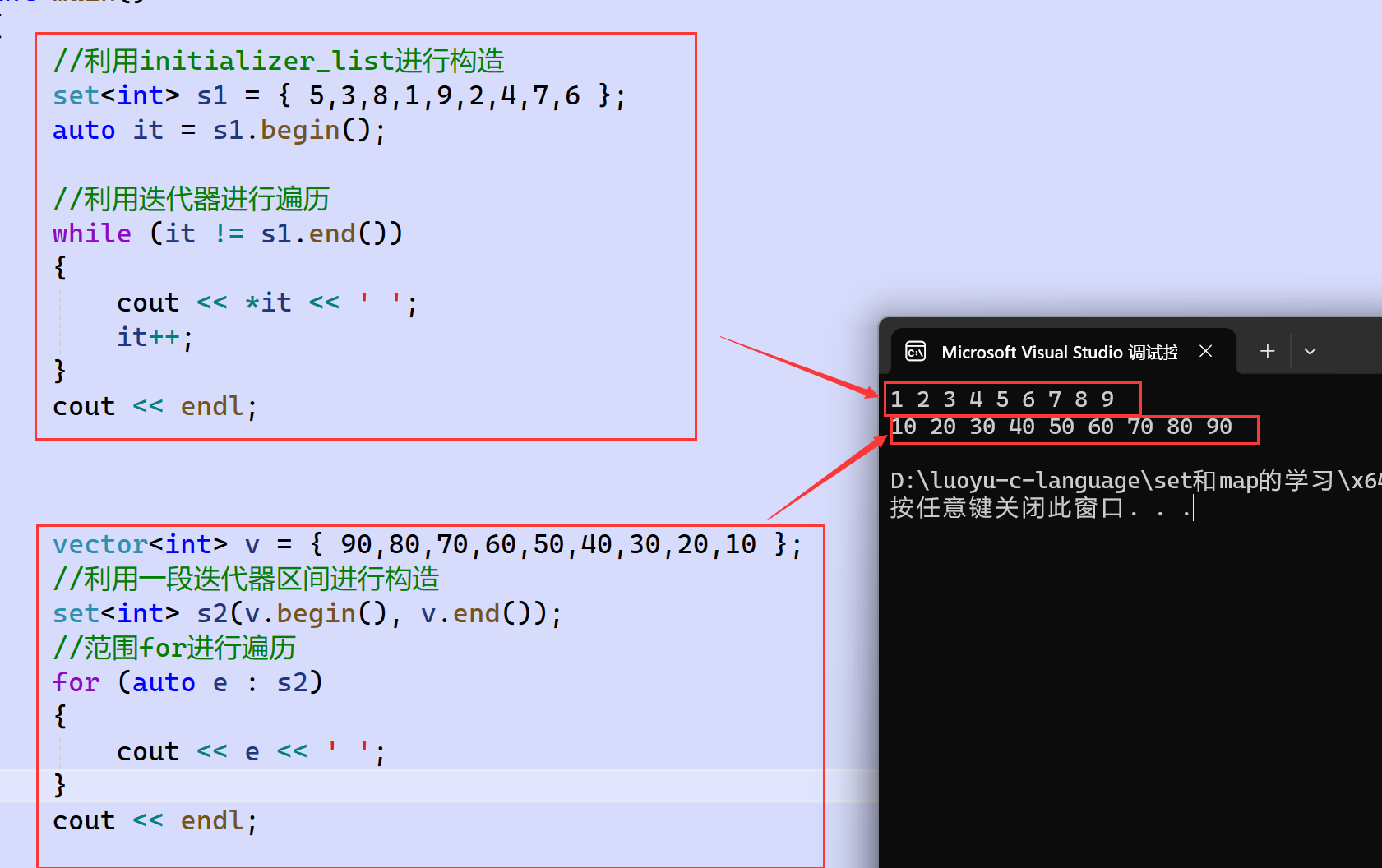
set也有迭代器,也有begin和end一系列接口。
set的begin()和end()是它的中序遍歷序列的開頭和結尾,begin是中序第一個結點,end是中序的最后一個結點的下一個位置。后面的容器也是一樣,begin和end都是中序遍歷的位置。不難想象,begin()返回的是最小key值結點的迭代器。
set支持正向和反向迭代器,也支持范圍for,迭代器++和范圍for都是按照樹的中序順序進行遍歷。但是set的iteritor和const_iteritor都不支持迭代器修改key,會破壞底層搜索樹的結構。
set類中當然還有增刪查等相關功能:
-
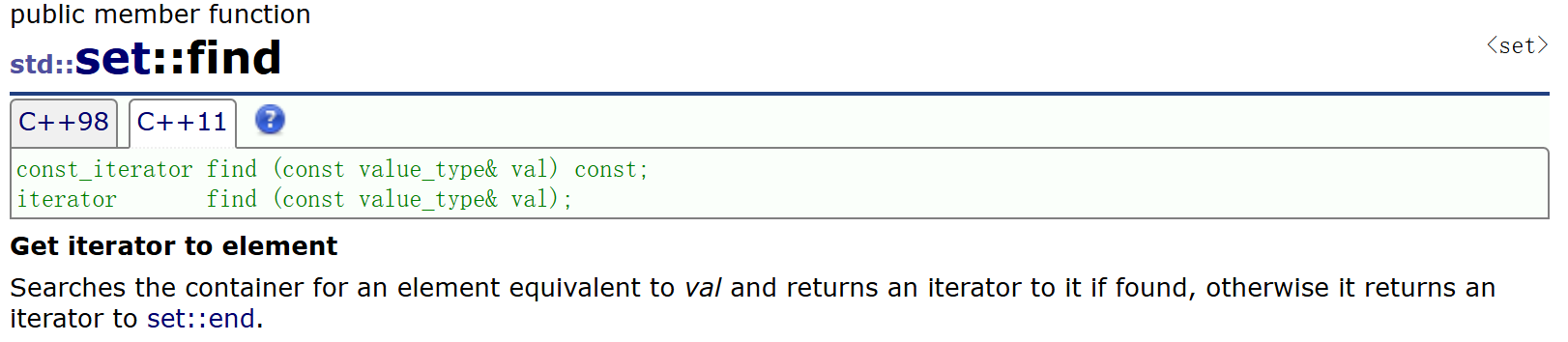
find:查找key為傳參val的位置,若存在則返回這個位置的迭代器,若不存在則返回end()
-
count:記錄set中key為傳參的結點個數

這個函數的返回值是size_t類型,是key值為val的個數,但是由于set中不允許有重復key值,所以set類對象這個函數的返回值只能是0或1,也就可以依據是0或1判斷某個key是否存在。換句話說,count也可以有查找判斷key是否存在的功能。 -
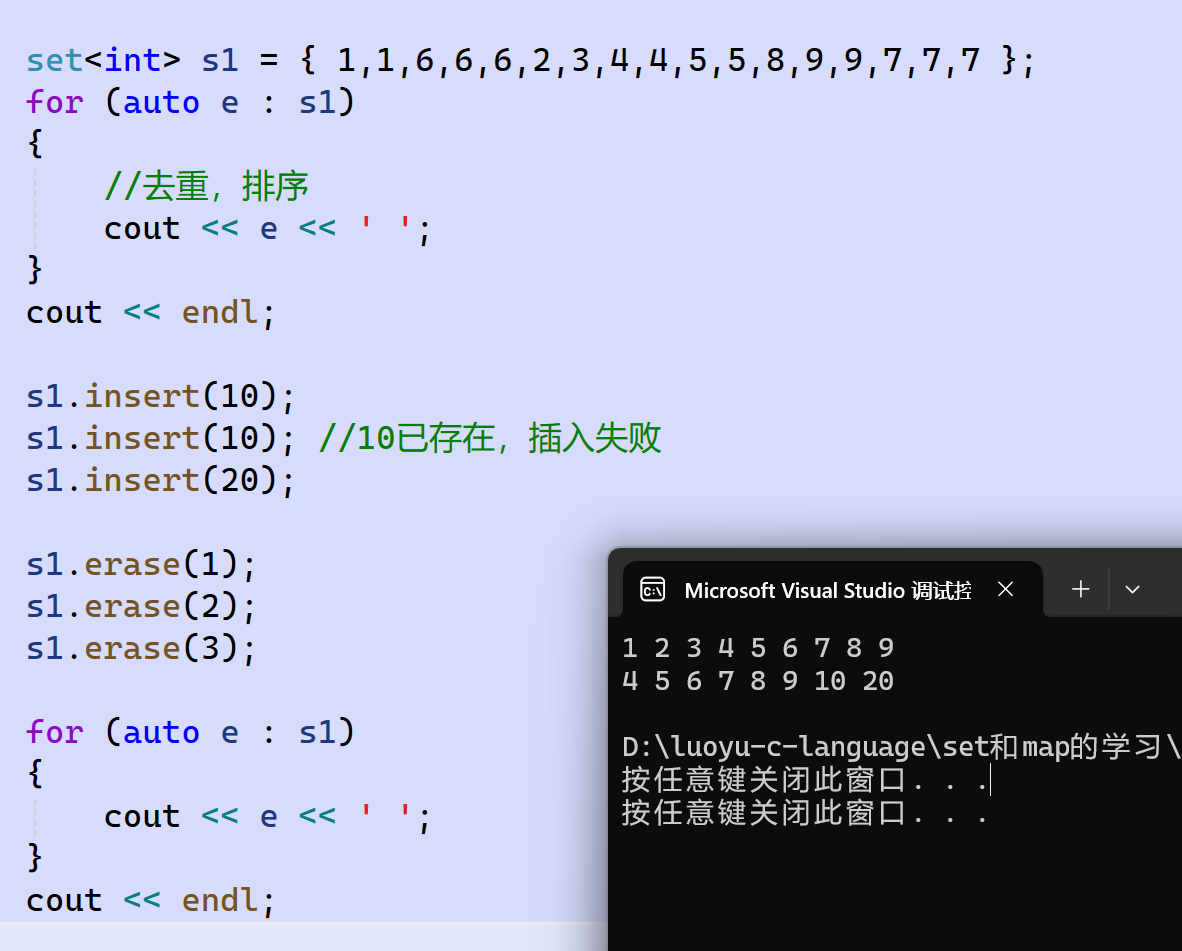
insert:插入新的key
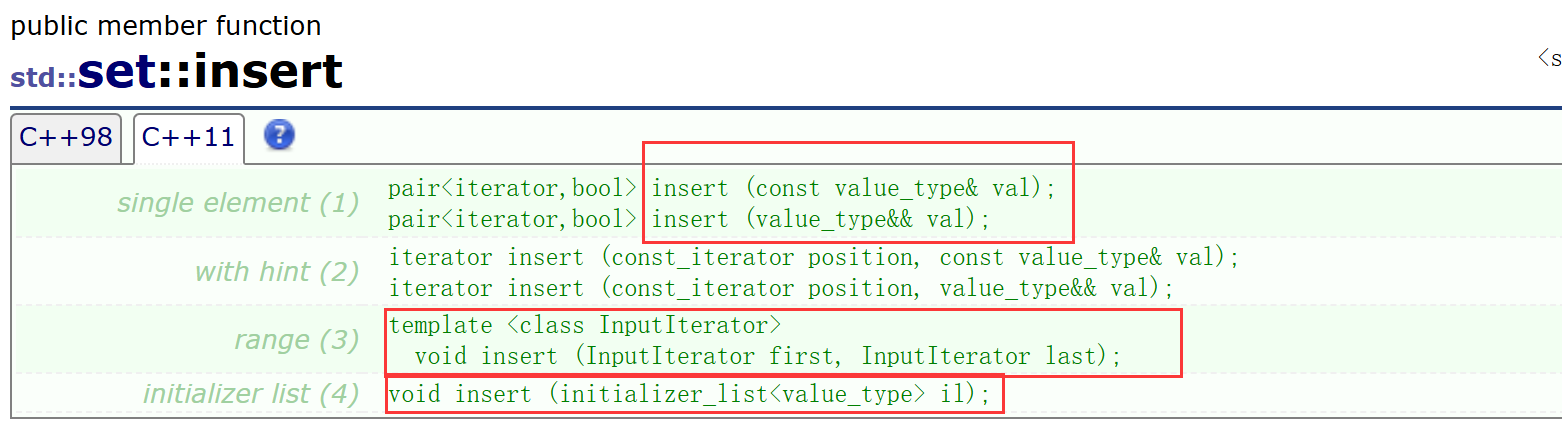 insert可以插入單個數據、一段迭代器區間、一段{ }列表。但由于set不允許有重復key值,所以插入內容中出現了重復key值則不會插入。這個過程實際是先進行了一次查找操作,在原set中找不到想新插入的key,才能進行插入。
insert可以插入單個數據、一段迭代器區間、一段{ }列表。但由于set不允許有重復key值,所以插入內容中出現了重復key值則不會插入。這個過程實際是先進行了一次查找操作,在原set中找不到想新插入的key,才能進行插入。 -
erase:刪除結點

erase可以傳一個迭代器刪除這個迭代器的結點,可以傳一段迭代器區間整體刪除。也可以傳一個key值刪除這個key值的結點,找不到這個key結點則不刪除,這種版本的erase返回值是size_t,和count道理一樣,返回值代表刪除的結點個數,1代表刪除了一個結點,0代表沒有刪除結點,也可以用于判斷刪除是否成功。
演示:
除此之外,set還有兩個接口lower_bound、upper_bound:
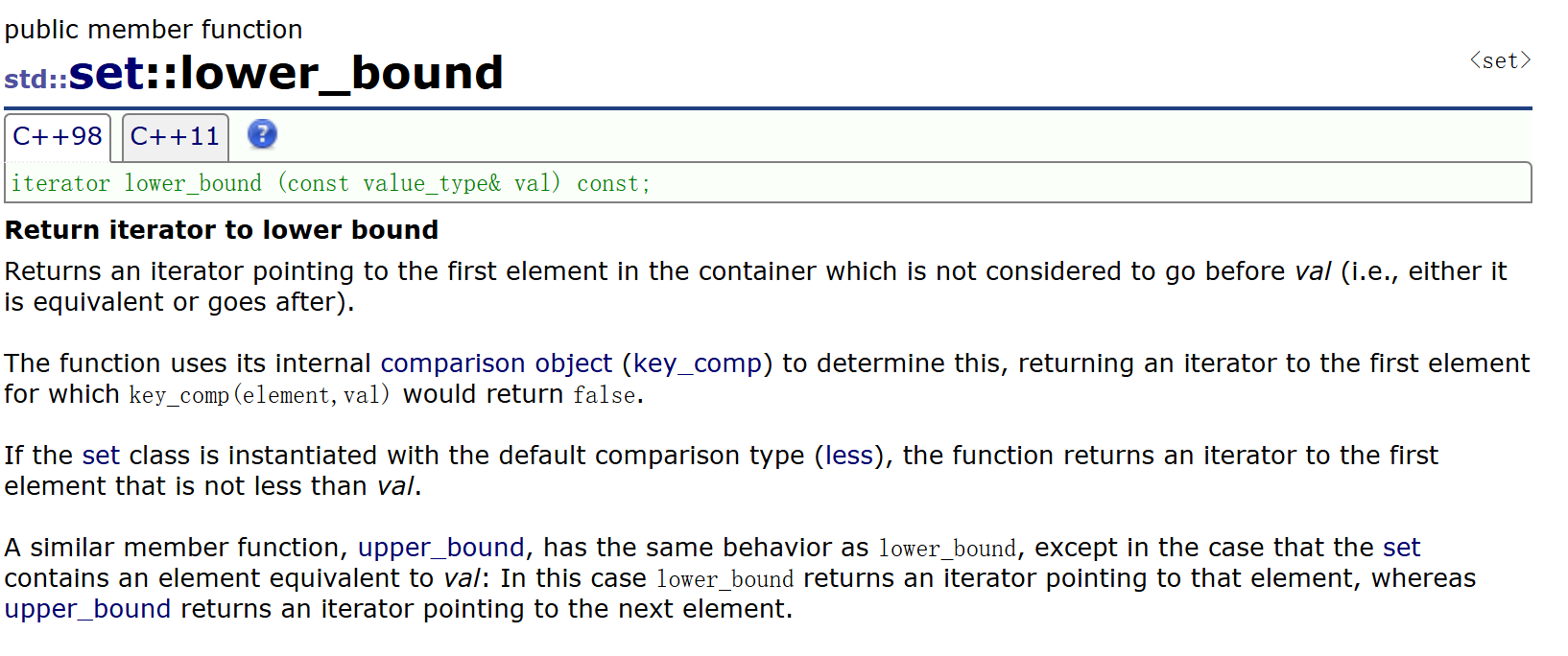
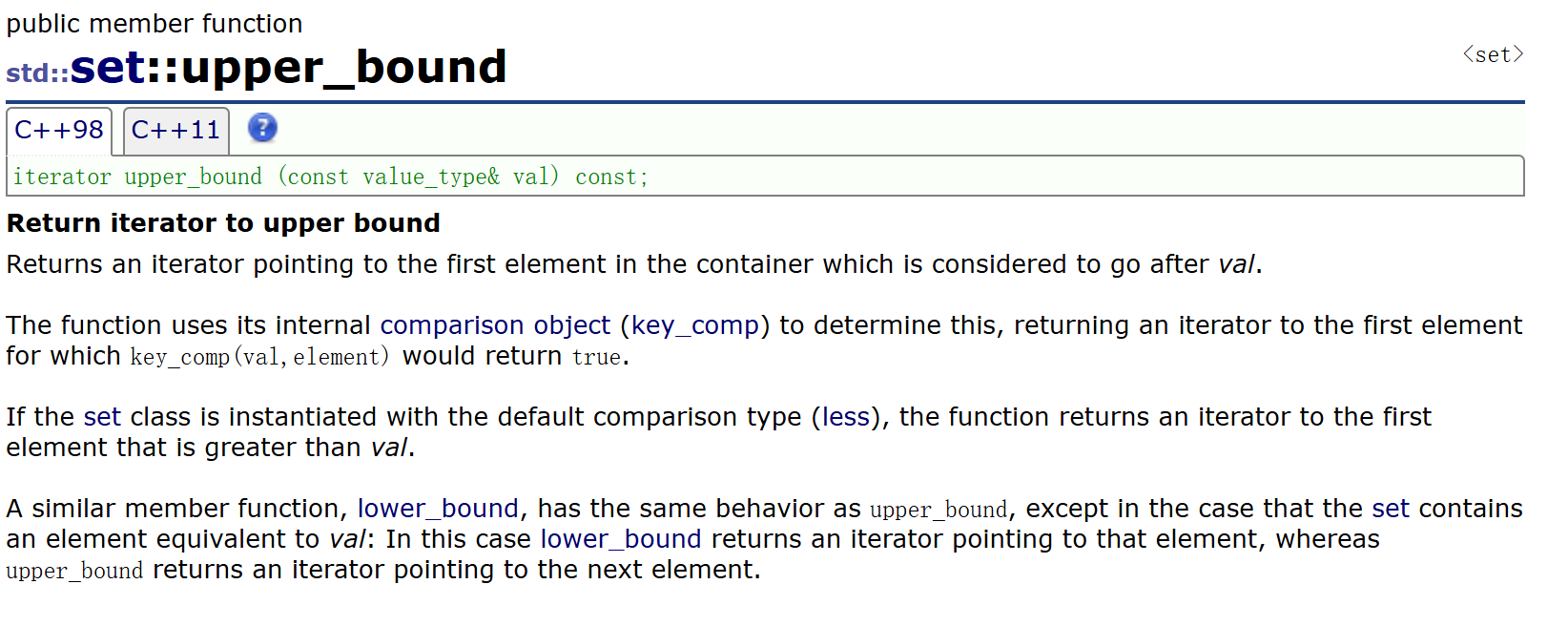
它們通常一起使用,lower_bound返回set中的第一個key值>=val值的結點的迭代器,upper_bound返回set中的第一個key值>val值的結點的迭代器。它們的作用是找一段值的區間。
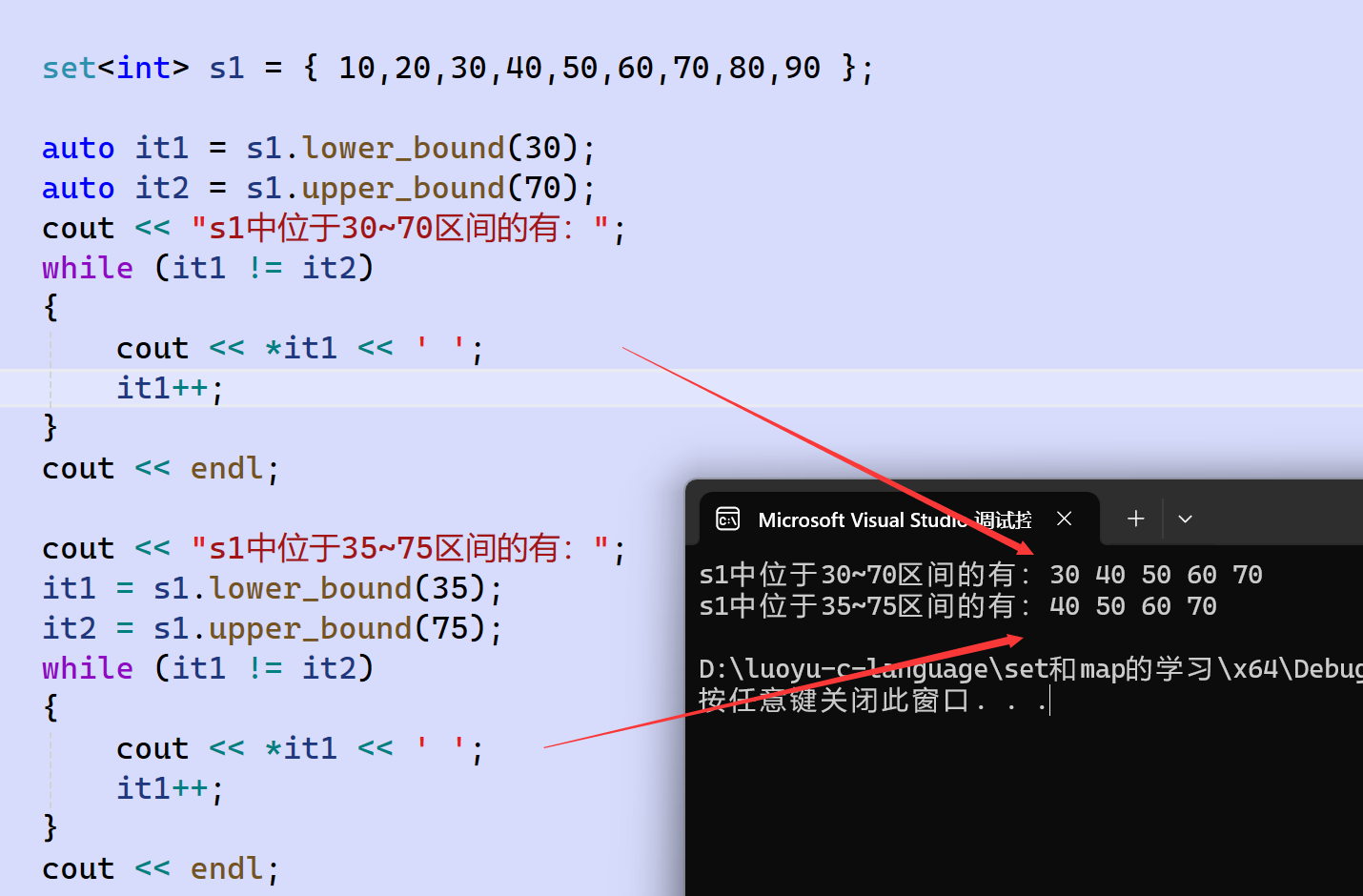
比如一個set中結點為{10, 20, 30, 40, 50, 60, 70, 80, 90},auto it1 = lower_bound(30);
則it1是結點30的迭代器,auto it2 = upper_bound(70);,則it2是結點70的迭代器。也就是說,it1和it2兩個迭代器包含了30、40、50、60、70這段結點區間。
這兩個函數的傳參可以不是set中已存在的key值,比如上面的例子,傳auto it1 = lower_bound(35);則it1是結點40的迭代器,auto it2 = upper_bound(75);,則it2是結點80的迭代器。
若它們找不到比val大的key結點,則返回end()。
演示:
2. multiset
multiset也是set系列的一種,相比于set,它支持key值的冗余,也就是可以存在重復的key值。相同的key可能在根結點key的左邊或右邊。它的使用與set大體類似,但find、insert、erase、count等與set的有所差異:
- find:multiset的key中可能有多個為val的結點。multiset的find是按照中序序列查找第一個key為val的結點,返回它的迭代器。
- insert:multiset支持存在重復的key,因此插入已存在key值的新結點也能成功。
- erase:multiset的這種erase版本
size_type erase (const value_type& val);會刪除所有key值為val的結點,返回值是刪除的結點的個數。因為multiset中可能有重復key值,所以返回值可能是任何非負整數。 - count:和set一樣,也是記錄返回key值為傳參val的結點個數。因為multiset中可能有重復key值,所以返回值可能是任何非負整數。
只要理解了multiset和set的差異只在于muliset支持key重復存在,它們的接口的差異都很好理解了。
演示: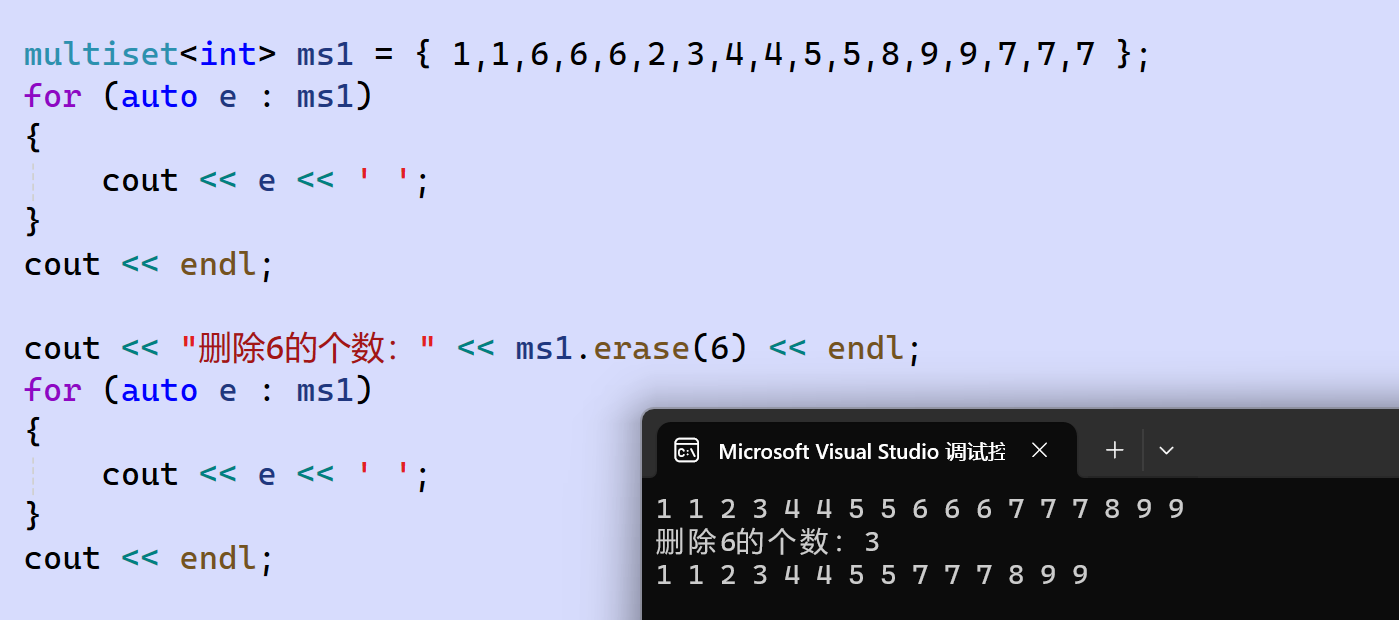
multiset也有lower_bound和upper_bound操作,和set道理一樣。
multiset中還有一個equal_range,是查找key值為傳參val的結點的區間。因為multiset中若有重復的key結點,則它們在中序序列中一定是連續的。equal_range就返回這一段迭代器區間。注意到它的返回類型是pair<iteritor, iteritor>,這就是兩個迭代器的組合代表一段區間,關于pair具體下面再介紹。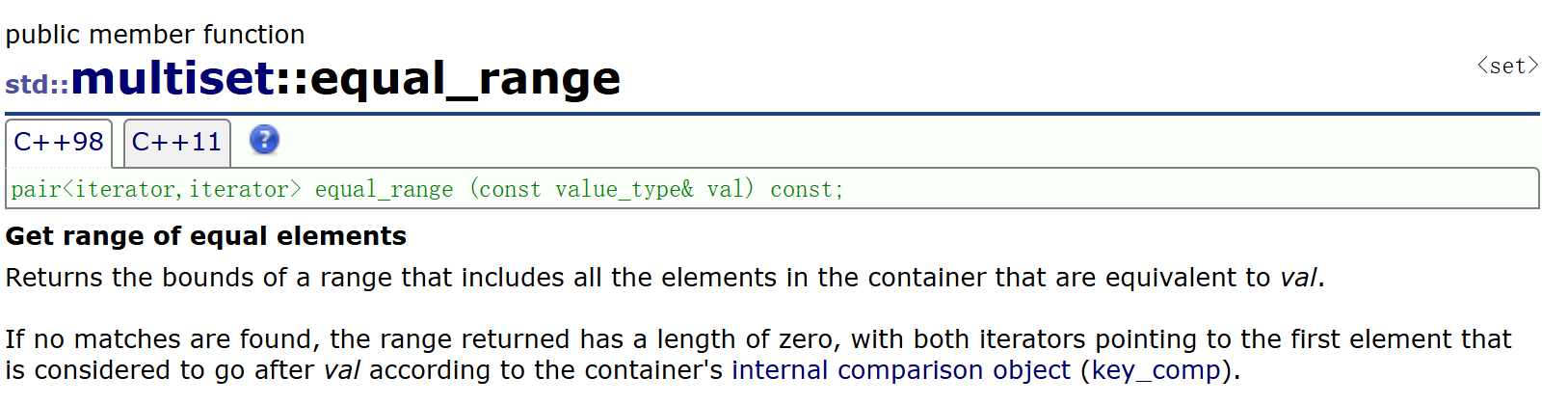
三、map系列
使用map系列的map、multimap,都需要#include <map>
1. map
set系列底層是key結構的紅黑樹,而map系列底層是key/value結構的紅黑樹。
map不允許key值重復出現的平衡二叉搜索樹。
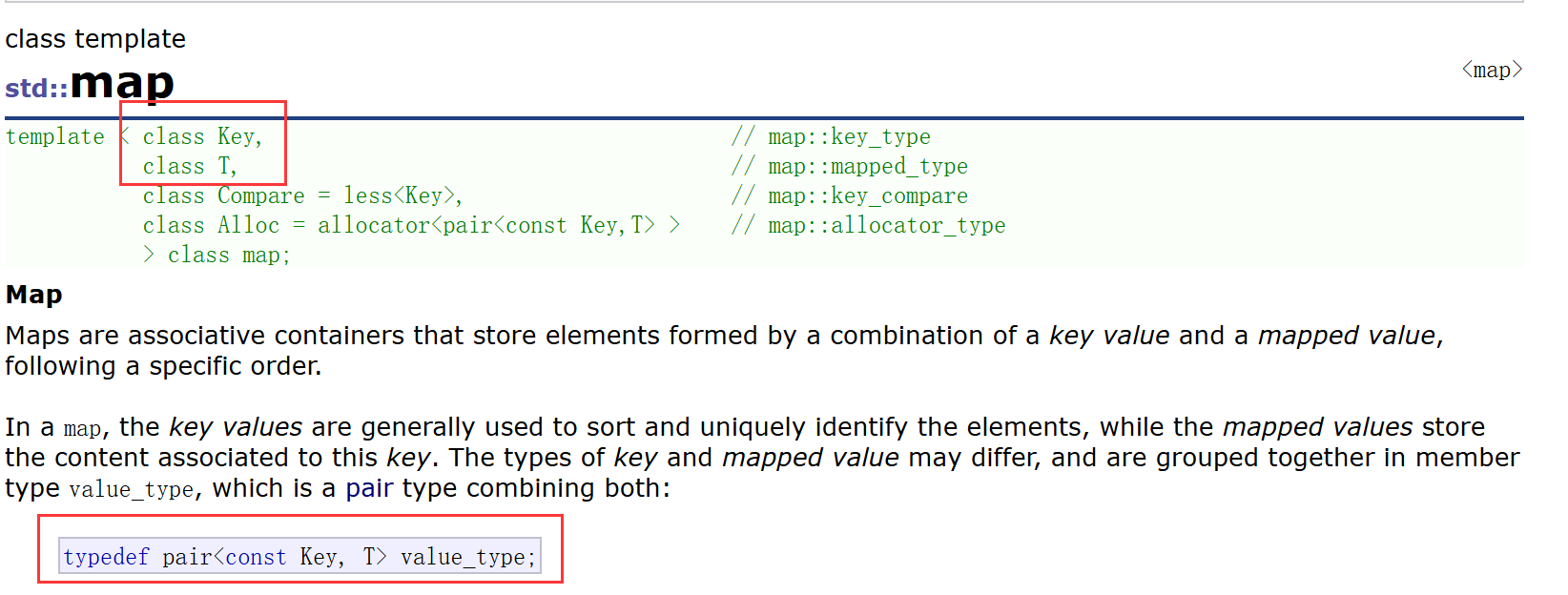
其中,Key是key的類型,T是value的類型。Compar默認傳less要求支持小于比較。map的增刪查改效率是O(N),迭代器也是走的中序遍歷,按照key的有序順序進行遍歷。
而在map的結點中,它的key和value其實是被封裝成一個叫pair的結構體來存儲的:
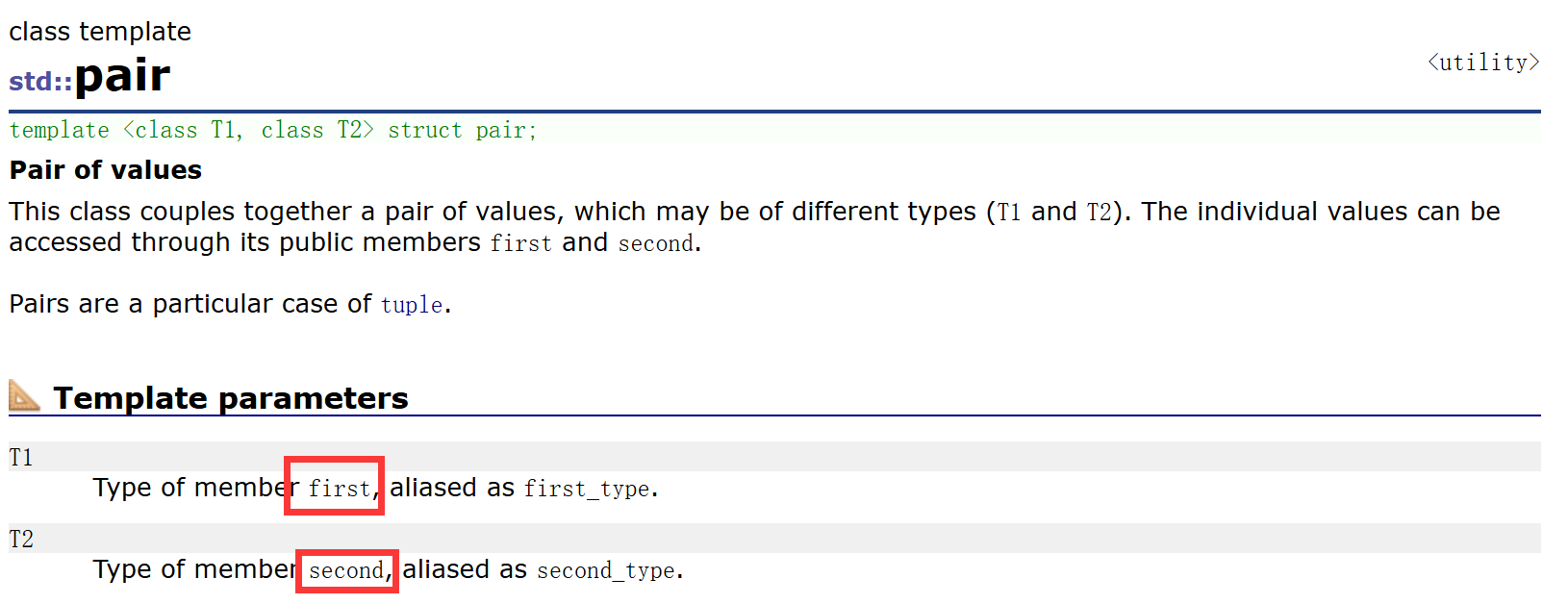
pair的結構其實很簡單,就是兩個類型的兩個成員封裝在一起,T1 first、T2 second。在map的結點中的pair,T1為key的類型,T2為value的類型,first就是key,second就是value。map的結點中,使用pair<Key, T>存儲鍵值對數據。當然,pair類型中還有一些構造函數、拷貝構造函數,不多贅述。
map的構造、迭代器、其他操作大體和set都是相似的,區別只在于map可以修改value值,不能修改key值。查和刪的操作只關注key,所以map的查和刪和set一樣。增的操作不僅要增key,還要增value:

第一個版本的insert返回類型是pair<iterator, bool>,如果key已在map中,則插入失敗,返回的pair的first是已存在key所在節點的迭代器,second是false;如果key不在map中,插入成功,返回的pair的first是新插入key的結點迭代器,second是true。也就是說,無論key插入失敗成功,insert的返回值的first都是key結點的迭代器,意味著insert也能充當查找的功能,下面[ ]的重載就是利用了這一點。
insert要求的參數是一個pair,這里其實就很靈活了。可以構造對象再傳參、匿名對象傳參、隱式類型轉換傳參:

相比set,map還可以修改value的功能。一種方法是通過迭代器,map的迭代器相當于指向pair的指針,利用迭代器->second = x;來完成修改。
另一種方法,map重載了[]操作符,但是用法很特殊:map的[ ]中不是傳尋常的下標,而是傳key值,若這個key值在map中已存在,則返回它對應的value的引用;若這個key值不存在,則將這個key新插入進去,它的value則使用它的缺省值或調它的類型的默認構造,也返回value的引用。
value若是自定義類型,就有它的默認構造;內置類型也有默認構造,如int默認構造為0,指針默認構造為nullptr。
不難看出,[ ]有查找+插入的功能,同時因為返回value的引用,也具備了修改的功能。map的[ ]重載是一個非常重要的多功能接口,它的內部實現是這樣的,利用剛才說的insert的特點:
T& operator[](const Key& key)
{pair<iterator, bool> ret = insert({key, T()});//it指向了key值的結點,不論這個key是已存在的還是新插入的iterator it = ret.first;//it相當于指向了pair,it的second就是value了return it->second;
}
map的[ ]在一些特定場景下使用是很爽的,比如這樣一個例子:統計字母出現個數。
不使用[ ]可能要這么做:
vector<char> v = { 'a','b','c','b','a','c','a','a','b' };//構建一個map<char,int>,char代表字母,int代表它的出現次數
map<char, int> countMap;for (auto e : v)
{//查找字母在不在map中auto ret = countMap.find(e);//不在,說明這個字母是第一次出現,插入{字母,1}if (ret == countMap.end()){countMap.insert({ e,1 });}//這個字母存在,則它的出現次數+1else {ret->second++;}
}for (auto e : countMap)
{cout << e.first << ":" << e.second << "次" << endl;
}
cout << endl;

但使用[ ],就更簡潔了:
vector<char> v = { 'a','b','c','b','a','c','a','a','b' };//構建一個map<char,int>,char代表字母,int代表它的出現次數
map<char, int> countMap;for (auto e : v)
{//字母不在,說明這個字母第一次出現,則插入,int默認構造成0,++一下就成1了//字母在,也返回value的引用,也會++一次countMap[e]++;
}for (auto e : countMap)
{cout << e.first << ":" << e.second << "次" << endl;
}
cout << endl;

沒有問題!
2. multimap
multimap就是支持key重復出現的map,同一key值的不同結點的value也可以不一樣。multimap的增刪查改相對于map也有一些不同,但是大概規律和multiset相對于set一樣,比如find返回多個key值結點的中序遍歷第一個。除此之外就是multimap不支持map的[ ]。
本篇完,感謝閱讀~




)
—— 數據探索之概率統計)

算法)











