論文鏈接:LoRA: Low-Rank Adaptation of Large Language Models
官方實現:microsoft/LoRA
非官方實現:huggingface/peft、huggingface/diffusers
這篇文章要介紹的是一種大模型/擴散模型的微調方法,叫做低秩適應(也就是 Low-Rank Adaptation,LoRA)。經常使用 stable diffusion webui 的讀者應該對這個名詞非常熟悉,通過給擴散模型加載不同的 lora,可以讓擴散模型生成出不同風格的圖像。現在也已經有很多平臺(例如 civitai、tensorart 等)可以下載現成的 lora,可以看出 LoRA 的影響力還是比較大的。
LoRA 作為一種高效的參數微調(Parameter-Efficient Fine-Tuning,PEFT)方法,最初是被用來微調 LLM 的,后來也被用來微調擴散模型。這種方法的主要思想是固定住預訓練模型的參數,同時引入額外的可訓練低秩分解模塊,只訓練額外引入的這部分參數,從而大大減小模型的微調成本。
與其他的 Peft 方法相比,LoRA 也有一些獨特的優勢:
- 首先是與 adapter 的方法相比,LoRA 不引入額外推理延遲。因為 Adapter 會在模型中插入額外的 layer,在推理時這些 layer 都會引入延遲,并且在分布式訓練中需要更多的進程同步操作。而 LoRA 不存在這個問題,且在推理階段可以利用重參數化將額外的權重與原有權重合并(這個后邊會介紹),從而保持推理延遲不變。
- 其次是與 prefix embedding tuning 相比,LoRA 更容易優化。并且 prefix embedding tuning 需要在序列前方插入一部分用來微調的 prompt,這種做法限制了有效 prompt 的長度。
- 除此之外,不同 LoRA 模型可以共用同一個基座模型,每次微調只需要保存額外參數。而且這種方法與其他的 peft 方法正交,可以同時使用多種 peft 方法進行微調。
LoRA 介紹
論文的作者提出本方法主要是基于一個觀察:模型通常都是過參數化的,在模型的優化過程中,更新的參數集中在低維度的子空間中。同時,模型在下游任務微調后,權重的內在秩(intrinsic rank,或者叫本征秩)是比較低的,因此可以認為更新的權重也是低秩的。所謂的更新的權重,可以表示成: W = W 0 + Δ W W=W_0+\Delta W W=W0?+ΔW,其中 W 0 W_0 W0? 就是原始的權重、 Δ W \Delta W ΔW 則是權重的變化量,也就是更新的權重。
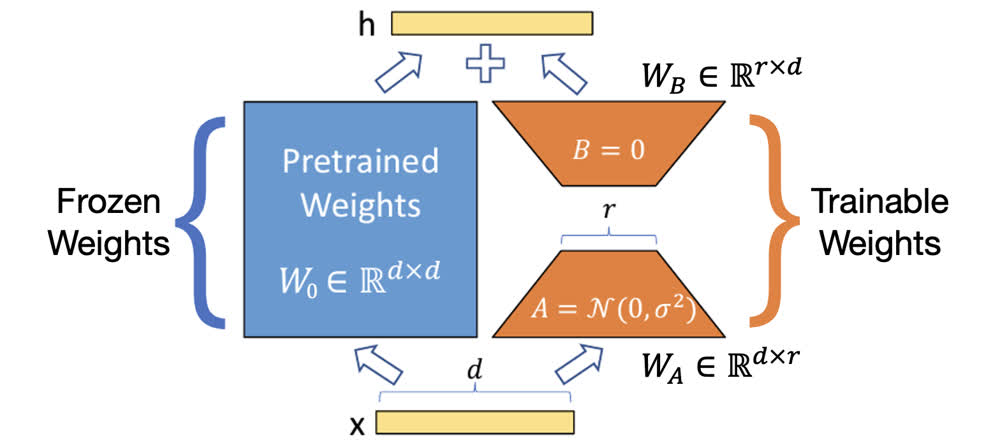
LoRA 具體的做法如上圖所示,在預訓練權重的旁邊加入了一個新的支路,表示 Δ W \Delta W ΔW。由于上文中說的 Δ W \Delta W ΔW 具有較低的秩,因此可以對其進行低秩分解: Δ W = B A \Delta W=BA ΔW=BA,如果原始權重 W W W 的維度為 d × d d\times d d×d,低秩分解的秩為 r r r,那么有 B ∈ R d × r B\in\mathbb{R}^{d\times r} B∈Rd×r、 A ∈ R r × d A\in\mathbb{R}^{r\times d} A∈Rr×d,并且 r ? d r\ll d r?d。由于 r r r 很小,所以這部分的參數量也很小,在微調時只有這部分權重需要更新,所以訓練的資源消耗并不大。
加入低秩分解模塊后,模型的推理過程就變成了 W x = W 0 x + Δ W x = W 0 x + B A x Wx=W_0x+\Delta Wx=W_0x+BAx Wx=W0?x+ΔWx=W0?x+BAx。在初始條件下,LoRA 權重分別被初始化為高斯分布與 0,如上圖所示。(根據作者的意思,A 和 B 的初始化也可以反過來)這樣在初始條件下, B A x BAx BAx 這一項為 0,相當于從原始模型開始微調。
在實際使用時,還會引入一個額外的參數用來調整 LoRA 部分的權重,也就是 W x = W 0 x + α r B A x Wx=W_0x+\frac{\alpha}{r}BAx Wx=W0?x+rα?BAx,一般 α \alpha α 會設置為一個比 r r r 大的值。這樣做一方面是為了放大 LoRA 的效果,另一方面也是為了方便調參。
在微調結束后,推理時,由于 A 和 B 的權重矩陣相乘結果 BA 的維度和原始權重 W 0 W_0 W0? 的維度是相同的,所以直接加到 W 0 W_0 W0? 上即可完成重參數化。這樣額外的分支就合并到了原始的權重里,不會引入額外延遲。
到這里 LoRA 的微調過程就算介紹完了,下面再補充一些知識點和細節。
LoRA 降低了哪部分顯存
我們知道使用 LoRA 可以大大減少微調的顯存消耗量,然而 LoRA 相比原始模型是增加了模塊,所以相比原始模型產生的梯度肯定是更大的。之所以能夠降低顯存,主要是因為 optimizer 中保存的 state 減少了,對于單層,從 d × d d\times d d×d 變為了 d × r d\times r d×r,所以整體顯存使用量依然是降低。
LoRA 加入模型的哪一部分
論文的作者將 LoRA 的作用范圍限制在了 self-attention 的 projection 層中,也就是只有 QKV 和輸出 O 的 projection 才使用 LoRA。在實驗時,作者限制了可微調參數量,如果僅對 QKVO 中的一個使用 LoRA,則 rank 為 8;如果對其中兩個使用,則 rank 為 4。
根據實驗,相比于 rank 的大小,使用的 LoRA 數量對性能來說更重要。對所有的 QKVO 使用 LoRA 時,盡管 rank 很低(僅為 2),也能達到不錯的效果。
LoRA 代碼解讀
其實主流的 LoRA 都是用 microsoft 的官方實現以及 huggingface 的 peft 庫實現的,不過這類實現一般是用于 LLM,因為我們更關心如何在擴散模型里使用,所以這里基于 diffusers 的實現進行解讀。
一些工程代碼(可以略讀)
首先還是先初始化了 stable diffusion 的各個模塊:
# Load scheduler, tokenizer and models.
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
)
vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
unet = UNet2DConditionModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
# freeze parameters of models to save more memory
unet.requires_grad_(False)
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
然后配置了一些 LoRA 的參數,可以看到設置了 r 和 α \alpha α,以及初始化權重的方式和作用的 projection 范圍:
unet_lora_config = LoraConfig(r=args.rank,lora_alpha=args.rank,init_lora_weights="gaussian",target_modules=["to_k", "to_q", "to_v", "to_out.0"],
)
然后把 LoRA 加入到 UNet 中:
unet.add_adapter(unet_lora_config)
這個 add_adapter 是由 diffusers.loaders.peft.PeftAdapterMixin 引入,這里調用了 peft 庫里的 inject_adapter_in_model 方法,可以看到最后還是使用的 peft 中的實現。這個方法定義在 peft.mapping.inject_adapter_in_model,初始化了一個新的 peft 對象:
tuner_cls = PEFT_TYPE_TO_TUNER_MAPPING[peft_config.peft_type]# By instantiating a peft model we are injecting randomly initialized LoRA layers into the model's modules.
peft_model = tuner_cls(model, peft_config, adapter_name=adapter_name)
這里我們使用的是 lora,所以 tuner_cls 是 peft.tuners.lora.model.LoraModel。在這個對象初始化的時候,會調用 peft.tuners.tuners_utils.inject_adapter。核心的邏輯在這里,具體的看注釋:
# 獲得模型所有模塊的 key
key_list = [key for key, _ in model.named_modules()]
# 找到所有要進行 adaptation 的 layer
peft_config = _maybe_include_all_linear_layers(peft_config, model)
# 遍歷所有的 key 進行 LoRA 的插入
for key in key_list:# 如果不需要加入 LoRA,則直接跳過if not self._check_target_module_exists(peft_config, key):continue# 一些記錄self.targeted_module_names.append(key)is_target_modules_in_base_model = True# 正式進行替換(重點部分)parent, target, target_name = _get_submodules(model, key)self._create_and_replace(peft_config, adapter_name, target, target_name, parent, current_key=key)
這里調用的 _create_and_replace 在 LoraModel 實現:
def _create_and_replace(self, ...):... # 前邊的主要是解析一些參數,此處略去# 這里創建了 LoRA 模塊,并且將原始的 projection 模塊替換成 LoRA 模塊new_module = self._create_new_module(lora_config, adapter_name, target, **kwargs)self._replace_module(parent, target_name, new_module, target)
具體怎么創建和替換不是很重要,只需要知道這里就是篩選了所有符合條件的 key 將其替換成了對應的 LoRA 模塊即可。知道了替換的邏輯之后,下面我們看看 LoRA 模塊內部的具體實現。
LoRA 的具體實現
在 peft 的 LoRA 實現中,提供了 Linear、Embedding、Conv2d 三種 LoRA 層,因為我們上邊說的 LoRA 主要用在 self-attention 的 projection 中,所以重點分析一下 Linear 的實現。
LoRA 的初始化
Linear 的實現位于 peft.tuners.lora.layer.Linear,其繼承自 nn.Module 和 LoraLayer,后者應該也可以看作一種 mixin。在初始化時,LoraLayer 初始化了以下屬性:
self.base_layer = base_layer # 這個就是沒有加 LoRA 的 projection 層
self.r = {} # rank
self.lora_alpha = {} # alpha
self.scaling = {} # 這個是 alpha/rank
self.lora_A = nn.ModuleDict({}) # LoRA 中的 A
self.lora_B = nn.ModuleDict({}) # LoRA 中的 B
然后在 update_layer 中進行了進一步的初始化:
self.r[adapter_name] = r
self.lora_alpha[adapter_name] = lora_alpha
# Actual trainable parameters
self.lora_A[adapter_name] = nn.Linear(self.in_features, r, bias=False)
self.lora_B[adapter_name] = nn.Linear(r, self.out_features, bias=False)
self.scaling[adapter_name] = lora_alpha / r
隨后繼續調用 reset_lora_parameters 初始化了權重:
nn.init.normal_(self.lora_A[adapter_name].weight, std=1 / self.r[adapter_name])
nn.init.zeros_(self.lora_B[adapter_name].weight)
推理過程實現
直接看 forward 函數的實現即可,具體的可以看下邊代碼里的注釋。這里需要提前介紹一下,這個類有一個屬性 merged 用來表示有沒有重參數化過,如果已經進行了重參數化,那么這個屬性就是 True,反之同理。
def forward(self, x: torch.Tensor, *args: Any, **kwargs: Any) -> torch.Tensor:# 如果不使用 adapter,就只傳播原始網絡,也就是 base_layerif self.disable_adapters:# 如果已經進行了重參數化,需要反重參數化if self.merged:self.unmerge()result = self.base_layer(x, *args, **kwargs)# 如果已經重參數化,那么就和原始的 base_layer 的推理過程相同if self.merged:result = self.base_layer(x, *args, **kwargs)else: # 如果沒有重參數化# 先推理原始網絡result = self.base_layer(x, *args, **kwargs)torch_result_dtype = result.dtypefor active_adapter in self.active_adapters:if active_adapter not in self.lora_A.keys():continue# 再推理 A 和 Blora_A = self.lora_A[active_adapter]lora_B = self.lora_B[active_adapter]dropout = self.lora_dropout[active_adapter]scaling = self.scaling[active_adapter]x = x.to(lora_A.weight.dtype)# 可以看到這里進行了加權求和result = result + lora_B(lora_A(dropout(x))) * scalingresult = result.to(torch_result_dtype)return result
重參數化與反重參數化
重參數化就是把 base_layer 的權重 W 0 W_0 W0? 替換為 W 0 + Δ W W_0+\Delta W W0?+ΔW,反重參數化則是需要進行這個過程的反過程。因此首先需要實現計算 Δ W \Delta W ΔW,計算方式是 Δ W = W B W A \Delta W=W_BW_A ΔW=WB?WA?,在代碼中就是:
def get_delta_weight(self, adapter) -> torch.Tensor:... # 去掉了一些不重要的類型/設備轉換相關的代碼weight_A = self.lora_A[adapter].weightweight_B = self.lora_B[adapter].weight# 可以看到實現還是很直接的output_tensor = transpose(weight_B @ weight_A, self.fan_in_fan_out) * self.scaling[adapter]return output_tensor
重參數化代碼在 merge 中,這里也給出一個比較簡化的版本,具體的見注釋:
def merge(self, safe_merge: bool = False, adapter_names: Optional[list[str]] = None) -> None:adapter_names = check_adapters_to_merge(self, adapter_names)if not adapter_names:return# 遍歷所有的 adapter,這里應該就只有 lorafor active_adapter in adapter_names:if active_adapter in self.lora_A.keys():# 原始的 layerbase_layer = self.get_base_layer()# 用上述方法獲得的 delta Wdelta_weight = self.get_delta_weight(active_adapter)# 直接加到原始 layer 的權重上base_layer.weight.data += delta_weight# 記錄 merge 情況self.merged_adapters.append(active_adapter)
反重參數化也是同理:
def unmerge(self) -> None:if not self.merged:warnings.warn("Already unmerged. Nothing to do.")returnwhile len(self.merged_adapters) > 0:active_adapter = self.merged_adapters.pop()if active_adapter in self.lora_A.keys():weight = self.get_base_layer().weight# 計算 delta Wdelta_weight = self.get_delta_weight(active_adapter)# 從原始 layer 權重中將其減去weight.data -= delta_weight
權重的保存和讀取
可以看看 demo 里是怎么保存的 LoRA 權重:
unwrapped_unet = unwrap_model(unet)
unet_lora_state_dict = convert_state_dict_to_diffusers(get_peft_model_state_dict(unwrapped_unet)
)
StableDiffusionPipeline.save_lora_weights(save_directory=save_path,unet_lora_layers=unet_lora_state_dict,safe_serialization=True,
)
從這段代碼里可以看出,主要需要關注的就只有 get_peft_model_state_dict,這部分負責從模型的 state_dict 中將 LoRA 對應的權重提取出來。具體的為:
def get_peft_model_state_dict(model, state_dict=None, adapter_name="default", unwrap_compiled=False, save_embedding_layers="auto"
):config = model.peft_config[adapter_name]if state_dict is None:state_dict = model.state_dict()# 遍歷 state_dict,保存所有 key 帶有 lora 的權重to_return = {k: state_dict[k] for k in state_dict if ("lora_" in k and adapter_name in k)}return to_return
對于讀取,則是直接使用 load_lora_weights:
pipeline.load_lora_weights(args.output_dir)
這部分的封裝也是非常復雜,一直找到最內層是調用了 peft.utils.save_and_load 這個模塊中的 set_peft_model_state_dict,簡化一下大概是這樣:
def set_peft_model_state_dict(model, peft_model_state_dict, adapter_name="default", ignore_mismatched_sizes: bool = False
):config = model.peft_config[adapter_name]state_dict = peft_model_state_dictpeft_model_state_dict = {}# 所有 LoRA 參數都含有以 lora 開頭的一個子串parameter_prefix = 'lora_'# 將 LoRA key 進行一些轉換for k, v in state_dict.items():if parameter_prefix in k:suffix = k.split(parameter_prefix)[1]if "." in suffix:suffix_to_replace = ".".join(suffix.split(".")[1:])k = k.replace(suffix_to_replace, f"{adapter_name}.{suffix_to_replace}")else:k = f"{k}.{adapter_name}"peft_model_state_dict[k] = velse:peft_model_state_dict[k] = v# 加載 state_dictload_result = model.load_state_dict(peft_model_state_dict, strict=False)return load_result
總結
感覺 LoRA 的思想還是很巧妙的,用很簡單的方法實現了大模型的微調。雖然方法很簡單,但是在工程實現方面由于很多中 peft 方法的實現,實際上還是很復雜的,真是很佩服寫 peft 庫的這群人,處理的情況也太多了,最后提供的接口也是很易用,tql。
參考資料:
- 當紅炸子雞 LoRA,是當代微調 LLMs 的正確姿勢?
- 圖解大模型微調系列之:大模型低秩適配器LoRA(原理篇)
本文原文以 CC BY-NC-SA 4.0 許可協議發布于 筆記|LoRA 理論與實現|大模型輕量級微調,轉載請注明出處。




解決方案)




![2025年滲透測試面試題總結-小鵬[實習]安全工程師(題目+回答)](http://pic.xiahunao.cn/2025年滲透測試面試題總結-小鵬[實習]安全工程師(題目+回答))



)





)